
 Peranti teknologi
AI
Apa-apa sahaja dalam Mana-mana Scene: Sisipan objek realistik (untuk membantu dalam sintesis pelbagai data pemanduan)
Peranti teknologi
AI
Apa-apa sahaja dalam Mana-mana Scene: Sisipan objek realistik (untuk membantu dalam sintesis pelbagai data pemanduan)
Apa-apa sahaja dalam Mana-mana Scene: Sisipan objek realistik (untuk membantu dalam sintesis pelbagai data pemanduan)

Tajuk asal: Anything in Any Scene: Photorealistic Video Object Insertion
Pautan kertas: https://arxiv.org/pdf/2401.17509.pdf
Pautan kod: https://github.com/Anything/anything
Gabungan pengarang: Xpeng Motors

Idea tesis
Simulasi video yang realistik telah menunjukkan potensi yang besar dalam pelbagai bidang aplikasi daripada realiti maya kepada penghasilan filem. Lebih-lebih lagi jika merakam video di dunia nyata adalah tidak praktikal atau mahal. Kaedah sedia ada dalam simulasi video sering gagal memodelkan persekitaran pencahayaan dengan tepat, mewakili geometri objek atau mencapai fotorealisme tahap tinggi. Kertas kerja ini mencadangkan Anything in Any Scene, rangka kerja simulasi video sebenar yang novel dan serba boleh yang boleh memasukkan sebarang objek dengan lancar ke dalam video dinamik sedia ada dan menekankan realisme fizikal. Rangka kerja keseluruhan yang dicadangkan dalam kertas kerja ini mengandungi tiga proses utama: 1) menyepadukan objek sebenar ke dalam video pemandangan yang diberikan dan meletakkannya di lokasi yang sesuai untuk memastikan realisme geometri 2) menganggar taburan pencahayaan langit dan ambien dan Simulasi bayang-bayang sebenar dan meningkatkan realisme cahaya; 3) Gunakan rangkaian pemindahan gaya untuk memperhalusi output video akhir untuk memaksimumkan realisme foto. Artikel ini secara eksperimen membuktikan bahawa rangka kerja Anything in Any Scene boleh menjana video simulasi dengan realisme geometri, realisme pencahayaan dan realisme foto yang sangat baik. Dengan mengurangkan cabaran yang berkaitan dengan penjanaan data video dengan ketara, rangka kerja kami menyediakan penyelesaian yang cekap dan kos efektif untuk mendapatkan video berkualiti tinggi. Tambahan pula, aplikasinya melangkaui peningkatan data video, menunjukkan potensi yang menjanjikan dalam realiti maya, penyuntingan video dan pelbagai aplikasi tertumpu video lain.
Sumbangan Utama
Kertas kerja ini memperkenalkan rangka kerja simulasi video novel dan boleh diperluaskan dalam Anything in Any Scene, yang mampu menyepadukan sebarang objek ke dalam mana-mana video adegan dinamik.
Artikel ini berstruktur unik dan memfokuskan pada mengekalkan geometri, pencahayaan dan fotorealisme dalam simulasi video untuk memastikan kualiti tinggi dan ketulenan hasil output.
Selepas pengesahan meluas, keputusan menunjukkan bahawa rangka kerja itu mempunyai keupayaan untuk menghasilkan simulasi video yang sangat realistik, sekali gus meluaskan skop aplikasi dan potensi pembangunan bidang ini dengan ketara.
Reka Bentuk Tesis
Simulasi imej dan video berjaya digunakan dalam pelbagai aplikasi daripada realiti maya kepada penghasilan filem. Keupayaan untuk menjana kandungan visual yang pelbagai dan berkualiti tinggi melalui simulasi imej dan video fotorealistik berpotensi untuk memajukan bidang ini, memperkenalkan kemungkinan dan aplikasi baharu. Walaupun ketulenan imej dan video yang ditangkap di dunia nyata tidak ternilai, ia selalunya dihadkan oleh pengedaran ekor panjang. Ini membawa kepada perwakilan yang berlebihan bagi senario biasa dan kurang representasi situasi yang jarang berlaku tetapi kritikal, memberikan cabaran yang dikenali sebagai masalah luar pengedaran. Kaedah tradisional untuk menangani batasan ini melalui tangkapan dan penyuntingan video terbukti tidak praktikal atau kos tinggi kerana sukar untuk menampung semua senario yang mungkin. Kepentingan simulasi video, terutamanya dengan menyepadukan video sedia ada dengan objek yang baru dimasukkan, menjadi penting untuk mengatasi cabaran ini. Dengan menjana kandungan visual berskala besar, pelbagai dan realistik, simulasi video membantu menambah aplikasi dalam realiti maya, pengeditan video dan penambahan data video.
