

单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具

ChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。
正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。
这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spaces of the week)。

△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Image to 3D技术,受到了广泛关注
现行beta版本生成的3D模型,能够直接连同PBR材质下载到本地。不仅效果不错,更重要的是免费可玩。有网友惊呼:
有够酷的,感觉能很便捷地生成自己的数字孪生了。

由此吸引不少网友纷纷试用并贡献脑洞。有人拿这款产品和ControlNet结合,发现效果细腻写实到有些出乎意料。
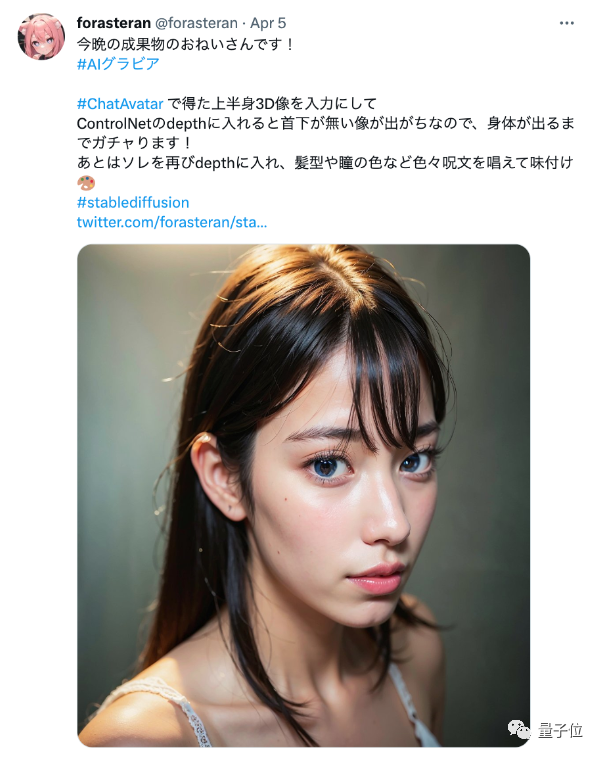
这款使用起来几乎零门槛的Text-to-3D工具名叫ChatAvatar,由国内AI初创公司影眸科技团队打造。
据了解,这是全球首款Production-Ready的Text to 3D产品,通过简单的文本,例如一个明星的名字、或是某个想要的人物长相,就能生成影视级的3D超写实数字人资产。
