

从头设计抗体,腾讯、北大团队预训练大语言模型登Nature子刊

 编辑 | KX
编辑 | KX
AI 技术在辅助抗体设计方面取得了巨大进步。然而,抗体设计仍然严重依赖于从血清中分离抗原特异性抗体,这是一个资源密集且耗时的过程。
为了解决这个问题,腾讯 AI Lab、北京大学深圳研究生院和西京消化病医院研究团队提出了一种预训练抗体生成大语言模型(PALM-H3),用于从头生成具有所需抗原结合特异性的人工抗体CDRH3,减少对天然抗体的依赖。
此外,还设计了一个高精度的抗原-抗体结合预测模型 A2binder,将抗原表位序列与抗体序列配对,从而预测结合特异性和亲和力。
总之,该研究建立了一个用于抗体生成和评估的人工智能框架,这有可能显着加速抗体药物的开发。
相关研究以「De novo generation of SARS-CoV-2 antibody CDRH3 with a pre-trained generative large language model」为题,于8 月10 日发布在《Nature Communications》上。

抗体药物,又称单克隆抗体,在生物治疗中发挥着至关重要的作用。通过模仿免疫系统的作用,这些药物可以选择性地针对病毒和癌细胞等致病因子。与传统治疗方法相比,抗体药物是一种更具体、更有效的方法。抗体药物在治疗多种疾病方面已显示出积极的效果。
开发抗体药物是一个复杂的过程,包括从动物源中分离抗体,使其人性化,并优化其亲和力。但抗体药物的开发仍然严重依赖于天然抗体。
蛋白质的序列数据可以看作是一种语言,因此自然语言处理(NLP)领域的大规模预训练模型已被用来学习蛋白质的表征模式。当前已经开发了多种蛋白质语言模型。然而,由于抗体的多样性高和可用的抗原抗体配对数据稀缺,生成对特定抗原表位具有高亲和力的抗体仍然是一项具有挑战性的任务。
