

4M令牌? Minimax-Text-01优于DeepSeek V3

中国人工智能正在取得很大的进步,具有挑战性的领先模型,例如GPT-4,Claude和Grok,具有具有成本效益的开源替代方案,例如DeepSeek-V3和Qwen 2.5。 这些模型由于其效率,可及性和强大的性能而出色。 许多人在允许的商业许可下运营,扩大对开发商和企业的吸引力。 该组的最新成员Minimax-Text-01以其前所未有的400万令牌上下文长度设置了一个新标准,该标准的长度超过了典型的128K-256K令牌限制。这种扩展的上下文能力,结合了效率的混合注意体系结构和开源,商业允许的许可,促进了创新而无需高昂的成本。
>
>让我们深入研究minimax-text-01的功能:>
>混合体系结构
Experts(MOE)策略的混合物训练和缩放策略
- >训练后优化
- 关键创新
- 核心学术基准
- 一般任务基准
- 推理任务基准
- 数学和编码任务基准
- >开始使用minimax-text-01
- 重要链接
- >混合体系结构
- > minimax-text-01通过整合闪电的注意力,软效果的注意力和杂物(MOE)来巧妙地平衡效率和性能。
- >
7/8线性注意力(Lightning Coative-2):
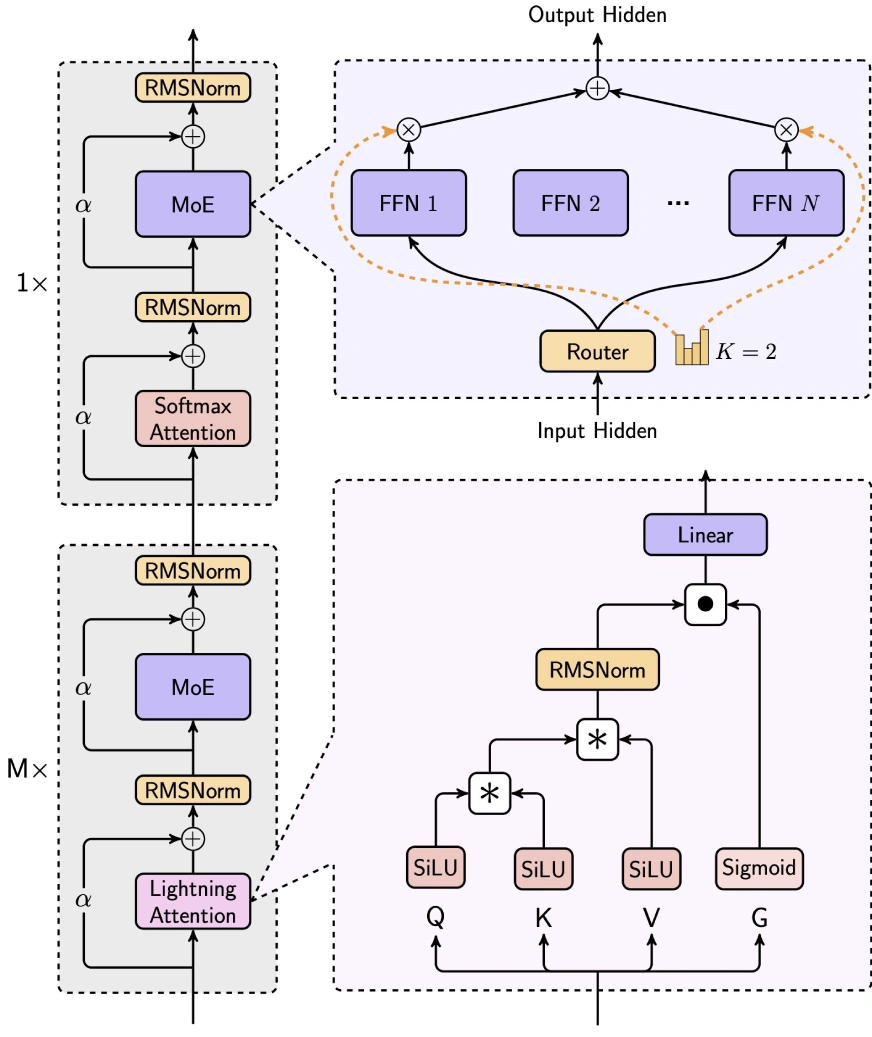 1/8 softmax的注意:
1/8 softmax的注意:
- > minimax-text-01的独特MOE架构将其与诸如DeepSeek-V3:之类的模型区分开
-
-
与DeepSeek的无滴方法不同,
- 使用辅助损失来维持跨专家的平衡令牌分配。
- >全局路由器:优化令牌分配,以在专家组之间进行工作负载分配。
- top-k路由:>选择每个令牌的top-2专家(与DeepSeek的Top-8 1共享专家相比)。 专家配置:
- 使用32位专家(与DeepSeek的256 1共享),专家隐藏的维度为9216(vs. DeepSeek的2048)。 每层的总激活参数与DeepSeek(18,432)相同。 训练和缩放策略
培训基础设施:- 使用了大约2000 h100 gpus,采用了高级并行性技术,例如专家张量并行性(ETP)和线性注意序列序列并行性和平行性(LASP)。 针对8位量化进行了优化,以在8x80GB H100节点上有效推断。
- 培训数据:使用WSD样学习率计划进行了大约12万亿代币培训。 该数据包括高质量和低质量来源的混合物,以及全局重复数据删除和4倍重复的高质量数据。
- >长篇下说训练:一种三个基础的方法:阶段1(128K上下文),第2阶段(512k上下文)和第3阶段(1M上下文),使用线性插值来管理上下文长度缩放期间的分布变化。 >
- > >训练后优化
使用脱机DPO和在线grpo进行对齐的监督微调(SFT)和强化学习(RL)的周期。 - >
- 长篇小说微调: 一个分阶段的方法:短篇小写SFT→长篇小写SFT→短篇小写→短上下文rl→长上下文RL,对于上下文的长篇小说性能至关重要。
- 关键创新
deepnorm:
>- 一种后构体结构增强了剩余连接缩放和训练稳定性。
- 批次尺寸热身: 逐渐将批次尺寸从16m增加到128m令牌,以进行最佳训练动力学。
- 有效的并行性: 利用环的注意来最大程度地减少长序列和填充优化的内存开销,以减少浪费的计算。
- 核心学术基准
(此处包括用于一般任务,推理任务和数学和编码任务的基准结果的表,此处包括原始输入表。)