效率也非常高,平均仅需30秒,就能做出一张以假乱真的脸——甚至是你自己的。
未来,生成领域还将拓展到其他三维资产。
并且该模型带有规整的拓扑、带有4k分辨率的PBR材质,同时带有绑定,可以直接接入Unity、Unreal Engine和Maya等制作引擎的生产管线中。
所以,ChatAvatar到底是怎样一个3D生成工具?背后究竟用到了什么技术?
30秒完成一次“画皮”
亲身体验ChatAvatar的玩法发现,可以说是真·零门槛。
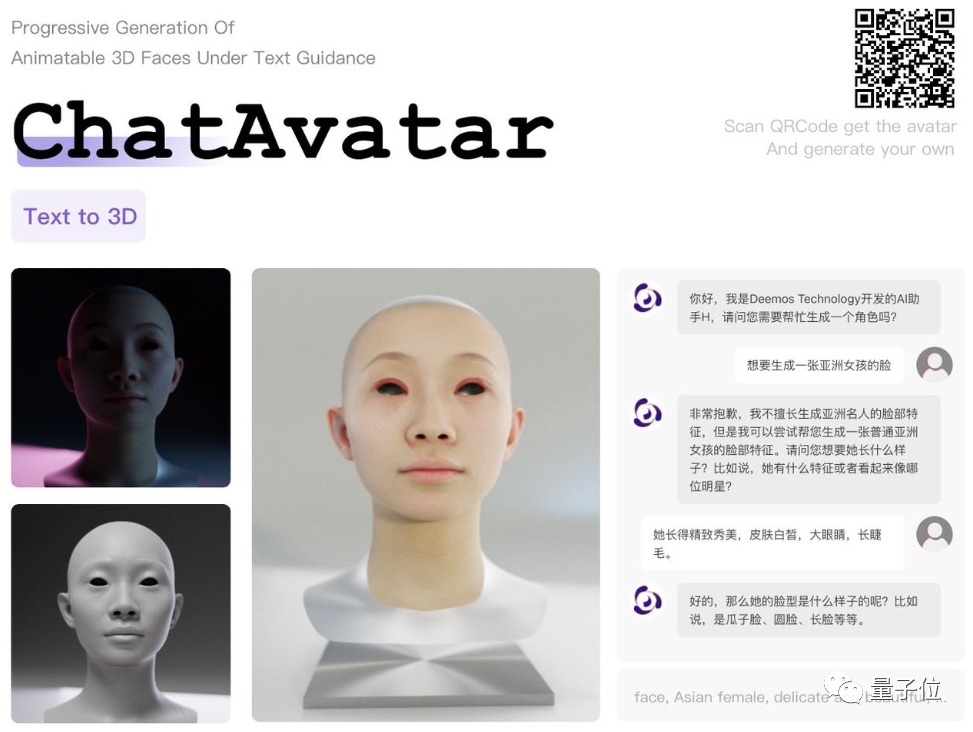
具体而言,只需以对话的形式,在官网上用大白话向ChatBot描述自己的需求,就能按需生成3D人脸,并覆盖一张贴合模型的真实“人皮”。
对话全流程里,根据用户需求,ChatBot会进行引导,尽可能细节地了解用户对所需模型的想法。
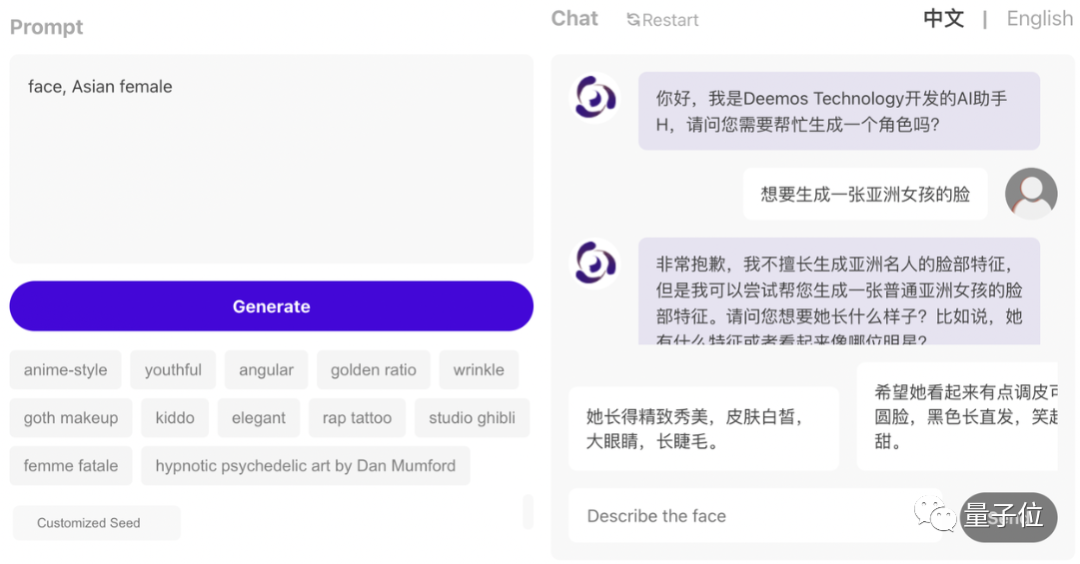
体验过程中,我们向ChatBot描述了这样一个想要生成的3D形象:
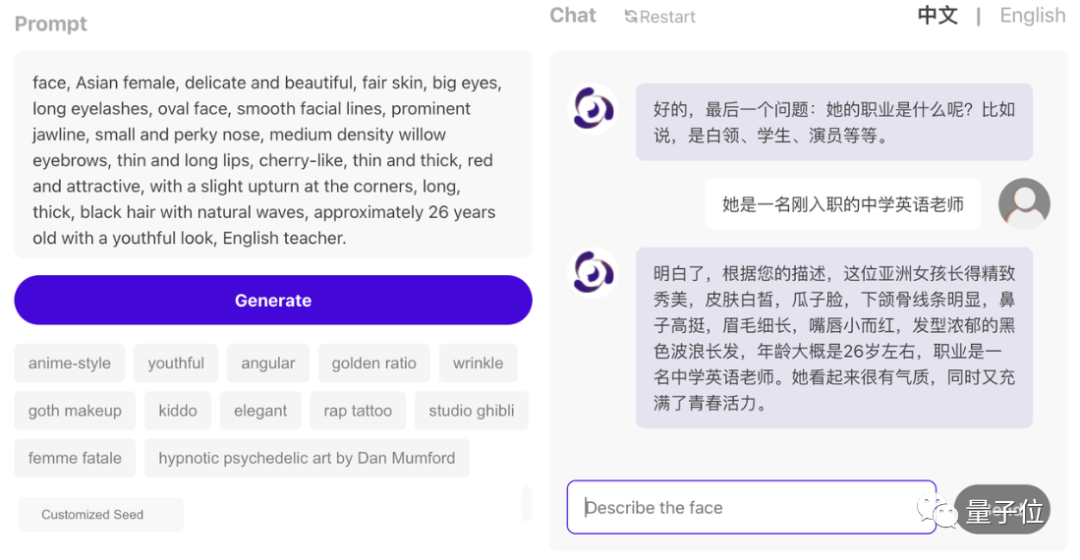
点击左侧的Generate按钮,平均10s不到,屏幕上就出现根据描述生成的9种不同3D人脸的初始雏形。
随意选择其中一种后,会基于选择继续优化模型和材质,最后出现覆盖皮肤后的模型渲结果,并展现不同光影下的渲染效果——这些渲染在浏览器内实时完成:

