

大模型精准反哺小模型,知识蒸馏助力提高 AI 算法性能

01 知识蒸馏诞生的背景
来,深度神经网络(DNN)在工业界和学术界都取得了巨大成功,尤其是在 计算机视觉任务 方面。深度学习的成功很大程度上归功于其具有数十亿参数的用于编码数据的可扩展性架构,其训练目标是在已有的训练数据集上建模输入和输出之间的关系,其性能高度依赖于网络的复杂程度及有标注训练数据的数量和质量。
相比于计算机视觉领域的传统算法,大多数基于 DNN 的模型都因为 过参数化 而具备强大的 泛化能力 ,这种泛化能力体现在对于某个问题输入的所有数据上,模型能给出较好的预测结果,无论是训练数据、测试数据,还是属于该问题的未知数据。
在当前深度学习的背景下,算法工程师为了提升业务算法的预测效果,常常会有两种方案:
使用过参数化的更复杂的网络,这类网络学习能力非常强,但需要大量的计算资源来训练,并且推理速度较慢。
集成模型,将许多效果弱一些的模型集成起来,通常包括参数的集成和结果的集成。
这两种方案能显著提升现有算法的效果,但都提升了模型的规模,产生了较大的计算负担,需要的计算和存储资源很大。
在工作中,各种算法模型的最终目的都是要 服务于某个应用 。就像在买卖中我们需要控制收入和支出一样。在工业应用中,除了要求模型要有好的预测以外, 计算资源的使用也要严格控制,不能只考虑结果不考虑效率。在输入数据编码量高的计算机视觉领域,计算资源更显有限,控制算法的资源占用就更为重要。
通常来说,规模较大的模型预测效果更好,但训练时间长、推理速度慢的问题使得模型难以实时部署。尤其是在视频监控、自动驾驶汽车和高吞吐量云端环境等计算资源有限的设备上,响应速度显然不够用。规模较小的模型虽然推理速度较快,但是因为参数量不足,推理效果和泛化性能可能就没那么好。如何权衡大规模模型和小规模模型一直是一个热门话题,当前的解决方法大多是 根据部署环境的终端设备性能选择合适规模的 DNN 模型。
如果我们希望有一个规模较小的模型,能在保持较快推理速度的前提下,达到和大模型相当或接近的效果该如何做到呢?
在机器学习中,我们常常假定输入到输出有一个潜在的映射函数关系,从头学习一个新模型就是输入数据和对应标签中一个 近似 未知的映射函数。在输入数据不变的前提下,从头训练一个小模型,从经验上来看很难接近大模型的效果。为了提升小模型算法的性能,一般来说最有效的方式是标注更多的输入数据,也就是提供更多的监督信息,这可以让学习到的映射函数更鲁棒,性能更好。举两个例子,在计算机视觉领域中,实例分割任务通过额外提供掩膜信息,可以提高目标包围框检测的效果;迁移学习任务通过提供在更大数据集上的预训练模型,显著提升新任务的预测效果。因此 提供更多的监督信息 ,可能是缩短小规模模型和大规模模型差距的关键。
按照之前的说法,想要获取更多的监督信息意味着标注更多的训练数据,这往往需要巨大的成本,那么有没有一种低成本又高效的监督信息获取方法呢?2006 年的文献[1]中指出,可以让新模型近似(approximate)原模型(模型即函数)。因为原模型的函数是已知的,新模型训练时等于天然地增加了更多的监督信息,这显然要更可行。
进一步思考,原模型带来的监督信息可能蕴含着不同维度的知识,这些与众不同的信息可能是新模型自己不能捕捉到的,在某种程度上来说,这对于新模型也是一种“跨域”的学习。
2015年Hinton在论文《Distilling the Knowledge in a Neural Network》[2] 中沿用近似的思想,率先提出“ 知识蒸馏 (Knowledge Distillation, KD)”的概念:可以先训练出一个大而强的模型,然后将其包含的知识转移给小的模型,就实现了“保持小模型较快推理速度的同时,达到和大模型相当或接近的效果”的目的。这其中先训练的大模型可以称之为教师模型,后训练的小模型则被称之为学生模型,整个训练过程可以形象地比喻为“师生学习”。随后几年,涌现了大量的知识蒸馏与师生学习的工作,为工业界提供了更多新的解决思路。目前,KD 已广泛应用于两个不同的领域:模型压缩和知识迁移[3]。