为了应对上述挑战,腾讯AI Lab 团队提出了预训练抗体生成大型语言模型PALM-H3,用于优化和生成重链互补决定区3 (CDRH3),该区域在抗体的特异性和多样性中起着至关重要的作用。
为了评估 PALM-H3 产生的抗体对抗原的亲和力,研究人员结合使用了抗原抗体对接和基于 AI 的方法。
研究人员还开发了用于评估抗体-抗原亲和力的 A2binder。 A2binder 能够实现准确且可推广的亲和力预测,即使对于未知抗原也是如此。
PALM-H3 和 A2Binder 的框架
PALM-H3 和 A2binder 的工作流程和模型框架如下图所示。
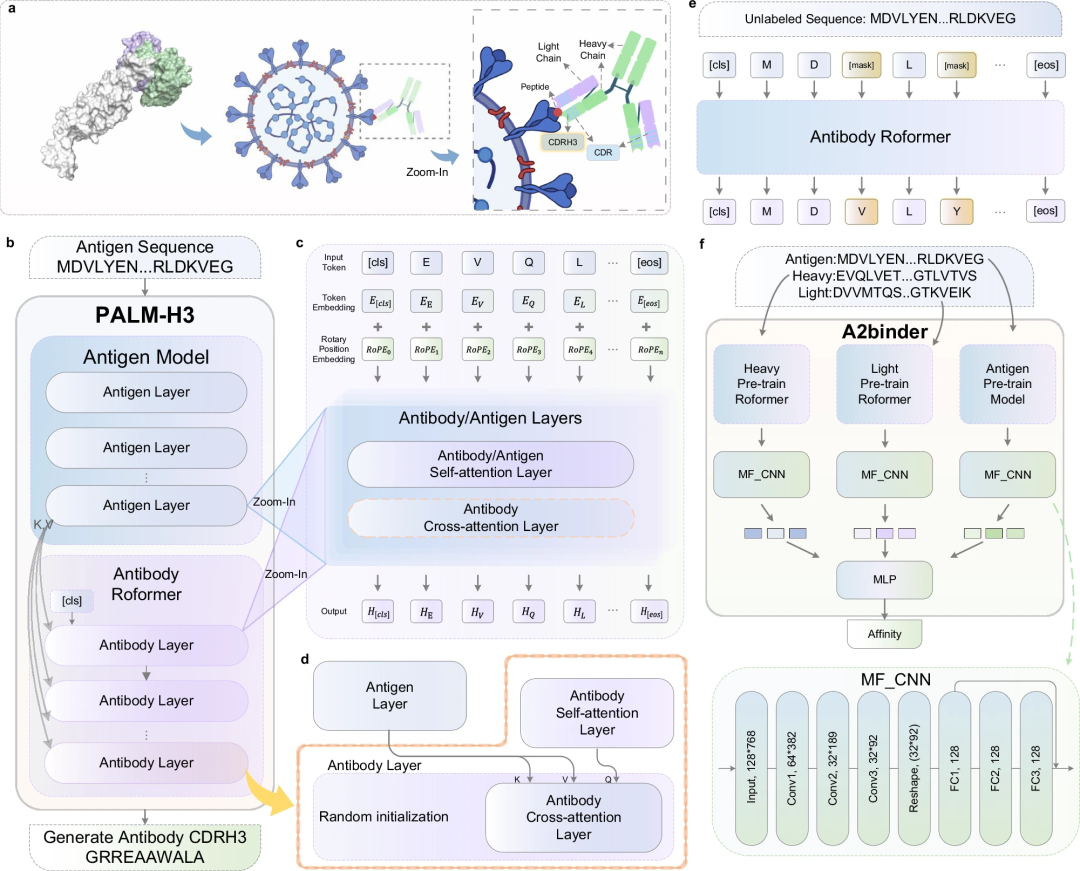
PALM-H3 的目的是生成抗体中的从头 CDRH3 序列。 CDRH3 区域在决定抗体对特定抗原序列的结合特异性方面起着最重要的作用。 PALM-H3 是一个类似 transformer 的模型,它使用基于 ESM2 的抗原模型作为编码器,使用抗体 Roformer 作为解码器。研究还构建了 A2binder 来预测人工生成的抗体的结合亲和力。
PALM-H3 和 A2binder 的构建包括三个步骤:首先,研究人员分别在未配对的抗体重链和轻链序列上预训练两个 Roformer 模型。然后,基于预训练的 ESM2、抗体重链 Roformer 和抗体轻链 Roformer 构建 A2binder,并使用配对亲和力数据对其进行训练。最后,使用预训练的 ESM2 和抗体重链 Roformer 构建 PALM-H3,并在配对抗原-CDRH3 数据上对其进行训练,以从头生成 CDRH3。