用鼠标拖动,还能旋转头部,并放大看更细节的局部效果,毛孔和痘痘都清晰可见:

值得一提的是,如果用户是个提示工程高手,直接在左侧框中输入prompt,同样可以完成生成。
最后,一键下载,就能获得一个可直接接入制作引擎并被驱动的3D数字头部资产:
虽然beta版本还没上线发型功能,但整体而言,最后生成的3D数字人资产与描述内容已经有高匹配度。
官网上还陈列了许多ChatAvatar用户的生成资产,不同人种、不同肤色、不同年龄,喜怒哀乐,美丑胖瘦,各式相貌应有尽有。
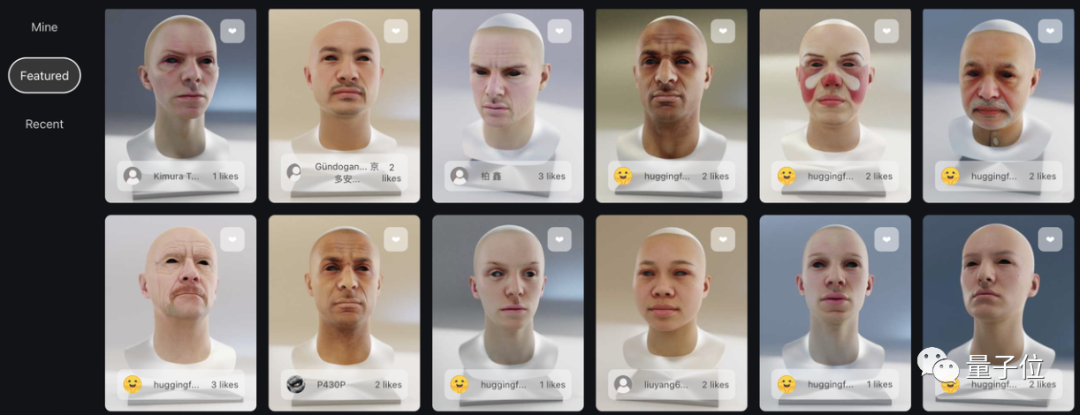
总结一下ChatAvatar这款产品生成3D数字人资产的效果亮点:
首先是使用简便;其次是生成跨度大,且五官可改,还能生成与面部贴合的面具、纹身等,譬如这样:

