

DeepMind升级Transformer,前向通过FLOPs最多可降一半

引入混合深度,DeepMind 新设计可大幅提升 Transformer 效率。



论文标题:Mixture-of-Depths: Dynamically allocating compute in transformer-based language models 论文地址:https://arxiv.org/pdf/2404.02258.pdf
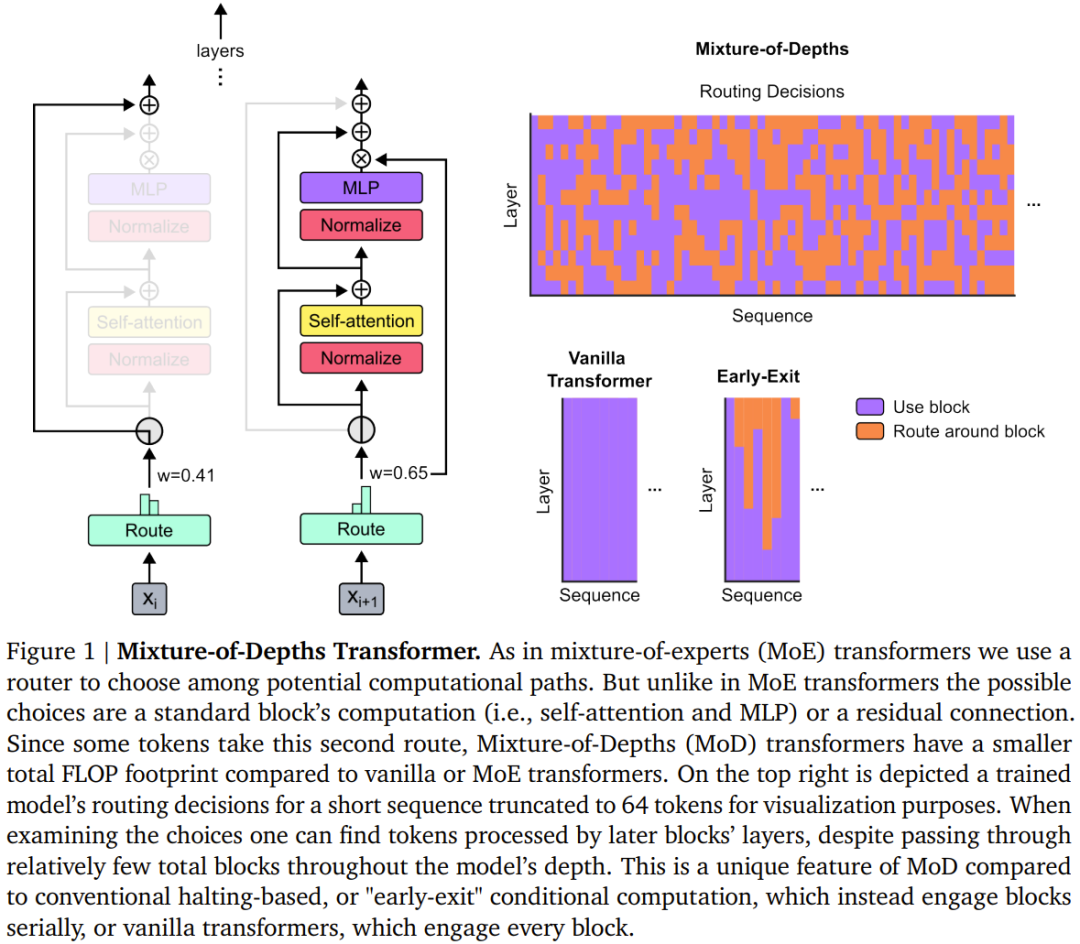
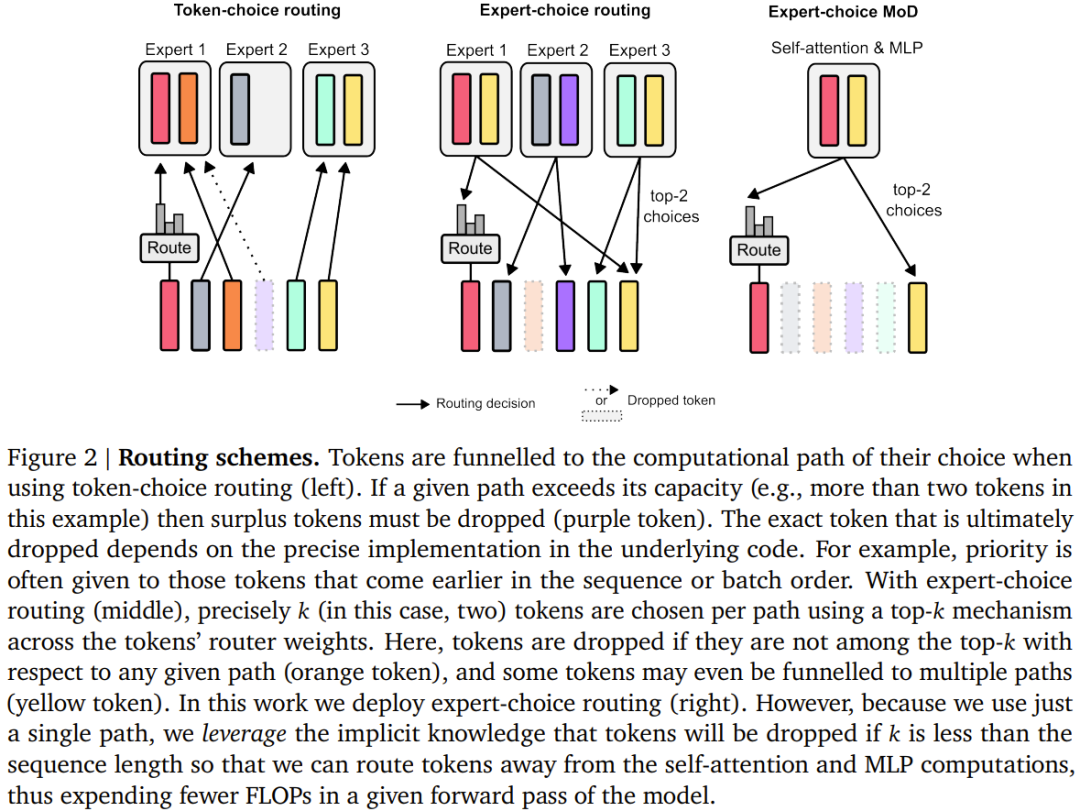
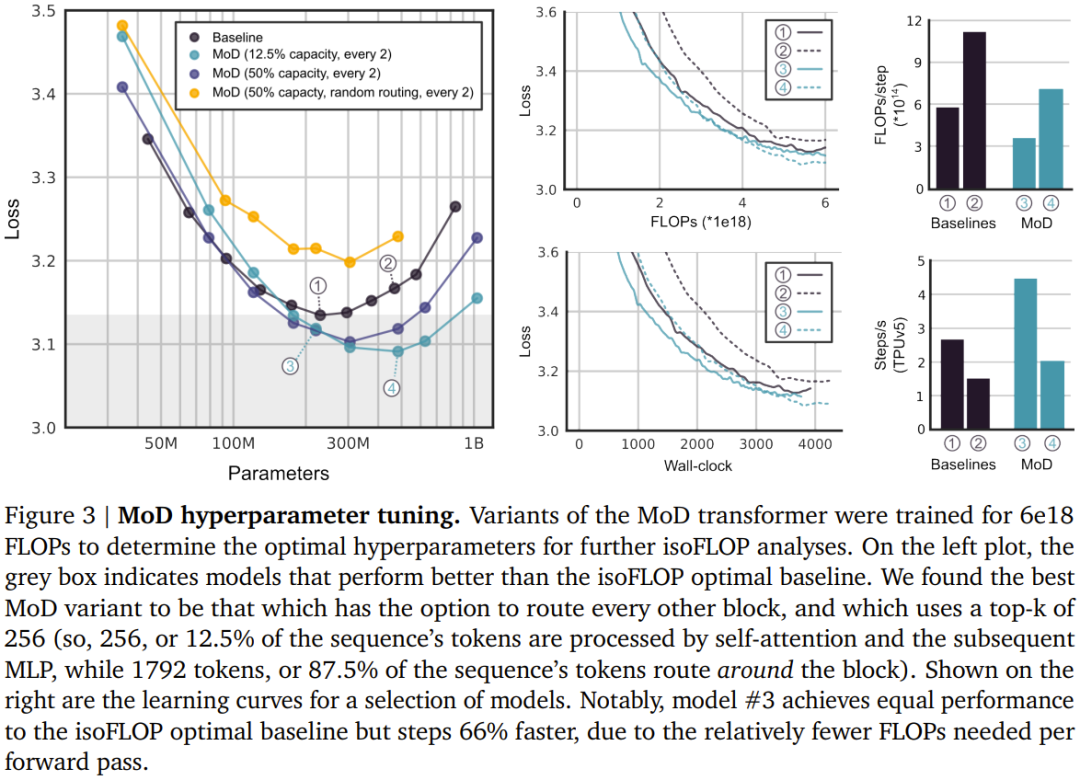
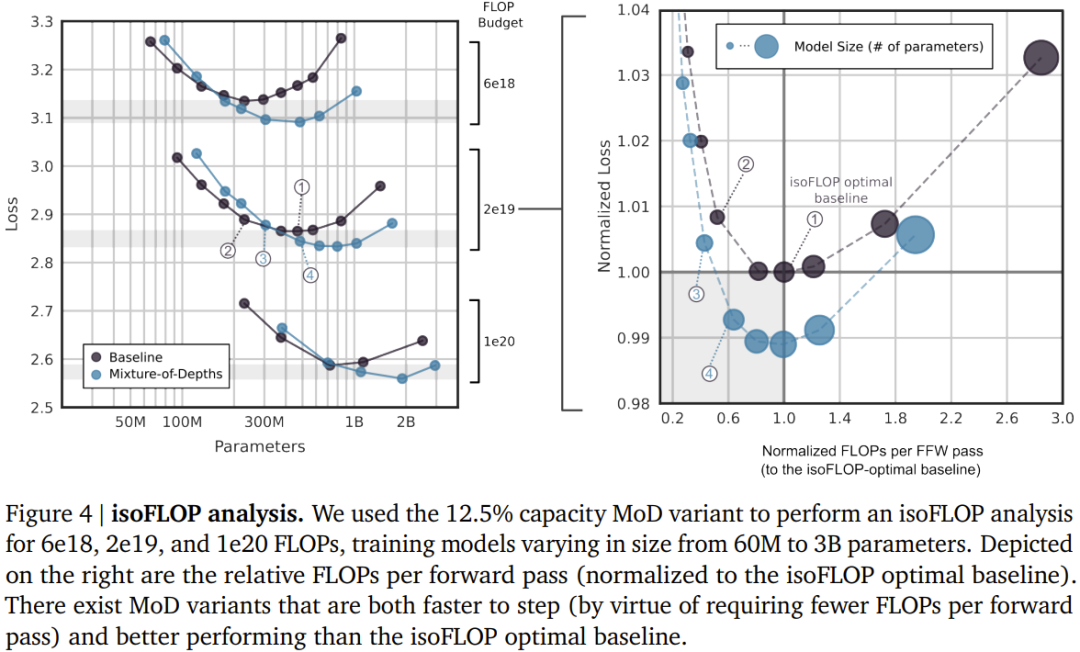
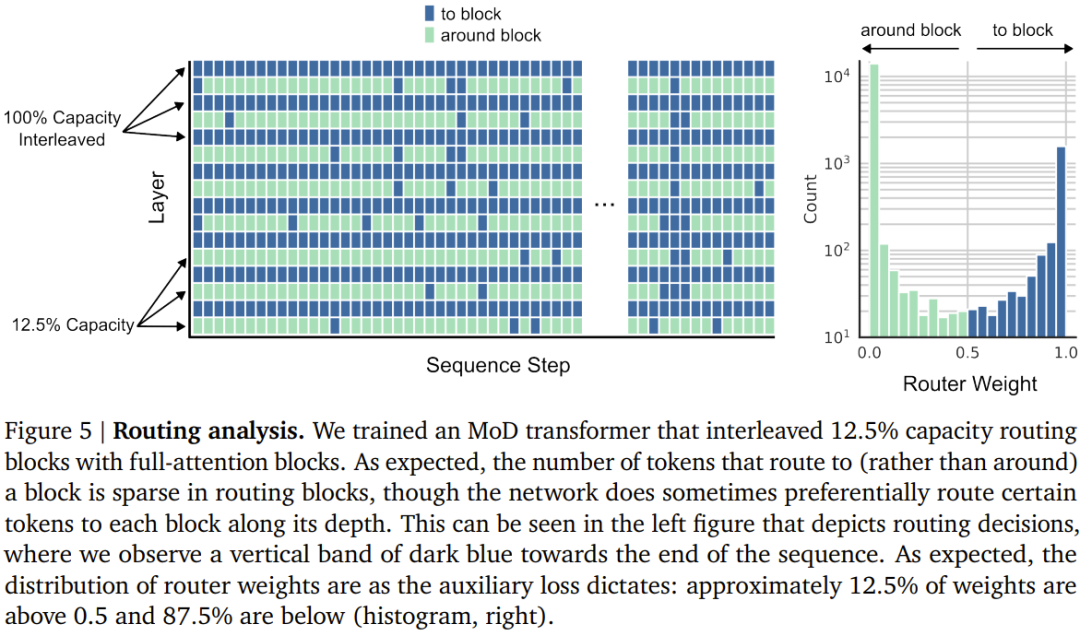
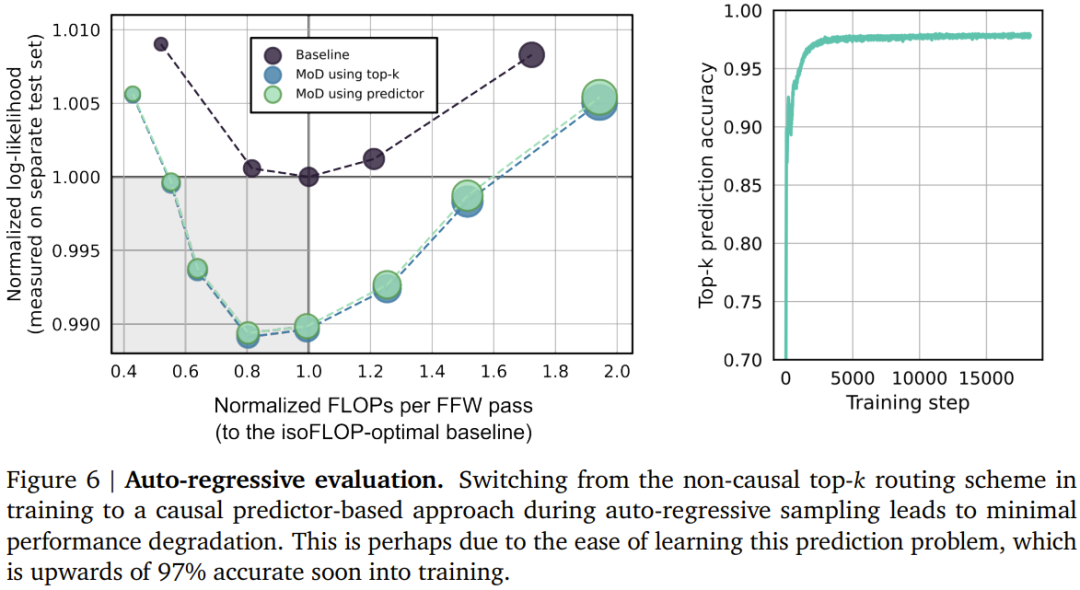