Walau bagaimanapun, menjana video simulasi realistik memandangkan realisme fizikal masih merupakan masalah terbuka yang mencabar. Kaedah sedia ada sering mempamerkan batasan dengan memfokuskan pada tetapan tertentu, terutamanya persekitaran dalaman [9, 26, 45, 46, 57]. Kaedah ini mungkin tidak menangani kerumitan pemandangan luar dengan secukupnya, termasuk keadaan pencahayaan yang berbeza-beza dan objek yang bergerak pantas. Kaedah bergantung pada pendaftaran model 3D adalah terhad untuk menyepadukan kelas terhad objek [12, 32, 40, 42]. Banyak kaedah mengabaikan faktor penting seperti pemodelan persekitaran pencahayaan, penempatan objek yang betul, dan mencapai realisme [12, 36]. Kes yang gagal ditunjukkan dalam Rajah 1. Oleh itu, pengehadan ini sangat mengehadkan penggunaannya dalam kawasan yang memerlukan simulasi video adegan yang sangat berskala, konsisten dari segi geometri dan realistik, seperti pemanduan autonomi dan robotik.
Kertas kerja ini mencadangkan Anything in Any Scene, rangka kerja komprehensif untuk sisipan objek video fotorealistik yang menangani cabaran ini. Rangka kerja ini direka bentuk untuk serba boleh dan sesuai untuk adegan dalaman dan luaran, memastikan ketepatan fizikal dari segi realisme geometri, realisme pencahayaan dan fotorealisme. Matlamat artikel ini adalah untuk mencipta simulasi video yang bukan sahaja berguna untuk penambahan data visual dalam pembelajaran mesin, tetapi juga sesuai untuk pelbagai aplikasi video seperti realiti maya dan penyuntingan video.
Gambaran keseluruhan rangka kerja Anything in Any Scene artikel ini ditunjukkan dalam Rajah 2. Kertas kerja ini memperincikan novel dan saluran paip berskala kami untuk membina perpustakaan aset pelbagai video adegan dan jerat objek dalam Bahagian 3. Kertas kerja ini memperkenalkan enjin pertanyaan data visual yang direka untuk mendapatkan semula klip video yang berkaitan dengan cekap daripada pertanyaan visual menggunakan kata kunci deskriptif. Seterusnya, kertas kerja ini mencadangkan dua kaedah untuk menghasilkan jejaring 3D, memanfaatkan aset 3D sedia ada serta pembinaan semula imej berbilang paparan. Ini membenarkan pemasukan tanpa had bagi mana-mana objek yang diingini, walaupun ia sangat tidak teratur atau lemah dari segi semantik. Dalam Bahagian 4, kertas memperincikan kaedah untuk menyepadukan objek ke dalam video adegan dinamik, memfokuskan pada mengekalkan realisme fizikal. Kertas kerja ini mereka bentuk penempatan objek dan kaedah penstabilan yang diterangkan dalam Bahagian 4.1 untuk memastikan objek yang dimasukkan berlabuh secara stabil pada bingkai video berturut-turut. Untuk menangani cabaran mencipta pencahayaan dan kesan bayang yang realistik, kertas kerja ini menganggarkan pencahayaan langit dan persekitaran serta menghasilkan bayang-bayang realistik semasa pemaparan, seperti yang diterangkan dalam Bahagian 4.2. Bingkai video simulasi yang dijana pastinya mengandungi artifak tidak realistik yang berbeza daripada video yang ditangkap dunia sebenar, seperti perbezaan kualiti pengimejan dalam tahap hingar, kesetiaan warna dan ketajaman. Kertas kerja ini menggunakan rangkaian pemindahan gaya untuk meningkatkan realisme foto dalam Bahagian 4.3.
Video simulasi yang dijana daripada rangka kerja yang dicadangkan dalam artikel ini mencapai tahap realisme pencahayaan, realisme geometri dan realisme foto yang tinggi, mengatasi prestasi video lain dalam kualiti dan kuantiti, seperti yang ditunjukkan dalam Bahagian 5.3. Artikel ini menunjukkan lagi aplikasi video simulasi artikel ini dalam algoritma persepsi latihan dalam Bahagian 5.4 untuk mengesahkan nilai praktikalnya. Rangka kerja Anything in Any Scene membolehkan penciptaan set data video berskala besar dan kos rendah untuk penambahan data dengan kecekapan masa dan kualiti visual yang realistik, dengan itu meringankan beban penjanaan data video dan berpotensi menambah baik long-tail dan out-of- cabaran pengedaran. Dengan reka bentuk rangka kerja amnya, rangka kerja Anything in Any Scene boleh dengan mudah menyepadukan model yang dipertingkatkan dan modul baharu, seperti kaedah pembinaan semula jaringan 3D yang dipertingkatkan, untuk meningkatkan lagi prestasi simulasi video.
