

Redis命令处理过程实例源码分析

本文基于社区版Redis 4.0.8
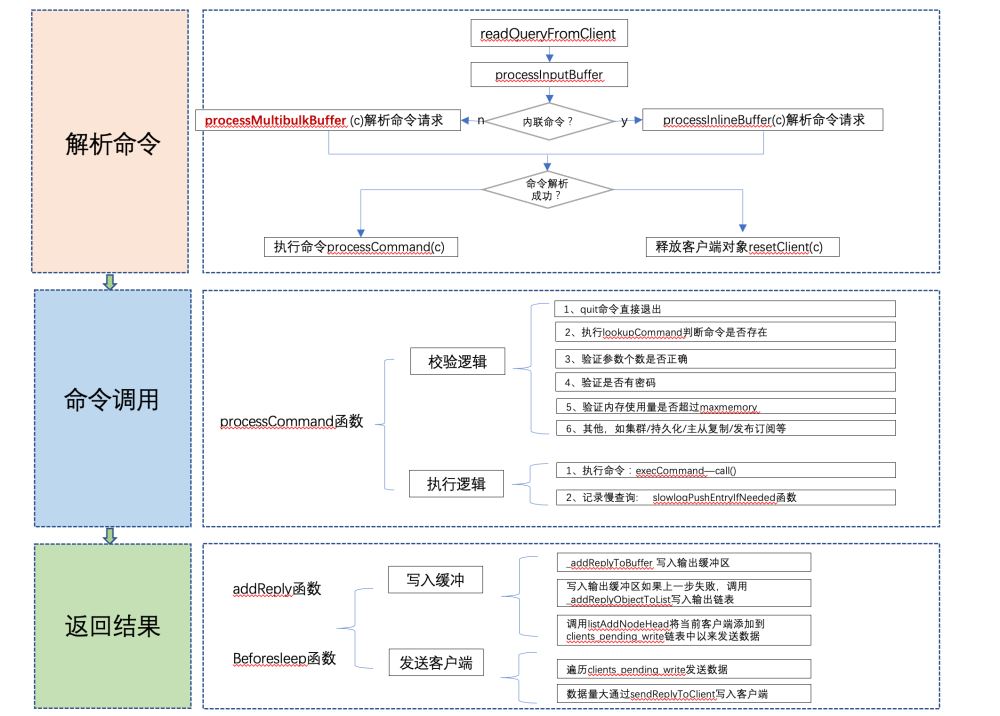
1、命令解析
Redis服务器接收到的命令请求首先存储在客户端对象的querybuf输入缓冲区,然后解析命令请求的各个参数,并存储在客户端对象的argv和argc字段。
客户端解析命令请求的入口函数为readQueryFromClient,会读取socket数据存储到客户端对象的输入缓冲区,并调用函数processInputBuffer解析命令请求。
注:内联命令:使用telnet会话输入命令的方式
void processInputBuffer(client *c) {
......
//循环遍历输入缓冲区,获取命令参数,调用processMultibulkBuffer解析命令参数和长度
while(sdslen(c->querybuf)) {
if (c->reqtype == PROTO_REQ_INLINE) {
if (processInlineBuffer(c) != C_OK) break;//处理telnet方式的内联命令
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != C_OK) break; //解析命令参数和长度暂存到客户端结构体中
} else {
serverPanic("Unknown request type");
}
}
}
//解析命令参数和长度暂存到客户端结构体中
int processMultibulkBuffer(client *c) {
//定位到行尾
newline = strchr(c->querybuf,'\r');
//解析命令请求参数数目,并存储在客户端对象的c->multibulklen字段
serverAssertWithInfo(c,NULL,c->querybuf[0] == '*');
ok = string2ll(c->querybuf+1,newline-(c->querybuf+1),&ll);
c->multibulklen = ll;
pos = (newline-c->querybuf)+2;//记录已解析命令的请求长度resp的长度
/* Setup argv array on client structure */
//分配请求参数存储空间
c->argv = zmalloc(sizeof(robj*)*c->multibulklen);
// 开始循环解析每个请求参数
while(c->multibulklen) {
......
newline = strchr(c->querybuf+pos,'\r');
if (c->querybuf[pos] != '$') {
return C_ERR;
ok = string2ll(c->querybuf+pos+1,newline-(c->querybuf+pos+1),&ll);
pos += newline-(c->querybuf+pos)+2;
c->bulklen = ll;//字符串参数长度暂存在客户端对象的bulklen字段
//读取该长度的参数内容,并创建字符串对象,同时更新待解析参数multibulklen
c->argv[c->argc++] =createStringObject(c->querybuf+pos,c->bulklen);
pos += c->bulklen+2;
c->multibulklen--;
}2、命令调用
当multibulklen的值更新为0时,表示参数解析完成,开始调用processCommand来处理命令,处理命令前有很多校验逻辑,如下:
void processInputBuffer(client *c) {
......
