

DeepSeek R1 vs Openai O1:哪一个更好?

DeepSeek R1已经到了,它不仅是另一个AI模型,而且是AI功能的重大飞跃,接受了先前发布的DeepSeek-V3基本变体的训练。随着DeepSeek R1的全面发行,它在性能和灵活性方面与Openai O1保持一致。使它更加引人注目的是它的开放权重和麻省理工学院的许可,使其在商业上可行,并将其定位为开发人员和企业的强大选择。
>
但真正使DeepSeek R1与众不同的是它如何挑战Openai这样的行业巨头,从而获得了一小部分资源,取得了非凡的成果。在短短的两个月内,DeepSeek做了似乎不可能的事情 - 启动了一种在严格的限制下运行的开源AI模型,该模型与专有系统相匹配。在本文中,我们将比较 - DeepSeek R1与OpenAi O1。 目录的>
- deepseek r1:证明了独创性和效率
- >
- >是什么使deepseek r1成为游戏变化? O1:价格比较
- deepSeek r1 vs openai o1:比较不同的基准测试 >
- >如何使用ollama?
- 如何在Google colab中使用DeepSeek R1在Google colab中使用DeepSeek R1? DeepSeek R1:证明了独创性和效率
- > DeepSeek的预算仅为600万美元,
- 600万美元,已经完成了数十亿美元投资的公司努力工作。他们是这样做的:
>
仅为558万美元
- >。
资源优化:
- >以278万gpu小时实现的结果,对于类似规模的模型,大得低于Meta的> > 3080万小时。 >创新的解决方法: 使用
- 受限制的中国GPU 训练,在技术和地缘政治约束下展示了创造力。 >基准卓越:r1与关键任务中的OpenAI O1匹配, 明确的表现都超过了。
- > DeepSeek R1建立在开源研究的集体工作基础上,但其效率和绩效表明了
如何与Big Tech的大量预算相媲美。 是什么使DeepSeek R1变成游戏改变?> DeepSeek R1超出其令人印象深刻的技术功能,提供了关键功能,使其成为企业和开发人员的首选:> - 开放权重和麻省理工学院许可证:完全开放且商业上可用,为企业提供了构建的灵活性,而无需许可限制。 >
- 蒸馏模型:较小,微调的版本(类似于Qwen和Llama),提供出色的性能,同时保持不同应用的效率。
- api访问:>通过API轻松访问或直接在其平台上访问 - 免费!
与其他领先的AI模型相比,成本效益的成本效益:
> DeepSeek R1提出了一个令人兴奋的问题 - 我们目睹了一个新的AI时代的曙光,在这个新AI时代,拥有大创意的小型团队 可以破坏整个行业并超越10亿美元的巨人?随着AI景观的发展,DeepSeek的成功强调了 - 创新,效率和适应性可以像纯粹的财务状况一样强大。 DeepSeek R1 概述
6710亿参数体系结构,并已在
,类似于DeepSeek V3。 DeepSeek R1不仅是一个单片模型;生态系统包括模型上进行了训练。它的重点是思维链(COT)推理>使其成为需要高级理解和推理的任务的强大竞争者。有趣的是,尽管其参数计数较大,但在大多数操作中,仅激活370亿参数 六个蒸馏模型
对源自DeepSeek R1本身的合成数据进行了微调。这些较小的型号的尺寸和目标特定用例各不相同,为需要较轻,更快模型的开发人员提供了令人印象深刻的性能的开发人员。蒸馏模型阵容