 Rajah 1. Contoh bingkai video simulasi dengan ralat dalam anggaran persekitaran pencahayaan, ralat dalam peletakan objek dan gaya tekstur yang tidak realistik.
Rajah 1. Contoh bingkai video simulasi dengan ralat dalam anggaran persekitaran pencahayaan, ralat dalam peletakan objek dan gaya tekstur yang tidak realistik. 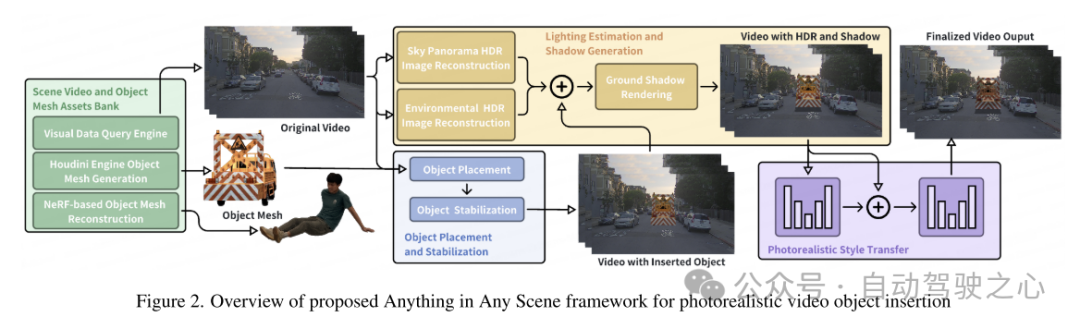 Rajah 2. Gambaran keseluruhan rangka kerja Anything in Any Scene untuk sisipan objek video fotorealistik
Rajah 2. Gambaran keseluruhan rangka kerja Anything in Any Scene untuk sisipan objek video fotorealistik  Rajah 3. Contoh video adegan memandu untuk penempatan objek. Titik merah dalam setiap imej adalah tempat objek dimasukkan.
Rajah 3. Contoh video adegan memandu untuk penempatan objek. Titik merah dalam setiap imej adalah tempat objek dimasukkan.
Experimental Results

Figure 4. Contoh -contoh imej langit asal, imej HDR yang direkonstruksikan dan peta pengedaran pencahayaan solar yang berkaitan.
Rajah 6. Contoh penjanaan bayang-bayang untuk objek yang dimasukkan
Rajah 7. Perbandingan kualitatif bingkai video simulasi daripada set data PandaSet menggunakan rangkaian pemindahan gaya yang berbeza. 
Rajah 8. Perbandingan kualitatif bagi bingkai video simulasi daripada set data PandaSet di bawah pelbagai keadaan pemaparan. 

Ringkasan:
Kertas kerja ini mencadangkan rangka kerja yang inovatif dan boleh diperluaskan, "Anything in any Scene", direka untuk simulasi video yang realistik. Rangka kerja yang dicadangkan dalam kertas kerja ini mengintegrasikan pelbagai objek dengan lancar ke dalam video dinamik yang berbeza, memastikan realisme geometri, realisme pencahayaan dan realisme foto dipelihara. Melalui demonstrasi yang meluas, kertas kerja ini menunjukkan keberkesanannya dalam mengurangkan cabaran yang berkaitan dengan pengumpulan dan penjanaan data video, menyediakan penyelesaian yang kos efektif dan menjimatkan masa untuk pelbagai senario. Aplikasi rangka kerja kami menunjukkan peningkatan yang ketara dalam tugas persepsi hiliran, terutamanya dalam menyelesaikan masalah pengedaran ekor panjang dalam pengesanan objek. Fleksibiliti rangka kerja kami membolehkan penyepaduan langsung model yang dipertingkatkan untuk setiap modul, dan rangka kerja kami meletakkan asas yang kukuh untuk penerokaan dan inovasi masa depan dalam bidang simulasi video yang realistik.