02 Knowledge Distillation
简介
Knowledge Distillation 是一种基于“教师-学生网络”思想的模型压缩方法,由于简单有效,在工业界被广泛应用。其目的是将已经训练好的大模型包含的知识——蒸馏(Distill),提取到另一个小的模型中去。那怎么让大模型的知识,或者说泛化能力转移到小模型身上去呢?KD 论文把大模型对样本输出的概率向量作为软目标(soft targets)提供给小模型,让小模型的输出尽量去向这个软目标靠(原来是往 one-hot 编码上靠),去近似学习大模型的行为。
在传统的硬标签训练过程中,所有负标签都被统一对待,但这种方式把类别间的关系割裂开了。比如说识别手写数字,同是标签为“3”的图片,可能有的比较像“8”,有的比较像“2”,硬标签区分不出来这个信息,但是一个训练良好的大模型可以给出。大模型 softmax 层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。近似学习这一行为使得每个样本给学生网络带来的信息量大于传统的训练方式。
因此,作者在训练学生网络时修改了一下损失函数,让小模型在拟合训练数据的真值(ground truth)标签的同时,也要拟合大模型输出的概率分布。这个方法叫做知识 蒸馏训练 (Knowledge Distillation Training, KD Training)。知识蒸馏过程所用的训练样本可以和训练大模型用的训练样本一样,或者另找一个独立的 Transfer set。
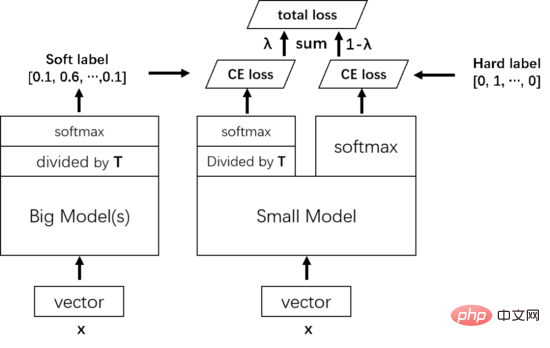
方法详解
具体来说,知识蒸馏使用的是 Teacher—Student 模型,其中 teacher 是“知识”的输出者,student 是“知识”的接受者。知识蒸馏的过程分为 2 个阶段:
- 教师模型训练:训练”Teacher 模型“, 简称为 Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。对“Teacher模型”不作任何关于模型架构、参数量、是否集成方面的限制,因为该模型不需要部署,唯一的要求就是,对于输入 X, 其都能输出 Y,其中 Y 经过 softmax 的映射,输出值对应相应类别的概率值。
- 学生模型训练:训练“Student 模型”, 简称为 Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入 X,其都能输出 Y,Y 经过 softmax 映射后同样能输出对应相应类别的概率值。
由于使用 softmax 的网络的结果很容易走向极端,即某一类的置信度超高,其他类的置信度都很低,此时学生模型关注到的正类信息可能还是仅属于某一类。除此之外,因为不同类别的负类信息也有相对的重要性,所有负类分数都差不多也不好,达不到知识蒸馏的目的。为了解决这个问题,引入温度(Temperature)的概念,使用高温将小概率值所携带的信息蒸馏出来。具体来说,在 logits 过 softmax 函数前除以温度 T。
训练时首先将教师模型学习到的知识蒸馏给小模型,具体来说对样本 X,大模型的倒数第二层先除以一个温度 T,然后通过 softmax 预测一个软目标 Soft target,小模型也一样,倒数第二层除以同样的温度 T,然后通过 softmax 预测一个结果,再把这个结果和软目标的交叉熵作为训练的 total loss 的一部分。然后再将小模型正常的输出和真值标签(hard target)的交叉熵作为训练的 total loss 的另一部分。Total loss 把这两个损失加权合起来作为训练小模型的最终的 loss。
在小模型训练好了要预测时,就不需要再有温度 T 了,直接按照常规的 softmax 输出就可以了。
03 FitNet
简介
