

Detailed example of MySQL index leftmost matching principle


Recommended learning: mysql video tutorial
Preparation
For subsequent instructions, we first create a The following table (MySQL5.7) has 5 fields in total (a, b, c, d, e ), where a is the primary key, there is a joint index composed of b, c, d, the storage engine is InnoDB, and three pieces of test data are inserted. It is strongly recommended that you try all the statements in this article in MySQL.
CREATE TABLE `test` ( `a` int NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, `e` int DEFAULT NULL, PRIMARY KEY(`a`), KEY `idx_abc` (`b`,`c`,`d`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (1, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (2, 2, 3, 4, 5); INSERT INTO test(`a`, `b`, `c`, `d`, `e`) VALUES (3, 2, 3, 4, 5);
At this time, if we execute the following SQL statement, do you think the index will be used?
SELECT b, c, d FROM test WHERE d = 2;
If you follow the leftmost matching principle (simply stated as in the joint index, start matching from the leftmost field, if the fields in the condition match the order from left to right in the joint index, then go to the index, Otherwise, it can be simply understood that the joint index of (a, b, c) is equivalent to creating a index, (a, b) index and (a, b, c) index). This sentence obviously does not comply with this rule. Yes, it cannot go through the index, but if we use the EXPLAIN statement to analyze it, we will find a very interesting phenomenon. Its output is as follows using the index.

This is very strange. Has the leftmost matching principle failed? In fact, no, let’s analyze it step by step.
Detailed Theoretical Explanation
Since the InnoDB engine is basically the main engine now, we use InnoDB as an example for the main explanation.
Clustered index and non-clustered index
The bottom layer of MySQL uses B-tree to store the index, and the data is stored on the leaf nodes. For InnoDB, the primary key index and row records are stored together, so it is called a clustered index. Except for the clustered index, all others are called non-clustered indexes (secondary index), including ordinary indexes, unique indexes, etc.
In InnoDB, there is only one clustered index:
- If the table has a primary key, the primary key index is a clustered index;
- If the table does not have a primary key, then The first non-empty unique index will be used as a clustered index;
- Otherwise, a rowid will be implicitly defined as a clustered index.
Let’s take the following figure as an example. Suppose there is a table with three fields: id, name, and age. ID is the primary key, so id is a clustered index, and name is indexed as a non-clustered index. Regarding the index of id and name, there is the following B-tree. You can see that the leaf nodes of the clustered index store the primary key and row records, and the leaf nodes of the non-clustered index store the primary key.
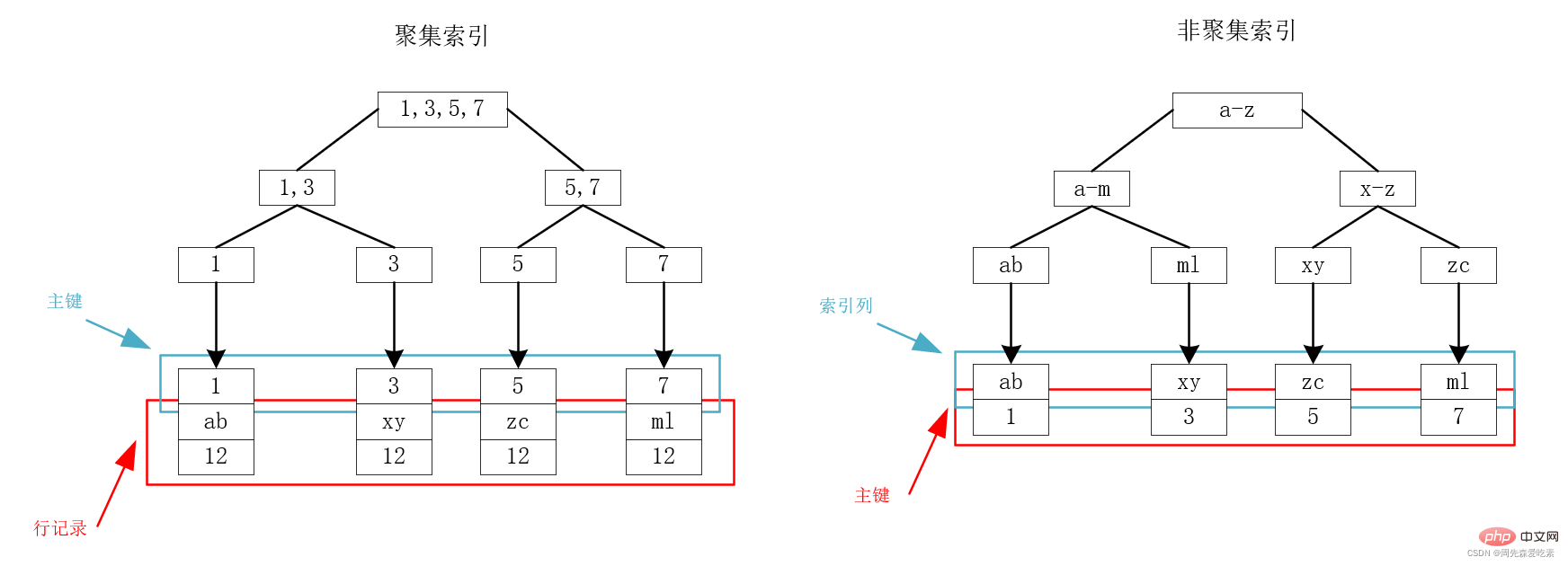
Back to table query
From the above index storage structure, we can see that on the primary key index tree, one-time query can be done through the primary key Find out the data we need very quickly. This is very intuitive, because the primary key is stored together with the row record. Once the primary key is located, the record containing all the fields that you are looking for is located.
But for non-clustered indexes, as shown in the right picture above, we can see that we need to first find the corresponding primary key according to the index tree where name is located, and then query the desired record through the primary key index tree. This process is called return Table query.
Index coverage
The above table return query will undoubtedly reduce the efficiency of the query, so is there any way to prevent it from returning the table? This is index coverage. The so-called index coverage means that when using this index to query, the data on the leaf nodes of its index tree can cover all the fields you query, so that you can avoid returning the table. Let's go back to the initial example. We established the joint index of (b,c,d), so when the fields we query are in b, c, d, the table will not be returned. The index tree only needs to be viewed once, which is index coverage.
Leftmost matching principle
refers to the index of the leftmost column in the joint index. The same applies to joint indexes on multiple fields. For example, index(a,b,c) joint index is equivalent to creating a single column index, (a,b) joint index, and (a,b,c) joint index.
We can execute the following statements to verify this principle.
EXPLAIN SELECT * FROM test WHERE b = 1;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2;

