
 Backend Development
C#.Net Tutorial
Detailed explanation of graphic code of C# classic sorting algorithm (Part 2)
Backend Development
C#.Net Tutorial
Detailed explanation of graphic code of C# classic sorting algorithm (Part 2)
Detailed explanation of graphic code of C# classic sorting algorithm (Part 2)

This article mainly introduces you in detailC#The second part of the series of seven classic sorting algorithms, direct insertion sorting, Hill sorting and merge sorting, has certain reference value, interested friends We can refer to
Today I will talk to you about the last three sorts: direct insertion sort, Hill sort and merge sort.
Direct insertion sorting:
This kind of sorting is actually quite easy to understand. A very realistic example is our Landlord fight. When we catch a random hand of cards, We have to sort out the poker cards according to size. After 30 seconds, the poker cards are sorted out, 4 3's, 5 s's, wow... Recall how we sorted it out at that time.
The leftmost card is 3, the second card is 5, the third card is 3 again, quickly insert it behind the first card, the fourth card is 3 again, great joy, hurry up Insert it after the second card, and the fifth card is 3 again. I am ecstatic, haha, a cannon is born.
How about it? Algorithms are everywhere in life and have already been integrated into our lives and blood.
The following is an explanation of the above picture:
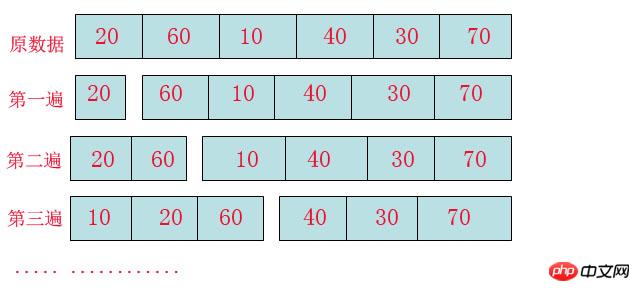
I don’t know if you can understand this picture. In insertion sort, Array It will be divided into two types, "ordered array block" and "unordered array block". Yes, in the first pass, a number 20 is extracted from the "unordered array block" as an ordered array block.
In the second pass, a number 60 is extracted from the "unordered array block" and placed in an orderly manner into the "ordered array block", that is, 20, 60.
The same goes for the third pass, but the difference is that 10 is found to be smaller than the value of the ordered array, so the 20 and 60 positions are moved back to free up a position for 10 to be inserted.
Then all insertions can be completed according to this rule.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace InsertSort
{
public class Program
{
static void Main(string[] args)
{
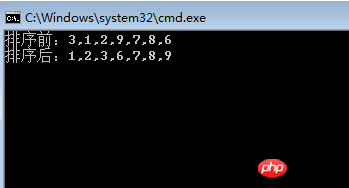
List<int> list = new List<int>() { 3, 1, 2, 9, 7, 8, 6 };
Console.WriteLine("排序前:" + string.Join(",", list));
InsertSort(list);
Console.WriteLine("排序后:" + string.Join(",", list));
}
static void InsertSort(List<int> list)
{
//无须序列
for (int i = 1; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - 1; j >= 0 && temp < list[j]; j--)
{
list[j + 1] = list[j];
}
list[j + 1] = temp;
}
}
}
}
Hill sorting:
Look at "insertion sort": Actually it doesn't It is difficult to find that she has a shortcoming:
If the data is "5, 4, 3, 2, 1", at this time we will insert the records in the "unordered block" When we reach the "ordered block", we are expected to collapse, and the position will be moved every time we insert. At this time, the efficiency of insertion sort can be imagined.
Shell has improved the algorithm based on this weakness and incorporated an idea called "Reduce incremental sorting method". It is actually quite simple, but something to note is:
The increment is not taken randomly, but has rules to follow.
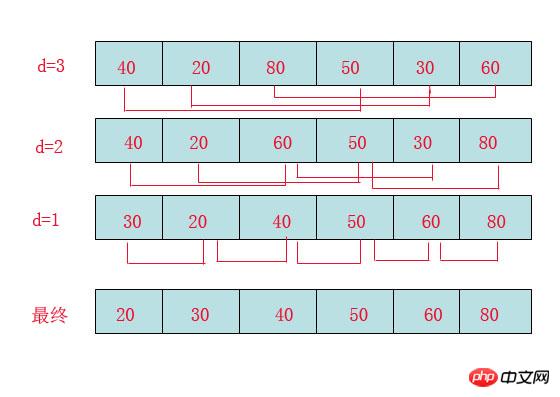
First of all, we need to clarify how to choose the increment:
The method to choose the first increment is: d=count/2;
The method of taking the second incremental increase is: d = (count/2)/2;
## Finally until: d = 1;When d=3: Compare 40 with 50. Because 50 is larger, there is no exchange.
Comparing 20 with 30, because 30 is larger, there is no exchange.
