

讲解更新锁(U)与排它锁(X)的相关知识
一直没有认真了解UPDATE操作的锁,最近在MSDN论坛上看到一个问题,询问堆表更新的死锁问题,问题很简单,有类似这样的表及数据:
CREATE TABLE dbo.tb( c1 int, c2 char(10), c3 varchar(10) ); GO DECLARE @id int; SET @id = 0; WHILE @id <5 BEGIN; SET @id = @id + 1; INSERT dbo.tb VALUES( @id, 'b' + RIGHT(10000 + @id, 4), 'c' + RIGHT(100000 + @id, 4) ); END;
在查询一中执行更新操作:
BEGIN TRAN UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 2; WAITFOR DELAY '00:00:30'; UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 5; ROLLBACK;
在查询一执行开始后,马上在查询二中执行下面的操作
BEGIN TRAN UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 1; ROLLBACK;
为什么会出现死锁,如果条件改为 c1 = 4 则不会死锁。
开始的时候想得比较简单,死锁的表现是形成循环等待(对于两个查询而言,可以简单地认为就是在相互等待对方锁定资源的释放)。
对于这个例子而言,第一个查询更新两次,会先更新并锁定一条记录,然后等待第二个更新;但第二个查询只会更新一条记录,它要么与第一个查询冲突,无法获得锁,需要等待查询一完成,这个时候它并没有锁定什么;要么能够获得锁,完成更新。似乎不应该会出现死锁,死锁会不会是其他原因导致。
在自己的电脑上简单测试了一下,似乎也确实没有死锁。
但后面通过Profile跟踪更新操作的下锁情况才发现,自己的分析大错特错了。主要原因在于没有正确理解更新操作是如何用锁的。
在联机帮助上“锁模式”中有关于更新的U(更新锁)和X(排它锁)的说明
http://msdn.microsoft.com/zh-cn/library/ms175519(v=sql.105).aspx
不过说得确实挺模糊的,里面还提到了S锁,我一直以为是查询数据过程中用的S锁(也 SELECT 一样),找到满足条件的记录后用U锁,再转换为X锁做更新。
Profile(事件探查器)跟踪的结果让我知道了这是一个错误的理解,在Profile中新建一个跟踪,选择Locks中的Lock:Acquired(加锁),Lock:Acquired(释放锁)解两个事件,在筛选中设置只跟踪测试用的查询窗口对应的spid(可以执行 PRINT @@SPID获得),然后执行一个更新语句,比如 UPDATE dbo.tb SET c2 = 'xx' WHERE c1 = 3
在Profile中可以看到,对于每条记录都有加 U 锁的操作,对于不满足条件的记录,会马上释放U锁;对于满足条件的记录,最终转换为X锁。如下图所示。
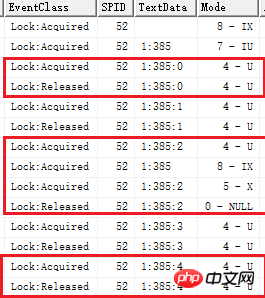
注意一下,在这个跟踪结果里面,并没有出现S锁。
另外学做了一些测试:
通过加大记录量做更新测试,会发现数据扫描涉及的记录都有U锁,并不限于更新记录所在的页。这从另一个角度说明了大表中Scan 可怕。
当使用索引Scan的时候,也会通过跟踪发现所Scan的索引资源有U锁,如果更新不涉及索引变化,那以只会对应的记录有U转X锁,索引的U锁会释放;如果影响索引,那么索引的U锁会转X锁。
删除操作与更新操作类似
使用 UPDATE aSET c2 = 'xx' FROM dbo.tb AS a WITH(NOLOCK) WHERE c1 = 3 的加锁情况是一样的, 并不会因为NOLOCK的提示而不加 U 或者 X 锁
最后回头研究一下示例中的死锁问题:
对于查询一,第一个更新依次扫描表中所有记录,对于每条记录,加 U 锁,判断是否符合更新条件,如果符合,转换为 X 锁;如果不符合条件,释放 U 锁。第一个更新完成的时候,查询一锁定了一条记录(由于事务未完成,所以锁一直保持),然后等待第二个更新
对于查询二,依次扫描表中的每条记录(与前面的更新一样),如果它更新的记录在查询一更新的记录前被扫描到,那么这条记录也会变成 X 锁;当继续并进行到查询一的X锁记录的零点,U 与 X 冲突,无法继续,这时候查询二等待查询一释放锁
查询一的第二个更新开始执行,依次扫描每条记录,同一个事务内不会有冲突,所以它不会与自己之前锁定的记录有冲突,但进行到查询二锁定的记录的时候,它也无法获得 U 锁,它需要等待查询二释放资源。这个时候就形成了相互等待,符合死锁条件
-
如果查询二需要更新的记录在查询一的第一个更新记录之后,则不会有死锁,因为查询二在扫描到查询一第一个更新的记录时就会因为锁冲突等待了,这个时候它没有对任何记录设置与查询一的操作有冲突的锁。我自己测试的时候没有死锁,就是这种情况。
注意这里面提到的顺序,是数据读取的顺序,不一定与存储顺序一样,磁盘上记录的顺序也不一定与INSERT的记录顺序一样,这也是我用同样条件没有测试出死锁的原因(我的环境中,恰好读出的顺序与INSERT的顺序不一样)