根据官方宣传片介绍,ChatAvatar甚至可以进一步生成超出人类范畴的角色,如阿凡达等影视作品中的角色:

最重要的是,ChatAvatar解决了3D模型与传统渲染软件存在的兼容性问题。
这意味着,ChatAvatar生成的3D资产可以直接接入游戏和影视生产流程。
当然,在正式接入工业流程之前,首轮公测,ChatAvatar已经吸引了数千名艺术家和专业美术人员参与,推特相关话题受到近百万的浏览与关注。
随随便便一条推文,浏览量都能破50k。
积攒了大批“自来水”不是没有原因,看看3D的爱因斯坦之脸,试问谁不说一句真的很像?

要是和ControlNet结合,生成效果不亚于单反相片直出:

已经有不少用户体验后,开始畅想将这个Text-to-3D工具大规模应用在游戏、影视等工业应用上了。
据了解,用户反馈会成为ChatAvatar团队快速迭代和更新的重要依据,形成数据飞轮,以便及时提供更加完整和贴近需求的功能。
事实上,对于此前的3D行业设计师或公司来说,大部分AI文字转3D应用并非效果不好,但实际落地到工业设计流程上,还是有不少难度。
这次ChatAvatar能如此出圈,背后究竟有什么技术上的原因?
符合产业要求的3D资产生成,究竟难在哪?
都说AI要替代人类,事实上仅仅就Text-to-3D领域,就并非那么容易替代。
最大的难点,在于让AI生成的东西从标准上符合产业对3D资产的要求。
这里面的产业标准怎么理解?从专业3D美工设计的视角来说,至少有三个方面——
质量、可控性和生成速度。
首先是质量。尤其是对于强调视觉效果的影视、游戏行业来说,要想生成符合管线要求的3D资产,拓扑规整度、纹理贴图的精度等“行业潜规则”,都是AI产品第一道必须迈过去的坎。
以拓扑结构的规整度为例,这里本质上指的是3D资产布线的合理度。
对于3D资产来说,拓扑的规整度,往往直接影响物体的动画效果、修改处理效率和贴图绘制速度:
据行内3D美工设计介绍,手工重拓扑的时间成本往往比制作3D模型本身更高,甚至按倍数以计。这意味着即使AI模型生成的3D资产再炫酷,如果生成的拓扑规整度达不到要求,成本就无法从根本上得到降低。更别提纹理精度。
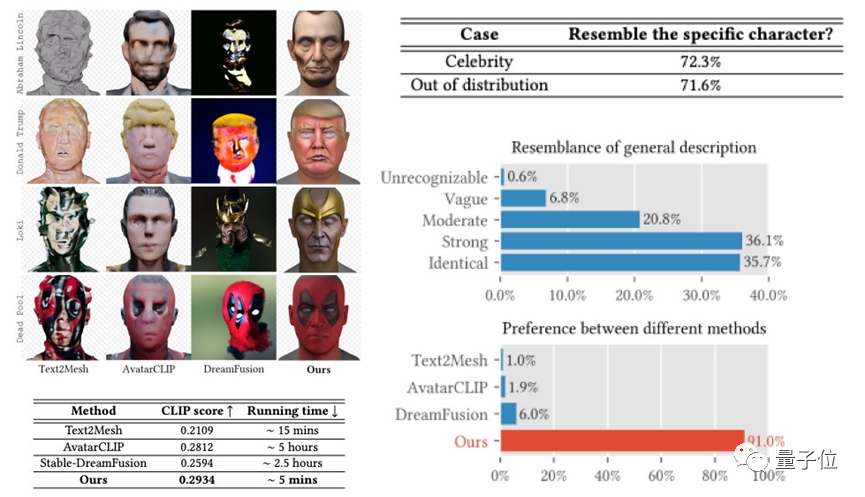
