

Detailed explanation of 5 Redis data structures

In this article, we mainly share with you detailed explanations of 5 Redis data structures. We hope that the cases and codes in the article can help everyone.
2.1.1 Global command
1 View all keys key*
2 The total number of keys dbsize (the dbsize command will not calculate the total number of keys Traverse all keys, but directly obtain the total number of keys built into Redis. The time complexity is O(1), while the keys command will traverse all keys, and the time complexity is O(n). When Redis saves a large number of keys, the line Use in the environment is prohibited)
3 Check whether the key exists exists key Returns 1 if it exists, 0 if it does not exist
4 Delete key del key Returns the number of successfully deleted keys , No return 0
5 key over -date Expire Key Seconds TTL commands will return the remaining expiration time key return type, if it does not exist, return none
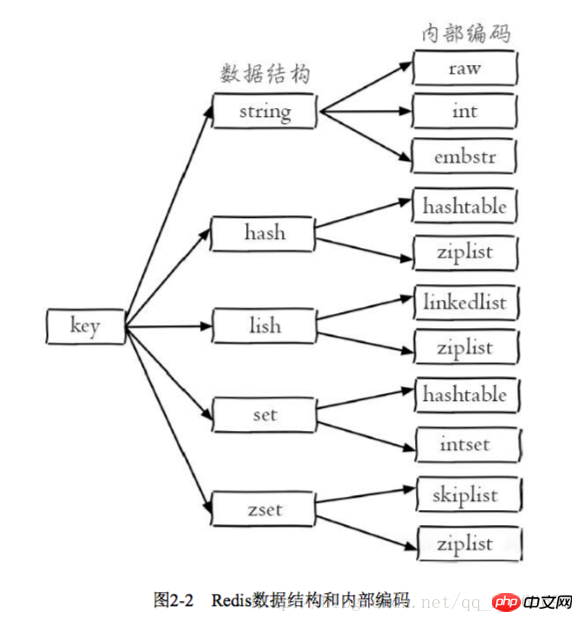
2.1.2 Data structure and internal encoding
Each data structure has its own underlying internal encoding implementation, and it is Multiple implementations, so that Redis will choose the appropriate internal encoding in the appropriate scenario
Each data structure has more than two internal encoding implementations. For example, the list data structure includes linkedlist and ziplist. Internal encoding, you can query the internal encoding through the object encoding command
Redis's design has two benefits: First, it can improve internal coding without affecting external data structures and commands. Second, multiple internal coding implementations can exert their respective advantages in different scenarios. For example, ziplist saves memory, but when there are many list elements, the performance decreases. At this time, Redis will convert the internal implementation of the list type into linkedlist
## all The commands are lined up in a queue and waited for execution, There is no situation where multiple commands are executed simultaneously. The time is about 100 nanoseconds, which is an important basis for Redis to achieve 10,000-level access per second. Second, non-blocking I/O. Redis uses epoll as the implementation of I/O multiplexing technology. In addition, Redis's own event processing model converts the connection, reading, writing, and closing in epoll into events, so as not to waste too much time on network I/O
Three single threads avoid the consumption caused by thread switching and race conditions
Single threads bring several benefits: First, the implementation of data structure and algorithm single threads. Second, single threading avoids the consumption caused by thread switching and race conditions. However, there are requirements for the execution of each command. If the execution time of a certain command is too long, it will cause other commands to be blocked. Redis is a database for fast execution scenarios. Single thread is the core of understanding Redis
