
本篇文章给大家分享的内容是3利用python如何爬取js里面的内容 ,有着一定的参考价值,有需要的朋友可以参考一下
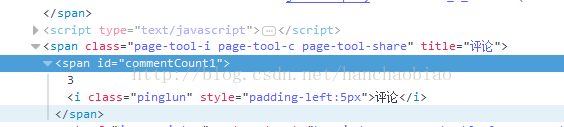
一、在编写爬虫软件获取所需内容时可能会碰到所需要的内容是由javascript添加上去的 在获取的时候为空 比如我们在获取新浪新闻的评论数时使用普通的方法就无法获取
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
此时所获取的结果为空 这是由于内容是存储在js文件中
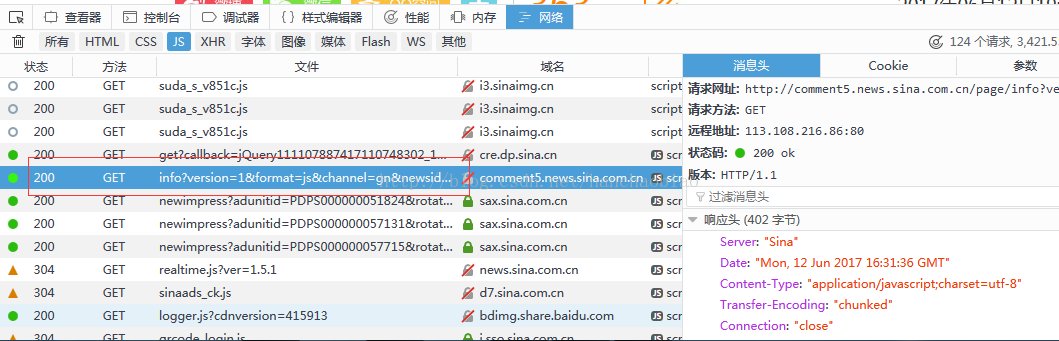
因此我们需要取寻找存储评论内容的js 经过查找我们发现其存储在改js里
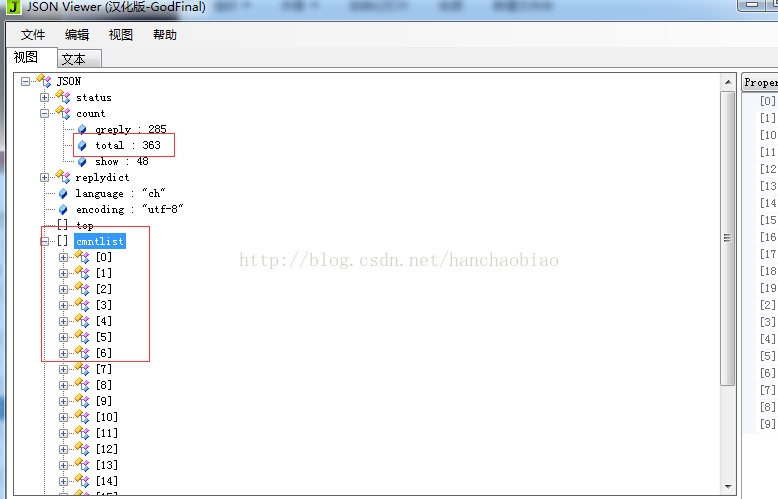
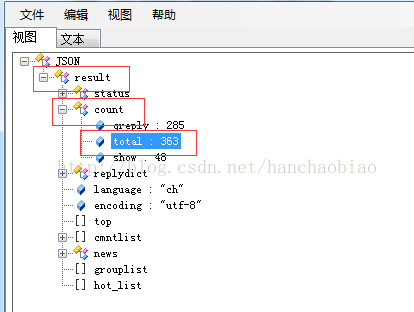
将相应内容放入json数据查看器中我们发现评论总数和评论内容都在该js文件中一json格式存放
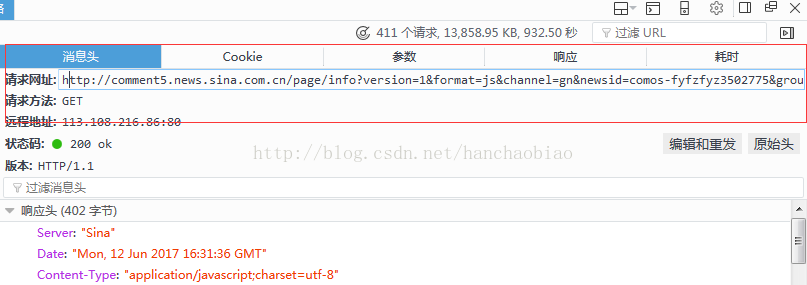
在消息头中我们可以看的该js文件的访问路径及请求方式
代码示例
import json comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783') comments.encoding = 'utf-8' print(comments) jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据 print(jd['result']['count']['total'])
注释:这里解释下为何需要移除 var data= 因为在获取时字符串前缀是包含var data=的 其不符合json数据格式 因此转化时需将其从请求内容中移除
取评论总数时为何使用jd['result']['count']['total']
以上就是利用python如何爬取js里面的内容的详细内容,更多请关注php中文网其它相关文章!




Copyright 2014-2024 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号




































 0
0 30
30











![ThinkPHP5实战之[教学管理系统]](https://img.php.cn/upload/course/000/000/068/6253d87459486427.png)











