
 Peranti teknologi
AI
Mereka bentuk antibodi dari awal, pasukan Tencent dan Universiti Peking telah melatih model bahasa besar dan menerbitkannya dalam sub-jurnal Nature
Peranti teknologi
AI
Mereka bentuk antibodi dari awal, pasukan Tencent dan Universiti Peking telah melatih model bahasa besar dan menerbitkannya dalam sub-jurnal Nature
Mereka bentuk antibodi dari awal, pasukan Tencent dan Universiti Peking telah melatih model bahasa besar dan menerbitkannya dalam sub-jurnal Nature

 Editor |. Teknologi KX
Editor |. Teknologi KX
AI telah mencapai kemajuan besar dalam membantu reka bentuk antibodi. Walau bagaimanapun, reka bentuk antibodi masih banyak bergantung pada pengasingan antibodi khusus antigen daripada serum, yang merupakan proses intensif sumber dan memakan masa.
Untuk menyelesaikan masalah ini, pasukan penyelidik Tencent AI Lab, Peking University Shenzhen Graduate School dan Xijing Digestive Disease Hospital mencadangkan model bahasa besar generasi antibodi terlatih (PALM-H3) untuk penjanaan de novo antibodi dengan kekhususan pengikatan antigen yang diperlukan Antibodi buatan yang unik CDRH3 mengurangkan pergantungan kepada antibodi semula jadi.
Selain itu, model ramalan pengikat antigen-antibodi berketepatan tinggi A2binder direka untuk memadankan jujukan epitop antigen dengan jujukan antibodi untuk meramalkan kekhususan dan pertalian pengikatan.
Ringkasnya, kajian ini mewujudkan rangka kerja kecerdasan buatan untuk penjanaan dan penilaian antibodi, yang berpotensi untuk mempercepatkan pembangunan ubat antibodi dengan ketara.
Penyelidikan berkaitan bertajuk "Generasi de novo antibodi SARS-CoV-2 CDRH3 dengan model bahasa besar generatif terlatih" telah diterbitkan dalam "Nature Communications" pada 10 Ogos.

Ubat antibodi, juga dikenali sebagai antibodi monoklonal, memainkan peranan penting dalam kesan terapi biologi. Dengan meniru tindakan sistem imun, ubat-ubatan ini secara terpilih boleh menyasarkan agen penyebab penyakit seperti virus dan sel kanser. Ubat antibodi adalah pendekatan yang lebih spesifik dan berkesan daripada rawatan tradisional. Ubat antibodi telah menunjukkan hasil yang positif dalam merawat pelbagai penyakit.
Membangunkan ubat antibodi ialah proses kompleks yang melibatkan pengasingan antibodi daripada sumber haiwan, memanusiakannya dan mengoptimumkan pertaliannya. Tetapi perkembangan ubat antibodi masih banyak bergantung pada antibodi semula jadi.
Data jujukan protein boleh dilihat sebagai bahasa, jadi model pra-latihan berskala besar dalam bidang pemprosesan bahasa semula jadi (NLP) telah digunakan untuk mempelajari corak perwakilan protein. Pelbagai model bahasa protein telah dibangunkan. Walau bagaimanapun, menjana antibodi dengan pertalian tinggi untuk epitop tertentu kekal sebagai tugas yang mencabar kerana kepelbagaian antibodi yang tinggi dan kekurangan data pasangan antigen-antibodi yang tersedia.
Untuk menangani cabaran di atas, pasukan Tencent AI Lab mencadangkan model bahasa berskala besar generasi antibodi terlatih PALM-H3 untuk mengoptimumkan dan menjana rantau penentu kesempurnaan rantaian berat 3 (CDRH3), yang memainkan peranan penting dalam kekhususan dan kepelbagaian antibodi memainkan peranan yang penting.
Untuk menilai pertalian antibodi yang dihasilkan oleh PALM-H3 untuk antigen, para penyelidik menggunakan gabungan dok antigen-antibodi dan kaedah berasaskan AI.