Model Base Model Download DeepSeek-R1-Distill-Qwen-1.5B Qwen2.5-Math-1.5B ? HuggingFace DeepSeek-R1-Distill-Qwen-7B Qwen2.5-Math-7B ? HuggingFace DeepSeek-R1-Distill-Llama-8B Llama-3.1-8B ? HuggingFace DeepSeek-R1-Distill-Qwen-14B Qwen2.5-14B ? HuggingFace DeepSeek-R1-Distill-Qwen-32B Qwen2.5-32B ? HuggingFace DeepSeek-R1-Distill-Llama-70B Llama-3.3-70B-Instruct ? HuggingFace 这些蒸馏模型可以灵活地迎合本地部署和API使用。值得注意的是,Llama 33.7b模型在几个基准中优于O1 mini,强调了蒸馏型变体的强度。
模型
#total paramsModel #Total Params #Activated Params Context Length Download DeepSeek-R1-Zero 671B 37B 128K ? HuggingFace DeepSeek-R1 671B 37B 128K ? HuggingFace #activated params 上下文长度 上下文长度>下载 deepSeek-r1-Zero 671b 37b 128K ?拥抱面 deepSeek-r1 671b 37b 128K ?拥抱面 >您可以在此处找到有关OpenAi O1的全部内容。
> DeepSeek R1以最低的成本提供无与伦比的性能? DeepSeek R1以最低成本的令人印象深刻的表现归因于其培训和优化过程中的几种关键策略和创新。这是他们如何实现它的
:> 1。强化学习,而不是重大监督的微调
最传统的LLM(例如GPT,Llama等)严重依赖于监督的微调,这需要由人类注释者策划的广泛标记的数据集。 DeepSeek R1采用了不同的方法:
>deepSeek-r1-Zero:
- 而不是监督学习,而是利用纯强化学习(RL)
- 。
- 该模型是通过>自我进化训练的,允许它迭代地提高推理能力而无需人工干预。 与监督培训相比,RL有助于基于反复试验的策略来优化基于反复试验的策略,使模型更具成本效益 ,这需要大量的人类标记的数据集。
- deepSeek-r1(冷启动策略):
- 为了避免仅RL模型中的常见问题(例如不一致的响应),他们引入了一个小的,高质量的监督数据集以进行“冷启动”。 这使模型从一开始就可以更好地引导,从而确保了 人类般的流利性和可读性
> -
- 影响:
- RL培训大大降低了数据注释成本。
- 自我进化使该模型可以自主发现解决问题的策略。 2。提高效率和缩放 的蒸馏 DeepSeek使用的另一种改变游戏的方法是从较大的R1模型到较小模型的推理能力的
蒸馏
> Qwen,Llama等 通过提炼知识,他们能够创建较小的模型(例如14b),甚至超过了某些最先进的模型(SOTA)模型,例如QWQ-32B。 这个过程实质上将高级推理能力转移到了较小的体系结构上,使其高效而无需牺牲太多的准确性。
- 密钥蒸馏益处:
aime 2024:-
降低计算成本:较小的模型需要更少的推理时间和内存。
- 可伸缩性:在边缘设备或成本敏感的云环境上部署蒸馏模型更容易。
> 保持强劲的性能: - R1的蒸馏版仍在基准中进行竞争性排名。 3。基准性能和优化焦点
- >在79.8%
- 上取得附近的SOTA性能 MATH-500: 以97.3%的精度改善推理
- > CodeForces(竞争性编程): 排名在最高的3.7%
- >之内 mmlu(经常知识): 竞争性的90.8%,略低于某些模型,但仍然令人印象深刻。
- DeepSeek R1不是成为通用的聊天机器人,而是更多地关注>数学和逻辑推理任务,确保更好的资源分配和模型效率。 4。有效的体系结构和培训技术
> 稀疏注意机制:
可以处理较低的计算成本的较长上下文。>
-
专家(MOE)的混合物
-
:>
- 可能仅用于动态激活模型的一部分,从而导致有效的推断。
- 有效的训练管道:
- 培训良好的域特异性数据集而没有噪音过多的培训。
- 使用合成数据进行增强学习阶段。