//调用processCommand来处理命令
if (processCommand(c) == C_OK) {
......
}
}
//处理命令函数
int processCommand(client *c) {
//校验是否是quit命令
if (!strcasecmp(c->argv[0]->ptr,"quit")) {
addReply(c,shared.ok);
c->flags |= CLIENT_CLOSE_AFTER_REPLY;
return C_ERR;
}
//调用lookupCommand,查看该命令是否存在
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
if (!c->cmd) {
flagTransaction(c);
addReplyErrorFormat(c,"unknown command '%s'",
(char*)c->argv[0]->ptr);
return C_OK;
//检查用户权限
if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand)
{
addReply(c,shared.noautherr);
//还有很多检查,不一一列举,比如集群/持久化/复制等
/* 真正执行命令 */
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
queueMultiCommand(c);
//将结果写入outbuffer
addReply(c,shared.queued);
}
// 调用execCommand执行命令
void execCommand(client *c) {
call(c,CMD_CALL_FULL);//调用call执行命令
//调用execCommand调用call执行命令
void call(client *c, int flags) {
start = ustime();
c->cmd->proc(c);//执行命令
duration = ustime()-start;
//如果是慢查询,记录慢查询
if (flags & CMD_CALL_SLOWLOG && c->cmd->proc != execCommand) {
char *latency_event = (c->cmd->flags & CMD_FAST) ?
"fast-command" : "command";
latencyAddSampleIfNeeded(latency_event,duration/1000);
//记录到慢日志中
slowlogPushEntryIfNeeded(c,c->argv,c->argc,duration);
//更新统计信息:当前命令执行时间和调用次数
if (flags & CMD_CALL_STATS) {
c->lastcmd->microseconds += duration;
c->lastcmd->calls++;3、返回结果
Redis返回结果并不是直接返回给客户端,而是先写入到输出缓冲区(buf字段)或者输出链表(reply字段)
int processCommand(client *c) {
......
//将结果写入outbuffer
addReply(c,shared.queued);
......
}
//将结果写入outbuffer
void addReply(client *c, robj *obj) {
//调用listAddNodeHead将客户端添加到服务端结构体的client_pending_write链表,以便后续能快速查找出哪些客户端有数据需要发送
if (prepareClientToWrite(c) != C_OK) return;
//然后添加字符串到输出缓冲区
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
//如果添加失败,则添加到输出链表中
_addReplyObjectToList(c,obj);
}addReply函数只是将待发送给客户端的数据暂存在输出链表或者输出缓冲区,那么什么时候将这些数据发送给客户端呢?答案是开启事件循环时,调用的beforesleep函数,该函数专门执行一些不是很费时的操作,如过期键删除,向客户端返回命令回复等
void beforeSleep(struct aeEventLoop *eventLoop) {
......
/* Handle writes with pending output buffers. */
handleClientsWithPendingWrites();
}
//回复客户端命令函数
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
/* 发送客户端数据 */
if (writeToClient(c->fd,c,0) == C_ERR) continue;
/* If there is nothing left, do nothing. Otherwise install
* the write handler. */
//如果数据量很大,一次性没有发送完成,则进行添加文件事件,监听当前客户端socket文件描述符的可写事件即可
if (clientHasPendingReplies(c) &&
aeCreateFileEvent(server.el, c->fd, AE_WRITABLE,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
return processed;以上是Redis命令处理过程实例源码分析的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
在CentOS系统上,您可以通过修改Redis配置文件或使用Redis命令来限制Lua脚本的执行时间,从而防止恶意脚本占用过多资源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位于/etc/redis/redis.conf。编辑配置文件:使用文本编辑器(例如vi或nano)打开配置文件:sudovi/etc/redis/redis.conf设置Lua脚本执行时间限制:在配置文件中添加或修改以下行,设置Lua脚本的最大执行时间(单位:毫秒)
 redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通过以下步骤管理和操作 Redis:连接到服务器,指定地址和端口。使用命令名称和参数向服务器发送命令。使用 HELP 命令查看特定命令的帮助信息。使用 QUIT 命令退出命令行工具。
 redis计数器怎么实现
Apr 10, 2025 pm 10:21 PM
redis计数器怎么实现
Apr 10, 2025 pm 10:21 PM
Redis计数器是一种使用Redis键值对存储来实现计数操作的机制,包含以下步骤:创建计数器键、增加计数、减少计数、重置计数和获取计数。Redis计数器的优势包括速度快、高并发、持久性和简单易用。它可用于用户访问计数、实时指标跟踪、游戏分数和排名以及订单处理计数等场景。
 redis过期策略怎么设置
Apr 10, 2025 pm 10:03 PM
redis过期策略怎么设置
Apr 10, 2025 pm 10:03 PM
Redis数据过期策略有两种:定期删除:定期扫描删除过期键,可通过 expired-time-cap-remove-count、expired-time-cap-remove-delay 参数设置。惰性删除:仅在读取或写入键时检查删除过期键,可通过 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 参数设置。
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