Compare 80 with 60. Since 60 is smaller, exchange them.
When d=2: Compare 40 with 60 without exchanging, then exchange 60 with 30. At this time, the exchanged 30 is smaller than the previous 40, and 40 and 30 need to be exchanged, as shown in the picture above. .
Compare 20 with 50 without exchanging, and continue to compare 50 with 80 without exchanging.
d=1: This is the insertion sort mentioned earlier, but the sequence at this time is almost in order, so it brings a great performance improvement to the insertion sort.
Since "Hill sort" is an improved version of "insertion sort", then we have to compare how much faster it can be among 10,000 numbers?
Let’s do a test:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Diagnostics;
namespace ShellSort
{
public class Program
{
static void Main(string[] args)
{
//5次比较
for (int i = 1; i <= 5; i++)
{
List<int> list = new List<int>();
//插入1w个随机数到数组中
for (int j = 0; j < 10000; j++)
{
Thread.Sleep(1);
list.Add(new Random((int)DateTime.Now.Ticks).Next(10000, 1000000));
}
List<int> list2 = new List<int>();
list2.AddRange(list);
Console.WriteLine("\n第" + i + "次比较:");
Stopwatch watch = new Stopwatch();
watch.Start();
InsertSort(list);
watch.Stop();
Console.WriteLine("\n插入排序耗费的时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + string.Join(",", list.Take(10).ToList()));
watch.Restart();
ShellSort(list2);
watch.Stop();
Console.WriteLine("\n希尔排序耗费的时间:" + watch.ElapsedMilliseconds);
Console.WriteLine("输出前十个数:" + string.Join(",", list2.Take(10).ToList()));
}
}
///<summary>
/// 希尔排序
///</summary>
///<param name="list"></param>
static void ShellSort(List<int> list)
{
//取增量
int step = list.Count / 2;
while (step >= 1)
{
//无须序列
for (int i = step; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - step; j >= 0 && temp < list[j]; j = j - step)
{
list[j + step] = list[j];
}
list[j + step] = temp;
}
step = step / 2;
}
}
///<summary>
/// 插入排序
///</summary>
///<param name="list"></param>
static void InsertSort(List<int> list)
{
//无须序列
for (int i = 1; i < list.Count; i++)
{
var temp = list[i];
int j;
//有序序列
for (j = i - 1; j >= 0 && temp < list[j]; j--)
{
list[j + 1] = list[j];
}
list[j + 1] = temp;
}
}
}
}The screenshot is as follows:
 I hope you can see it The sorting has been optimized a lot. In the w-level sorting, the difference is more than 70 times.
I hope you can see it The sorting has been optimized a lot. In the w-level sorting, the difference is more than 70 times.
Personally feel that the sorting that we can easily understand is basically O (n^2), and the sorting that is more difficult to understand is basically O(n^2) It is N(LogN), so merge sorting is also difficult to understand, especially when it comes to writing the code
. It took me an entire afternoon to figure it out, hehe.
