

Penjanaan laporan kewangan multimodal menggunakan llamaindex

Dalam banyak aplikasi dunia nyata, data tidak semata-mata tekstual-ia mungkin termasuk imej, jadual, dan carta yang membantu memperkuat naratif. Penjana laporan multimodal membolehkan anda memasukkan kedua -dua teks dan imej ke dalam output akhir, menjadikan laporan anda lebih dinamik dan kaya dengan visual.
Artikel ini menggariskan bagaimana untuk membina saluran paip itu menggunakan:
- llamaindex untuk penguraian dokumen dan enjin pertanyaan,
- Model bahasa terbuka untuk analisis teks,
-
llamaparse untuk mengekstrak kedua -dua teks dan imej dari dokumen PDF, persediaan pemerhatian menggunakan - arize phoenix (melalui lbatrace) untuk pembalakan dan debugging.
Objektif Pembelajaran
- memahami cara mengintegrasikan teks dan visual untuk penjanaan laporan kewangan yang berkesan menggunakan saluran paip multimodal.
- belajar menggunakan llamaindex dan llamaparse untuk generasi laporan kewangan yang dipertingkatkan dengan output berstruktur.
- meneroka llamaparse untuk mengekstrak kedua -dua teks dan imej dari dokumen PDF dengan berkesan.
- Sediakan pemerhatian menggunakan Arize Phoenix (melalui lbatrace) untuk pembalakan dan debugging saluran paip kompleks.
- Buat enjin pertanyaan berstruktur untuk menjana laporan bahawa ringkasan teks interleave dengan elemen visual.
- Artikel ini diterbitkan sebagai sebahagian daripada Blogathon Sains Data
Jadual Kandungan Model Langkah 5: Mengurangkan dokumen dengan llamaparse Langkah 6: Teks dan Imej Bersekutu
Langkah 7: Bina Indeks Ringkasan
Ditanya soalan- Gambaran keseluruhan proses
- Membina penjana laporan multimodal melibatkan membuat saluran paip yang mengintegrasikan elemen teks dan visual dengan lancar dari dokumen kompleks seperti PDF. Proses ini bermula dengan memasang perpustakaan yang diperlukan, seperti llamaindex untuk menghuraikan dokumen dan pertanyaan orkestra, dan llamaparse untuk mengekstrak kedua -dua teks dan imej. Observability ditubuhkan menggunakan Arize Phoenix (melalui Lbatrace) untuk memantau dan debug saluran paip.
- llama-index
- llama-sarse (untuk penguraian imej teks)
- llama-index-callbacks-verize-phoenix (untuk pemerhatian/pembalakan)
-
nest_asyncio (untuk mengendalikan gelung acara async dalam buku nota)
Setelah persediaan selesai, saluran paip memproses dokumen PDF, menguraikan kandungannya ke dalam teks berstruktur dan menjadikan elemen visual seperti jadual dan carta. Unsur -unsur parsed ini kemudiannya dikaitkan, mewujudkan dataset bersatu. SummaryIndex dibina untuk membolehkan pandangan peringkat tinggi, dan enjin pertanyaan berstruktur dibangunkan untuk menghasilkan laporan yang menggabungkan analisis teks dengan visual yang relevan. Hasilnya adalah penjana laporan dinamik dan interaktif yang mengubah dokumen statik menjadi output yang kaya dan multimodal yang disesuaikan untuk pertanyaan pengguna.
Pelaksanaan langkah demi langkah
Ikuti panduan terperinci ini untuk membina penjana laporan multimodal, dari menubuhkan kebergantungan untuk menghasilkan output berstruktur dengan teks dan imej bersepadu. Setiap langkah memastikan integrasi lullamaindex, llamaparse, dan arize Phoenix untuk saluran paip yang cekap dan dinamik.