FitNet 论文在蒸馏时引入了中间层隐藏映射(intermediate-level hints)来指导学生模型的训练。使用一个宽而浅的教师模型来训练一个窄而深的学生模型。在进行 hint 引导时,提出使用一个层来匹配 hint 层和 guided 层的输出 shape,这在后人的工作里面常被称为 adaptation layer。
总的来说,相当于是在做知识蒸馏时,不仅用到了教师模型的 logit 输出,还用到了教师模型的中间层特征图作为监督信息。可以想到的是,直接让小模型在输出端模仿大模型,这个对于小模型来说太难了(模型越深越难训,最后一层的监督信号要传到前面去还是挺累的),不如在中间加一些监督信号,使得模型在训练时可以从逐层接受学习更难的映射函数,而不是直接学习最难的映射函数;除此之外,hint 引导加速了学生模型的收敛,在一个非凸问题上找到更好的局部最小值,使得学生网络能更深的同时,还能训练得更快。这感觉就好像是,我们的目的是让学生做高考题,那么就先把初中的题目给他教会了(先让小模型用前半个模型学会提取图像底层特征),然后再回到本来的目的、去学高考题(用 KD 调整小模型的全部参数)。
这篇文章是提出蒸馏中间特征图的始祖,提出的算法很简单,但思路具有开创性。
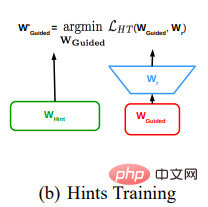
方法详解
FitNets 的具体做法是:
- 确定教师网络,并训练成熟,将教师网络的中间特征层 hint 提取出来。
- 设定学生网络,该网络一般较教师网络更窄、更深。训练学生网络使得学生网络的中间特征层与教师模型的 hint 相匹配。由于学生网络的中间特征层和与教师 hint 尺寸不同,因此需要在学生网络中间特征层后添加回归器用于特征升维,以匹配 hint 层尺寸。其中匹配教师网络的 hint 层与回归器转化后的学生网络的中间特征层的损失函数为均方差损失函数。
实际训练的时候往往和上一节的 KD Training 联合使用,用两阶段法训练:先用 hint training 去 pretrain 小模型前半部分的参数,再用 KD Training 去训练全体参数。由于蒸馏过程中使用了更多的监督信息, 基于中间特征图的蒸馏方法比基于结果 logits 的蒸馏方法效果要好 ,但是训练时间更久。
04 总结
知识蒸馏对于将知识从集成或从高度正则化的大型模型转移到较小的模型中非常有效。即使在用于训练蒸馏模型的迁移数据集中缺少任何一个或多个类的数据时,蒸馏的效果也非常好。在经典之作 KD 和 FitNet 提出之后,各种各样的蒸馏方法如雨后春笋般涌现。未来我们也希望能在模型压缩和知识迁移领域做出更进一步的探索。
作者简介
马佳良,网易易盾高级计算机视觉算法工程师,主要负责计算机视觉算法在内容安全领域的研发、优化和创新。
以上是大模型精准反哺小模型,知识蒸馏助力提高 AI 算法性能的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 WorldCoin(WLD)价格预测2025-2031:到2031年WLD会达到4美元吗?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)价格预测2025-2031:到2031年WLD会达到4美元吗?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)凭借其独特的生物识别验证和隐私保护机制,在加密货币市场中脱颖而出,吸引了众多投资者的目光。 WLD凭借其创新技术,特别是结合OpenAI人工智能技术,在众多山寨币中表现突出。但未来几年,数字资产的走势如何呢?让我们一起预测WLD的未来价格。 2025年WLD价格预测预计2025年WLD将实现显着增长。市场分析显示,WLD平均价格可能达到1.31美元,最高可能触及1.36美元。然而,在熊市情况下,价格可能跌至0.55美元左右。这一增长预期主要源于WorldCoin2.