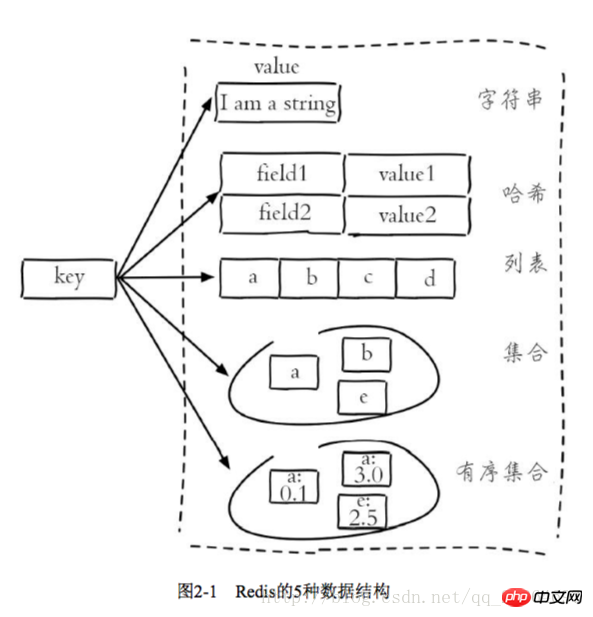
2.2 String
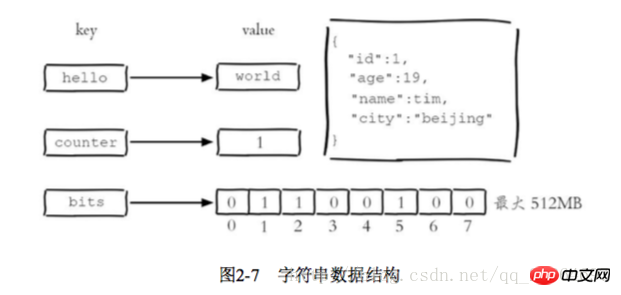
The string type of Redis is the basis for several other types. The value can be a string (simple or complex json, xml), a number (integer, floating point), Binary (pictures, audio, video), the maximum value cannot exceed 512MB
Learning to use batch operations will help improve business processing efficiency, but you must pay attention to the commands sent in each batch operation. Too many commands will cause Redis blocking or network congestion. key
There are three situations in which the result is returned
# key does not exist, the self -increase is 0 according to the value, the return result is 1
and DECR (self -reduced), INCRBY Subtract the specified number), incrbyfloat (increment the floating point number)
2 Uncommonly used commands
1 Append value append key value
2 String length strlen key
3 Set and return the original value getset key value
4 Set the characters at the specified position setrange key offset value
5 Get part of the string getrange key start end
2.2.2 Internal encoding
There are 3 internal encodings for strings: int 8-byte long integer embstr less than A string equal to 39 bytes raw A string larger than 39 bytes. Redis will decide which internal encoding to use based on the type and length of the current value
2.2.3 Typical usage scenarios
. Since Redis has the feature of supporting concurrency, caching can usually play a role in accelerating reading and writing and reducing back-end pressure. :Key name naming method: Business name: Object name: id: [Attribute] as key name
Pseudo code implementation:
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id
value=redis.get(userRedisKey);
UserInfo userInfo;
if(value!=null){
userInfo=deserialize(value)
}else{
userInfo=mysql.get(id)
if(userInfo!=null)
redis.setex(userRedisKey,3600,serizelize(userInfo))
}return userInfo
}
2 Count
long incrVideoCounter(long id){
key="video:playCount:"+id;
return redis.incr(key)
} Development Tips: Anti -cheating, counting according to different dimensions, data durable to the bottom layer data source 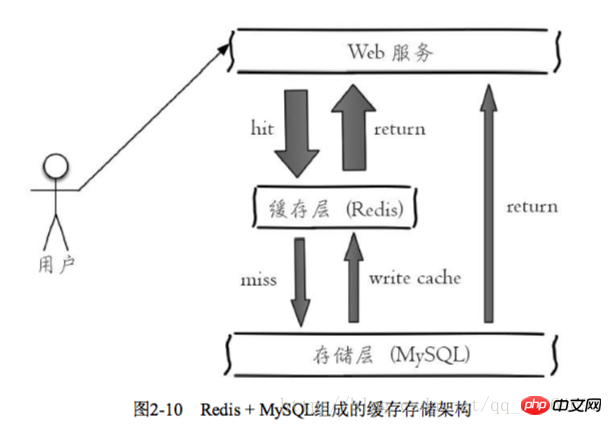

# A similar idea can be used when accessing more than n times within seconds
## 2.3.1 Command
1 Set value
hset key field value
Get the value hget key field Or get field-value hmget key field hmset key field value
6 Determine whether the field exists hexists key field
7 Get all field hkeys key
8 Get all Value HVALS Key
Development Tips: If you must get all the Field-Value, you can use HSCAN to use HSCAN Command, this command will progressively traverse the hash type
2.3 .2 Internal encoding
There are two types of internal encoding:
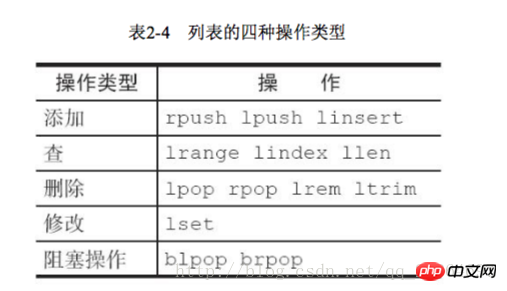
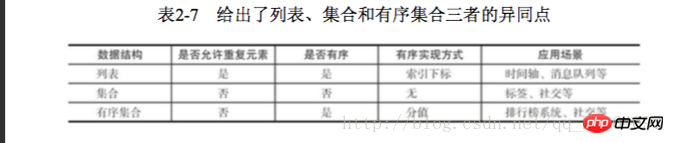