A2binder 可以准确预测抗原抗体结合概率、亲和力
通过将 A2binder 预测亲和力的能力与几种基线方法进行比较来评估其性能。
A2binder 在亲和力数据集上表现出色,部分原因在于抗体序列的预训练,这使得 A2binder 能够学习这些序列中存在的独特模式。
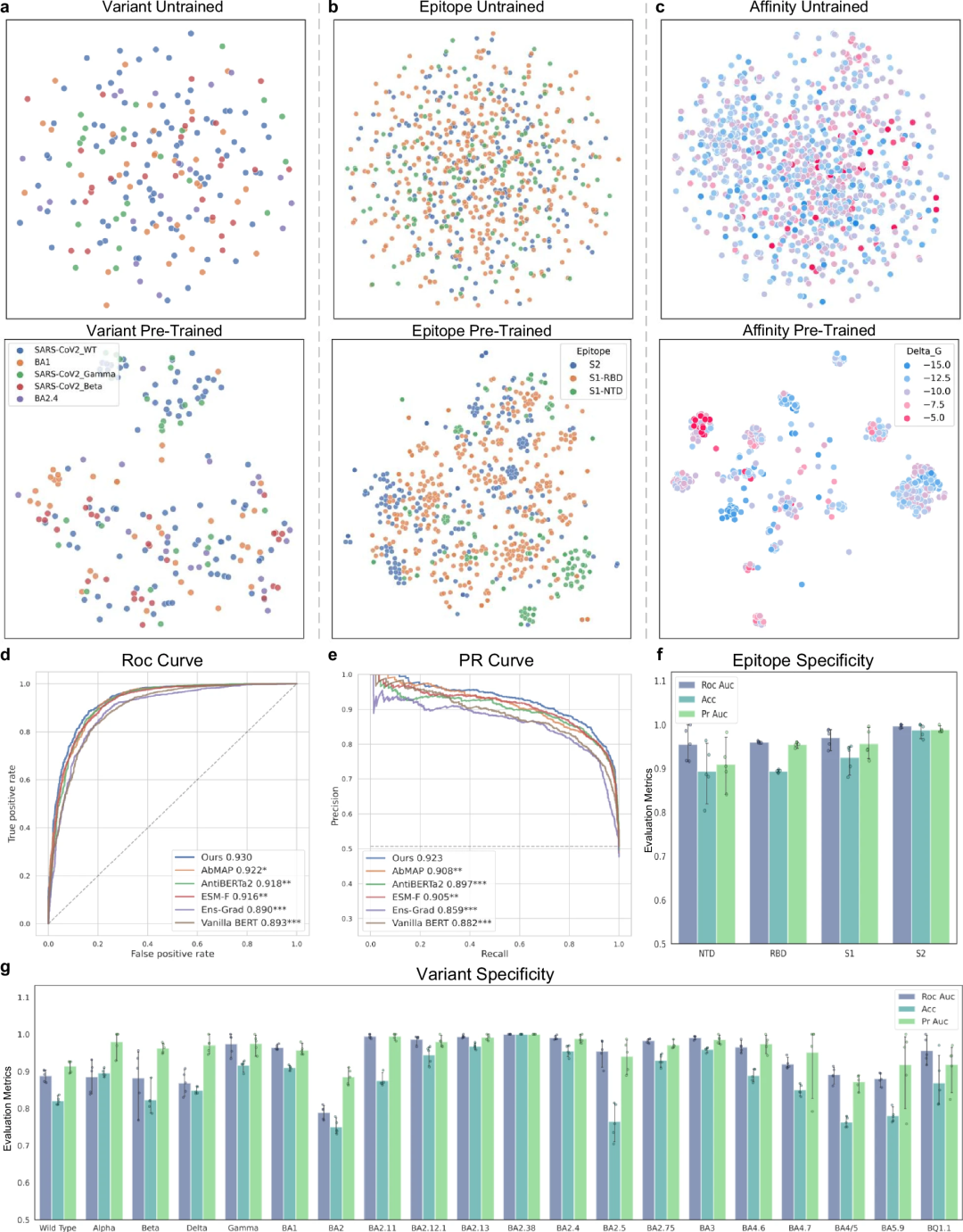
结果表明,在所有抗原抗体亲和力预测数据集上,A2binder 的表现均优于基线模型 ESM-F(后者具有相同的框架,但预训练模型被 ESM2 取代),这表明使用抗体序列进行预训练可能对相关的下游任务有益。
为了评估模型在预测亲和力值方面的表现,研究人员还利用了两个包含亲和力值标签的数据集 14H 和 14L。
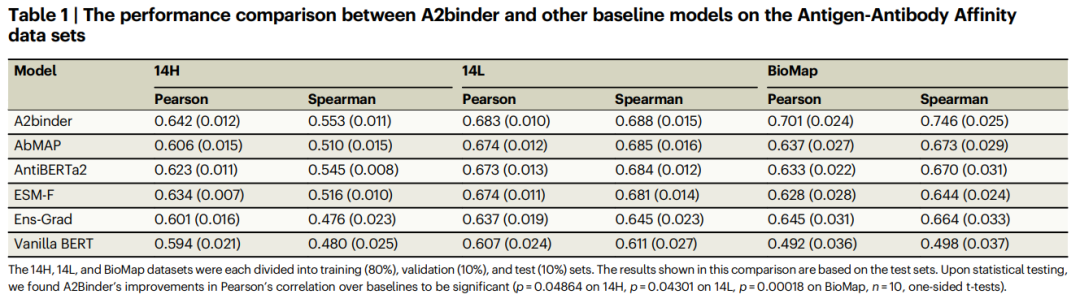
A2binder 在 Pearson 相关性和 Spearman 相关性指标上均优于所有基线模型。A2binder 在 14H 数据集上实现了 0.642 的 Pearson 相关性(提高了 3%),在 14L 数据集上实现了 0.683(提高了 1%)。
然而,与其他数据集相比,A2binder 和其他基线模型在 14H 和 14L 数据集上的性能略有下降。这一观察结果与以前的研究一致。
PALM-H3 在生成高结合概率抗体方面表现优异
研究人员探索了 PALM-H3 产生的抗体与天然抗体之间的差异。发现它们的序列存在显著差异,但产生的抗体的结合概率并没有受到这些差异的显著影响。同时,它们的结构差异确实导致结合亲和力的下降。这些结果与之前关于抗体库网络分析和功能性蛋白质序列生成的研究一致。
