

WAIT: synchronous replication for Redis

Redis unstable has a new command called "WAIT". Such a simple name, is indeed the incarnation of a simple feature consisting of less than 200 lines of code, but providing an interesting way to change the default behavior of Redis replicati
Redis unstable has a new command called "WAIT". Such a simple name, is indeed the incarnation of a simple feature consisting of less than 200 lines of code, but providing an interesting way to change the default behavior of Redis replication.The feature was extremely easy to implement because of previous work made. WAIT was basically a direct consequence of the new Redis replication design (that started with Redis 2.8). The feature itself is in a form that respects the design of Redis, so it is relatively different from other implementations of synchronous replication, both at API level, and from the point of view of the degree of consistency it is able to ensure.
Replication: synchronous or not?
===
Replication is one of the main concepts of distributed systems. For some state to be durable even when processes fail or when there are network partitions making processes unable to communicate, we are forced to use a simple but effective strategy, that is to take the same information “replicated” across different processes (database nodes).
Every kind of system featuring strong consistency will use a form of replication called synchronous replication. It means that before some new data is considered “committed”, a node requires acknowledge from other nodes that the information was received. The node initially proposing the new state, when the acknowledge is received, will consider the information committed and will reply to the client that everything went ok.
There is a price to pay for this safety: latency. Systems implementing strong consistency are unable to reply to the client before receiving enough acknowledges. How many acks are “enough”? This depends on the kind of system you are designing. For example in the case of strong consistent systems that are available as long as the majority of nodes are working, the majority of the nodes should reply back before some data is considered to be committed. The result is that the latency is bound to the slowest node that replies as the (N/2+1)th node. Slower nodes can be ignored once the majority is reached.
Asynchronous replication
===
This is why asynchronous replication exists: in this alternative model we reply to the client confirming its write BEFORE we get acknowledges from other nodes.
If you think at it from the point of view of CAP, it is like if the node *pretends* that there is a partition and can’t talk with the other nodes. The information will eventually be replicated at a latter time, exactly like an eventually consistent DB would do during a partition. Usually this latter time will be a few hundred microseconds later, but if the node receiving the write fails before propagating the write, but after it already sent the reply to the client, the write is lost forever even if it was acknowledged.
Redis uses asynchronous replication by default: Redis is designed for performances and low, easy to predict, latency. However if possible it is nice for a system to be able to adapt consistency guarantees depending on the kind of write, so some form of synchronous replication could be handy even for Redis.
WAIT: call me synchronous if you want.
===
The way I depicted synchronous replication above, makes it sound simpler than it actually is.
The reality is that usually synchronous replication is “transactional”, so that a write is propagated to the majority of nodes (or *all* the nodes with some older algorithm), or none, in one way or the other not only the node proposing the state change must wait for a reply from the majority, but also the other nodes need to wait for the proposing node to consider the operation committed in order to, in turn, commit the change. Replicas require in one way or the other a mechanism to collect the write without applying it, basically.
This means that nothing happens during this process, everything is blocked for the current operation, and later you can process a new one, and so forth and so forth.
Because synchronous replication can be very costly, maybe we can do with a bit less? We want a way to make sure some write propagated across the replicas, but at the same time we want other clients to go at light speed as usually sending commands and receiving replies. Clients waiting in a synchronous write should never block any other client doing other synchronous or non-synchronous work.
There is a tradeoff you can take: WAIT does not allow to rollback an operation that was not propagated to enough slaves. It only offers, merely, a way to inform the client about what happened.
The information, specifically, is the number of replicas that your write was able to reach, all this encapsulated into a simple to use blocking command.
This is how it works:
redis 127.0.0.1:9999> set foo bar
OK
redis 127.0.0.1:9999> incr mycounter
(integer) 1
redis 127.0.0.1:9999> wait 5 100
(integer) 7
Basically you can send any number of commands, and they’ll be executed, and replicated as usually.
