

釋放 MongoDB:為什麼基於遊標的分頁每次都優於基於偏移量的分頁!

分頁是處理大型資料集時任何資料庫操作的關鍵部分。它允許您將資料分割成可管理的區塊,從而更容易瀏覽、處理和顯示。 MongoDB 提供了兩種常見的分頁方法:基於偏移量和基於遊標。雖然這兩種方法具有相同的目的,但它們在效能和可用性方面顯著不同,尤其是隨著資料集的成長。
讓我們深入研究這兩種方法,看看為什麼基於遊標的分頁通常優於基於偏移量的分頁。
1. 基於偏移量的分頁
基於偏移量的分頁非常簡單。它檢索從給定偏移量開始的特定數量的記錄。例如,第一頁可能檢索記錄 0-9,第二頁檢索記錄 10-19,依此類推。
但是,這種方法有一個顯著的缺點:當您移動到更高的頁面時,查詢會變得更慢。這是因為資料庫需要跳過前幾頁的記錄,這涉及掃描它們。
這是基於偏移量的分頁代碼:
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
2. 基於遊標的分頁
基於遊標的分頁,也稱為鍵集分頁,依賴唯一識別碼(例如 ID 或時間戳記)來對記錄進行分頁。它不會跳過一定數量的記錄,而是使用最後檢索到的記錄作為取得下一組記錄的參考點。
這種方法更有效率,因為它避免了掃描目前頁面之前的記錄。因此,無論您深入資料集多深,查詢時間都保持一致。
這是基於遊標的分頁代碼:
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
在此範例中,lastDocumentId 是上一頁中最後一個文件的 ID。當查詢下一頁時,資料庫會取得ID大於該值的文檔,確保無縫過渡到下一組記錄。
3. 性能比較
讓我們看看這兩種方法如何在大型資料集上執行。
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
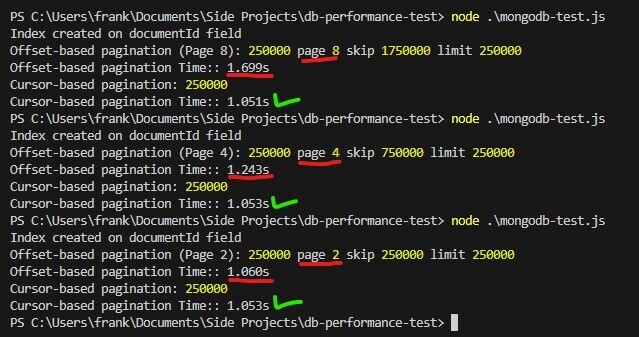
在效能測試中,您會注意到基於偏移分頁需要更長,因為頁碼增加,而遊標基於的分頁保持一致,使其成為大型資料集的更好選擇。此範例還展示了索引的強大功能。嘗試刪除索引然後查看結果!
為什麼索引很重要
如果沒有索引,MongoDB 將需要執行集合掃描,這意味著它必須查看集合中的每個文件以查找相關資料。這是低效的,尤其是當資料集成長時。索引可以讓 MongoDB 有效率地找到符合您查詢條件的文檔,顯著提升查詢效能。
在基於遊標的分頁上下文中,索引可確保快速取得下一組文件(基於 documentId),並且不會隨著更多文件添加到集合中而降低效能。
結論
雖然基於偏移的分頁很容易實現,但由於需要掃描記錄,因此對於大型資料集來說它可能會變得低效。另一方面,基於遊標的分頁提供了更具可擴展性的解決方案,無論資料集大小如何,都可以保持效能一致。如果您在 MongoDB 中處理大型集合,值得考慮基於遊標的分頁以獲得更流暢、更快的體驗。
這是您在本地運行的完整index.js:
const { MongoClient } = require("mongodb");
const uri = "mongodb://localhost:27017";
const client = new MongoClient(uri);
client.connect();
const db = client.db("testdb");
const collection = db.collection("testCollection");
async function insertMongoDBRecords() {
try {
let bulkOps = [];
for (let i = 0; i < 2000000; i++) {
bulkOps.push({
insertOne: {
documentId: i,
name: `Record-${i}`,
value: Math.random() * 1000,
},
});
// Execute every 10000 operations and reinitialize
if (bulkOps.length === 10000) {
await collection.bulkWrite(bulkOps);
bulkOps = [];
}
}
if (bulkOps.length > 0) {
await collection.bulkWrite(bulkOps);
console.log("? Inserted records till now -> ", bulkOps.length);
}
console.log("MongoDB Insertion Completed");
} catch (err) {
console.error("Error in inserting records", err);
}
}