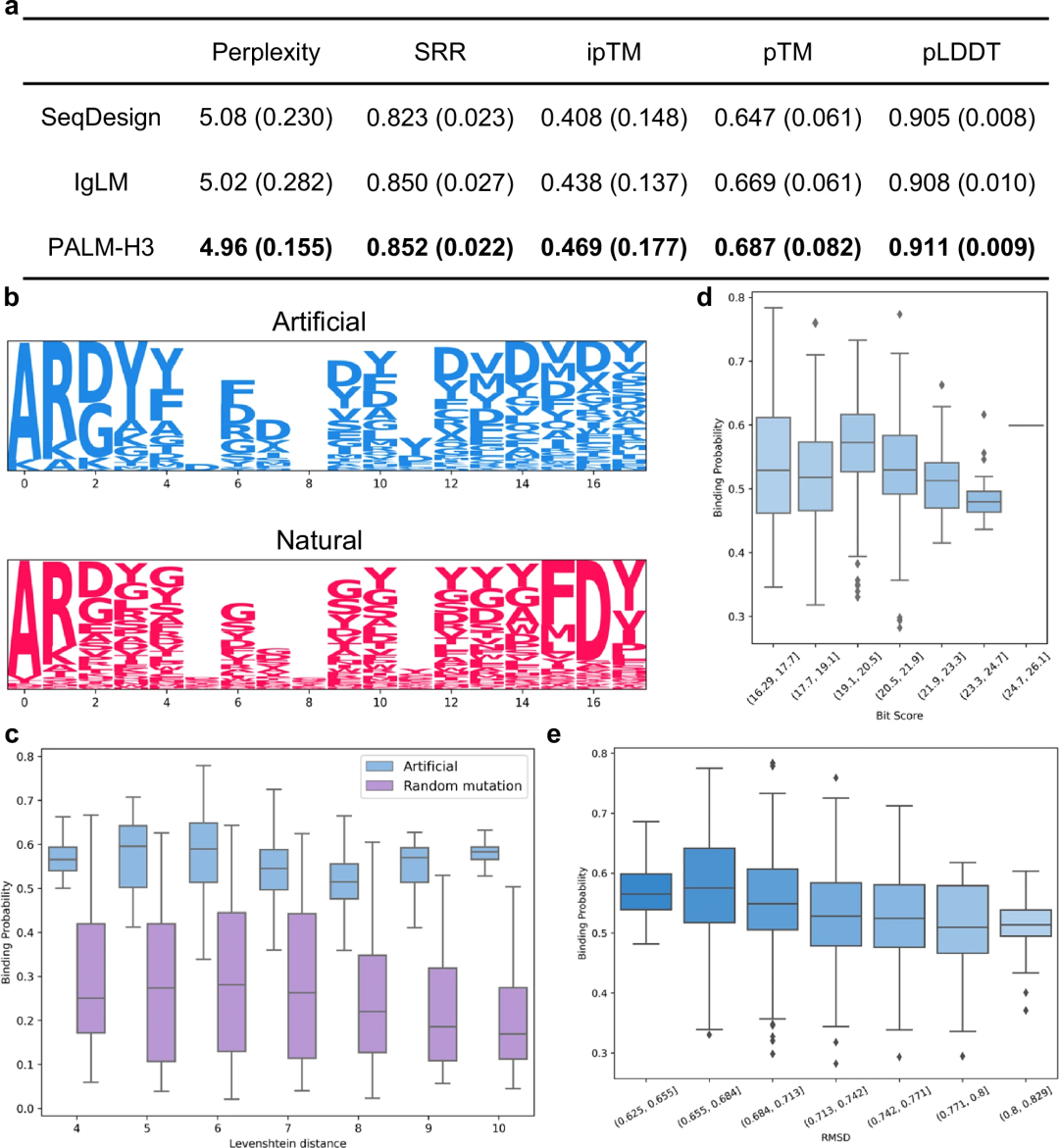
总体而言,结果表明,尽管与天然抗体不同,但 PALM-H3 能够生成具有高结合亲和力的多种抗体序列。
此外,研究人员通过 ClusPro 和 SnugDock 验证了 PALM-H3 的性能。PALM-H3 能够生成针对 SARS-CoV-2 HR2 区稳定肽的抗体 CDRH3 序列。它生成了新的 CDRH3 序列,并且验证了生成的序列 GRREAAWALA 与天然 CDHR3 序列 GKAAGTFDS 相比,对抗原稳定肽的靶向性有所改善。
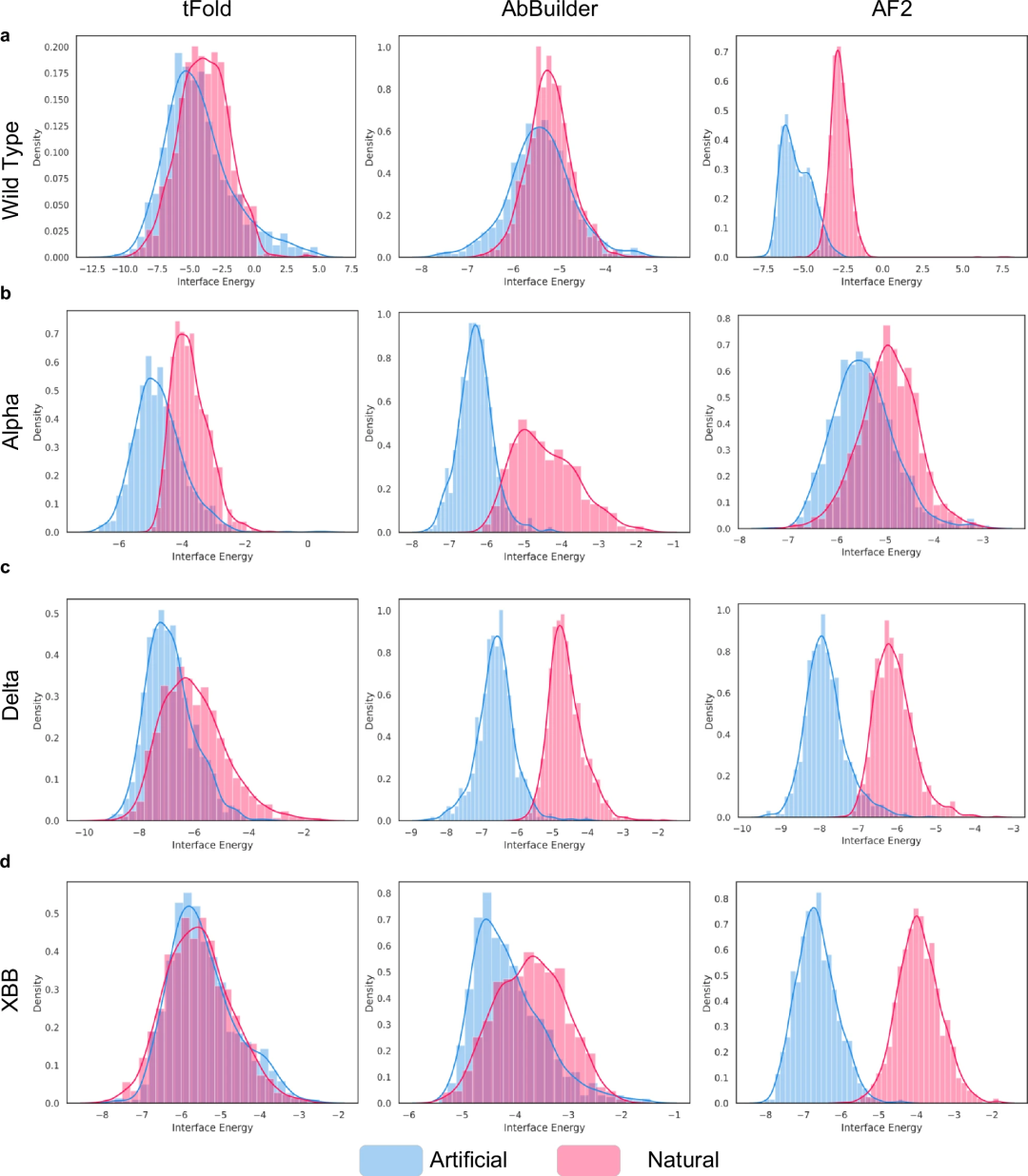
此外,PALM-H3 能够生成对新出现的 SARS-CoV-2 变体 XBB 具有更高亲和力的抗体 CDRH3 序列。生成的序列 AKDSRTSPLRLDYS 对 XBB 的亲和力比其来源 ASEVLDNLRDGYNF 更强。
此外,PALM-H3 不仅克服了传统顺序突变策略面临的局部最优陷阱,而且与 E-EVO 方法相比,它还能产生具有更高抗原结合亲和力的抗体。这凸显了 PALM-H3 在抗体设计方面的优势,能够更有效地探索序列空间并生成针对特定表位的高亲和力结合物。
体外实验
此外,研究人员还进行了体外试验,包括蛋白质印迹、表面等离子体共振分析和假病毒中和试验,为 PALM-H3 设计抗体的有效性提供了关键验证。
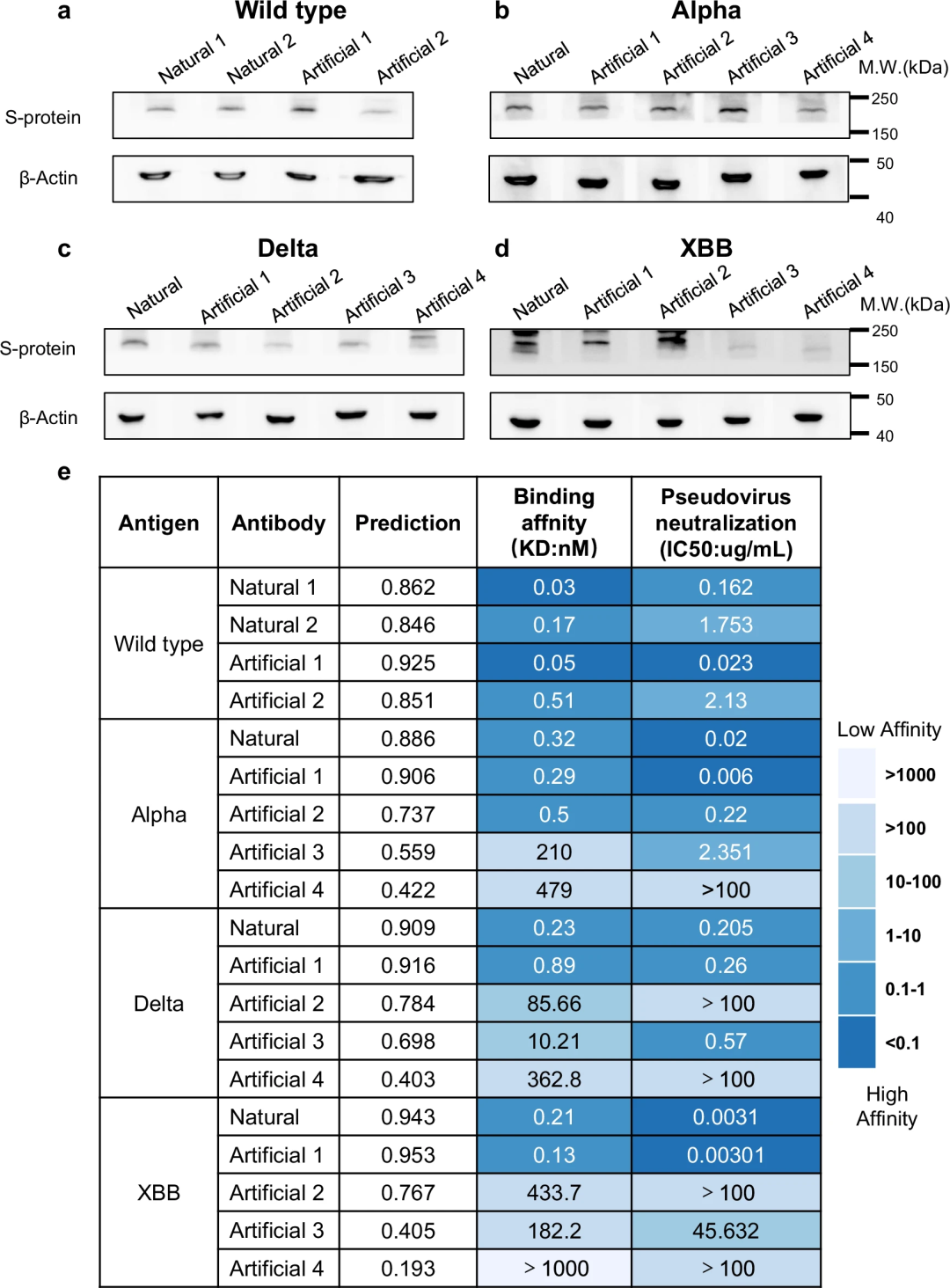