As soon as you call WAIT however the client stops until all the writes above are successfully replicated to the specified number of replicas (5 in the example), unless the timeout is reached (100 milliseconds in the example).
Once one of the two limits is reached, that is, the master replicated to 5 replicas, or the timeout was reached, the command returns, sending as reply the number of replicas reached. If the return value is less than the replicas we specified, the request timed out, otherwise the above commands were successfully replicated to the specified number of replicas.
In practical terms this means that you have to deal with the condition in which the command was accepted by less replicas you specified in the amount of time you specified. More about that later.
How it works?
===
The WAIT implementation is surprisingly simple. The first thing I did was to take the blocking code of BLPOP & other similar operations and make it a generic primitive of Redis internal API, so now implementing blocking commands is much simpler.
The rest of the implementation was trivial because 2.8 introduced the concept of master replication offset, that is, a global offset that we increment every time we send something to the slaves. All the salves receive exactly the same stream of data, and remember the offset processed so far as well.
This is very useful for partial resynchronization as you can guess, but moreover slaves acknowledge the amount of replication offset processed so far, every second, with the master, so the master has some idea about how much they processed.
Every second sucks right? We can’t base WAIT on an information available every second. So when WAIT is used by a client, it sets a flag, so that all the WAIT callers in a given event loop iteration will be grouped together, and before entering the event loop again we send a REPLCONF GETACK command into the replication stream. Slaves will reply ASAP with a new ACK.
As soon as the ACKs received from slaves is enough to unblock some client, we do it. Otherwise we unblock the client on timeout.
Not considering the refactoring needed for the block operations that is technically not part of the WAIT implementation, all the code is like 170 lines of code, so very easy to understand, modify, and with almost zero effects on the rest of the code base.
Living with the indetermination
===
WAIT does not offer any “transactional” feature to commit a write to N nodes or nothing, but provides information about the degree of durability we achieved with our write, in an easy to use form that does not slow down operations of other clients.
How this improves consistency in Redis land? Let’s look at the following pseudo code:
def save_payment(payment_id)
redis.set(payment_id,”confirmed”)
end
We can imagine that the function save_payment is called every time an user payed for something, and we want to store this information in our database. Now imagine that there are a number of clients processing payments, so the function above gets called again and again.
In Redis 2.6 if there was an issue communicating with the replicas, while running the above code, it was impossible to sense the problem in time. The master failing could result in replicas missing a number of writes.
In Redis 2.8 this was improved by providing options to stop accepting writes if there are problems communicating with replicas. Redis can check if there are at least N replicas that appear to be alive (pinging back the master) in this setup. With this option we improved the consistency guarantees a bit, now there is a maximum window to write to a master that is not backed by enough replicas.
With WAIT we can finally considerably improve how much safe are our writes, since I can modify the code in the following way:
def save_payment(payment_id)
redis.set(payment_id,”confirmed”)
if redis.wait(3,1000) >= 3 then
return true
else
return false
end
In the above version of the program we finally gained some information about what happened to the write, even if we actually did not changed the outcome of the write, we are now able to report back this information to the caller.
However what to do if wait returns less than 3? Maybe we could try to revert our write sending redis.del(payment_id)? Or we can try to set the value again in order to succeed the next time?
With the above code we are exposing our system to too much troubles. In a given moment if only two slaves are accepting writes all the transactions will have to deal with this inconsistency, whatever it is handled. There is a better thing we can do, modifying the code in a way so that it actually does not set a value, but takes a list of events about the transaction, using Redis lists:
def save_payment(payment_id)
redis.rpush(payment_id,”in progress”) # Return false on exception
if redis.wait(3,1000) >= 3 then
redis.rpush(payment_id,”confirmed”) # Return false on exception
if redis.wait(3,1000) >= 3 then
return true
else
redis.rpush(payment_id,”cancelled”)
return false
end
else
return false
end
Here we push an “in progress” state into the list for this payment ID before to actually confirming it. If we can’t reach enough replicas we abort the payment, and it will not have the “confirmed” element. In this way if there are only two replicas getting writes the transactions will fail one after the other. The only clients that will have the deal with inconsistencies are the clients that are able to propagate “in progress” to 3 or more replicas but are not able to do the same with the “confirmed” write. In the above code we try to deal with this issue with a best-effort “cancelled” write, however there is still the possibility of a race condition:
1) We send “in progress”
2) We send “confirmed”, it only reaches 2 slaves.