△影眸科技的ChatAvatar项目在生成质量、速度以及标准兼容上相比先前的工作都有明显的提升
以目前游戏、影视行业普遍要求的PBR贴图为例,包含的反射率贴图、法线贴图等一系列贴图,相当于2D图像PSD文件的“图层”,是3D资产流水线生产必不可少的条件之一。
然而,目前AI生成的3D资产往往是一个“整体”,少有能按要求单独生成符合产业环境的PBR贴图的效果。
其次是可控性,对于生成式AI而言,如何让生成的内容更加“可控”,是CG产业对于这项技术提出的又一大要求。
以大众所熟知的2D产业为例,在ControlNet出现之前,2D AIGC行业一直处在一种“半摸黑前进”的状态。
也就是说,AI能生成指定类别的物体画面,却无法生成指定姿态的物体,生成效果全靠提示工程和“玄学”。
而在ControlNet出现后,2D AI图像生成的可控性获得了突飞猛进的提升,然而对于3D AI而言,要想生成对应效果的资产,很大程度上依旧得依靠专业的提示工程。
最后是生成速度。相比3D美工设计而言,AI生成的优势在于速度,然而如果AI渲染的速度和效果无法与人工匹敌的话,那么这项技术依旧无法给产业带来收益。
以当前在AI技术上颇受欢迎的NeRF为例,其产业化落地就面临速度和质量的兼容性难题。
在生成质量较高的情况下,基于NeRF的3D生成往往需要相当漫长的时间;然而如果追求速度,即使是NeRF生成的3D资产便完全无法投入产业使用。
但即使解决了这个问题,如何在不损失精度的前提下让NeRF与传统CG行业的主流引擎兼容仍然是一个巨大的问题。
从上面的产业标准化流程不难发现,大部分AI文本转3D应用落地存在两大瓶颈:
一个是需要手动完成提示工程,对于非AI专业人士、或不了解AI的设计师来说不够友好;另一个是生成的3D资产往往不符合产业标准,即使再好看也无法投入使用。
针对这两点,ChatAvatar给出了两点具体有效的解决方案。
一方面,ChatAvatar实现了除手动输入提示工程外的第二条道路,也是更适合普通人的一条捷径:通过“甲方模式”直接对话描述需求。
团队官方推特介绍称,为了实现这一特性,ChatAvatar基于GPT的能力,开发了一种对话描述转人像特征的方法。
设计师只需要不断和GPT聊天,描述自己想要的“感觉”:

