

什么是专家的混合物?

专家(MOE)模型的混合物正在通过提高效率和可扩展性来彻底改变大型语言模型(LLM)。这种创新的体系结构将模型分为专门的子网络或“专家”,每个人都接受了特定数据类型或任务的培训。通过仅根据输入激活专家的一个相关子集,MOE模型可显着提高容量,而不会按比例增加计算成本。这种选择性激活优化了资源使用情况,并可以在自然语言处理,计算机视觉和推荐系统等各个领域跨越复杂的任务。本文探讨了MOE模型,其功能,流行示例和Python实施。
本文是数据科学博客马拉松的一部分。
目录:
- 什么是专家(MOE)的混合物?
- 深度学习
- MOE模型如何运作?
- 基于MOE的突出模型
- Moes实施Python
- 比较来自不同MOE模型的输出
- dbrx
- DeepSeek-V2
- 常见问题
什么是专家(MOE)的混合物?
MOE模型通过使用多个较小的专业模型而不是单个大型模型来增强机器学习。每个较小的型号都以特定的问题类型出色。 “决策者”(门控机制)为每个任务选择适当的模型,从而提高整体绩效。包括变压器在内的现代深度学习模型使用分层互连的单元(“神经元”)来处理数据并将结果传递到后续层。 MOE通过将复杂的问题分为专业组件(“专家”)来反映这一点,每个组件都可以解决特定方面。
MOE模型的关键优势:
- 与密集模型相比,训练的速度更快。
- 更快的推断,即使使用类似的参数计数。
- 由于同时存储所有专家的内存中,VRAM的需求很高。
MOE模型包括两个主要部分:专家(专业的较小的神经网络)和一个路由器(基于输入的相关专家)。这种选择性激活提高了效率。
深度学习
在深度学习中,MoE通过分解复杂问题来改善神经网络性能。它使用多个专门研究不同输入数据方面的多个较小的“专家”模型,而不是单个大型模型。门控网络确定每个输入要使用的专家,从而提高效率和有效性。
MOE模型如何运作?
MOE模型如下:
- 多个专家:该模型包含几个较小的神经网络(“专家”),每个神经网络均经过特定输入类型或任务的培训。
- 门控网络:一个单独的神经网络(门控网络)决定每个输入使用的专家,分配权重以指示每个专家对最终输出的贡献。
- 动态路由:门控网络动态选择每个输入的最相关的专家,以优化效率。
- 组合输出:选定的专家的输出是根据门控网络的分配权重组合的,从而产生最终预测。
- 效率和可扩展性: MOE模型是有效的,因为每个输入只激活了少数专家,从而降低了计算成本。可伸缩性是通过添加更多专家来处理更复杂任务的情况,而无需显着增加每个输入的计算。
基于MOE的突出模型
MOE模型在AI中越来越重要,因为它们在保持性能的同时有效地缩放了LLM。 Mixtral 8x7b是一个值得注意的例子,使用了稀疏的MOE架构,仅激活每个输入的一部分专家,从而导致效率显着提高。
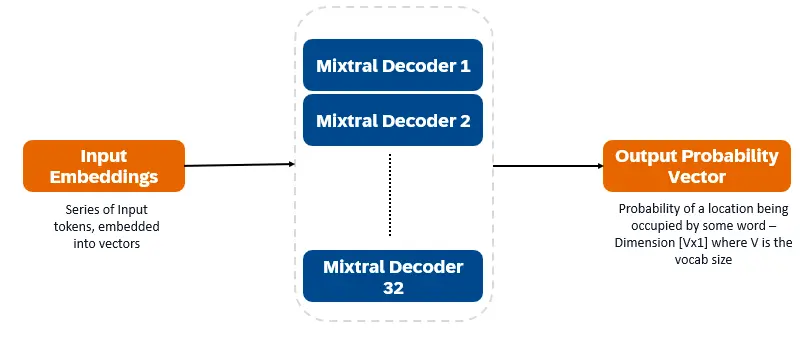
混合8x7b
混合8x7b是仅解码器的变压器。输入令牌嵌入向量中并通过解码器层进行处理。输出是每个位置被一个单词占据的概率,从而实现文本填充和预测。每个解码器层都有一个注意机制(用于上下文信息)和专家(SMOE)部分的稀疏混合物(单独处理每个单词向量)。 SMOE层使用多个层(“专家”),对于每个输入,都会使用最相关的专家输出的加权总和。
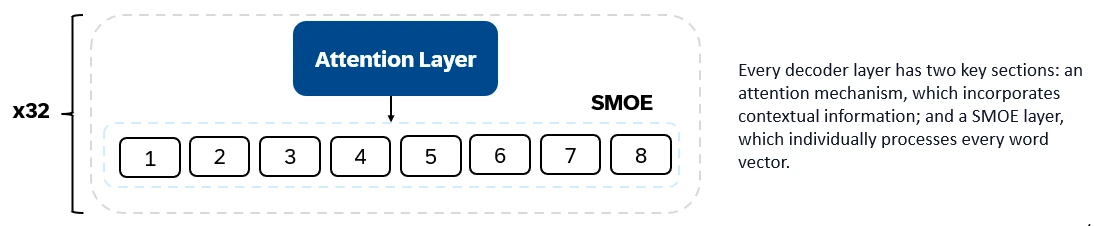
混音8x7b的主要特征:
- 总专家:8
- 活跃的专家:2
- 解码器层:32
- 词汇大小:32000
- 嵌入尺寸:4096
- 专家规模:每个参数56亿(共享组件共有70亿个参数)
- 主动参数:128亿
- 上下文长度:32K令牌
混音8x7b在文本生成,理解,翻译,摘要等方面表现出色。
dbrx
DBRX(Databricks)是一种基于变压器的仅解码器的LLM,该LLM使用下一步的预测训练。它使用细粒度的MOE架构(132B总参数,36B活动)。它已在文本和代码数据的12T代币上进行了预培训。 DBRX使用许多较小的专家(16位专家,每个输入选择4个)。
DBRX的主要体系结构特征:
- 细粒度专家:单个FFN分为细分市场,每个ffn均为专家。
- 其他技术:旋转位置编码(绳索),封闭式线性单元(GLU)和分组查询注意(GQA)。
DBRX的主要特征:
- 总专家:16
- 每层活跃的专家:4
- 解码器层:24
- 主动参数:360亿
- 总参数:1320亿
- 上下文长度:32K令牌