3) We send “cancelled” but at this point the master crashed and a failover elected one of the slaves.
So in the above case we returned a failed transaction while actually the “confirmed” state was written.
You can do different things to deal better with this kind of issues, that is, to mark the transaction as “broken” in a strong consistent and highly available system like Zookeeper, to write a log in the local client, to put it in the hands of a message queue that is designed with some redundancy, and so forth.
Synchronous replication and failover: two close friends
===
Synchronous replication is important per se because it means, there are N copies of this data around, however to really exploit the improved data safety, we need to make sure that when a master node fails, and a slave is elected, we get the best slave.
The new implementation of Sentinel already elects the slave with the best replication offset available, assuming it publishes its replication offset via INFO (that is, it must be Redis 2.8 or greater), so a good setup can be to run an odd number of Redis nodes, with a Redis Sentinel installed in every node, and use synchronous replication to write to the majority of nodes. As long as the majority of the nodes is available, a Sentinel will be able to win the election and elect a slave with the most updated data.
Redis cluster is currently not able to elect the slave with the best replication offset, but will be able to do that before the stable release. It is also conceivable that Redis Cluster will have an option to only promote a slave if the majority of replicas for a given hash slot are reachable.
I just scratched the surface of synchronous replication, but I believe that this is a building block that we Redis users will be able to exploit in the future to stretch Redis capabilities to cover new needs for which Redis was traditionally felt as inadequate. Comments

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 F5刷新密钥在Windows 11中不起作用
Mar 14, 2024 pm 01:01 PM
F5刷新密钥在Windows 11中不起作用
Mar 14, 2024 pm 01:01 PM
您的Windows11/10PC上的F5键是否无法正常工作?F5键通常用于刷新桌面或资源管理器或重新加载网页。然而,我们的一些读者报告说,F5键正在刷新他们的计算机,并且无法正常工作。如何在Windows11中启用F5刷新?要刷新您的WindowsPC,只需按下F5键即可。在某些笔记本电脑或台式机上,您可能需要按下Fn+F5组合键才能完成刷新操作。为什么F5刷新不起作用?如果按下F5键无法刷新您的电脑或在Windows11/10上遇到问题,可能是由于功能键被锁定所致。其他潜在原因包括键盘或F5键