PALM-H3 产生的针对 SARS-CoV-2 野生型、Alpha、Delta 和 XBB 变体刺突蛋白的两种抗体在这些试验中都实现了比天然抗体更高的结合亲和力和中和效力。这些湿实验室实验的有力经验结果补充了计算预测和分析,验证了 PALM-H3 和 A2binder 在生成和选择对已知和新抗原具有高特异性和亲和力的强效抗体方面的能力。
总之,提出的 PALM-H3 集成了大规模抗体预训练的能力和全局特征融合的有效性,从而具有卓越的亲和力预测性能和设计高亲和力抗体的能力。此外,直接序列生成和可解释的权重可视化使其成为设计高亲和力抗体的有效且可解释的工具。
以上是从头设计抗体,腾讯、北大团队预训练大语言模型登Nature子刊的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 突破传统缺陷检测的界限,\'Defect Spectrum\'首次实现超高精度丰富语义的工业缺陷检测。
Jul 26, 2024 pm 05:38 PM
突破传统缺陷检测的界限,\'Defect Spectrum\'首次实现超高精度丰富语义的工业缺陷检测。
Jul 26, 2024 pm 05:38 PM
在现代制造业中,精准的缺陷检测不仅是保证产品质量的关键,更是提升生产效率的核心。然而,现有的缺陷检测数据集常常缺乏实际应用所需的精确度和语义丰富性,导致模型无法识别具体的缺陷类别或位置。为了解决这一难题,由香港科技大学广州和思谋科技组成的顶尖研究团队,创新性地开发出了“DefectSpectrum”数据集,为工业缺陷提供了详尽、语义丰富的大规模标注。如表一所示,相比其他工业数据集,“DefectSpectrum”数据集提供了最多的缺陷标注(5438张缺陷样本),最细致的缺陷分类(125种缺陷类别
