

别等OpenAI了,全球首个类Sora抢先开源!所有训练细节/模型权重全公开,成本仅1万美元

就在不久前,OpenAI Sora凭借其惊人的视频生成效果迅速走红,凸显出与其他文生视频模型的差异,并成为全球瞩目的焦点。
继2周前推出成本直降46%的Sora训练推理复现流程后,Colossal-AI团队全面开源全球首个类Sora架构视频生成模型「Open-Sora 1.0」——涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球AI热爱者共同推进视频创作的新纪元。
Open-Sora开源地址:https://github.com/hpcaitech/Open-Sora
先睹为快,我们先看一段由Colossal-AI团队发布的「Open-Sora 1.0」模型生成的都市繁华掠影视频。

Open-Sora 1.0生成的都市繁华掠影
这仅仅是Sora复现技术冰山的一角,关于以上文生视频的模型架构、训练好的模型权重、复现的所有训练细节、数据预处理过程、demo展示和详细的上手教程,Colossal-AI团队已经全面免费开源在GitHub。
新智元第一时间联系了该团队,获悉他们将持续更新Open-Sora相关解决方案和最新动态。感兴趣的朋友可保持关注Open-Sora的开源社区。
全面解读Sora复现方案
接下来,我们将深入解读Sora复现方案的多个关键维度,包括模型架构设计、训练复现方案、数据预处理、模型生成效果展示以及高效训练优化策略。

模型架构设计
模型采用了目前火热的Diffusion Transformer(DiT)[1]架构。
作者团队以同样使用DiT架构的高质量开源文生图模型PixArt-α [2]为基座,在此基础上引入时间注意力层,将其扩展到了视频数据上。
具体来说,整个架构包括一个预训练好的VAE,一个文本编码器,和一个利用空间-时间注意力机制的STDiT(Spatial Temporal Diffusion Transformer)模型。
其中,STDiT 每层的结构如下图所示。它采用串行的方式在二维的空间注意力模块上叠加一维的时间注意力模块,用于建模时序关系。
在时间注意力模块之后,交叉注意力模块用于对齐文本的语意。与全注意力机制相比,这样的结构大大降低了训练和推理开销。
与同样使用空间-时间注意力机制的Latte [3]模型相比,STDiT可以更好的利用已经预训练好的图像DiT的权重,从而在视频数据上继续训练。
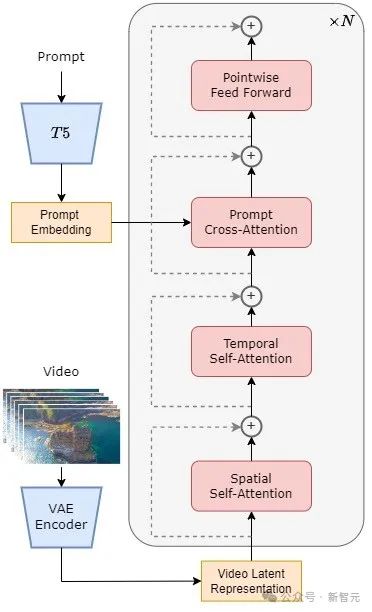
STDiT结构示意图
整个模型的训练和推理流程如下。据了解,在训练阶段首先采用预训练好的Variational Autoencoder(VAE)的编码器将视频数据进行压缩,然后在压缩之后的潜在空间中与文本嵌入(text embedding)一起训练STDiT扩散模型。
在推理阶段,从VAE的潜在空间中随机采样出一个高斯噪声,与提示词嵌入(prompt embedding)一起输入到STDiT中,得到去噪之后的特征,最后输入到VAE的解码器,解码得到视频。

模型的训练流程
训练复现方案
我们向该团队了解到,Open-Sora的复现方案参考了Stable Video Diffusion(SVD)[3]工作,共包括三个阶段,分别是:
1. 大规模图像预训练;
2. 大规模视频预训练;
3. 高质量视频数据微调。
每个阶段都会基于前一个阶段的权重继续训练。相比于从零开始单阶段训练,多阶段训练通过逐步扩展数据,更高效地达成高质量视频生成的目标。