-
5。战略模型设计选择
DeepSeek的方法在平衡成本和绩效方面具有高度战略性:
- 集中的域专业知识(数学,代码,推理)而不是通用的NLP任务。
- 优化的资源利用率优先考虑推理任务超过不太关键的NLP功能。
- 智能权衡喜欢在必要时使用rl,在最佳的情况下使用rl。
- 由于加强学习而减少了对昂贵监督数据集的需求。
- 有效的蒸馏 确保较小型号的顶级推理性能。
- 有针对性的训练重点 在推理基准上而不是一般NLP任务上。
- 优化体系结构以提高计算效率。 >
- 通过结合增强学习,选择性微调和战略性蒸馏 ,DeepSeek R1提供了顶级性能,同时与其他SOTA模型相比,保持
明显降低。 > DeepSeek R1 vs. Openai O1:价格比较>
在大多数评估中,DeepSeek R1与OpenAI O1的得分相当,甚至在特定情况下甚至超过了。这种高度的性能得到了可访问性的补充。 DeepSeek R1可以免费在DeepSeek聊天平台上使用,并提供负担得起的API定价。以下是成本比较:>
:输入55美分,输出为2.19美元(100万个令牌) > deepSeek r1 api
> deepSeek r1 api>openai o1 api :输入$ 15,输出$ 60(100万个令牌)
- API比Chatgpt便宜96.4%。
- > DeepSeek R1的较低成本和免费的聊天平台访问使其成为有预算意识的开发商和企业寻求可扩展AI解决方案的吸引人选择。 >基准测试和可靠性 DeepSeek模型始终显示出可靠的基准测试,R1模型坚持了这一声誉。 DeepSeek R1作为Openai O1的竞争对手和其他领先的模型,具有良好的性能指标,并且与聊天偏好相结合。蒸馏模型,例如 QWEN 32B
llama 33.7b,也提供了令人印象深刻的基准,在类似尺寸的类别中表现优于竞争对手。 实用的用法和可访问性
> DeepSeek R1及其蒸馏型变体很容易通过多个平台获得:- deepseek聊天平台:免费访问主型号。
- api Access :大规模部署的负担得起的价格。
- 本地部署:较小的型号,例如QWEN 8B或QWEN 32B,可以通过VM设置在本地使用。 >
>虽然某些模型(例如Llama变体)尚未出现在AMA上,但预计它们很快就会可用,进一步扩展了部署选项。
> DeepSeek R1 vs Openai O1:不同基准的比较1。 Aime 2024(通过@1)
- > deepSeek-r1: 79.8%精度
- >openai O1-1217:79.2%精度
-
>说明:
- 这个基准评估了美国邀请赛数学考试(AIME)的表现,这是一场具有挑战性的数学竞赛。
- > deepSeek-r1略优胜于0.6%的OpenAI-O1-1217,这意味着解决这些类型的数学问题的差距更差。
- > deepSeek-r1:96.3%
- OpenAI O1-1217:
96.6% >说明: -
> CodeForces是一个受欢迎的竞争编程平台,百分位排名显示了与其他模型相比的模型的表现。
- >
- openai-o1-1217稍好一些(比0.3%), 这意味着它在处理算法和编码挑战时可能具有略有优势。
- 3。 GPQA钻石(通过@1)
> deepSeek-r1:
71.5% - > OpenAi O1-1217:
75.7% >说明: - > GPQA钻石评估了模型回答复杂通用问题的能力。
- OpenAI-O1-1217的性能效果更好4.2%,表示此类别中的一般性提问能力更强。
> - 4。 Math-500(通过@1)
- > deepSeek-r1:
> OpenAI O1-1217:
96.4% - >说明: 这个基准测量了许多主题的数学解决问题技能。
- > deepSeek-r1的得分较高0.9%,表明它可能具有更好的精度和高级数学问题的推理。
-