Para penyelidik juga membangunkan A2binder untuk menilai pertalian antibodi-antigen. A2binder membolehkan ramalan pertalian yang tepat dan boleh digeneralisasikan, walaupun untuk antigen yang tidak diketahui.
Rangka kerja PALM-H3 dan A2Binder
Aliran kerja dan rangka kerja model PALM-H3 dan A2binder ditunjukkan dalam rajah di bawah.
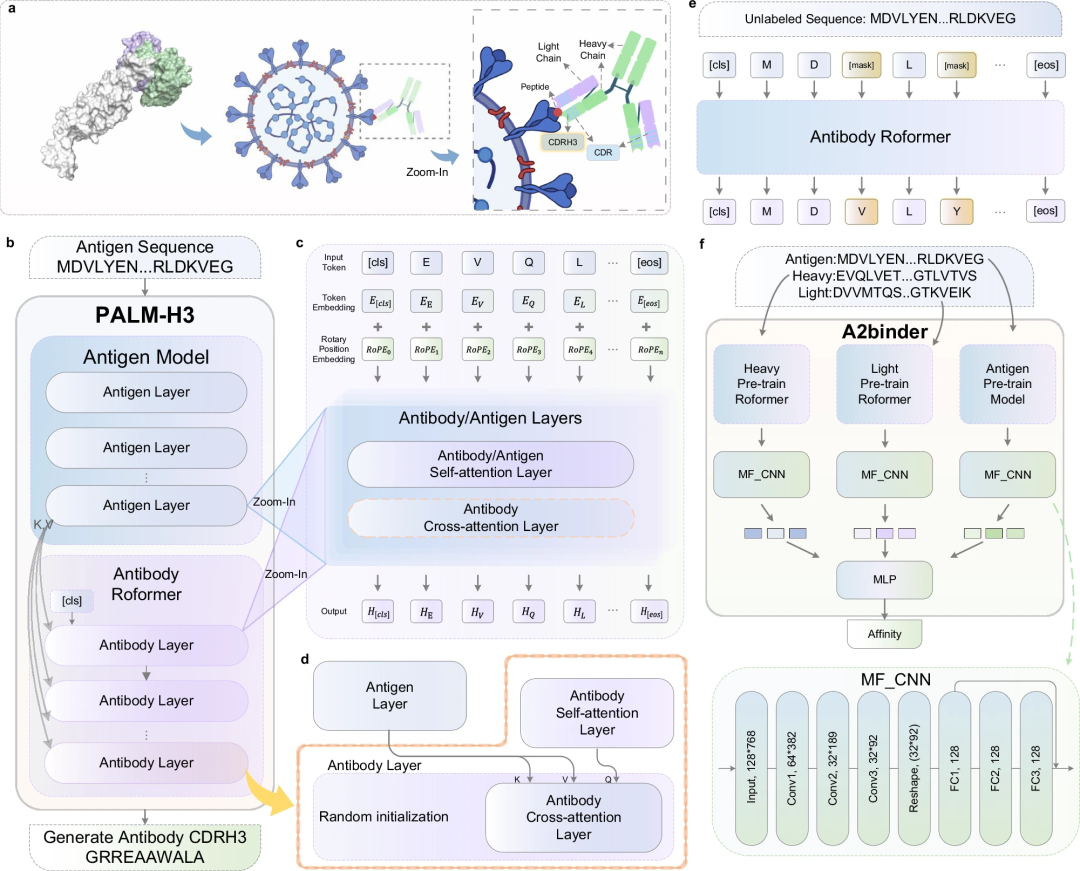
PALM-H3 direka untuk menjana urutan CDRH3 de novo dalam antibodi. Rantau CDRH3 memainkan peranan paling penting dalam menentukan kekhususan mengikat antibodi untuk urutan antigen tertentu. PALM-H3 ialah model seperti pengubah yang menggunakan model antigen berasaskan ESM2 sebagai pengekod dan Roformer antibodi sebagai penyahkod. Kajian itu juga membina A2binder untuk meramalkan pertalian mengikat antibodi yang dihasilkan secara buatan.
