

pytorch模型保存与加载中的一些问题实战记录

本篇文章给大家带来了关于Python的相关知识,其中主要介绍了关于pytorch模型保存与加载中的一些问题实战记录,下面一起来看一下,希望对大家有帮助。

【相关推荐:Python3视频教程 】
一、torch中模型保存和加载的方式
1、模型参数和模型结构保存和加载
torch.save(model,path) torch.load(path)
2、只保存模型的参数和加载——这种方式比较安全,但是比较稍微麻烦一点点
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
二、torch中模型保存和加载出现的问题
1、单卡模型下保存模型结构和参数后加载出现的问题
模型保存的时候会把模型结构定义文件路径记录下来,加载的时候就会根据路径解析它然后装载参数;当把模型定义文件路径修改以后,使用torch.load(path)就会报错。
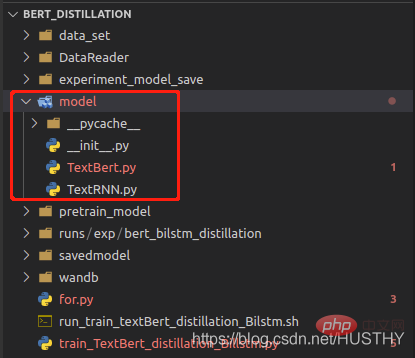
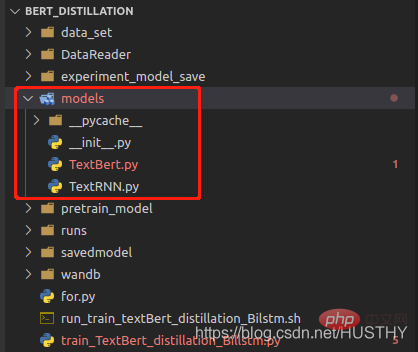

把model文件夹修改为models后,再加载就会报错。
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
这种保存完整模型结构和参数的方式,一定不要改动模型定义文件路径。
2、多卡机器单卡训练模型保存后在单卡机器上加载会报错
在多卡机器上有多张显卡0号开始,现在模型在n>=1上的显卡训练保存后,拷贝在单卡机器上加载
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
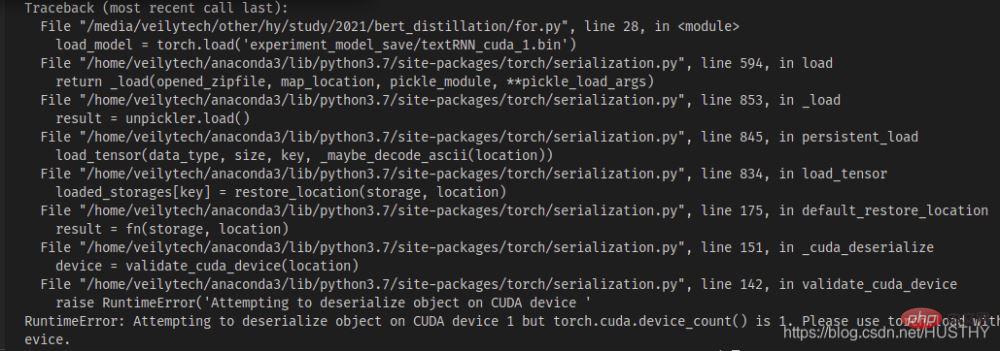
会出现cuda device不匹配的问题——你保存的模代码段 小部件型是使用的cuda1,那么采用torch.load()打开的时候,会默认的去寻找cuda1,然后把模型加载到该设备上。这个时候可以直接使用map_location来解决,把模型加载到CPU上即可。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3、多卡训练模型保存模型结构和参数后加载出现的问题
当用多GPU同时训练模型之后,不管是采用模型结构和参数一起保存还是单独保存模型参数,然后在单卡下加载都会出现问题
a、模型结构和参数一起保然后在加载

torch.distributed.init_process_group(backend='nccl')
模型训练的时候采用上述多进程的方式,所以你在加载的时候也要声明,不然就会报错。
b、单独保存模型参数
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
同样会出现问题,不过这里出现的问题是参数字典的key和模型定义的key不一样

原因是多GPU训练下,使用分布式训练的时候会给模型进行一个包装,代码如下:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)
包装前的模型结构:

包装后的模型
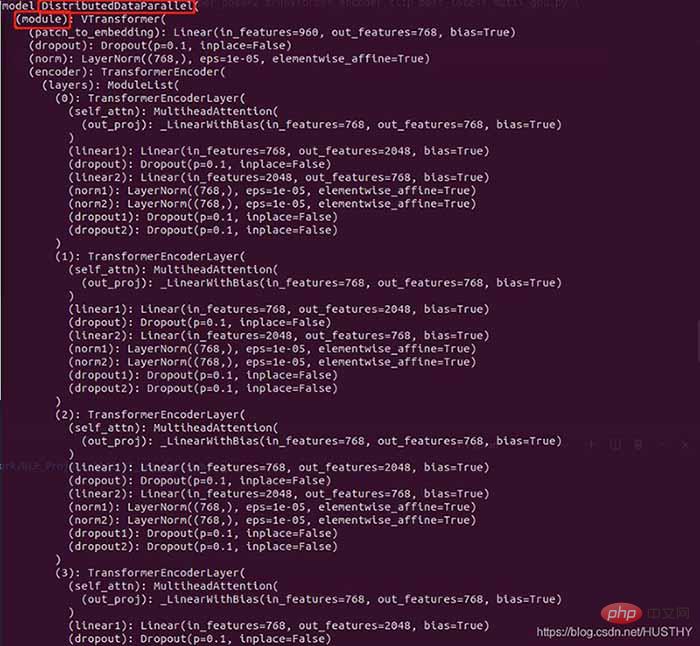
在外层多了DistributedDataParallel以及module,所以才会导致在单卡环境下加载模型权重的时候出现权重的keys不一致。
三、正确的保存模型和加载的方法
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)这样就是比较好的范式,加载不会出错。
【相关推荐:Python3视频教程 】
以上是pytorch模型保存与加载中的一些问题实战记录的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 sublime怎么运行代码python
Apr 16, 2025 am 08:48 AM
sublime怎么运行代码python
Apr 16, 2025 am 08:48 AM
在 Sublime Text 中运行 Python 代码,需先安装 Python 插件,再创建 .py 文件并编写代码,最后按 Ctrl B 运行代码,输出会在控制台中显示。
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 Golang vs. Python:性能和可伸缩性
Apr 19, 2025 am 12:18 AM
Golang vs. Python:性能和可伸缩性
Apr 19, 2025 am 12:18 AM
Golang在性能和可扩展性方面优于Python。1)Golang的编译型特性和高效并发模型使其在高并发场景下表现出色。2)Python作为解释型语言,执行速度较慢,但通过工具如Cython可优化性能。
 vscode在哪写代码
Apr 15, 2025 pm 09:54 PM
vscode在哪写代码
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中编写代码简单易行,只需安装 VSCode、创建项目、选择语言、创建文件、编写代码、保存并运行即可。VSCode 的优点包括跨平台、免费开源、强大功能、扩展丰富,以及轻量快速。
 notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
notepad 怎么运行python
Apr 16, 2025 pm 07:33 PM
在 Notepad 中运行 Python 代码需要安装 Python 可执行文件和 NppExec 插件。安装 Python 并为其添加 PATH 后,在 NppExec 插件中配置命令为“python”、参数为“{CURRENT_DIRECTORY}{FILE_NAME}”,即可在 Notepad 中通过快捷键“F6”运行 Python 代码。