EXPLAIN SELECT * FROM test WHERE b = 1 and c = 2 and d = 3;

接着,我们尝试一条不符合最左原则的查询,它也如图预期一样,走了全表扫描。
EXPLAIN SELECT * FROM test WHERE d = 3;

详细规则
我们先来看下面两个语句,他们的输出如下。
EXPLAIN SELECT b, c from test WHERE b = 1 and c = 1; EXPLAIN SELECT b, d from test WHERE d = 1;
id|select_type|table|partitions|type|possible_keys|key |key_len|ref |rows|filtered|Extra | --+-----------+-----+----------+----+-------------+-------+-------+-----------+----+--------+-----------+ 1|SIMPLE |test | |ref |idx_bcd |idx_bcd|10 |const,const| 1| 100.0|Using index| i d|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra | --+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+------------------------+ 1|SIMPLE |test | |index|idx_bcd |idx_bcd|15 | | 3| 33.33|Using where; Using index|
显然第一条语句是符合最左匹配的,因此type为ref,但是第二条并不符合最左匹配,但是也不是全表扫描,这是因为此时这表示扫描整个索引树。
具体来看,index 代表的是会对整个索引树进行扫描,如例子中的,列 d,就会导致扫描整个索引树。ref 代表 mysql 会根据特定的算法查找索引,这样的效率比 index 全扫描要高一些。但是,它对索引结构有一定的要求,索引字段必须是有序的。而联合索引就符合这样的要求,联合索引内部就是有序的,你可以理解为order by b,c,d这种排序规则,先根据字段b排序,再根据字段c排序,以此类推。这也解释了,为什么需要遵守最左匹配原则,当最左列有序才能保证右边的索引列有序。
因此,我们总结最后的原则为,若符合最左覆盖原则,则走ref这种索引;若不符合最左匹配原则,但是符合覆盖索引(index),就可以扫描整个索引树,从而找到覆盖索引对应的列,避免回表;若不符合最左匹配原则,也不符合覆盖索引(如本例的select *),则需要扫描整个索引树,并且回表查询行记录,此时,查询优化器认为这样两次查找索引树,还不如全表扫描来得快(因为联合索引此时不符合最左匹配原则,要不普通索引查询慢得多),因此,此时会走全表扫描。
补充:为什么要使用联合索引
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w,效率提升可想而知!
推荐学习:mysql视频教程
The above is the detailed content of Detailed example of MySQL index leftmost matching principle. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
When developing an e-commerce website using Thelia, I encountered a tricky problem: MySQL mode is not set properly, causing some features to not function properly. After some exploration, I found a module called TheliaMySQLModesChecker, which is able to automatically fix the MySQL pattern required by Thelia, completely solving my troubles.
 Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
Explain the purpose of foreign keys in MySQL.
Apr 25, 2025 am 12:17 AM
In MySQL, the function of foreign keys is to establish the relationship between tables and ensure the consistency and integrity of the data. Foreign keys maintain the effectiveness of data through reference integrity checks and cascading operations. Pay attention to performance optimization and avoid common errors when using them.
 Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
Compare and contrast MySQL and MariaDB.
Apr 26, 2025 am 12:08 AM
The main difference between MySQL and MariaDB is performance, functionality and license: 1. MySQL is developed by Oracle, and MariaDB is its fork. 2. MariaDB may perform better in high load environments. 3.MariaDB provides more storage engines and functions. 4.MySQL adopts a dual license, and MariaDB is completely open source. The existing infrastructure, performance requirements, functional requirements and license costs should be taken into account when choosing.