Pembinaan PALM-H3 dan A2binder merangkumi tiga langkah: Pertama, para penyelidik telah melatih dua model Roformer masing-masing pada rantai berat antibodi tidak berpasangan dan urutan rantai ringan. Kemudian, A2binder dibina berdasarkan ESM2 terlatih, Roformer rantai berat antibodi dan Roformer rantai ringan antibodi, dan dilatih menggunakan data pertalian berpasangan. Akhirnya, PALM-H3 dibina menggunakan ESM2 terlatih dan Roformer rantai berat antibodi dan dilatih pada data antigen-CDRH3 berpasangan untuk menjana CDRH3 de novo.
A2binder boleh meramal dengan tepat kebarangkalian pengikatan antigen-antibodi, pertalian
Prestasi A2binder dinilai dengan membandingkan keupayaannya untuk meramalkan pertalian dengan beberapa kaedah asas.
A2binder berfungsi dengan baik pada set data perkaitan, sebahagiannya disebabkan oleh pra-latihan pada jujukan antibodi, yang membolehkan A2binder mempelajari corak unik yang terdapat dalam jujukan ini.
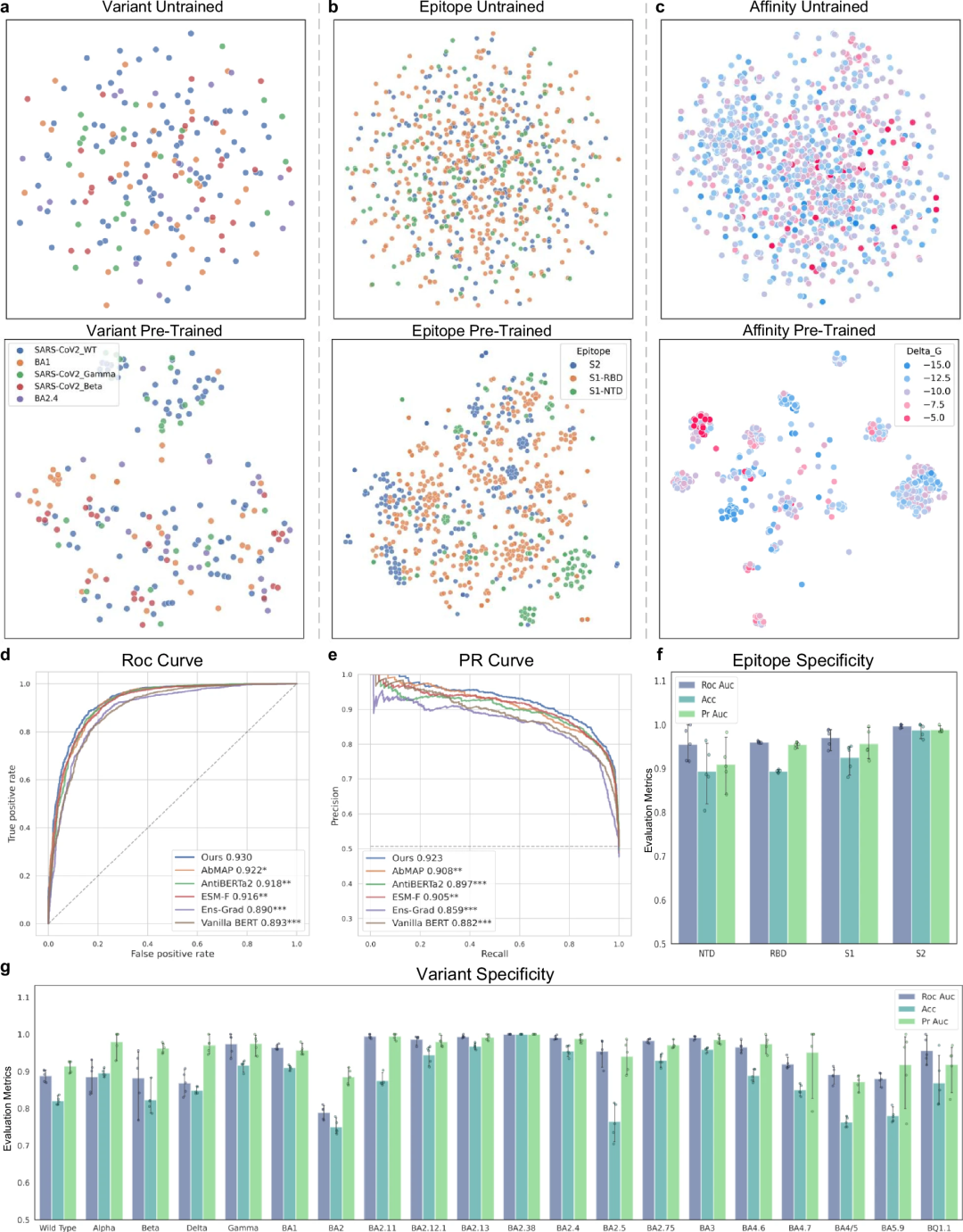
Die Ergebnisse zeigen, dass A2binder bei allen Antigen-Antikörper-Affinitätsvorhersagedatensätzen eine bessere Leistung erbringt als das Basismodell ESM-F (letzteres hat das gleiche Framework, aber das vorab trainierte Modell). ist die ESM2-Substitution), was darauf hindeutet, dass das Vortraining mit Antikörpersequenzen für verwandte nachgelagerte Aufgaben von Vorteil sein könnte.