- 5。 mmlu(通过@1)
- > deepSeek-r1:90.8%
> OpenAI O1-1217: - MMLU(大量的多任务语言理解)测试模型跨越历史,科学和社会研究等学科的通用知识。 > openai-o1-1217更好1%,
- 这意味着它可能对各种主题有更广泛或更深入的了解。
> - 6。经过验证(已解决)
- > deepSeek-r1:
49.2% -
OpenAi O1-1217:
48.9%
- > deepSeek-r1:
- > deepSeek-r1的优势略有0.3%,表明与较小的铅的编码水平相似。
- DeepSeek-R1优势: 与数学相关的基准(AIME 2024,MATH-500)和软件工程任务(SWE-BENCENFIEN)。
-
OpenAI O1-1217优势:
竞争性编程(CodeForces),通用Q&A(GPQA Diamond)和常识任务(MMLU)。 > - 网站以下载该工具。对于Linux用户: 在您的终端中执行以下命令:
-
>逻辑思考过程
- 该模型表现出A 明确的逐步推理过程
,考虑了递归和迭代方法。 。 >它捕获了常见的陷阱(例如,递归的效率低下),并证明了迭代方法的选择合理。
- 该模型表现出A 明确的逐步推理过程
- 代码的正确性
- 最终的迭代解决方案是正确的,并且正确处理基本案例。
- > 测试案例fib(5)产生正确的输出。
- >
- 说明深度
- 详细且对初学者友好,覆盖:
- 基本案例
- 循环行为
- >变量更新
- 复杂性分析
- 详细且对初学者友好,覆盖:
- 效率考虑
- >解释强调了时间复杂性($ o(n)$),并将其与递归对比,证明了对算法效率的很好的理解。
- 加速:一个库,以优化和加快培训和推断Pytorch型号。
- 火炬:pytorch库,这是一个深度学习框架。 >
-
自定义和开源优势
- >它的开源框架使团队可以根据其独特的需求来量身定制模型,将其与现有系统无缝集成或为专用域进行优化。这种灵活性对具有利基技术要求的组织特别有益。
>出色的数学能力 -
在需要复杂的计算,统计分析或数学建模的应用中,具有97.3%的精度,DeepSeek-R1在应用程序中脱颖而出。这使其成为金融,工程和科学研究等领域的强大选择。
- OpenAI的O1系列专为可靠性,安全性和高级推理至关重要的企业级应用而设计。这是它闪耀的地方:
-
>企业级安全性和合规性
- >通过强大的安全协议和合规措施,O1非常适合处理敏感数据或在严格的监管框架下运行的行业。 >
-
杰出的编程和推理技能
-
该模型在CodeForces(2061评级)和GPQA Diamond(75.7%)上的令人印象深刻的性能使其成为处理复杂应用程序或高级推理任务的软件开发团队的首选。
- >
- >关键任务应用程序的良好往绩记录
严格的测试和验证过程确保O1提供一致且可靠的性能,使其适用于无法选择失败的关键任务操作。 - >
结论
的发布标志着AI景观的重大转变,提供了开放量,MIT许可的替代品
摊牌突出了负担能力和可访问性。与专有模型不同,DeepSeek R1通过可扩展且预算友好的方法使AI民主化,这是那些寻求强大但具有成本效益的AI解决方案的人的首选。OpenAi o1 o1>。凭借令人印象深刻的基准和蒸馏变体,它为开发人员和研究人员提供了多功能,高性能的解决方案。 DeepSeek R1在推理,思想链(COT)任务和AI理解方面表现出色,提供了具有成本效益的性能,可与OpenAi O1匹配。它的负担能力和效率使其非常适合从聊天机器人到研究项目的各种应用程序。在测试中,其响应质量与Openai O1相匹配,证明了它是一个认真的竞争对手。 DeepSeek R1 vs Openai O1 >立即开始使用DeepSeek!在我们的“ DeepSeek入门”课程中,了解如何利用DeepSeek的AI和机器学习能力。现在注册,将您的技能提升到一个新的水平!
