

当前位置: 首页 > webdriver
-

python抢大麦票代码
使用 Python 抢大麦票需要以下步骤:安装 Selenium 和 Requests 库配置 Web 浏览器驱动程序打开大麦网并登录查找目标演出并获取演出信息获取演出时间并获取票务信息解析票务信息,打印区位、价位、座位和余票信息根据具体情况实现抢票逻辑
Python教程 5972024-09-07 10:58:31
-
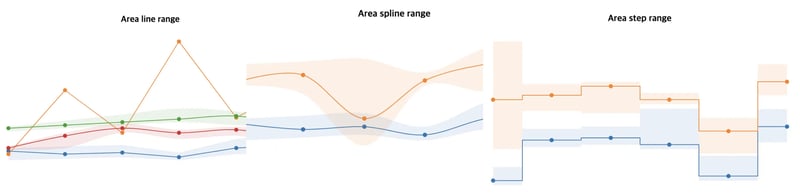
billboardjs elease:新的区域步长图表!
新的v3.13版本今天发布了!此版本包含4个新功能、2个错误修复和工具改进。详细发布信息请查看发行说明:https://github.com/naver/billboard.js/releases/tag/3.13.0什么是新的?面积步长范围图范围类型对于从基线值可视化“范围值”很有用。从这个版本开始,将为变体提供新的“步骤”类型。演示:https://naver.github.io/billboard.js/demo/#chart.funnelchartimportbb,{areastepra
js教程 6422024-08-25 08:42:37
-

使用 Selenium WebDriver 对 Java 函数进行端到端测试
SeleniumWebDriver可用于编写Java函数的端到端测试。步骤包括:添加SeleniumWebDriver依赖项到Java项目中。在Java类中扩展TestCase并编写测试用例。定义WebDriver、导航到应用程序URL、查找页面元素。输入参数、调用函数、验证函数输出。使用TestNG运行测试用例。通过SeleniumWebDriver,您可以自动化Java函数的测试以确保其按照预期工作。
java教程 4852024-08-21 15:15:04
-

java爬虫有什么教程
Java 爬虫是一种用 Java 编程语言编写的软件,用于自动化地从网站提取信息。推荐的 Java 爬虫教程包括:官方 Java 爬虫框架教程初学者指南:使用 Java 进行网络抓取使用 Java 8 Lambda 表达式进行网络抓取使用 HttpClient 和 XPath 进行 Java 爬虫使用 Selenium WebDriver 和 Java 进行爬虫
java教程 4642024-08-20 19:39:45
-

使用住宅代理解决机器人流量挑战:识别、使用和检测指南
您在访问网站时是否曾被要求输入验证码或完成其他验证步骤?这些措施通常是为了防止机器人流量影响网站。机器人流量是由自动化软件而不是真人生成的,这可能会对网站的分析数据、整体安全性和性能产生巨大影响。因此,许多网站使用验证码等工具来识别并阻止机器人流量进入。本文将解释什么是机器人流量、如何通过住宅代理合法使用它以及如何检测恶意机器人流量。什么是机器人流量及其工作原理?在了解机器人流量之前,我们需要先了解什么是人类流量。人流量是指真实用户通过使用网络浏览器与网站产生的交互,例如浏览页面、填写表单、点击
Python教程 10622024-08-19 11:10:28
-

java爬虫框架教程
流行的Java爬虫框架有四个:Apache HttpClient:低级HTTP客户端,提供丰富的HTTP请求操作方法。JSoup:用于解析和操作HTML文档的库,使用简单、支持选择器语法。Selenium:基于Webdriver的框架,允许模拟浏览器的行为。Htmleasy:DOM树解析框架,提供高效的HTML文档处理能力。
java教程 10512024-08-18 18:48:46
-

java爬虫操作教程
答案: Java爬虫是一种自动化工具,用于通过Java语言提取和分析网络数据。具体步骤:设置环境(安装JDK和Selenium WebDriver)创建和定义Java爬虫逻辑使用Selenium WebDriver创建浏览器实例和解析页面内容使用Selenium查找器提取所需数据处理异常和实现重试机制使用并发处理提高效率部署和维护爬虫
java教程 10392024-08-18 18:46:03
-