训练方案三阶段
第一阶段:大规模图像预训练
第一阶段通过大规模图像预训练,借助成熟的文生图模型,有效降低视频预训练成本。
作者团队向我们透露,通过互联网上丰富的大规模图像数据和先进的文生图技术,我们可以训练一个高质量的文生图模型,该模型将作为下一阶段视频预训练的初始化权重。
同时,由于目前没有高质量的时空VAE,他们采用了Stable Diffusion [5]模型预训练好的图像VAE。该策略不仅保障了初始模型的优越性能,还显著降低了视频预训练的整体成本。
第二阶段:大规模视频预训练
第二阶段执行大规模视频预训练,增加模型泛化能力,有效掌握视频的时间序列关联。
我们了解到,这个阶段需要使用大量视频数据训练,保证视频题材的多样性,从而增加模型的泛化能力。第二阶段的模型在第一阶段文生图模型的基础上加入了时序注意力模块,用于学习视频中的时序关系。
其余模块与第一阶段保持一致,并加载第一阶段权重作为初始化,同时初始化时序注意力模块输出为零,以达到更高效更快速的收敛。
Colossal-AI团队使用了PixArt-alpha[2]的开源权重作为第二阶段STDiT模型的初始化,以及采用了T5 [6]模型作为文本编码器。同时他们采用了256x256的小分辨率进行预训练,进一步增加了收敛速度,降低训练成本。
第三阶段:高质量视频数据微调
第三阶段对高质量视频数据进行微调,显著提升视频生成的质量。
作者团队提及第三阶段用到的视频数据规模比第二阶段要少一个量级,但是视频的时长、分辨率和质量都更高。通过这种方式进行微调,他们实现了视频生成从短到长、从低分辨率到高分辨率、从低保真度到高保真度的高效扩展。
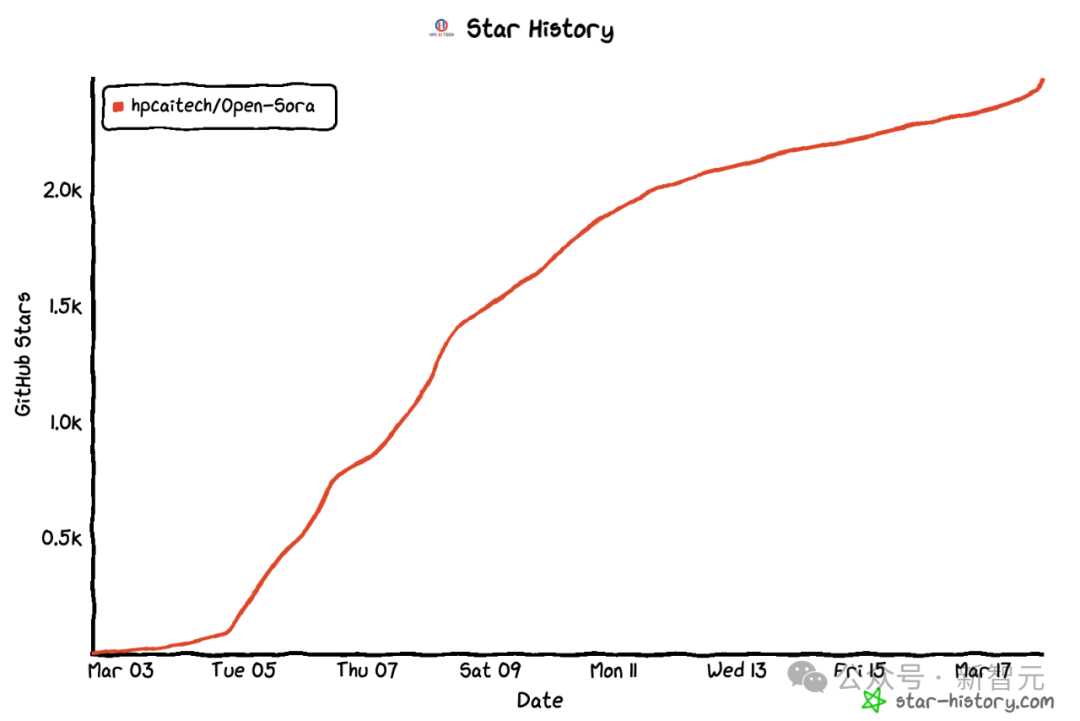
作者团队表示,在Open-Sora的复现流程中,他们使用了64块H800进行训练。
第二阶段的训练量一共是2808 GPU hours,约合7000美元。第三阶段的训练量是1920 GPU hours,大约4500美元。经过初步估算,整个训练方案成功把Open-Sora复现流程控制在了1万美元左右。
数据预处理
为了进一步降低Sora复现的门槛和复杂度,Colossal-AI团队在代码仓库中还提供了便捷的视频数据预处理脚本,让大家可以轻松启动Sora复现预训练,包括公开视频数据集下载,长视频根据镜头连续性分割为短视频片段,使用开源大语言模型LLaVA [7]生成精细的提示词。
作者团队提到他们提供的批量视频标题生成代码可以用两卡3秒标注一个视频,并且质量接近于GPT-4V。最终得到的视频/文本对可直接用于训练。
借助他们在GitHub上提供的开源代码,我们可以轻松地在自己的数据集上快速生成训练所需的视频/文本对,显着降低了启动Sora复现项目的技术门槛和前期准备。