Langkah 1: Pasang dan Import Ketergantungan
anda memerlukan perpustakaan berikut yang berjalan di Python 3.9.9:
Langkah 2: Sediakan pemerhatian!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Salin selepas log masukSalin selepas log masuk
Kami mengintegrasikan dengan llamatrace - Llamacloud API (Arize Phoenix). Pertama, dapatkan kunci API dari lbatrace.com, kemudian sediakan pembolehubah persekitaran untuk menghantar jejak ke Phoenix.Kunci API Phoenix Phoenix boleh didapati dengan mendaftar untuk lbatrace di sini, kemudian navigasi ke panel kiri bawah dan klik pada 'Kekunci' di mana anda perlu mencari kunci API anda.
Sebagai contoh:
Langkah 3: Muatkan data - Dapatkan dek slaid andaPHOENIX_API_KEY = "<PHOENIX_API_KEY>" os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}" llama_index.core.set_global_handler( "arize_phoenix", endpoint="https://llamatrace.com/v1/traces" )Salin selepas log masukSalin selepas log masukUntuk demonstrasi, kami menggunakan dek slaid pertemuan ConocoPhillips '2023. Kami memuat turun pdf:
periksa sama ada dek slaid PDF berada dalam folder data, jika tidak letakkan dalam folder data dan namakannya seperti yang anda mahukan.import os import requests # Create the directories (ignore errors if they already exist) os.makedirs("data", exist_ok=True) os.makedirs("data_images", exist_ok=True) # URL of the PDF url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf" # Download and save to data/conocophillips.pdf response = requests.get(url) with open("data/conocophillips.pdf", "wb") as f: f.write(response.content) print("PDF downloaded to data/conocophillips.pdf")Salin selepas log masukSalin selepas log masukLangkah 4: Sediakan Model
Anda memerlukan model penyembuhan dan LLM. Dalam contoh ini:
Seterusnya, anda mendaftarkannya sebagai lalai untuk llamaindex:from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Salin selepas log masukSalin selepas log masuk
Langkah 5: Mengurangkan dokumen dengan llamaparsefrom llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
Salin selepas log masukSalin selepas log masukllamaparse boleh mengekstrak teks dan imej (melalui model besar multimodal). Untuk setiap halaman PDF, ia kembali:
- teks markdown
- (dengan jadual, tajuk, titik peluru, dll.) imej yang diberikan
- (disimpan secara tempatan)
print(f"Parsing slide deck...") md_json_objs = parser.get_json_result("data/conocophillips.pdf") md_json_list = md_json_objs[0]["pages"]Salin selepas log masukSalin selepas log masuk
print(md_json_list[10]["md"])
Salin selepas log masukSalin selepas log masuk !pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Salin selepas log masukSalin selepas log masuk
Langkah 6: Teks dan Imej Bersekutu
Kami membuat senaraitextNode objek (struktur data Llamaindex) untuk setiap halaman. Setiap nod mempunyai metadata mengenai nombor halaman dan laluan fail imej yang sepadan:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>" os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}" llama_index.core.set_global_handler( "arize_phoenix", endpoint="https://llamatrace.com/v1/traces" )Salin selepas log masukSalin selepas log masuk Langkah 7: Membina Indeks Ringkasan dengan nod teks ini, anda boleh membuat summaryindex:
SummaryIndex memastikan anda dapat dengan mudah mengambil atau menghasilkan ringkasan peringkat tinggi ke seluruh dokumen.import os import requests # Create the directories (ignore errors if they already exist) os.makedirs("data", exist_ok=True) os.makedirs("data_images", exist_ok=True) # URL of the PDF url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf" # Download and save to data/conocophillips.pdf response = requests.get(url) with open("data/conocophillips.pdf", "wb") as f: f.write(response.content) print("PDF downloaded to data/conocophillips.pdf")Salin selepas log masukSalin selepas log masukLangkah 8: Tentukan skema output berstruktur
saluran paip kami bertujuan untuk menghasilkan output akhir dengan blok teks interleaved dan blok imej. Untuk itu, kami membuat model Pydantic tersuai (menggunakan pydantic v2 atau memastikan keserasian) dengan dua jenis blok-