ziplist (compressed list) number of hash elements 哈希类型和关系型数据库两点不同: 1 哈希类型是稀疏的,而关系型数据库是完全结构化的 2 关系型数据库可以做复杂的查询,而Redis去模拟关系型复杂查询开发困难,维护成本高 三种方法缓存用户信息 1 原声字符串类型:每个属性一个键 优点:简单直观,每个属性都支持更新操作 缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差,所以一般不会在生产环境用 2 序列化字符串类型:将用户信息序列化后用一个键保存 优点:简化编程,如果合理的使用序列化可以提高内存的使用效率 缺点:序列化和反序列化有一定的开销,同时每次更新属性,都需要把数据取出来反序列化,更新后再序列化到Redis中 3 哈希类型:每个用户属性使用一对field-value,但是只用一个键保存 优点:简单直观,如果使用合理,可以减少内存空间的使用 缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多的内存 2.4 列表 列表类型用来存储多个有序的字符串,一个列表最多存储2的32次方-1个元素,列表是一种比较灵活的数据结构,它可以灵活的充当栈和队列的角色,在实际开发上有很多应用场景 列表有两个特点:第一、列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表。第二、列表中的元素可以是重复的 2.4.1 命令 1 添加操作 1.1 从右边往左插入元素 rpush key value 1.2 从左往右插入元素 lpush key value 1.3 向某个元素前或者后插入元素 linsert key before|after pivot value 2 查找 1 获取指定范围内的元素列表 lrange key start end Index with two characteristics: First, the index is 0-N-1 from left to right, respectively, from right to left is -1-n, second, LRANDE's END option contains its own , this is not the same as many programming languages that do not include end 2 Get the element lindex key index or or or or or or or or or to to get the element lindex key 3 Delete 1 Popping elements from the left side of the list lpop Key 2 The list is not empty: the client will immediately return 3 2.4.2 Internal encoding There are two internal encodings for list types ziplist (compressed list): When the number of list elements is < list-max-ziplist-entries, and list-max-ziplist-value (64 bytes), Redis will use the internal implementation of the list to reduce memory usage When the conditions of ziplist cannot be met, Redis will use linkedlist as the internal implementation of the list 2.4.3 Usage scenarios using using using using using using ’ s ’s ‐ ‐ off ‐ ‐ using lpush+brpop=Message Queue(Message Queue) 2.5 Collection 1 There are duplicate elements, and the elements in the set are unordered 2.5.1 Commands 1 Operations within the set 1.1 Add elements sadd key element 1.2 Delete element srem key element 1.3 Calculate the number of elements scar key 1.4 Determine whether the element is in the set sismember key element 1.5 Randomly return a specified number of elements from the collection srandmember key 1.6 Randomly pop up elements from the collection spop key 1.7 Get all elements smembers key 2 Operations between sets 1 Find the intersection sinter key of multiple sets... 2 Find The union of multiple sets suinon key.. . Save hashtable( Hash table) When the collection type cannot meet the conditions of intset, Redis will use hashtable as the internal implementation of the collection 2.5.3 Usage scenarios 3 Delete the tags under the user srem user:1:tags tag1 tag5 4 Delete the user under the tag srem tag1:users user:1 5 Calculate the tags of common interest to users been been been 5 Calculating tags of common interest to users =Random item (generate random numbers, such as lottery) spop/srandmember=Random item (generate random numbers, such as lottery) sadd+sinter=Social Graph (social needs) 2.6 Orderly Set An ordered set is to add a score to the set as the basis for sorting 2.6.1 Command 1 In the collection 1Add memberzadd key score