基于数据预处理脚本自动生成的视频/文本对
模型生成效果展示
下面我们来看一下Open-Sora实际视频生成效果。比如让Open-Sora生成一段在悬崖海岸边,海水拍打着岩石的航拍画面。

再让Open-Sora去捕捉山川瀑布从悬崖上澎湃而下,最终汇入湖泊的宏伟鸟瞰画面。

除了上天还能入海,简单输入prompt,让Open-Sora生成了一段水中世界的镜头,镜头中一只海龟在珊瑚礁间悠然游弋。

Open-Sora还能通过延时摄影的手法,向我们展现了繁星闪烁的银河。

如果你还有更多视频生成的有趣想法,可以访问Open-Sora开源社区获取模型权重进行免费的体验。
链接:https://github.com/hpcaitech/Open-Sora
值得注意的是,作者团队在Github上提到目前版本仅使用了400K的训练数据,模型的生成质量和遵循文本的能力都有待提升。例如在上面的乌龟视频中,生成的乌龟多了一只脚。 Open-Sora 1.0也并不擅长生成人像和复杂画面。
作者团队在Github上列举了一系列待做规划,旨在不断解决现有缺陷,提升生成质量。

高效训练加持
除了大幅降低Sora复现的技术门槛,提升视频生成在时长、分辨率、内容等多个维度的质量,作者团队还提供了Colossal-AI加速系统进行Sora复现的高效训练加持。
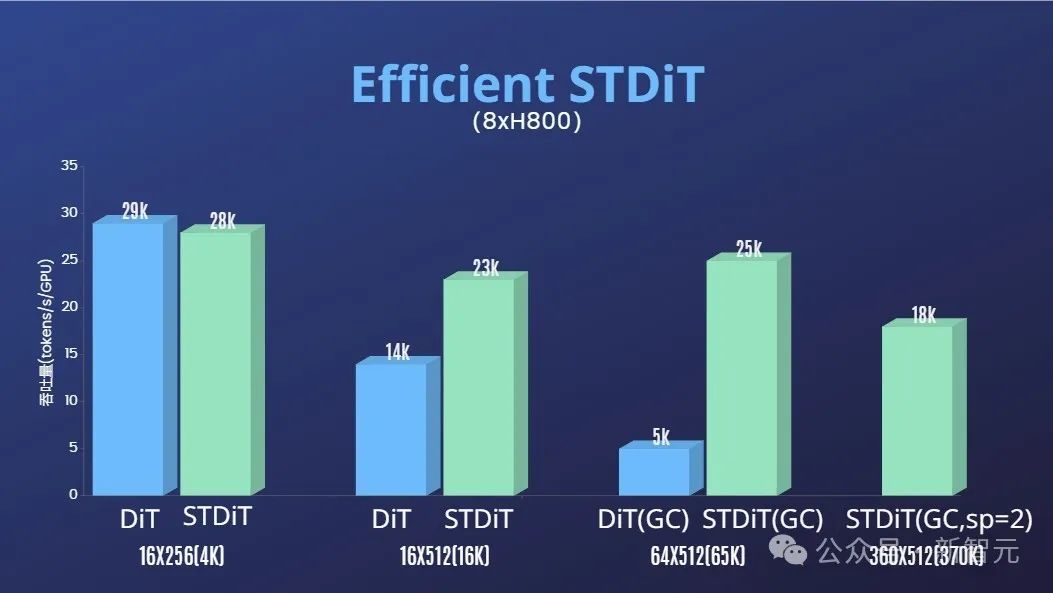
通过算子优化和混合并行等高效训练策略,在处理64帧、512x512分辨率视频的训练中,实现了1.55倍的加速效果。
同时,得益于Colossal-AI的异构内存管理系统,在单台服务器上(8 x H800)可以无阻碍地进行1分钟的1080p高清视频训练任务。