-
>企业级安全性和合规性
>说明: 此基准测试评估模型在解决软件工程任务时的性能。
Benchmark DeepSeek-R1 (%) OpenAI o1-1217 (%) Verdict AIME 2024 (Pass@1) 79.8 79.2 DeepSeek-R1 wins (better math problem-solving) Codeforces (Percentile) 96.3 96.6 OpenAI-o1-1217 wins (better competitive coding) GPQA Diamond (Pass@1) 71.5 75.7 OpenAI-o1-1217 wins (better general QA performance) MATH-500 (Pass@1) 97.3 96.4 DeepSeek-R1 wins (stronger math reasoning) MMLU (Pass@1) 90.8 91.8 OpenAI-o1-1217 wins (better general knowledge understanding) SWE-bench Verified (Resolved) 49.2 48.9 DeepSeek-R1 wins (better software engineering task handling) >总体判决:
DeepSeek-R1在数学和软件任务方面引导,而OpenAI O1-1217在一般知识和解决问题方面都表现出色。
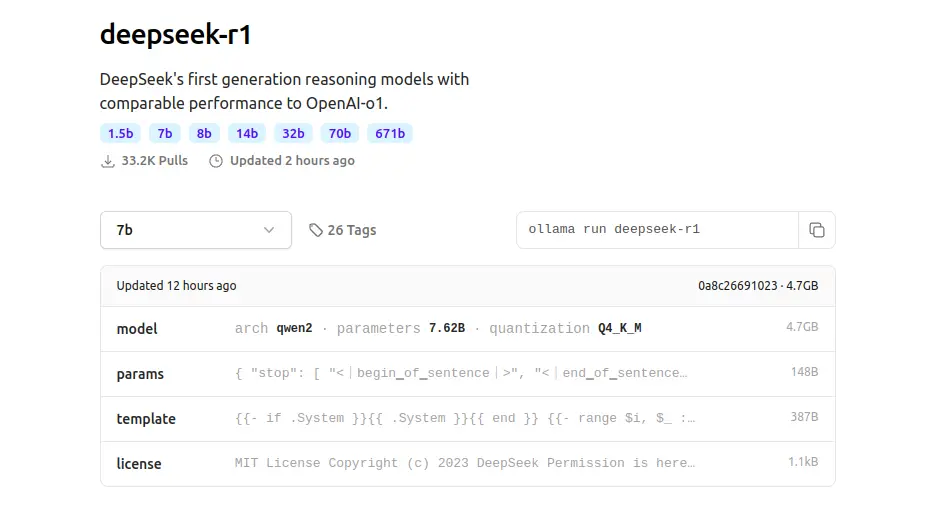
>如果您的重点是> 数学推理和软件工程,DeepSeek-R1可能是一个更好的选择,而对于>通用任务和编程竞赛,则OpenAI O1-1217可能具有优势。 如何使用Ollama访问DeepSeek R1?