textblock dan Titik utama: ReportOutput memerlukan sekurang -kurangnya satu blok imej, memastikan jawapan terakhir adalah multimodal. Langkah 9: Buat enjin pertanyaan berstruktur
llamaindex membolehkan anda menggunakan "LLM berstruktur" (iaitu, llm yang outputnya secara automatik dihuraikan ke dalam skema tertentu). Inilah caranya:from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Salin selepas log masukSalin selepas log masukfrom llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
Salin selepas log masukSalin selepas log masuk Kesimpulan Dengan menggabungkan llamaindex, llamaparse, dan openai, anda boleh membina penjana laporan multimodal yang memproses keseluruhan PDF (dengan teks, jadual, dan imej) ke dalam output berstruktur. Pendekatan ini memberikan hasil yang lebih kaya dan lebih bermaklumat -betul -betul apa yang dikehendaki oleh pihak berkepentingan untuk mendapatkan pandangan kritikal dari dokumen korporat atau teknikal yang kompleks.print(f"Parsing slide deck...") md_json_objs = parser.get_json_result("data/conocophillips.pdf") md_json_list = md_json_objs[0]["pages"]Salin selepas log masukSalin selepas log masuk Jangan ragu untuk menyesuaikan saluran paip ini ke dokumen anda sendiri, tambahkan langkah pengambilan untuk arkib besar, atau mengintegrasikan model khusus domain untuk menganalisis imej yang mendasari. Dengan asas-asas yang dibentangkan di sini, anda boleh membuat laporan dinamik, interaktif, dan visual yang jauh melebihi pertanyaan berasaskan teks yang mudah. Terima kasih banyak kepada Jerry Liu dari Llamaindex untuk membangunkan saluran paip yang menakjubkan ini.print(md_json_list[10]["md"])
Salin selepas log masukSalin selepas log masukTakeaways Key
- Transformasi PDF dengan teks dan visual ke dalam format berstruktur sambil mengekalkan integriti kandungan asal menggunakan llamaparse dan llamaindex.
- menghasilkan laporan yang diperkaya secara visual bahawa ringkasan dan imej tekstual yang sama untuk pemahaman kontekstual yang lebih baik.
- Generasi laporan kewangan dapat dipertingkatkan dengan mengintegrasikan kedua -dua teks dan elemen visual untuk output yang lebih mendalam dan dinamik.
- Memanfaatkan Llamaindex dan Llamaparse menyelaraskan proses penjanaan laporan kewangan, memastikan hasil yang tepat dan berstruktur.
- Dapatkan dokumen yang relevan sebelum memproses untuk mengoptimumkan generasi laporan untuk arkib besar.
- Meningkatkan parsing visual, menggabungkan analisis spesifik carta, dan menggabungkan model untuk pemprosesan teks dan imej untuk pandangan yang lebih mendalam.
Soalan Lazim
Q1. Apakah "Generator Laporan Multimodal"?a. Penjana laporan multimodal adalah sistem yang menghasilkan laporan yang mengandungi pelbagai jenis kandungan -terutamanya teks dan imej -dalam satu output kohesif. Dalam saluran paip ini, anda menghuraikan PDF ke dalam kedua -dua elemen teks dan visual, kemudian menggabungkannya ke dalam satu laporan akhir.
Q2. Kenapa saya perlu memasang llama-index-callbacks-verize-phoenix dan menubuhkan pemerhatian? a. Alat pemerhatian seperti Arize Phoenix (melalui Lbatrace) membolehkan anda memantau dan menghilangkan tingkah laku model, pertanyaan trek dan tindak balas, dan mengenal pasti isu -isu dalam masa nyata. Ia amat berguna apabila berurusan dengan dokumen besar atau kompleks dan beberapa langkah berasaskan LLM.
a. Kebanyakan pengekstrak teks PDF hanya mengendalikan teks mentah, sering kehilangan pemformatan, imej, dan jadual. Llamaparse mampu mengekstrak kedua -dua teks dan imej (imej halaman yang diberikan), yang penting untuk membina saluran paip multimodal di mana anda perlu merujuk kembali ke jadual, carta, atau visual lain. Apakah kelebihan menggunakan SummaryIndex?Q3. Mengapa menggunakan llamaparse dan bukannya pengekstrak teks pdf standard?a. SummaryIndex adalah abstraksi llamaindex yang menganjurkan kandungan anda (mis., Halaman PDF) supaya ia dapat dengan cepat menghasilkan ringkasan yang komprehensif. Ia membantu mengumpulkan pandangan peringkat tinggi dari dokumen panjang tanpa perlu memotong mereka secara manual atau menjalankan pertanyaan pengambilan untuk setiap data.