此外,在作者团队的报告中,我们也发现STDiT模型架构在训练时也展现出卓越的高效性。
和采用全注意力机制的DiT相比,随着帧数的增加,STDiT实现了高达5倍的加速效果,这在处理长视频序列等现实任务中尤为关键。
一览Open-Sora模型视频生成效果
欢迎持续关注Open-Sora开源项目:https://github.com/hpcaitech/Open-Sora
作者团队提及,他们将会继续维护和优化Open-Sora项目,预计将使用更多的视频训练数据,以生成更高质量、更长时长的视频内容,并支持多分辨率特性,切实推进AI技术在电影、游戏、广告等领域的落地。
以上是别等OpenAI了,全球首个类Sora抢先开源!所有训练细节/模型权重全公开,成本仅1万美元的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono库可以让你更加精确地控制时间和时间间隔,让我们来探讨一下这个库的魅力所在吧。C 的chrono库是标准库的一部分,它提供了一种现代化的方式来处理时间和时间间隔。对于那些曾经饱受time.h和ctime折磨的程序员来说,chrono无疑是一个福音。它不仅提高了代码的可读性和可维护性,还提供了更高的精度和灵活性。让我们从基础开始,chrono库主要包括以下几个关键组件:std::chrono::system_clock:表示系统时钟,用于获取当前时间。std::chron
 如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
DMA在C 中是指DirectMemoryAccess,直接内存访问技术,允许硬件设备直接与内存进行数据传输,不需要CPU干预。1)DMA操作高度依赖于硬件设备和驱动程序,实现方式因系统而异。2)直接访问内存可能带来安全风险,需确保代码的正确性和安全性。3)DMA可提高性能,但使用不当可能导致系统性能下降。通过实践和学习,可以掌握DMA的使用技巧,在高速数据传输和实时信号处理等场景中发挥其最大效能。
 怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
在C 中处理高DPI显示可以通过以下步骤实现:1)理解DPI和缩放,使用操作系统API获取DPI信息并调整图形输出;2)处理跨平台兼容性,使用如SDL或Qt的跨平台图形库;3)进行性能优化,通过缓存、硬件加速和动态调整细节级别来提升性能;4)解决常见问题,如模糊文本和界面元素过小,通过正确应用DPI缩放来解决。
 C 中的实时操作系统编程是什么?
Apr 28, 2025 pm 10:15 PM
C 中的实时操作系统编程是什么?
Apr 28, 2025 pm 10:15 PM
C 在实时操作系统(RTOS)编程中表现出色,提供了高效的执行效率和精确的时间管理。1)C 通过直接操作硬件资源和高效的内存管理满足RTOS的需求。2)利用面向对象特性,C 可以设计灵活的任务调度系统。3)C 支持高效的中断处理,但需避免动态内存分配和异常处理以保证实时性。4)模板编程和内联函数有助于性能优化。5)实际应用中,C 可用于实现高效的日志系统。
 怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
在C 中测量线程性能可以使用标准库中的计时工具、性能分析工具和自定义计时器。1.使用库测量执行时间。2.使用gprof进行性能分析,步骤包括编译时添加-pg选项、运行程序生成gmon.out文件、生成性能报告。3.使用Valgrind的Callgrind模块进行更详细的分析,步骤包括运行程序生成callgrind.out文件、使用kcachegrind查看结果。4.自定义计时器可灵活测量特定代码段的执行时间。这些方法帮助全面了解线程性能,并优化代码。
 给MySQL表添加和删除字段的操作步骤
Apr 29, 2025 pm 04:15 PM
给MySQL表添加和删除字段的操作步骤
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,删除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段时,需指定位置以优化查询性能和数据结构;删除字段前需确认操作不可逆;使用在线DDL、备份数据、测试环境和低负载时间段修改表结构是性能优化和最佳实践。
 量化交易所排行榜2025 数字货币量化交易APP前十名推荐
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 数字货币量化交易APP前十名推荐
Apr 30, 2025 pm 07:24 PM
交易所内置量化工具包括:1. Binance(币安):提供Binance Futures量化模块,低手续费,支持AI辅助交易。2. OKX(欧易):支持多账户管理和智能订单路由,提供机构级风控。独立量化策略平台有:3. 3Commas:拖拽式策略生成器,适用于多平台对冲套利。4. Quadency:专业级算法策略库,支持自定义风险阈值。5. Pionex:内置16 预设策略,低交易手续费。垂直领域工具包括:6. Cryptohopper:云端量化平台,支持150 技术指标。7. Bitsgap:
 C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中的字符串流如何使用?
Apr 28, 2025 pm 09:12 PM
C 中使用字符串流的主要步骤和注意事项如下:1.创建输出字符串流并转换数据,如将整数转换为字符串。2.应用于复杂数据结构的序列化,如将vector转换为字符串。3.注意性能问题,避免在处理大量数据时频繁使用字符串流,可考虑使用std::string的append方法。4.注意内存管理,避免频繁创建和销毁字符串流对象,可以重用或使用std::stringstream。