memeber nx xx ch returns the number of elements and scores of the ordered set that have changed after this operation, incr: increase the score Ordered sets provide a sorting field compared to sets, but they also produce Including the cost, the time complexity of zadd is O(log(n)), and the time complexity of sadd is O(1) 2 Calculate the number of members scard key 3 Calculate the score of a member zscore key member 4 Calculate the member’s ranking zrank key member 5 Delete the member zrem key member 6 6 Add members' scores Zincrby Key Increment Member 1 intersection zintersstore destination numkeys Key 2 Union zunionstore destionation numkeys key 1 Add User Like ZDD User: RANKING: 2016_03_15 Mike 3 Since rangebyrank user:ranking:2016_03_15 0 9 4 Display user information and user scores # This function can use the user name as a key suffix and save user information in the hash type. Ranking can use two functions, zcore and zrank Management 1 Key rename rename key newkey 2 Randomly return a key randomkey 3 Key expiration -1 The key has no expiration setting Time - 2 The key does not exist expire key itmestamp The key expires after the second-level timestamp timestamp 1 If the key of Expire Key does not exist, the return result is 0 2. If the expiration time is negative, the key will be deleted immediately, just like using the Del command 3 The persist command can clear the expiration time of the key 4 For string type keys, executing the set command will remove the expiration time. This issue is easily overlooked in development 5 Redis does not support the expiration function of internal elements of the secondary data structure. For example, the expiration time cannot be set for an element of this list type. 3 Migrate command used for data migration between redis instances The corresponding commands include hsan, sscan, zcan Progressive traversal can effectively solve the blocking problem that may occur with the keys command. When there are additions and deletions, the new keys cannot be guaranteed to be traversed to 2.7.3 Database management 1 Switch database select dbIndex 2.8 Review of the end of this chapter The above is the detailed content of Detailed explanation of 5 Redis data structures. For more information, please follow other related articles on the PHP Chinese website!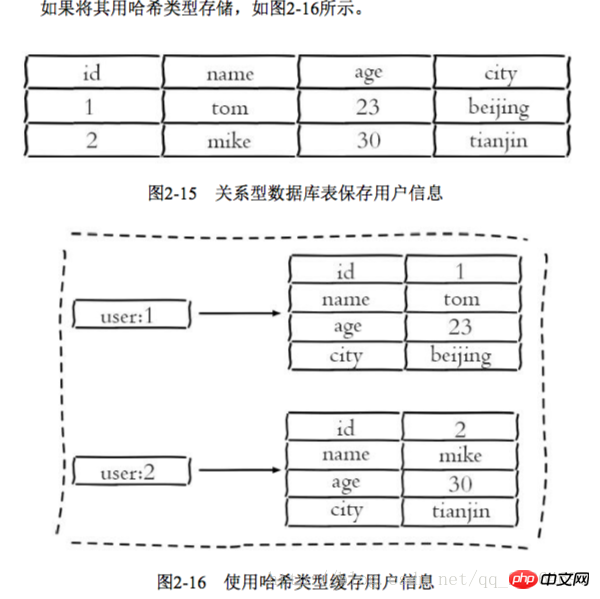
UserInfo getUserInfo(long id){
userRedisKey="user:info:"+id;
userInfoMap=redis.hgetAll(userRedisKey);
userInfoMap userInfo;
if(userInfoMap!=null){
userInfo=transferMapToUserInfo(userInfoMap);
}else{
userInfo=mysql.get(id);
redis.hmset(userRedisKey,tranferUserInfoToMap(userInfo));
redis.expire(userRedisKey,3600);
}
return userInfo;
}

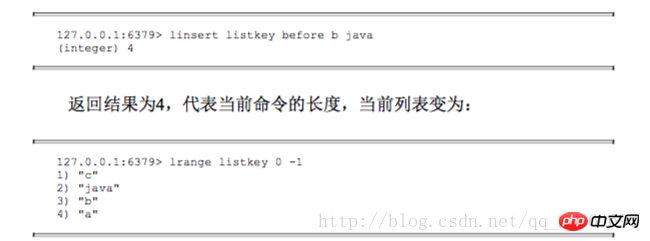
#
# lpsh +ltrim=Capped Collection(limited collection)
2 to add users
## Development Tips: The relationship between the relationship between the user and the label should be executed in one transaction to prevent the data caused by some commands. 