DBRX在代码生成,复杂的语言理解和数学推理方面表现出色。
DeepSeek-V2
DeepSeek-V2使用精细的专家和共享专家(始终活跃)来整合普遍知识。
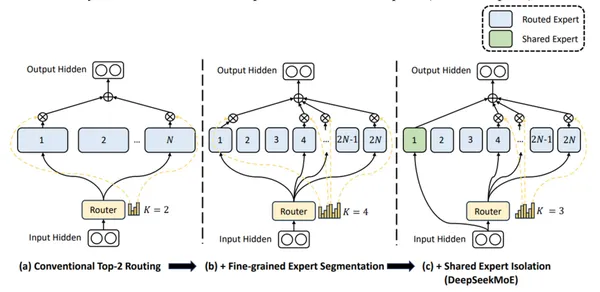
DeepSeek-V2的主要特征:
- 总参数:2360亿
- 主动参数:210亿
- 每层路由专家:160(选择2个)
- 每层共享专家:2
- 每层活跃的专家:8
- 解码器层:60
- 上下文长度:128K令牌
DeepSeek-V2擅长对话,内容创建和代码生成。
(Python实施和输出比较部分是为了简短的,因为它们是冗长的代码示例和详细的分析。)
常见问题
Q1。专家(MOE)模型的混合物是什么? A. Moe模型使用稀疏体系结构,仅激活每个任务最相关的专家,从而减少了计算资源的使用。
Q2。 MOE型号的权衡是什么? A. MOE模型需要重要的VRAM来存储所有专家,以平衡计算能力和内存要求。
Q3。混合8x7b的主动参数计数是什么? A.混合8x7b具有128亿个活动参数。
Q4。 DBRX与其他MOE模型有何不同? A. DBRX使用较小的专家使用细粒度的MOE方法。
Q5。 DeepSeek-V2有什么区别? A. DeepSeek-V2结合了细粒度和共享的专家,以及较大的参数集和长上下文长度。
结论
MOE模型为深度学习提供了高效的方法。在需要大量VRAM的同时,他们对专家的选择性激活使它们成为处理各个领域的复杂任务的强大工具。混合8x7b,dbrx和DeepSeek-V2代表了该领域的重大进步,每个方面都具有自己的优势和应用。
以上是什么是专家的混合物?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架构建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在从事代理AI时,开发人员经常发现自己在速度,灵活性和资源效率之间进行权衡。我一直在探索代理AI框架,并遇到了Agno(以前是Phi-
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑
Apr 16, 2025 am 11:37 AM
该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
Andrew Ng的新简短课程
Apr 15, 2025 am 11:32 AM
解锁嵌入模型的力量:深入研究安德鲁·NG的新课程 想象一个未来,机器可以完全准确地理解和回答您的问题。 这不是科幻小说;多亏了AI的进步,它已成为R
 火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
火箭发射模拟和分析使用Rocketpy -Analytics Vidhya
Apr 19, 2025 am 11:12 AM
模拟火箭发射的火箭发射:综合指南 本文指导您使用强大的Python库Rocketpy模拟高功率火箭发射。 我们将介绍从定义火箭组件到分析模拟的所有内容
 Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
Google揭示了下一个2025年云上最全面的代理策略
Apr 15, 2025 am 11:14 AM
双子座是Google AI策略的基础 双子座是Google AI代理策略的基石,它利用其先进的多模式功能来处理和生成跨文本,图像,音频,视频和代码的响应。由DeepM开发
 您可以自己3D打印的开源人形机器人:拥抱面孔购买花粉机器人技术
Apr 15, 2025 am 11:25 AM
您可以自己3D打印的开源人形机器人:拥抱面孔购买花粉机器人技术
Apr 15, 2025 am 11:25 AM
“超级乐于宣布,我们正在购买花粉机器人,以将开源机器人带到世界上,” Hugging Face在X上说:“自从Remi Cadene加入Tesla以来,我们已成为开放机器人的最广泛使用的软件平台。
 DeepCoder-14b:O3-Mini和O1的开源竞赛
Apr 26, 2025 am 09:07 AM
DeepCoder-14b:O3-Mini和O1的开源竞赛
Apr 26, 2025 am 09:07 AM
在AI社区的重大发展中,Agentica和AI共同发布了一个名为DeepCoder-14B的开源AI编码模型。与OpenAI等封闭源竞争对手提供代码生成功能