GPT就能自动帮忙完成提示工程,将结果输送给AI:
换而言之,如果说ControlNet是2D行业的“Game Changer”,那么对于3D产业来说,能实现文本转3D的ChatAvatar,无异于行业的游戏规则改变者。
另一方面更为重要,那就是ChatAvatar能完美兼容CG管线,即生成的资产在拓扑结构、可控性和速度上都符合产业要求。
这不仅意味着生成3D资产之后,下载的内容可以直接导入各种后期制作软件进行二次编辑,可控性更强;
同时,生成的模型和高精度材质贴图,还能在后期的渲染中达到极为逼真的渲染效果。
为了实现这样的效果,团队为ChatAvatar自研了一个渐进式3D生成框架DreamFace。
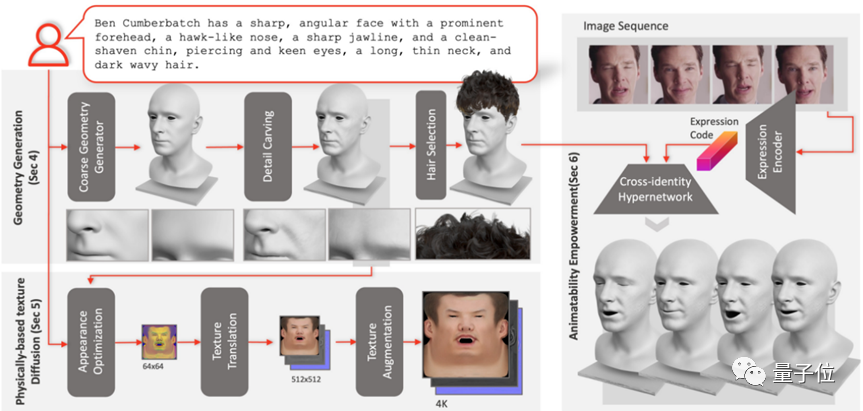
其中的关键,在于训练该模型用的底层数据,即影眸科技基于“穹顶光场”采集到的世界首个大体量、高精度、多表情的人脸高精度数据集。
基于这个数据集,DreamFace可以高效地完成产品级三维资产的生成,即生成的资产带有规整的拓扑、材质,带有绑定。
DreamFace主要包括三个模块:几何体生成,基于物理的材质扩散和动画能力生成。
通过引入外部3D数据库,DreamFace能够直接输出符合CG流程的资产。

△生成的资产驱动渲染的效果
上述两大技术瓶颈的解决,本质上进一步加速了AIGC洪流下,“生成”将取代“搜索”的时代趋势——
影眸团队认为,“生成”将成为新一代数字资产的获取方式。
此前,我们需要找到一张符合需求的图片或者资产时,通常会使用搜索引擎进行查询。
ChatAvatar项目主页上展示的巨大的“搜索框”和整齐的资产卡片,看似搜索引擎,但实际上是一种与搜索截然不同的资产查找方式。
△ChatAvatar项目主页
影眸科技CTO张启煊对此介绍:
以前,如果我们需要一张插图,可能要在多个图库中反复搜索,或是通过Photoshop合成、手绘等较复杂的方式才能得到结果。但在Stable Diffusion等技术出现后,你只需要通过文字描述想要的图像,就能直接生成符合需求的结果。
这对于传统的资产库来说是一个巨大的冲击。而ChatAvatar的目标,正是用3D生成替代传统的搜索式3D资产库。
AIGC领域的下一个前沿热点
ChatGPT一石激起千层浪,进入AI 2.0时代之后,人们的目光也投向包含图像、视频、3D等信息的多模态AI。
仅就3D生成领域而言,无论是影视还是游戏行业,3D内容生产和消费市场已经拥有足够大的规模,但在制作层面却因技术难度遭遇掣肘。
譬如,文本领域大行其道的Transformer,在3D生成领域的使用还相对有限。
去年夏天,当文生图领域因Diffusion Model取得成绩后,人们开始期待文字生成3D有同样惊艳的表现。一旦生成式AI的3D创作技术成熟,VR、视频等的内容创作都将起飞。
△扩散模型Midjourney5.1生成的“梵高风摄影”
事实上,无论是科技巨头还是初创公司,的确都在朝Text-to-3D这个方向暗暗发力。
去年9月,谷歌发布了基于文本提示生成3D模型的FreamFusion,声称不需要3D训练数据,也不需要修改图像扩散模型。紧随其后,Meta也推出可以从文本一键生成视频的Make-A-Video模型。
后来的Text-to-3D的AI模型队伍中,还先后出现了英伟达Magic3D、OpenAI最新开源项目Shap-E等,今年8月将举办的计算机图形顶会SIGGRAPH 2023所展示的论文,也有多篇与Text-to-3D有关。
影眸科技有关文本指导的渐进式3D生成框架DreamFace的论文,就是其中之一。
而ChatAvatar,也是目前为止最集中在3D数字人资产方向的生成式模型产品。
其背后的AI初创公司影眸科技,2020年孵化自上海科技大学MARS实验室,成立后获得奇绩创坛与红杉种子的两轮投资。
公司专注于专注于计算机图形学、生成式AI的研究与产品化。2021年,AIGC还未掀起巨浪之时,公司就已经推出国内首个AIGC ToC绘画应用Wand,产品一度登顶AppStore分区榜首。