首先,安装Ollama
>访问- > ollama
curl -fsSL https://ollama.com/install.sh | sh
登录后复制登录后复制这是Ollama,例如DeepSeek R1:Ollama Run DeepSeek-r1
> 在我正在运行Ollama在本地运行DeepSeek-r1:1.5b,下载该模型将需要几分钟。
提示:给我fibonAcci nth系列
的代码 输出
固体deepSeek-r1:1.5b的输出质量看起来很,有一些积极的方面和潜在改进的领域:
积极方面
使用变压器此命令安装三个python库:curl -fsSL https://ollama.com/install.sh | sh
登录后复制登录后复制- 变形金刚:通过拥抱面对的图书馆,以使用预训练的语言模型。
>!pip install transformers accelerate torch
登录后复制
这定义了消息列表,其中每个消息都是一个字典,其中包含角色(例如“用户”)和内容(消息的实际文本)。这种格式通常用于会话模型。from transformers import pipeline
登录后复制
这将使用DeepSeek-ai/deepSeek-r1-distill-qwen-7b模型创建文本生成管道。管道函数自动处理加载模型和令牌。>messages = [ {"role": "user", "content": "Give me code for the Fibonacci nth series"}, ]登录后复制这将消息列表传递给管道,该列表基于输入生成响应。
> 输出
Openai O1的代码实现
pipe = pipeline("text-generation", model="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B") pipe(messages)登录后复制
输出Okay, the user is asking for a Fibonacci sequence calculator. I remember<br><br>that the Fibonacci sequence starts with 0 and 1, and each subsequent<br><br>number is the sum of the previous two.<br><br>I should write a function called fib(n) where n is the term number we want<br><br>to find. If n is 0 or 1, it returns 0 since those are the starting points.<br><br>For other values, I'll use recursion because each term depends on the two<br><br>before it, which seems straightforward.<br><br>Wait, but recursion can be inefficient for large n because it recalculates<br><br>many terms repeatedly. Maybe the user wants an iterative approach instead<br><br>to make it faster and more efficient. That way, even if n is big, it<br><br>doesn't take too long.<br><br>I'll structure my function with a loop that starts from 2 up to n. I'll<br><br>keep track of the two previous numbers, prev1 and prev2. Then for each<br><br>step beyond 2, calculate current as the sum of prev1 and prev2. Update<br><br>prev2 to be prev1, and update prev1 to current.<br><br>Wait again, what if n is 0? The function should return 0, same with n=1.<br><br>So I'll add a condition at the beginning of the loop where if it's the<br><br>first term, we handle it correctly.<br><br>Let me test some examples. For fib(5), it should be 5. Let's see: prev1<br><br>starts as 0, prev2 as 1. Then for i=3 to 5:<br><br>i=3: current = 1 (0+1)<br><br>i=4: current = 2 (1+1)<br><br>i=5: current = 3 (1+2) Wait, that's not right. Oh no, I think I messed up the calculation steps.<br><br>Wait, for fib(5), let me recount:<br><br>n=0: 0<br><br>n=1: 1<br><br>n=2: 1<br><br>n=3: 2<br><br>n=4: 3<br><br>n=5: 5. So my previous step-by-step was wrong. I need to make sure each iteration is correct.<br><br>I think in the loop, when i reaches n-2, which for fib(5) is index 5 (since starting at 0), but wait, let me adjust the code correctly.<br><br>Let me write down:<br><br>def fib(n):<br><br>if n == 0:<br><br>return 0<br><br>elif n == 1:<br><br>return 1<br><br>prev1 = 0<br><br>prev2 = 1<br><br>for i in range(2, n+1):<br><br>current = prev1 + prev2<br><br>prev1 = prev2<br><br>prev2 = current<br><br>return prev2<br><br>Testing fib(5) would give:<br><br>i=2: current 1; prev1=1, prev2=1<br><br>i=3: current 2; prev1=1, prev2=2<br><br>i=4: current 3; prev1=2, prev2=3<br><br>i=5: current 5; return 5. Correct.<br><br>Yes, that should work.<br><br></think><br><br>Here’s a simple iterative implementation of the Fibonacci sequence:<br><br>```python<br><br>def fib(n):<br><br>if n == 0:<br><br>return 0<br><br>elif n == 1:<br><br>return 1<br><br>else:<br><br>prev1 = 0<br><br>prev2 = 1<br><br>for i in range(2, n+1):<br><br>current = prev1 + prev2<br><br>prev1 = prev2<br><br>prev2 = current<br><br>return prev2<br><br># Test the function<br><br>print(fib(5)) # Output: 5<br><br>```<br><br>### Explanation:<br><br>- The function `fib(n)` calculates the nth Fibonacci number using an iterative approach.<br><br>- **Base Cases**: If `n` is 0, it returns 0; if `n` is 1, it returns 1.<br><br>- **Iteration**: For values of `n` greater than 1, we initialize two variables (`prev1` and `prev2`) to represent the first two Fibonacci numbers (0 and 1).<br><br>- **Loop**: We loop from 2 up to `n`, updating the values of `prev1` and `prev2` in each iteration. After completing the loop, `prev2` contains the nth Fibonacci number.<br><br>- **Efficiency**: This method is efficient with a time complexity of O(n) since it only iterates once through the sequence.<br><br>### Example<br><br>If you want to calculate the 5th Fibonacci number:<br><br>- The function returns 5 when called as `fib(5)`.<br><br>This implementation avoids the inefficiencies of recursion and is more straightforward for educational purposes.