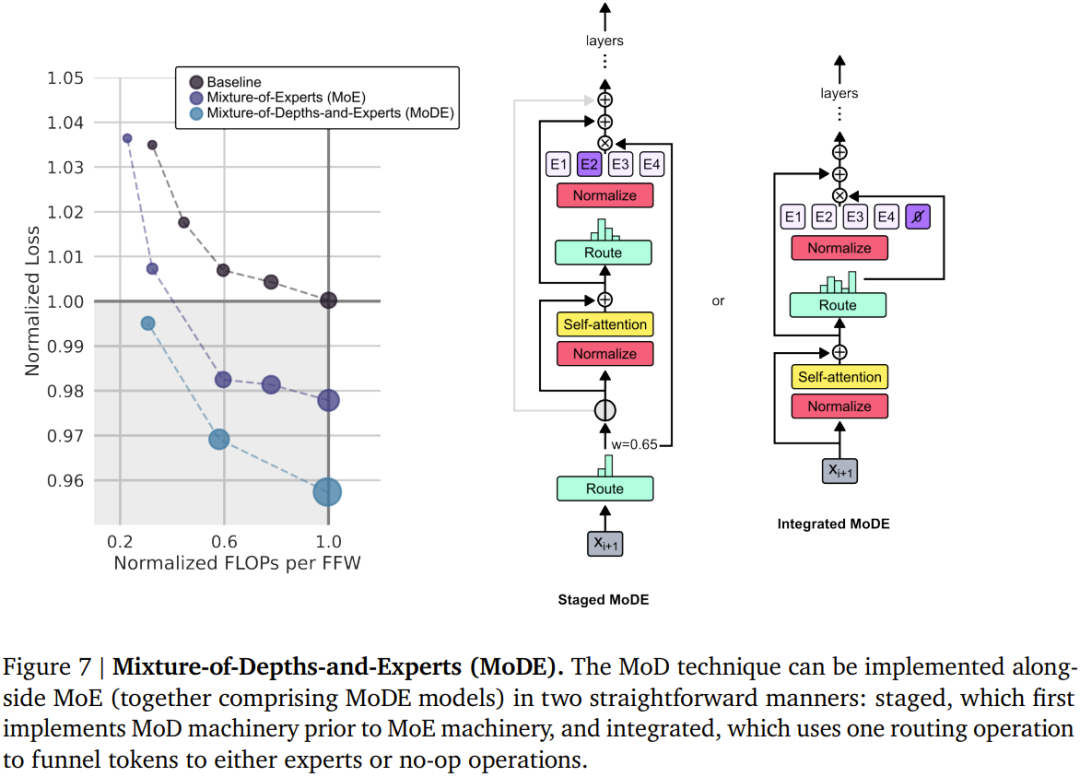
设定一个静态的计算预算,该预算低于等价的常规 Transformer 所需的计算量;做法是限制序列中可参与模块计算(即自注意力模块和后续的 MLP)的 token 数量。举个例子,常规 Transformer 可能允许序列中的所有 token 都参与自注意力计算,但 MoD Transformer 可限定仅使用序列中 50% 的 token。 针对每个 token,每个模块中都有一个路由算法给出一个标量权重;该权重表示路由对各个 token 的偏好 —— 是参与模块的计算还是绕过去。 在每个模块中,找到最大的前 k 个标量权重,它们对应的 token 会参与到该模块的计算中。由于必定只有 k 个 token 参与到该模块的计算中,因此其计算图和张量大小在训练过程中是静态的;这些 token 都是路由算法认定的动态且与上下文有关的 token。
以上是DeepMind升级Transformer,前向通过FLOPs最多可降一半的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
