
 Peranti teknologi
AI
COCA: Kapsyen kontras adalah model asas teks imej yang dijelaskan secara visual
Peranti teknologi
AI
COCA: Kapsyen kontras adalah model asas teks imej yang dijelaskan secara visual
COCA: Kapsyen kontras adalah model asas teks imej yang dijelaskan secara visual

Tutorial Komuniti DataCamp ini, disunting untuk kejelasan dan ketepatan, meneroka model asas teks imej, yang memberi tumpuan kepada model Captioner Contressve Inovatif (COCA). Coca secara unik menggabungkan objektif pembelajaran yang kontras dan generatif, mengintegrasikan kekuatan model seperti klip dan simvlm menjadi seni bina tunggal.

Model Yayasan: menyelam dalam
Model asas, yang terlatih pada dataset besar-besaran, boleh disesuaikan untuk pelbagai tugas hiliran. Walaupun NLP telah melihat lonjakan model asas (GPT, Bert), model penglihatan dan penglihatan masih berkembang. Penyelidikan telah meneroka tiga pendekatan utama: model penyenaraian tunggal, dwi-pengoder teks imej dengan kehilangan kontras, dan model pengekodkan pengekod dengan objektif generatif. Setiap pendekatan mempunyai batasan.
Istilah utama:
- Model Yayasan: Model pra-terlatih yang boleh disesuaikan untuk pelbagai aplikasi.
- kehilangan kontras: fungsi kerugian membandingkan pasangan input yang serupa dan berbeza.
- Interaksi Cross-Modal: Interaksi antara jenis data yang berbeza (mis., Imej dan teks).
- arsitektur pengekod-decoder: input pemprosesan rangkaian saraf dan menghasilkan output.
- pembelajaran sifar-shot: meramalkan pada kelas data yang tidak kelihatan.
- klip: model pra-training bahasa yang kontras.
- simvlm: model bahasa visual yang mudah.
perbandingan model:
- Model encoder tunggal: Excel pada tugas-tugas penglihatan tetapi berjuang dengan tugas-tugas bahasa penglihatan kerana pergantungan pada anotasi manusia.
- model dual-encoder-teks imej (klip, menyelaraskan): sangat baik untuk klasifikasi sifar-tembakan dan pengambilan imej, tetapi terhad dalam tugas yang memerlukan perwakilan teks imej yang bersatu (mis., Jawab soalan visual). Model Generatif (SIMVLM):
- Gunakan interaksi silang modal untuk perwakilan teks imej bersama, sesuai untuk vqa dan imej imej.
Coca bertujuan menyatukan kekuatan pendekatan yang kontras dan generatif. Ia menggunakan kerugian yang kontras untuk menyelaraskan imej dan perwakilan teks dan objektif generatif (kehilangan keterangan) untuk mewujudkan perwakilan bersama.
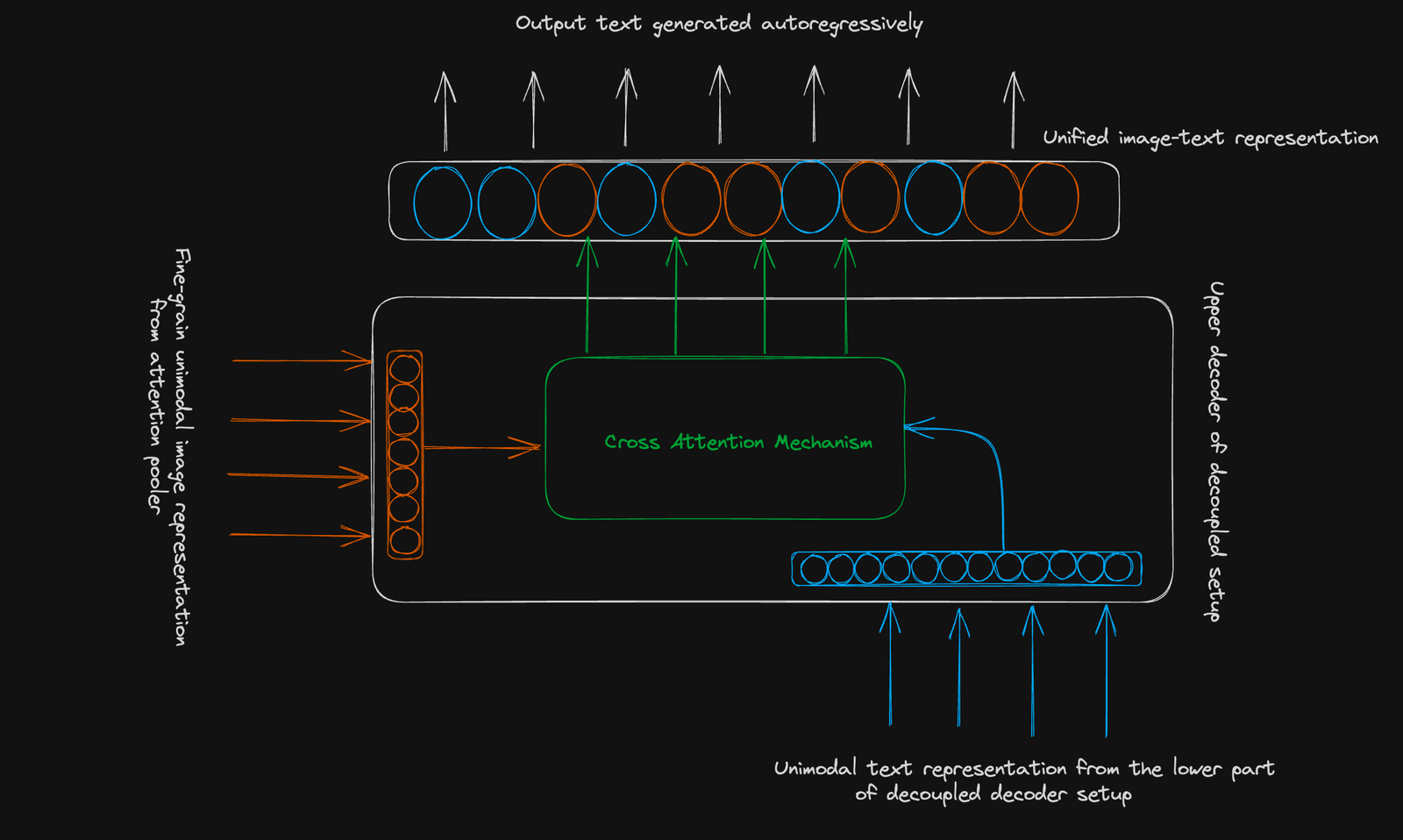
COCA Architecture:
Coca menggunakan struktur pengekodan pengekod standard. Inovasinya terletak pada decoder
decoupled: Objektif Kontrasif: Belajar untuk pasangan pasangan imej yang berkaitan dengan kluster dan yang berasingan yang tidak berkaitan dalam ruang vektor bersama. Satu embedding imej yang dikumpulkan digunakan. Objektif Generatif: Menggunakan perwakilan imej halus (urutan 256 dimensi) dan perhatian silang modal untuk meramalkan teks secara autoregresif. Kesimpulan: Coca mewakili kemajuan yang ketara dalam model asas teks imej. Pendekatan gabungannya meningkatkan prestasi dalam pelbagai tugas, menawarkan alat serba boleh untuk aplikasi hiliran. Untuk meneruskan pemahaman anda tentang konsep pembelajaran yang maju, pertimbangkan pembelajaran mendalam DataCamp dengan kursus Keras. Bacaan Lanjut:

Atas ialah kandungan terperinci COCA: Kapsyen kontras adalah model asas teks imej yang dijelaskan secara visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1664
1664
 14
1423
52
1318
25
1269
29
1248
24
14
1423
52
1318
25
1269
29
1248
24

 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
10 Pelanjutan pengekodan AI generatif dalam kod vs yang mesti anda pelajari
Apr 13, 2025 am 01:14 AM
Hei ada, pengekodan ninja! Apa tugas yang berkaitan dengan pengekodan yang anda telah merancang untuk hari itu? Sebelum anda menyelam lebih jauh ke dalam blog ini, saya ingin anda memikirkan semua kesengsaraan yang berkaitan dengan pengekodan anda-lebih jauh menyenaraikan mereka. Selesai? - Let ’
 AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
AV Bytes: Meta ' s llama 3.2, Google's Gemini 1.5, dan banyak lagi
Apr 11, 2025 pm 12:01 PM
Landskap AI minggu ini: Badai kemajuan, pertimbangan etika, dan perdebatan pengawalseliaan. Pemain utama seperti Openai, Google, Meta, dan Microsoft telah melepaskan kemas kini, dari model baru yang terobosan ke peralihan penting di LE
 GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?
Apr 13, 2025 am 10:18 AM
Pengenalan OpenAI telah mengeluarkan model barunya berdasarkan seni bina "strawberi" yang sangat dijangka. Model inovatif ini, yang dikenali sebagai O1, meningkatkan keupayaan penalaran, yang membolehkannya berfikir melalui masalah MOR
 Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Panduan Komprehensif untuk Model Bahasa Visi (VLMS)
Apr 12, 2025 am 11:58 AM
Pengenalan Bayangkan berjalan melalui galeri seni, dikelilingi oleh lukisan dan patung yang terang. Sekarang, bagaimana jika anda boleh bertanya setiap soalan dan mendapatkan jawapan yang bermakna? Anda mungkin bertanya, "Kisah apa yang anda ceritakan?
 3 Kaedah untuk menjalankan Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
3 Kaedah untuk menjalankan Llama 3.2 - Analytics Vidhya
Apr 11, 2025 am 11:56 AM
Meta's Llama 3.2: Powerhouse AI Multimodal Model multimodal terbaru Meta, Llama 3.2, mewakili kemajuan yang ketara dalam AI, yang membanggakan pemahaman bahasa yang dipertingkatkan, ketepatan yang lebih baik, dan keupayaan penjanaan teks yang unggul. Keupayaannya t
 Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Pernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Pixtral -12b: Model Multimodal Pertama Mistral Ai '
Apr 13, 2025 am 11:20 AM
Pixtral -12b: Model Multimodal Pertama Mistral Ai '
Apr 13, 2025 am 11:20 AM
Pengenalan Mistral telah mengeluarkan model multimodal yang pertama, iaitu Pixtral-12B-2409. Model ini dibina atas parameter 12 bilion Mistral, NEMO 12B. Apa yang membezakan model ini? Ia kini boleh mengambil kedua -dua gambar dan Tex