而这个颇具前瞻性,且已在业内小有名气的团队,平均年龄只有25岁。
将首个商业化场景具体锚定在数字人后,ChatAvatar是他们乘AIGC东风在该方向的最新进展。
作为一个新推出的产品,ChatAvatar在兼容性、完成度和精度等产品效果层面,都超出了影眸团队预期。然而在吴迪口中,行至此处的过程“很狼狈”。
主要原因不外乎“缺人”一事。目前,影眸已经在多类别3D生成技术上取得了进展,下一步还计划推出“3D生成大模型”。
△影眸科技将于5月上线首个多模态跨平台3D搜索引擎Rodin,打通Sketchfab等多个3D资产平台,支持以文搜3D、以图搜3D甚至以3D搜3D。搜索引擎只是Rodin的初级形态,影眸将把Rodin打造为3D生成大模型。
需要持续向前推进,就需要更多的工程化团队、技术美术和拥抱生成式AI的产品人才加入团队。作为一个以研发为背景主基调的团队,这样的人才仍然紧缺。
“人是万物的尺度,”吴迪表示道,“我们需要更多志同道合的人加入,共同推动3D领域的创新发展。”
可以看到,ChatAvatar背后技术从无到有的搭建,揭示了一家AI初创公司的不断创新;而从这家公司对人才的渴望以小见大,更揭示着AIGC浪潮下,每一个细分领域想要从水下浮出水面的心。
你愿意拥抱生成式AI,成为Text-to-3D领域的Game Changer吗?
以上是单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
ChatGPT 现在允许免费用户使用 DALL-E 3 生成每日限制的图像
Aug 09, 2024 pm 09:37 PM
DALL-E 3 于 2023 年 9 月正式推出,是比其前身大幅改进的型号。它被认为是迄今为止最好的人工智能图像生成器之一,能够创建具有复杂细节的图像。然而,在推出时,它不包括
 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
手机怎么安装chatgpt
Mar 05, 2024 pm 02:31 PM
安装步骤:1、在ChatGTP官网或手机商店上下载ChatGTP软件;2、打开后在设置界面中,选择语言为中文;3、在对局界面中,选择人机对局并设置中文相谱;4、开始后在聊天窗口中输入指令,即可与软件进行交互。
 ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人
Oct 27, 2023 pm 06:00 PM
ChatGPT和Python的完美结合:打造智能客服聊天机器人引言:在当今信息时代,智能客服系统已经成为企业与客户之间重要的沟通工具。而为了提供更好的客户服务体验,许多企业开始转向采用聊天机器人的方式来完成客户咨询、问题解答等任务。在这篇文章中,我们将介绍如何使用OpenAI的强大模型ChatGPT和Python语言结合,来打造一个智能客服聊天机器人,以提高
 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
 LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
写在前面&笔者的个人理解这篇论文致力于解决当前多模态大语言模型(MLLMs)在自动驾驶应用中存在的关键挑战,即将MLLMs从2D理解扩展到3D空间的问题。由于自动驾驶车辆(AVs)需要针对3D环境做出准确的决策,这一扩展显得尤为重要。3D空间理解对于AV来说至关重要,因为它直接影响车辆做出明智决策、预测未来状态以及与环境安全互动的能力。当前的多模态大语言模型(如LLaVA-1.5)通常仅能处理较低分辨率的图像输入(例如),这是由于视觉编码器的分辨率限制,LLM序列长度的限制。然而,自动驾驶应用需