Petikan:
Bai C, Shao Z, Zhang G, et al Apa-apa sahaja dalam Mana-mana Pemandangan: Sisipan Objek Video Fotorealistik[J]. arXiv pracetak arXiv:2401.17509, 2024.
Atas ialah kandungan terperinci Apa-apa sahaja dalam Mana-mana Scene: Sisipan objek realistik (untuk membantu dalam sintesis pelbagai data pemanduan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1660
1660
 14
1416
52
1310
25
1259
29
1233
24
14
1416
52
1310
25
1259
29
1233
24

 Cara merakam video skrin dengan telefon OPPO (operasi mudah)
May 07, 2024 pm 06:22 PM
Cara merakam video skrin dengan telefon OPPO (operasi mudah)
May 07, 2024 pm 06:22 PM
Kemahiran permainan atau tunjuk cara mengajar, dalam kehidupan seharian, kita selalunya perlu menggunakan telefon bimbit untuk merakam video skrin untuk menunjukkan beberapa langkah operasi. Fungsinya merakam video skrin juga sangat baik, dan telefon mudah alih OPPO ialah telefon pintar yang berkuasa. Membolehkan anda menyelesaikan tugasan rakaman dengan mudah dan cepat, artikel ini akan memperkenalkan secara terperinci cara menggunakan telefon mudah alih OPPO untuk merakam video skrin. Persediaan - Tentukan matlamat rakaman Anda perlu menjelaskan matlamat rakaman anda sebelum anda memulakan. Adakah anda ingin merakam video demonstrasi langkah demi langkah? Atau mahu merakam detik indah permainan? Atau ingin merakam video pengajaran? Hanya dengan mengatur proses rakaman yang lebih baik dan matlamat yang jelas. Buka fungsi rakaman skrin telefon mudah alih OPPO dan cari dalam panel pintasan Fungsi rakaman skrin terletak di panel pintasan.
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Cara menukar bahasa dalam Adobe After Effects cs6 (Ae cs6) Langkah terperinci untuk menukar antara bahasa Cina dan Inggeris dalam Ae cs6 - muat turun ZOL
May 09, 2024 pm 02:00 PM
Cara menukar bahasa dalam Adobe After Effects cs6 (Ae cs6) Langkah terperinci untuk menukar antara bahasa Cina dan Inggeris dalam Ae cs6 - muat turun ZOL
May 09, 2024 pm 02:00 PM
1. Mula-mula cari folder AMTLanguages. Kami menemui beberapa dokumentasi dalam folder AMTLanguages. Jika anda memasang Bahasa Cina Ringkas, akan ada dokumen teks zh_CN.txt (kandungan teks ialah: zh_CN). Jika anda memasangnya dalam bahasa Inggeris, akan ada dokumen teks en_US.txt (kandungan teks ialah: en_US). 3. Oleh itu, jika kita ingin bertukar kepada bahasa Cina, kita perlu mencipta dokumen teks baharu zh_CN.txt (kandungan teks ialah: zh_CN) di bawah laluan AdobeAfterEffectsCCSupportFilesAMTLanguages . 4. Sebaliknya, jika kita ingin bertukar kepada bahasa Inggeris,
 Bagaimana untuk merakam video di Douyin? Bagaimana untuk menghidupkan mikrofon untuk rakaman video?
May 09, 2024 pm 02:40 PM
Bagaimana untuk merakam video di Douyin? Bagaimana untuk menghidupkan mikrofon untuk rakaman video?
May 09, 2024 pm 02:40 PM
Sebagai salah satu platform video pendek yang paling popular hari ini, kualiti dan kesan video Douyin secara langsung mempengaruhi pengalaman menonton pengguna. Jadi, bagaimana untuk menangkap video berkualiti tinggi di TikTok? 1. Bagaimana untuk merakam video di Douyin? 1. Buka APP Douyin dan klik butang "+" di bahagian tengah di bahagian bawah untuk memasuki halaman rakaman video. 2. Douyin menyediakan pelbagai mod penangkapan, termasuk penangkapan biasa, gerakan perlahan, video pendek, dsb. Pilih mod penangkapan yang sesuai mengikut keperluan anda. 3. Pada halaman penangkapan, klik butang "Penapis" di bahagian bawah skrin untuk memilih kesan penapis yang berbeza untuk menjadikan video lebih diperibadikan. 4. Jika anda perlu melaraskan parameter seperti pendedahan dan kontras, anda boleh mengklik butang "Parameter" di sudut kiri bawah skrin untuk menetapkannya. 5. Semasa penangkapan, anda boleh klik pada sebelah kiri skrin
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