2 episodes operation rooms
2.6.2 Internal encoding
There are two internal encodings for ordered set types:
ziplist (compressed list) When the number of elements in the ordered set is less than the zset-max-ziplist-entries configuration, and the value of each element is less than the zset-max-ziplist-value configuration, Redis will use ziplist As the internal implementation of ordered collections, ziplist can effectively reduce memory usage. Skiplist (skip list) When ziplist conditions are not met, ordered collections will use skiplist as internal implementation, so this At this time, the reading and writing efficiency of ziplist will decrease
2.6.3 Usage scenarios
For example, a video website needs to rank the videos uploaded by users
6 The setex command is used as a set+expire combination. It not only executes atomically, but also reduces the time of network communication. The methods, their implementation methods and usage scenarios are not the same
1 move is used for data migration within Redis
2 dump+restore is implemented in different Redis The function of data migration between instances. This migration is divided into two steps. 1. On the source Redis, the dump command will serialize the key value in the RDB format.
2 On the target Redis, the restore command restores the above serialized value, where the ttl parameter represents the expiration time
## [] represents a character matching a character
## \ x is used to transfer it. Causes blocking
2 Progressive traversal
keys until all keys in the dictionary are traversed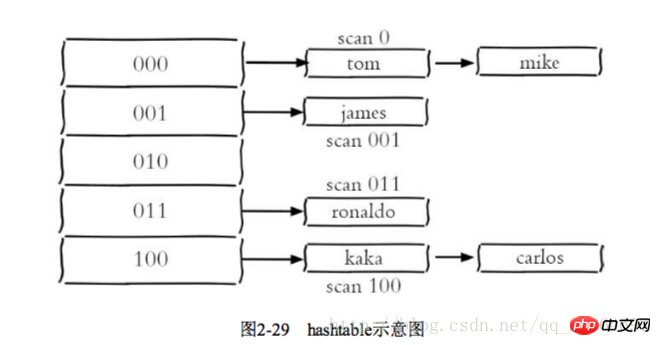 2 flushdb/flushall is used to clear the database, which will cause blocking when there is a lot of data.
2 flushdb/flushall is used to clear the database, which will cause blocking when there is a lot of data.
Related recommendations:
Redis data structure

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1663
1663
 14
1420
52
1313
25
1266
29
1239
24
14
1420
52
1313
25
1266
29
1239
24

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
How to configure Lua script execution time in centos redis
Apr 14, 2025 pm 02:12 PM
On CentOS systems, you can limit the execution time of Lua scripts by modifying Redis configuration files or using Redis commands to prevent malicious scripts from consuming too much resources. Method 1: Modify the Redis configuration file and locate the Redis configuration file: The Redis configuration file is usually located in /etc/redis/redis.conf. Edit configuration file: Open the configuration file using a text editor (such as vi or nano): sudovi/etc/redis/redis.conf Set the Lua script execution time limit: Add or modify the following lines in the configuration file to set the maximum execution time of the Lua script (unit: milliseconds)
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
 How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
How to set the redis expiration policy
Apr 10, 2025 pm 10:03 PM
There are two types of Redis data expiration strategies: periodic deletion: periodic scan to delete the expired key, which can be set through expired-time-cap-remove-count and expired-time-cap-remove-delay parameters. Lazy Deletion: Check for deletion expired keys only when keys are read or written. They can be set through lazyfree-lazy-eviction, lazyfree-lazy-expire, lazyfree-lazy-user-del parameters.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
