

释放 MongoDB:为什么基于游标的分页每次都优于基于偏移量的分页!

分页是处理大型数据集时任何数据库操作的关键部分。它允许您将数据分割成可管理的块,从而更容易浏览、处理和显示。 MongoDB 提供了两种常见的分页方法:基于偏移量和基于游标。虽然这两种方法具有相同的目的,但它们在性能和可用性方面显着不同,尤其是随着数据集的增长。
让我们深入研究这两种方法,看看为什么基于光标的分页通常优于基于偏移量的分页。
1. 基于偏移量的分页
基于偏移量的分页非常简单。它检索从给定偏移量开始的特定数量的记录。例如,第一页可能检索记录 0-9,第二页检索记录 10-19,依此类推。
但是,这种方法有一个显着的缺点:当您移动到更高的页面时,查询会变得更慢。这是因为数据库需要跳过前几页的记录,这涉及到扫描它们。
这是基于偏移量的分页代码:
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
2. 基于光标的分页
基于游标的分页,也称为键集分页,依赖于唯一标识符(例如 ID 或时间戳)来对记录进行分页。它不会跳过一定数量的记录,而是使用最后检索到的记录作为获取下一组记录的参考点。
这种方法更加高效,因为它避免了扫描当前页面之前的记录。因此,无论您深入数据集多深,查询时间都保持一致。
这是基于光标的分页代码:
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
在此示例中,lastDocumentId 是上一页中最后一个文档的 ID。当查询下一页时,数据库会获取ID大于该值的文档,确保无缝过渡到下一组记录。
3. 性能比较
让我们看看这两种方法如何在大型数据集上执行。
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
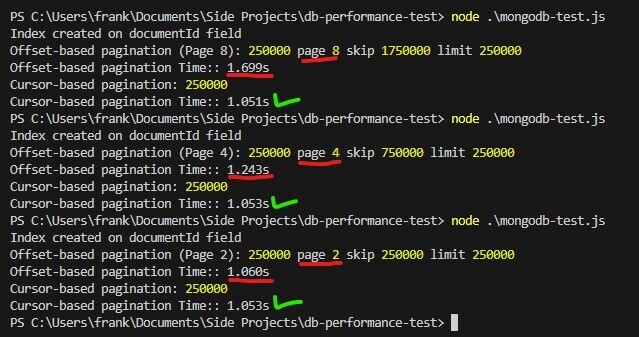
在性能测试中,您会注意到基于偏移分页需要更长,因为页码增加,而光标基于的分页保持一致,使其成为大型数据集的更好选择。此示例还展示了索引的强大功能。尝试删除索引然后查看结果!
为什么索引很重要
如果没有索引,MongoDB 将需要执行集合扫描,这意味着它必须查看集合中的每个文档以查找相关数据。这是低效的,尤其是当数据集增长时。索引可以让 MongoDB 高效地找到符合您查询条件的文档,显着提升查询性能。
在基于游标的分页上下文中,索引可确保快速获取下一组文档(基于 documentId),并且不会随着更多文档添加到集合中而降低性能。
结论
虽然基于偏移的分页很容易实现,但由于需要扫描记录,因此对于大型数据集来说它可能会变得低效。另一方面,基于游标的分页提供了更具可扩展性的解决方案,无论数据集大小如何,都可以保持性能一致。如果您在 MongoDB 中处理大型集合,值得考虑基于游标的分页以获得更流畅、更快的体验。
这是供您在本地运行的完整index.js:
const { MongoClient } = require("mongodb");
const uri = "mongodb://localhost:27017";
const client = new MongoClient(uri);
client.connect();
const db = client.db("testdb");
const collection = db.collection("testCollection");
async function insertMongoDBRecords() {
try {
let bulkOps = [];
for (let i = 0; i < 2000000; i++) {
bulkOps.push({
insertOne: {
documentId: i,
name: `Record-${i}`,
value: Math.random() * 1000,
},
});
// Execute every 10000 operations and reinitialize
if (bulkOps.length === 10000) {
await collection.bulkWrite(bulkOps);
bulkOps = [];
}
}
if (bulkOps.length > 0) {
await collection.bulkWrite(bulkOps);
console.log("? Inserted records till now -> ", bulkOps.length);
}