(其他评估参数链接保留)
>开始使用minimax-text-01
(用于使用拥抱脸部变压器的minimax-text-01的代码示例保持不变。) 重要链接
聊天机器人- 在线API
- 文档
- 结论
> minimax-Text-01表现出令人印象深刻的功能,在长期和通用任务中实现了最先进的表现。尽管存在改进领域,但其开源性质,成本效益和创新的建筑使其成为AI领域的重要参与者。 它特别适用于记忆密集型和复杂的推理应用,尽管编码任务的进一步完善可能是有益的。
以上是4M令牌? Minimax-Text-01优于DeepSeek V3的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 10个生成AI编码扩展,在VS代码中,您必须探索
Apr 13, 2025 am 01:14 AM
10个生成AI编码扩展,在VS代码中,您必须探索
Apr 13, 2025 am 01:14 AM
嘿,编码忍者!您当天计划哪些与编码有关的任务?在您进一步研究此博客之前,我希望您考虑所有与编码相关的困境,这是将其列出的。 完毕? - 让&#8217
 AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作吗?
Apr 13, 2025 am 10:18 AM
介绍 Openai已根据备受期待的“草莓”建筑发布了其新模型。这种称为O1的创新模型增强了推理能力,使其可以通过问题进行思考
 视觉语言模型(VLMS)的综合指南
Apr 12, 2025 am 11:58 AM
视觉语言模型(VLMS)的综合指南
Apr 12, 2025 am 11:58 AM
介绍 想象一下,穿过美术馆,周围是生动的绘画和雕塑。现在,如果您可以向每一部分提出一个问题并获得有意义的答案,该怎么办?您可能会问:“您在讲什么故事?
 3种运行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3种运行Llama 3.2的方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2:多式联运AI强力 Meta的最新多模式模型Llama 3.2代表了AI的重大进步,具有增强的语言理解力,提高的准确性和出色的文本生成能力。 它的能力t
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表语句:动态地将列添加到数据库 在数据管理中,SQL的适应性至关重要。 需要即时调整数据库结构吗? Alter表语句是您的解决方案。本指南的详细信息添加了Colu
 pixtral -12b:Mistral AI'第一个多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一个多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
介绍 Mistral发布了其第一个多模式模型,即Pixtral-12b-2409。该模型建立在Mistral的120亿参数Nemo 12B之上。是什么设置了该模型?现在可以拍摄图像和Tex