登录后复制最终判决
> DeepSeek R1提供了更有效,更通用的解决方案
,使其总体上是更好的选择。它正确处理边缘案例,提供返回值的函数以供进一步使用,并包括详细说明。这使其适合于实际应用和教育目的。 openai o1虽然更简单,更易于初学者,但在功能方面受到限制,因为它仅在不返回值的情况下打印序列,从而使其对高级任务的有用程度降低。
>推荐:>如果需要有效且可重复使用的解决方案,请与 DeepSeek R1的方法一起使用。如果您只是想简单地理解斐波那契序列,请使用openai o1的 为您的需求选择理想的AI模型
为您的项目选择正确的AI模型涉及评估多种因素,例如技术规格,预算限制和运营需求。下面,我们探讨了不同模型及其理想用例的优势,以帮助您做出明智的决定。> DeepSeek-R1:无与伦比 DeepSeek-R1是特定应用程序的最大竞争者,尤其是那些优先考虑负担能力和适应性的竞争者。这就是为什么它可能非常适合您的项目:
预算友好的解决方案
与传统模型相比,DeepSeek-R1的运营成本低至5%,非常适合初创企业,学术研究和财务资源有限的项目。
 > deepSeek r1 api
> deepSeek r1 api

 deepSeek-r1:1.5b的输出质量看起来很
deepSeek-r1:1.5b的输出质量看起来很

以上是DeepSeek R1 vs Openai O1:哪一个更好?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
本文回顾了AI最高的艺术生成器,讨论了他们的功能,对创意项目的适用性和价值。它重点介绍了Midjourney是专业人士的最佳价值,并建议使用Dall-E 2进行高质量的可定制艺术。
 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&amp;更多)
Apr 02, 2025 pm 06:09 PM
最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&amp;更多)
Apr 02, 2025 pm 06:09 PM
本文比较了诸如Chatgpt,Gemini和Claude之类的顶级AI聊天机器人,重点介绍了其独特功能,自定义选项以及自然语言处理和可靠性的性能。
 Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4当前可用并广泛使用,与诸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和产生连贯的响应方面取得了重大改进。未来的发展可能包括更多个性化的间
 顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
文章讨论了Grammarly,Jasper,Copy.ai,Writesonic和Rytr等AI最高的写作助手,重点介绍了其独特的内容创建功能。它认为Jasper在SEO优化方面表现出色,而AI工具有助于保持音调的组成
 构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
2024年见证了从简单地使用LLM进行内容生成的转变,转变为了解其内部工作。 这种探索导致了AI代理的发现 - 自主系统处理任务和最少人工干预的决策。 Buildin
 向员工出售AI策略:Shopify首席执行官的宣言
Apr 10, 2025 am 11:19 AM
向员工出售AI策略:Shopify首席执行官的宣言
Apr 10, 2025 am 11:19 AM
Shopify首席执行官TobiLütke最近的备忘录大胆地宣布AI对每位员工的基本期望是公司内部的重大文化转变。 这不是短暂的趋势。这是整合到P中的新操作范式
 选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
本文评论了Google Cloud,Amazon Polly,Microsoft Azure,IBM Watson和Discript等高级AI语音生成器,重点介绍其功能,语音质量和满足不同需求的适用性。