更新时,记录读取的顺序,可以通过Profile跟踪的Lock:Acquired (加锁)事件来看,涉及大量数据时,如果服务器支持,还会有并发读取。这也是分析死锁时要考虑的因素
本文讲解了讲解更新锁(U)与排它锁(X)的相关知识,更多相关内容请关注php中文网。
相关推荐:
SQL Server 2008 处理隐式数据类型转换在执行计划中的增强
以上是讲解更新锁(U)与排它锁(X)的相关知识的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何处理C++开发中的死锁问题
Aug 22, 2023 pm 02:24 PM
如何处理C++开发中的死锁问题
Aug 22, 2023 pm 02:24 PM
如何处理C++开发中的死锁问题死锁是多线程编程中常见的问题之一,尤其是在使用C++进行开发时更容易遇到。当多个线程互相等待对方持有的资源时,就可能发生死锁问题。如果不及时处理,死锁不仅会导致程序卡死,还会影响系统的性能和稳定性。因此,学习如何处理C++开发中的死锁问题是非常重要的。一、理解死锁的原因要解决死锁问题,首先需要了解死锁产生的原因。死锁通常发生在以
 C++ 多线程编程中死锁预防和检测机制
Jun 01, 2024 pm 08:32 PM
C++ 多线程编程中死锁预防和检测机制
Jun 01, 2024 pm 08:32 PM
多线程死锁预防机制包括:1.锁顺序;2.测试并设置。检测机制包括:1.超时;2.死锁检测器。文章举例共享银行账户,通过锁顺序避免死锁,为转账函数先请求转出账户再请求转入账户的锁。
 golang函数并发控制中死锁与饥饿的预防与解决
Apr 24, 2024 pm 01:42 PM
golang函数并发控制中死锁与饥饿的预防与解决
Apr 24, 2024 pm 01:42 PM
Go中死锁和饥饿:预防与解决死锁:协程相互等待而无法进行的操作,使用runtime.SetBlockProfileRate函数检测。预防死锁:使用细粒度加锁、超时、无锁数据结构,防止死锁。饥饿:协程持续无法获得资源,使用公平锁防止饥饿。公平锁实践:创建公平锁并等待协程尝试获取锁的时间最长的优先获取锁。
 如何调试 C++ 程序中的死锁?
Jun 03, 2024 pm 05:24 PM
如何调试 C++ 程序中的死锁?
Jun 03, 2024 pm 05:24 PM
死锁是一种并发编程中的常见错误,发生在多个线程等待彼此持有的锁时。可以通过使用调试器检测死锁,分析线程活动并识别涉及的线程和锁,从而解决死锁。解决死锁的方法包括避免循环依赖、使用死锁检测器和使用超时。在实践中,通过确保线程按相同的顺序获取锁或使用递归锁或条件变量可以避免死锁。
 Go开发中解决死锁的方法
Jun 30, 2023 pm 04:58 PM
Go开发中解决死锁的方法
Jun 30, 2023 pm 04:58 PM
解决Go语言开发中的死锁问题的方法Go语言是一种开源的静态类型编译型语言,被广泛应用于并发编程。然而,由于Go语言的并发模型的特性,开发者在编写并发程序时常常会遇到死锁问题。本文将介绍一些解决Go语言开发中死锁问题的方法。首先,我们需要了解何为死锁。死锁是指多个并发任务因互相等待对方释放资源而无法继续执行的情况。在Go语言中,死锁问题通常由于对资源的竞争或者
 C++ 函数如何解决并发编程中的死锁问题?
Apr 26, 2024 pm 01:18 PM
C++ 函数如何解决并发编程中的死锁问题?
Apr 26, 2024 pm 01:18 PM
在C++中,使用互斥量函数可以解决多线程并发编程中的死锁问题。具体步骤如下:创建一个互斥量;当线程需要访问共享变量时,获得互斥量;修改共享变量;释放互斥量。这样可以确保任何时刻只有一个线程访问共享变量,有效防止死锁。
 如何解决Go语言中的死锁问题?
Oct 08, 2023 pm 05:07 PM
如何解决Go语言中的死锁问题?
Oct 08, 2023 pm 05:07 PM
如何解决Go语言中的死锁问题?Go语言具有并发编程的特性,可以通过使用goroutine和channel来实现并发操作。然而,在并发编程中,死锁是一个常见的问题。当goroutine之间相互依赖于彼此的资源,并且在访问这些资源时产生了循环依赖关系,就可能导致死锁的发生。本文将介绍如何解决Go语言中的死锁问题,并提供具体的代码示例。首先,让我们来了解一下什么是
 Python 中的并发编程难题:与死锁和竞态条件作战
Feb 19, 2024 pm 02:40 PM
Python 中的并发编程难题:与死锁和竞态条件作战
Feb 19, 2024 pm 02:40 PM
死锁死锁是指多个线程相互等待资源,从而形成一个循环,最终导致所有线程都阻塞。在python中,死锁通常发生在对多个锁或互斥量按错误顺序进行锁定时。示例:importthreading#两个线程共享两个锁lock1=threading.Lock()lock2=threading.Lock()defthread1_func():lock1.acquire()lock2.acquire()#做一些操作lock2.release()lock1.release()defthread2_func():loc