 英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
开放LLM社区正是百花齐放、竞相争鸣的时代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等许多表现优良的模型。但是,相比于以GPT-4-Turbo为代表的专有大模型,开放模型在很多领域依然还有明显差距。在通用模型之外,也有一些专精关键领域的开放模型已被开发出来,比如用于编程和数学的DeepSeek-Coder-V2、用于视觉-语言任务的InternVL
 数百万晶体数据训练,解决晶体学相位问题,深度学习方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
数百万晶体数据训练,解决晶体学相位问题,深度学习方法PhAI登Science
Aug 08, 2024 pm 09:22 PM
编辑|KX时至今日,晶体学所测定的结构细节和精度,从简单的金属到大型膜蛋白,是任何其他方法都无法比拟的。然而,最大的挑战——所谓的相位问题,仍然是从实验确定的振幅中检索相位信息。丹麦哥本哈根大学研究人员,开发了一种解决晶体相问题的深度学习方法PhAI,利用数百万人工晶体结构及其相应的合成衍射数据训练的深度学习神经网络,可以生成准确的电子密度图。研究表明,这种基于深度学习的从头算结构解决方案方法,可以以仅2埃的分辨率解决相位问题,该分辨率仅相当于原子分辨率可用数据的10%到20%,而传统的从头算方
 谷歌AI拿下IMO奥数银牌,数学推理模型AlphaProof面世,强化学习 is so back
Jul 26, 2024 pm 02:40 PM
谷歌AI拿下IMO奥数银牌,数学推理模型AlphaProof面世,强化学习 is so back