 Java中sleep和wait方法有什么区别
May 06, 2023 am 09:52 AM
Java中sleep和wait方法有什么区别
May 06, 2023 am 09:52 AM
一、sleep和wait方法的区别根本区别:sleep是Thread类中的方法,不会马上进入运行状态,wait是Object类中的方法,一旦一个对象调用了wait方法,必须要采用notify()和notifyAll()方法唤醒该进程释放同步锁:sleep会释放cpu,但是sleep不会释放同步锁的资源,wait会释放同步锁资源使用范围:sleep可以在任何地方使用,但wait只能在synchronized的同步方法或是代码块中使用异常处理:sleep需要捕获异常,而wait不需要捕获异常二、wa
 win7按f8怎么一键还原电脑系统
Jul 13, 2023 pm 12:17 PM
win7按f8怎么一键还原电脑系统
Jul 13, 2023 pm 12:17 PM
在Windows7中计算机的修复和恢复功能得到了加强和改进,当我们的计算机出现故障或需要恢复备份时,可以通过在启动时按下F8键激活Windows的“高级启动选项”,然后进行还原系统,下面就来看看如何操作吧。1、首先单击Windows开始图标,在“搜索程序和文件”输入框中键入“cmd”,在搜索结果中用鼠标右键单击“cmd.exe”,并在弹出的列表中单击“以管理员身份运行”。2、然后,在打开的命令行环境下键入“reagentc/info”,并按下“回车”键。之后会出现WindowsRE的相关信息。如
 无法使用F8键进入win10安全模式
Jan 03, 2024 pm 07:16 PM
无法使用F8键进入win10安全模式
Jan 03, 2024 pm 07:16 PM
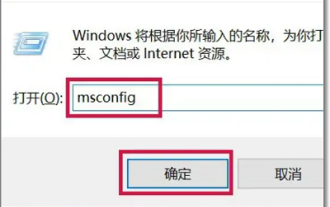
很多用户在操作电脑的时候发现按F8却无法进入到安全模式里面,我们可以进入组策略里面进行修改和调整,具体的方法还是很简单的,只需要跟着下面的步骤来操作就可以了。win10按f8无法进入安全模式1、按下win+R,然后输入“MSConfig”2、点击上面的“引导”,再点击“安全引导”3、弹出对话框里面,你点击重新启动就可以进入安全模式了。4、如果你不进入安全模式的话,那就回去点击“正常启动”就可以了。
 Java中如何使用wait和notify实现线程间的通信
Apr 22, 2023 pm 12:01 PM
Java中如何使用wait和notify实现线程间的通信
Apr 22, 2023 pm 12:01 PM
一.为什么需要线程通信线程是并发并行的执行,表现出来是线程随机执行,但是我们在实际应用中对线程的执行顺序是有要求的,这就需要用到线程通信线程通信为什么不使用优先级来来解决线程的运行顺序?总的优先级是由线程pcb中的优先级信息和线程等待时间共同决定的,所以一般开发中不会依赖优先级来表示线程的执行顺序看下面这样的一个场景:面包房的例子来描述生产者消费者模型有一个面包房,里面有面包师傅和顾客,对应我们的生产者和消费者,而面包房有一个库存用来存储面包,当库存满了之后就不在生产,同时消费者也在购买面包,当
 MySQL同步数据Replication如何实现
May 26, 2023 pm 03:22 PM
MySQL同步数据Replication如何实现
May 26, 2023 pm 03:22 PM
MySQL提供了Replication功能,可以实现将一个数据库的数据同步到多台其他数据库。前者通常称之为主库(master),后者则被称从库(slave)。MySQL复制过程采用异步方式,但延时非常小,秒级同步。一、同步复制数据基本原理1.在主库上发生的数据变化记录到二进制日志Binlog2.从库的IO线程将主库的Binlog复制到自己的中继日志Relaylog3.从库的SQL线程通过读取、重放中继日志实现数据复制MySQL的复制有三种模式:StatementLevel、RowLevel、Mi
 深入理解Java多线程编程:高级应用wait和notify方法
Dec 20, 2023 am 08:10 AM
深入理解Java多线程编程:高级应用wait和notify方法
Dec 20, 2023 am 08:10 AM
Java中的多线程编程:掌握wait和notify的高级用法引言:多线程编程是Java开发中常见的技术,面对复杂的业务处理和性能优化需求,合理利用多线程可以极大地提高程序的运行效率。在多线程编程中,wait和notify是两个重要的关键字,用于实现线程间的协调和通信。本文将介绍wait和notify的高级用法,并提供具体的代码示例,以帮助读者更好地理解和应用
 探究Java中对象方法wait和notify的内部实现机制
Dec 20, 2023 pm 12:47 PM
探究Java中对象方法wait和notify的内部实现机制
Dec 20, 2023 pm 12:47 PM
深入理解Java中的对象方法:wait和notify的底层实现原理,需要具体代码示例Java中的对象方法wait和notify是用于实现线程间通信的关键方法,它们的底层实现原理涉及到Java虚拟机的监视器机制。本文将深入探讨这两个方法的底层实现原理,并提供具体的代码示例。首先,我们来了解wait和notify的基本用途。wait方法的作用是使当前线程释放对象