Java分布式爬虫视频教程
分布式爬虫是将爬取任务分配给多个工作节点共同执行以提高效率的技术,避免单机爬虫的瓶颈问题。Java分布式爬虫包括:选择爬虫框架和分布式框架;搭建任务分配器和工作节点;采用数据存储方案。视频教程可提供详细指南,注意负载均衡、容错机制、数据一致性、反爬虫策略。扩展阅读材料包括分布式爬虫简介、设计模式和Java分布式爬虫库。
java教程 5672024-08-18 18:16:57
-

java爬虫抓取解解析视频教程
本指南提供了使用 Java 爬虫从视频网站抓取和解析视频教程的步骤:准备工作:确定目标网站,安装 Java 开发环境和 Selenium WebDriver。使用 Selenium 获取视频源 URL:打开 WebDriver,导航到目标网站,使用定位方法获取播放器元素,从中提取视频源 URL。发送 HTTP 请求抓取视频:使用 URL 解析视频源 URL,建立 HTTP 连接,获取视频流。写入文件保存视频:创建 File 对象,创建输出流,将视频流写入输出流中。解析视频元数据:使用 Media
java教程 6882024-08-18 18:16:28
-

java 爬虫抓取新闻视频教程
使用 Selenium 和 BeautifulSoup 爬取新闻视频步骤:1. 安装所需环境(如 JDK、Python、Selenium WebDriver、BeautifulSoup);2. 使用 Selenium 驱动程序打开目标新闻网站并提取视频链接;3. (可选)使用 BeautifulSoup 解析 HTML 获取更多视频信息。
java教程 7642024-08-18 18:04:05
-

python爬虫全套教程js
Python 爬虫需要解析 Js 代码来获取动态加载的数据。解析方法包括:Webdriver:直接执行 Js 代码。Beautiful Soup:通过 lxml 扩展包解析 Js 代码。Selenium:执行 Js 代码并获取页面信息。
Python教程 11072024-08-18 17:34:58
-

Python爬虫selenium库教程
Selenium是一个浏览器自动化库,用于模拟真实用户的操作,处理JavaScript渲染页面,绕过反爬虫措施。它支持多种浏览器,使用方法如下:安装webdriver导入webdriver模块创建webdriver实例浏览页面模拟用户操作退出浏览器
Python教程 4232024-08-18 17:24:41
-

python爬虫高级教程视频
高级爬虫教程为掌握基础爬虫技术的用户提供深入知识和实践指导。推荐的视频教程包括:1. Scrapy官方和Udemy教程;2. Selenium WebDriver官方和Edureka教程;3. BeautifulSoup官方和Coder's Guide教程;4. Lxml官方和GeeksforGeeks教程;5. 多线程和asyncio爬虫教程。教程重点涵盖分布式爬虫、数据提取处理、优化调优、反爬绕过、道德和法律问题。
Python教程 10752024-08-18 17:21:39
-

python爬虫助手使用教程
Python 爬虫助手是一个自动化脚本,用于从网站提取数据。使用该助手需要安装 Python 和 Selenium 库,创建代码文件并导入模块,设置浏览器驱动程序,并创建 Selenium Webdriver 实例。常见用途包括从网站收集数据、自动化表单提交、检测网站更改和进行功能测试。其优点包括自动化任务、强大的提取功能、易用性和跨平台性。
Python教程 7542024-08-18 17:19:33
-

python3.6.5爬虫教程
爬虫是一种用于抓取互联网数据的计算机程序。Python 3.6.5 提供了几个爬虫库,包括 Requests、BeautifulSoup、Selenium 和 Scrapy。创建爬虫步骤:1. 设置目标 URL;2. 使用 Requests 发送 HTTP 请求;3. 使用 BeautifulSoup 解析 HTML 响应;4. 提取所需信息。
Python教程 5682024-08-18 16:49:05

社区问答
-

vue3+tp6怎么加入微信公众号啊
阅读:5095 · 6个月前
-

老师好,当客户登录并立即发送消息,这时候客服又并不在线,这时候发消息会因为touid没有赋值而报错,怎么处理?
阅读:6100 · 7个月前
-
RPC模式
阅读:5106 · 8个月前
-
insert时,如何避免重复注册?
阅读:5886 · 9个月前
-
vite 启动项目报错 不管用yarn 还是cnpm
阅读:6503 · 10个月前















最新文章
-
谷歌浏览器怎么恢复上次关闭的标签页_Chrome标签页恢复技巧
阅读:203 · 3小时前
-
Quark浏览器怎样设置书签同步_Quark浏览器书签同步设置操作指南
阅读:961 · 3小时前
-
谷歌浏览器如何离线安装CRX扩展文件 谷歌浏览器开发者模式安装插件
阅读:406 · 4小时前
-
抖音怎么写标题吸引人_撰写能吸引用户的抖音标题的方法
阅读:928 · 4小时前
-
mcjs网页版一键启动 mcjs免安装版登录入口
阅读:469 · 4小时前
-
小米16 SE 拍照模糊_小米16 SE 相机修复
阅读:389 · 4小时前
-
小米手机运行内存小怎么提升性能_小米手机运行内存小的优化与提速技巧
阅读:221 · 4小时前
-
红果短剧网页版播放入口 红果短剧电脑版官网网址
阅读:666 · 4小时前
-
edge浏览器提示“由你的组织管理”怎么办 Edge浏览器解除组织策略限制的方法
阅读:925 · 4小时前
-
UC浏览器下载文件显示已完成但打不开怎么办 UC浏览器文件修复方法
阅读:580 · 4小时前