 虚拟币价格上涨或者下降是为什么 虚拟币价格上涨或者下降的原因
Apr 21, 2025 am 08:57 AM
虚拟币价格上涨或者下降是为什么 虚拟币价格上涨或者下降的原因
Apr 21, 2025 am 08:57 AM
虚拟币价格上涨因素包括:1.市场需求增加,2.供应量减少,3.利好消息刺激,4.市场情绪乐观,5.宏观经济环境;下降因素包括:1.市场需求减少,2.供应量增加,3.利空消息打击,4.市场情绪悲观,5.宏观经济环境。
 Aavenomics是修改AAVE协议令牌并介绍令牌回购的建议,已达到法定人数
Apr 21, 2025 pm 06:24 PM
Aavenomics是修改AAVE协议令牌并介绍令牌回购的建议,已达到法定人数
Apr 21, 2025 pm 06:24 PM
Aavenomics是修改AAVE协议令牌并引入令牌回购的提议,已为AAVEDAO实现了一个法定人数。AAVE连锁计划(ACI)创始人马克·泽勒(MarcZeller)在X上宣布了这一点,并指出它标志着该协议的新时代。AAVE连锁倡议(ACI)创始人MarcZeller在X上宣布,Aavenomics提案包括修改AAVE协议令牌和引入令牌回购,已为AAVEDAO实现了法定人数。根据Zeller的说法,这标志着该协议的新时代。AaveDao成员以压倒性的投票支持该提议,即在周三以每周100
 跨链交易什么意思?跨链交易所有哪些?
Apr 21, 2025 pm 11:39 PM
跨链交易什么意思?跨链交易所有哪些?
Apr 21, 2025 pm 11:39 PM
支持跨链交易的交易所有:1. Binance,2. Uniswap,3. SushiSwap,4. Curve Finance,5. Thorchain,6. 1inch Exchange,7. DLN Trade,这些平台通过各种技术支持多链资产交易。
 币圈杠杆交易所排名 币圈十大杠杆交易所APP最新推荐
Apr 21, 2025 pm 11:24 PM
币圈杠杆交易所排名 币圈十大杠杆交易所APP最新推荐
Apr 21, 2025 pm 11:24 PM
2025年在杠杆交易、安全性和用户体验方面表现突出的平台有:1. OKX,适合高频交易者,提供最高100倍杠杆;2. Binance,适用于全球多币种交易者,提供125倍高杠杆;3. Gate.io,适合衍生品专业玩家,提供100倍杠杆;4. Bitget,适用于新手及社交化交易者,提供最高100倍杠杆;5. Kraken,适合稳健型投资者,提供5倍杠杆;6. Bybit,适用于山寨币探索者,提供20倍杠杆;7. KuCoin,适合低成本交易者,提供10倍杠杆;8. Bitfinex,适合资深玩
 币圈行情实时数据免费平台推荐前十名发布
Apr 22, 2025 am 08:12 AM
币圈行情实时数据免费平台推荐前十名发布
Apr 22, 2025 am 08:12 AM
适合新手的加密货币数据平台有CoinMarketCap和非小号。1. CoinMarketCap提供全球加密货币实时价格、市值、交易量排名,适合新手与基础分析需求。2. 非小号提供中文友好界面,适合中文用户快速筛选低风险潜力项目。
 如何在币安拿下 KERNEL 空投奖励 全流程攻略
Apr 21, 2025 pm 01:03 PM
如何在币安拿下 KERNEL 空投奖励 全流程攻略
Apr 21, 2025 pm 01:03 PM
在加密货币的繁华世界里,新机遇总是不断涌现。当下,KernelDAO (KERNEL) 空投活动正备受瞩目,吸引着众多投资者的目光。那么,这个项目究竟是什么来头?BNB Holder 又能从中获得怎样的好处?别急,下面将为你一一揭晓。
 对于加密货币行业来说,'黑色星期一抛售”是艰难的一天
Apr 21, 2025 pm 02:48 PM
对于加密货币行业来说,'黑色星期一抛售”是艰难的一天
Apr 21, 2025 pm 02:48 PM
加密货币市场暴跌引发投资者恐慌,Dogecoin(Doge)成为重灾区之一。其价格大幅下挫,去中心化金融(DeFi)总价值锁定(TVL)也出现显着下降。 “黑色星期一”的抛售潮席卷加密货币市场,Dogecoin首当其冲。其DeFiTVL跌至2023年水平,币价在过去一个月内下跌23.78%。 Dogecoin的DeFiTVL降至272万美元的低点,主要原因是SOSO价值指数下跌26.37%。其他主要DeFi平台,如无聊的Dao和Thorchain,TVL也分别下降了24.04%和20.