Q5. Bagaimanakah saya memastikan laporan akhir termasuk sekurang -kurangnya satu blok imej? a. Dalam model Pydantic ReportOutput, menguatkuasakan bahawa senarai blok memerlukan sekurang -kurangnya satu ImageBlock. Ini dinyatakan dalam sistem dan skema sistem anda. LLM mesti mematuhi peraturan ini, atau ia tidak akan menghasilkan output berstruktur yang sah.
Media yang ditunjukkan dalam artikel ini tidak dimiliki oleh Analytics Vidhya dan digunakan pada budi bicara penulis.

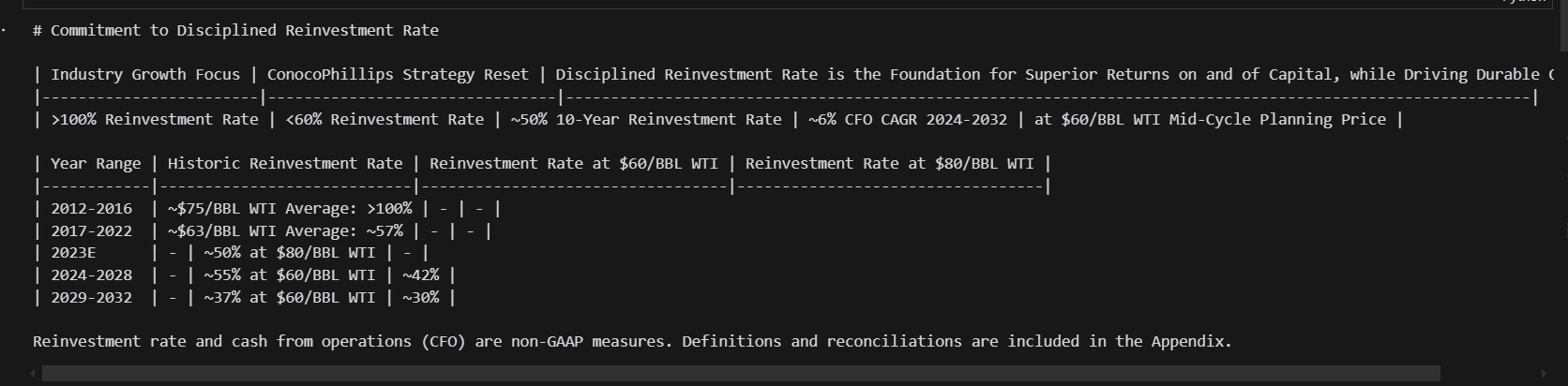
 Langkah 7: Membina Indeks Ringkasan
Langkah 7: Membina Indeks Ringkasan  Kesimpulan
Kesimpulan  Jangan ragu untuk menyesuaikan saluran paip ini ke dokumen anda sendiri, tambahkan langkah pengambilan untuk arkib besar, atau mengintegrasikan model khusus domain untuk menganalisis imej yang mendasari. Dengan asas-asas yang dibentangkan di sini, anda boleh membuat laporan dinamik, interaktif, dan visual yang jauh melebihi pertanyaan berasaskan teks yang mudah.
Jangan ragu untuk menyesuaikan saluran paip ini ke dokumen anda sendiri, tambahkan langkah pengambilan untuk arkib besar, atau mengintegrasikan model khusus domain untuk menganalisis imej yang mendasari. Dengan asas-asas yang dibentangkan di sini, anda boleh membuat laporan dinamik, interaktif, dan visual yang jauh melebihi pertanyaan berasaskan teks yang mudah. Atas ialah kandungan terperinci Penjanaan laporan kewangan multimodal menggunakan llamaindex. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Bagaimana Membina Ejen AI Multimodal Menggunakan Rangka Kerja AGNO?
Apr 23, 2025 am 11:30 AM
Bagaimana Membina Ejen AI Multimodal Menggunakan Rangka Kerja AGNO?