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
testMongoDB();
以上是釋放 MongoDB:為什麼基於遊標的分頁每次都優於基於偏移量的分頁!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 JavaScript引擎:比較實施
Apr 13, 2025 am 12:05 AM
JavaScript引擎:比較實施
Apr 13, 2025 am 12:05 AM
不同JavaScript引擎在解析和執行JavaScript代碼時,效果會有所不同,因為每個引擎的實現原理和優化策略各有差異。 1.詞法分析:將源碼轉換為詞法單元。 2.語法分析:生成抽象語法樹。 3.優化和編譯:通過JIT編譯器生成機器碼。 4.執行:運行機器碼。 V8引擎通過即時編譯和隱藏類優化,SpiderMonkey使用類型推斷系統,導致在相同代碼上的性能表現不同。
 Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:學習曲線和易用性
Apr 16, 2025 am 12:12 AM
Python更適合初學者,學習曲線平緩,語法簡潔;JavaScript適合前端開發,學習曲線較陡,語法靈活。 1.Python語法直觀,適用於數據科學和後端開發。 2.JavaScript靈活,廣泛用於前端和服務器端編程。
 從C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
從C/C到JavaScript:所有工作方式
Apr 14, 2025 am 12:05 AM
從C/C 轉向JavaScript需要適應動態類型、垃圾回收和異步編程等特點。 1)C/C 是靜態類型語言,需手動管理內存,而JavaScript是動態類型,垃圾回收自動處理。 2)C/C 需編譯成機器碼,JavaScript則為解釋型語言。 3)JavaScript引入閉包、原型鍊和Promise等概念,增強了靈活性和異步編程能力。
 JavaScript和Web:核心功能和用例
Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例
Apr 18, 2025 am 12:19 AM
JavaScript在Web開發中的主要用途包括客戶端交互、表單驗證和異步通信。 1)通過DOM操作實現動態內容更新和用戶交互;2)在用戶提交數據前進行客戶端驗證,提高用戶體驗;3)通過AJAX技術實現與服務器的無刷新通信。
 JavaScript在行動中:現實世界中的示例和項目
Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目
Apr 19, 2025 am 12:13 AM
JavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。
 了解JavaScript引擎:實施詳細信息
Apr 17, 2025 am 12:05 AM
了解JavaScript引擎:實施詳細信息
Apr 17, 2025 am 12:05 AM
理解JavaScript引擎內部工作原理對開發者重要,因為它能幫助編寫更高效的代碼並理解性能瓶頸和優化策略。 1)引擎的工作流程包括解析、編譯和執行三個階段;2)執行過程中,引擎會進行動態優化,如內聯緩存和隱藏類;3)最佳實踐包括避免全局變量、優化循環、使用const和let,以及避免過度使用閉包。
 Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社區,圖書館和資源
Apr 15, 2025 am 12:16 AM
Python和JavaScript在社區、庫和資源方面的對比各有優劣。 1)Python社區友好,適合初學者,但前端開發資源不如JavaScript豐富。 2)Python在數據科學和機器學習庫方面強大,JavaScript則在前端開發庫和框架上更勝一籌。 3)兩者的學習資源都豐富,但Python適合從官方文檔開始,JavaScript則以MDNWebDocs為佳。選擇應基於項目需求和個人興趣。
 Python vs. JavaScript:開發環境和工具
Apr 26, 2025 am 12:09 AM
Python vs. JavaScript:開發環境和工具
Apr 26, 2025 am 12:09 AM
Python和JavaScript在開發環境上的選擇都很重要。 1)Python的開發環境包括PyCharm、JupyterNotebook和Anaconda,適合數據科學和快速原型開發。 2)JavaScript的開發環境包括Node.js、VSCode和Webpack,適用於前端和後端開發。根據項目需求選擇合適的工具可以提高開發效率和項目成功率。