console.log("MongoDB Insertion Completed");
} catch (err) {
console.error("Error in inserting records", err);
}
}
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
testMongoDB();
以上是释放 MongoDB:为什么基于游标的分页每次都优于基于偏移量的分页!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
神秘的JavaScript:它的作用以及为什么重要
Apr 09, 2025 am 12:07 AM
JavaScript是现代Web开发的基石,它的主要功能包括事件驱动编程、动态内容生成和异步编程。1)事件驱动编程允许网页根据用户操作动态变化。2)动态内容生成使得页面内容可以根据条件调整。3)异步编程确保用户界面不被阻塞。JavaScript广泛应用于网页交互、单页面应用和服务器端开发,极大地提升了用户体验和跨平台开发的灵活性。
 JavaScript的演变:当前的趋势和未来前景
Apr 10, 2025 am 09:33 AM
JavaScript的演变:当前的趋势和未来前景
Apr 10, 2025 am 09:33 AM
JavaScript的最新趋势包括TypeScript的崛起、现代框架和库的流行以及WebAssembly的应用。未来前景涵盖更强大的类型系统、服务器端JavaScript的发展、人工智能和机器学习的扩展以及物联网和边缘计算的潜力。
 JavaScript引擎:比较实施
Apr 13, 2025 am 12:05 AM
JavaScript引擎:比较实施
Apr 13, 2025 am 12:05 AM
不同JavaScript引擎在解析和执行JavaScript代码时,效果会有所不同,因为每个引擎的实现原理和优化策略各有差异。1.词法分析:将源码转换为词法单元。2.语法分析:生成抽象语法树。3.优化和编译:通过JIT编译器生成机器码。4.执行:运行机器码。V8引擎通过即时编译和隐藏类优化,SpiderMonkey使用类型推断系统,导致在相同代码上的性能表现不同。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 JavaScript:探索网络语言的多功能性
Apr 11, 2025 am 12:01 AM
JavaScript:探索网络语言的多功能性
Apr 11, 2025 am 12:01 AM
JavaScript是现代Web开发的核心语言,因其多样性和灵活性而广泛应用。1)前端开发:通过DOM操作和现代框架(如React、Vue.js、Angular)构建动态网页和单页面应用。2)服务器端开发:Node.js利用非阻塞I/O模型处理高并发和实时应用。3)移动和桌面应用开发:通过ReactNative和Electron实现跨平台开发,提高开发效率。
 如何使用Next.js(前端集成)构建多租户SaaS应用程序
Apr 11, 2025 am 08:22 AM
如何使用Next.js(前端集成)构建多租户SaaS应用程序
Apr 11, 2025 am 08:22 AM
本文展示了与许可证确保的后端的前端集成,并使用Next.js构建功能性Edtech SaaS应用程序。 前端获取用户权限以控制UI的可见性并确保API要求遵守角色库
 使用Next.js(后端集成)构建多租户SaaS应用程序
Apr 11, 2025 am 08:23 AM
使用Next.js(后端集成)构建多租户SaaS应用程序
Apr 11, 2025 am 08:23 AM
我使用您的日常技术工具构建了功能性的多租户SaaS应用程序(一个Edtech应用程序),您可以做同样的事情。 首先,什么是多租户SaaS应用程序? 多租户SaaS应用程序可让您从唱歌中为多个客户提供服务
 从C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
从C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
从C/C 转向JavaScript需要适应动态类型、垃圾回收和异步编程等特点。1)C/C 是静态类型语言,需手动管理内存,而JavaScript是动态类型,垃圾回收自动处理。2)C/C 需编译成机器码,JavaScript则为解释型语言。3)JavaScript引入闭包、原型链和Promise等概念,增强了灵活性和异步编程能力。