Apr 23, 2025 am 11:30 AM
Semasa bekerja pada AIS AI, pemaju sering mendapati diri mereka menavigasi perdagangan antara kelajuan, fleksibiliti, dan kecekapan sumber. Saya telah meneroka rangka kerja AI yang agentik dan menjumpai Agno (sebelum ini adalah Phi-
 Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Bagaimana untuk menambah lajur dalam SQL? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Pernyataan Jadual Alter SQL: Menambah lajur secara dinamik ke pangkalan data anda Dalam pengurusan data, kebolehsuaian SQL adalah penting. Perlu menyesuaikan struktur pangkalan data anda dengan cepat? Pernyataan Jadual ALTER adalah penyelesaian anda. Butiran panduan ini menambah colu
 Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kos
Apr 16, 2025 am 11:37 AM
Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kos
Apr 16, 2025 am 11:37 AM
Pelepasan ini termasuk tiga model yang berbeza, GPT-4.1, GPT-4.1 Mini dan GPT-4.1 Nano, menandakan langkah ke arah pengoptimuman khusus tugas dalam landskap model bahasa yang besar. Model-model ini tidak segera menggantikan antara muka yang dihadapi pengguna seperti
 Beyond the Llama Drama: 4 Benchmarks Baru Untuk Model Bahasa Besar
Apr 14, 2025 am 11:09 AM
Beyond the Llama Drama: 4 Benchmarks Baru Untuk Model Bahasa Besar
Apr 14, 2025 am 11:09 AM
Penanda Aras Bermasalah: Kajian Kes Llama Pada awal April 2025, Meta melancarkan model Llama 4 suite, dengan metrik prestasi yang mengagumkan yang meletakkan mereka dengan baik terhadap pesaing seperti GPT-4O dan Claude 3.5 sonnet. Pusat ke LAUNC
 Kursus Pendek Baru mengenai Model Embedding oleh Andrew Ng
Apr 15, 2025 am 11:32 AM
Kursus Pendek Baru mengenai Model Embedding oleh Andrew Ng
Apr 15, 2025 am 11:32 AM
Buka kunci kekuatan model embedding: menyelam jauh ke kursus baru Andrew Ng Bayangkan masa depan di mana mesin memahami dan menjawab soalan anda dengan ketepatan yang sempurna. Ini bukan fiksyen sains; Terima kasih kepada kemajuan dalam AI, ia menjadi R
 Bagaimana permainan ADHD, alat kesihatan & chatbots AI mengubah kesihatan global
Apr 14, 2025 am 11:27 AM
Bagaimana permainan ADHD, alat kesihatan & chatbots AI mengubah kesihatan global
Apr 14, 2025 am 11:27 AM
Bolehkah permainan video meringankan kebimbangan, membina fokus, atau menyokong kanak -kanak dengan ADHD? Memandangkan cabaran penjagaan kesihatan melonjak di seluruh dunia - terutamanya di kalangan belia - inovator beralih kepada alat yang tidak mungkin: permainan video. Sekarang salah satu hiburan terbesar di dunia Indus
 Simulasi dan analisis pelancaran roket menggunakan Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulasi dan analisis pelancaran roket menggunakan Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulasi Rocket dilancarkan dengan Rocketpy: Panduan Komprehensif Artikel ini membimbing anda melalui mensimulasikan pelancaran roket kuasa tinggi menggunakan Rocketpy, perpustakaan Python yang kuat. Kami akan merangkumi segala -galanya daripada menentukan komponen roket untuk menganalisis simula
 Google melancarkan strategi ejen yang paling komprehensif di Cloud Seterusnya 2025
Apr 15, 2025 am 11:14 AM
Google melancarkan strategi ejen yang paling komprehensif di Cloud Seterusnya 2025
Apr 15, 2025 am 11:14 AM
Gemini sebagai asas strategi AI Google Gemini adalah asas kepada strategi ejen AI Google, memanfaatkan keupayaan multimodalnya untuk memproses dan menjana respons di seluruh teks, imej, audio, video dan kod. Dibangunkan oleh DeepM