Jul 26, 2024 pm 02:40 PM
对于AI来说,奥数不再是问题了。本周四,谷歌DeepMind的人工智能完成了一项壮举:用AI做出了今年国际数学奥林匹克竞赛IMO的真题,并且距拿金牌仅一步之遥。上周刚刚结束的IMO竞赛共有六道赛题,涉及代数、组合学、几何和数论。谷歌提出的混合AI系统做对了四道,获得28分,达到了银牌水平。本月初,UCLA终身教授陶哲轩刚刚宣传了百万美元奖金的AI数学奥林匹克竞赛(AIMO进步奖),没想到7月还没过,AI的做题水平就进步到了这种水平。IMO上同步做题,做对了最难题IMO是历史最悠久、规模最大、最负
 PRO | 为什么基于 MoE 的大模型更值得关注?
Aug 07, 2024 pm 07:08 PM
PRO | 为什么基于 MoE 的大模型更值得关注?
Aug 07, 2024 pm 07:08 PM
2023年,几乎AI的每个领域都在以前所未有的速度进化,同时,AI也在不断地推动着具身智能、自动驾驶等关键赛道的技术边界。多模态趋势下,Transformer作为AI大模型主流架构的局面是否会撼动?为何探索基于MoE(专家混合)架构的大模型成为业内新趋势?大型视觉模型(LVM)能否成为通用视觉的新突破?...我们从过去的半年发布的2023年本站PRO会员通讯中,挑选了10份针对以上领域技术趋势、产业变革进行深入剖析的专题解读,助您在新的一年里为大展宏图做好准备。本篇解读来自2023年Week50
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 Nature观点,人工智能在医学中的测试一片混乱,应该怎么做?