First look at the picture:
 There are two things to do in merge sort:
There are two things to do in merge sort:
第一: “分”, 就是将数组尽可能的分,一直分到原子级别。
第二: “并”,将原子级别的数两两合并排序,最后产生结果。
代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace MergeSort
{
class Program
{
static void Main(string[] args)
{
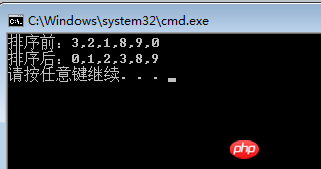
int[] array = { 3, 2, 1, 8, 9, 0 };
MergeSort(array, new int[array.Length], 0, array.Length - 1);
Console.WriteLine(string.Join(",", array));
}
///<summary>
/// 数组的划分
///</summary>
///<param name="array">待排序数组</param>
///<param name="temparray">临时存放数组</param>
///<param name="left">序列段的开始位置,</param>
///<param name="right">序列段的结束位置</param>
static void MergeSort(int[] array, int[] temparray, int left, int right)
{
if (left < right)
{
//取分割位置
int middle = (left + right) / 2;
//递归划分数组左序列
MergeSort(array, temparray, left, middle);
//递归划分数组右序列
MergeSort(array, temparray, middle + 1, right);
//数组合并操作
Merge(array, temparray, left, middle + 1, right);
}
}
///<summary>
/// 数组的两两合并操作
///</summary>
///<param name="array">待排序数组</param>
///<param name="temparray">临时数组</param>
///<param name="left">第一个区间段开始位置</param>
///<param name="middle">第二个区间的开始位置</param>
///<param name="right">第二个区间段结束位置</param>
static void Merge(int[] array, int[] temparray, int left, int middle, int right)
{
//左指针尾
int leftEnd = middle - 1;
//右指针头
int rightStart = middle;
//临时数组的下标
int tempIndex = left;
//数组合并后的length长度
int tempLength = right - left + 1;
//先循环两个区间段都没有结束的情况
while ((left <= leftEnd) && (rightStart <= right))
{
//如果发现有序列大,则将此数放入临时数组
if (array[left] < array[rightStart])
temparray[tempIndex++] = array[left++];
else
temparray[tempIndex++] = array[rightStart++];
}
//判断左序列是否结束
while (left <= leftEnd)
temparray[tempIndex++] = array[left++];
//判断右序列是否结束
while (rightStart <= right)
temparray[tempIndex++] = array[rightStart++];
//交换数据
for (int i = 0; i < tempLength; i++)
{
array[right] = temparray[right];
right--;
}
}
}
}结果图:
ps:
插入排序的时间复杂度为:O(N^2)
希尔排序的时间复杂度为:平均为:O(N^3/2)
最坏:O(N^2)
归并排序时间复杂度为: O(NlogN)
空间复杂度为: O(N)
The above is the detailed content of Detailed explanation of graphic code of C# classic sorting algorithm (Part 2). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Active Directory with C#
Sep 03, 2024 pm 03:33 PM
Active Directory with C#
Sep 03, 2024 pm 03:33 PM
Guide to Active Directory with C#. Here we discuss the introduction and how Active Directory works in C# along with the syntax and example.
 C# Serialization
Sep 03, 2024 pm 03:30 PM
C# Serialization
Sep 03, 2024 pm 03:30 PM
Guide to C# Serialization. Here we discuss the introduction, steps of C# serialization object, working, and example respectively.
 Random Number Generator in C#
Sep 03, 2024 pm 03:34 PM
Random Number Generator in C#
Sep 03, 2024 pm 03:34 PM
Guide to Random Number Generator in C#. Here we discuss how Random Number Generator work, concept of pseudo-random and secure numbers.
 C# Data Grid View
Sep 03, 2024 pm 03:32 PM
C# Data Grid View
Sep 03, 2024 pm 03:32 PM
Guide to C# Data Grid View. Here we discuss the examples of how a data grid view can be loaded and exported from the SQL database or an excel file.
 Patterns in C#
Sep 03, 2024 pm 03:33 PM
Patterns in C#
Sep 03, 2024 pm 03:33 PM
Guide to Patterns in C#. Here we discuss the introduction and top 3 types of Patterns in C# along with its examples and code implementation.
 Factorial in C#
Sep 03, 2024 pm 03:34 PM
Factorial in C#
Sep 03, 2024 pm 03:34 PM
Guide to Factorial in C#. Here we discuss the introduction to factorial in c# along with different examples and code implementation.
 Prime Numbers in C#
Sep 03, 2024 pm 03:35 PM
Prime Numbers in C#
Sep 03, 2024 pm 03:35 PM
Guide to Prime Numbers in C#. Here we discuss the introduction and examples of prime numbers in c# along with code implementation.
 The difference between multithreading and asynchronous c#
Apr 03, 2025 pm 02:57 PM
The difference between multithreading and asynchronous c#
Apr 03, 2025 pm 02:57 PM
The difference between multithreading and asynchronous is that multithreading executes multiple threads at the same time, while asynchronously performs operations without blocking the current thread. Multithreading is used for compute-intensive tasks, while asynchronously is used for user interaction. The advantage of multi-threading is to improve computing performance, while the advantage of asynchronous is to not block UI threads. Choosing multithreading or asynchronous depends on the nature of the task: Computation-intensive tasks use multithreading, tasks that interact with external resources and need to keep UI responsiveness use asynchronous.