要通过 Git 下载项目到本地,请按以下步骤操作:安装 Git。导航到项目目录。使用以下命令克隆远程存储库:git clone https://github.com/username/repository-name.git
 git怎么更新代码
Apr 17, 2025 pm 04:45 PM
git怎么更新代码
Apr 17, 2025 pm 04:45 PM
更新 git 代码的步骤:检出代码:git clone https://github.com/username/repo.git获取最新更改:git fetch合并更改:git merge origin/master推送更改(可选):git push origin master
 git commit怎么用
Apr 17, 2025 pm 03:57 PM
git commit怎么用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一种命令,将文件变更记录到 Git 存储库中,以保存项目当前状态的快照。使用方法如下:添加变更到暂存区域编写简洁且信息丰富的提交消息保存并退出提交消息以完成提交可选:为提交添加签名使用 git log 查看提交内容
 git怎么合并代码
Apr 17, 2025 pm 04:39 PM
git怎么合并代码
Apr 17, 2025 pm 04:39 PM
Git 代码合并过程:拉取最新更改以避免冲突。切换到要合并的分支。发起合并,指定要合并的分支。解决合并冲突(如有)。暂存和提交合并,提供提交消息。
 如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
在开发一个电商网站时,我遇到了一个棘手的问题:如何在大量商品数据中实现高效的搜索功能?传统的数据库搜索效率低下,用户体验不佳。经过一番研究,我发现了Typesense这个搜索引擎,并通过其官方PHP客户端typesense/typesense-php解决了这个问题,大大提升了搜索性能。
 git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
解决 Git 下载速度慢时可采取以下步骤:检查网络连接,尝试切换连接方式。优化 Git 配置:增加 POST 缓冲区大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。尝试使用不同的 Git 客户端(如 Sourcetree 或 Github Desktop)。检查防火
 git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
要删除 Git 仓库,请执行以下步骤:确认要删除的仓库。本地删除仓库:使用 rm -rf 命令删除其文件夹。远程删除仓库:导航到仓库设置,找到“删除仓库”选项,确认操作。
 git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代码?用 git fetch 从远程仓库拉取最新更改。用 git merge origin/<远程分支名称> 将远程变更合并到本地分支。解决因合并产生的冲突。用 git commit -m "Merge branch <远程分支名称>" 提交合并更改,应用更新。