Aug 22, 2024 pm 04:37 PM
Nature观点,人工智能在医学中的测试一片混乱,应该怎么做?
Aug 22, 2024 pm 04:37 PM
编辑|ScienceAI基于有限的临床数据,数百种医疗算法已被批准。科学家们正在讨论由谁来测试这些工具,以及如何最好地进行测试。DevinSingh在急诊室目睹了一名儿科患者因长时间等待救治而心脏骤停,这促使他探索AI在缩短等待时间中的应用。Singh利用了SickKids急诊室的分诊数据,与同事们建立了一系列AI模型,用于提供潜在诊断和推荐测试。一项研究表明,这些模型可以加快22.3%的就诊速度,将每位需要进行医学检查的患者的结果处理速度加快近3小时。然而,人工智能算法在研究中的成功只是验证此
 准确率达60.8%,浙大基于Transformer的化学逆合成预测模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
准确率达60.8%,浙大基于Transformer的化学逆合成预测模型,登Nature子刊
Aug 06, 2024 pm 07:34 PM
编辑|KX逆合成是药物发现和有机合成中的一项关键任务,AI越来越多地用于加快这一过程。现有AI方法性能不尽人意,多样性有限。在实践中,化学反应通常会引起局部分子变化,反应物和产物之间存在很大重叠。受此启发,浙江大学侯廷军团队提出将单步逆合成预测重新定义为分子串编辑任务,迭代细化目标分子串以生成前体化合物。并提出了基于编辑的逆合成模型EditRetro,该模型可以实现高质量和多样化的预测。大量实验表明,模型在标准基准数据集USPTO-50 K上取得了出色的性能,top-1准确率达到60.8%。