Um die Leistung des Modells bei der Vorhersage von Affinitätswerten zu bewerten, verwendeten die Forscher auch zwei Datensätze, 14H und 14L, die Affinitätswertbezeichnungen enthalten.
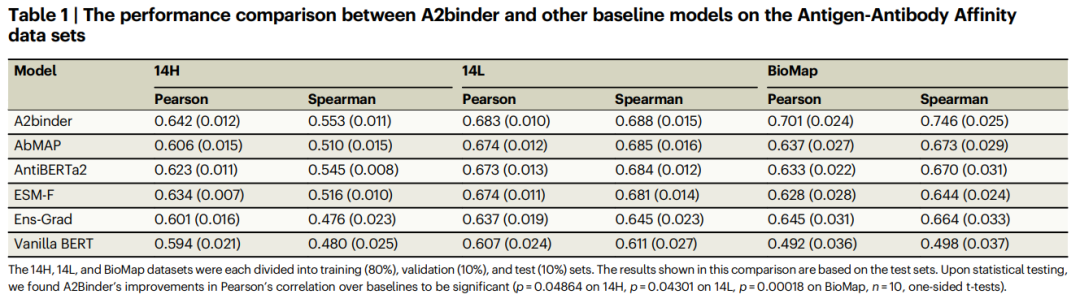
A2binder übertrifft alle Basismodelle sowohl hinsichtlich der Pearson-Korrelations- als auch der Spearman-Korrelationsmetriken. A2binder erreicht eine Pearson-Korrelation von 0,642 für den 14H-Datensatz (eine Verbesserung von 3 %) und 0,683 für den 14L-Datensatz (eine Verbesserung von 1 %).
Allerdings sank die Leistung von A2binder und anderen Basismodellen bei den 14H- und 14L-Datensätzen im Vergleich zu anderen Datensätzen leicht. Diese Beobachtung steht im Einklang mit früheren Studien.
PALM-H3 zeichnet sich durch die Erzeugung von Antikörpern mit hoher Bindungswahrscheinlichkeit aus.
Die Forscher untersuchten den Unterschied zwischen den von PALM-H3 produzierten und natürlichen Antikörpern Antikörper. Unterschied zwischen. Es wurde festgestellt, dass sich ihre Sequenzen erheblich unterscheiden, die Bindungswahrscheinlichkeiten der produzierten Antikörper wurden jedoch durch diese Unterschiede nicht wesentlich beeinflusst. Gleichzeitig führen ihre strukturellen Unterschiede zu einer Verringerung der Bindungsaffinität. Diese Ergebnisse stehen im Einklang mit früheren Studien zur Netzwerkanalyse von Antikörperbibliotheken und zur Erzeugung funktioneller Proteinsequenzen.
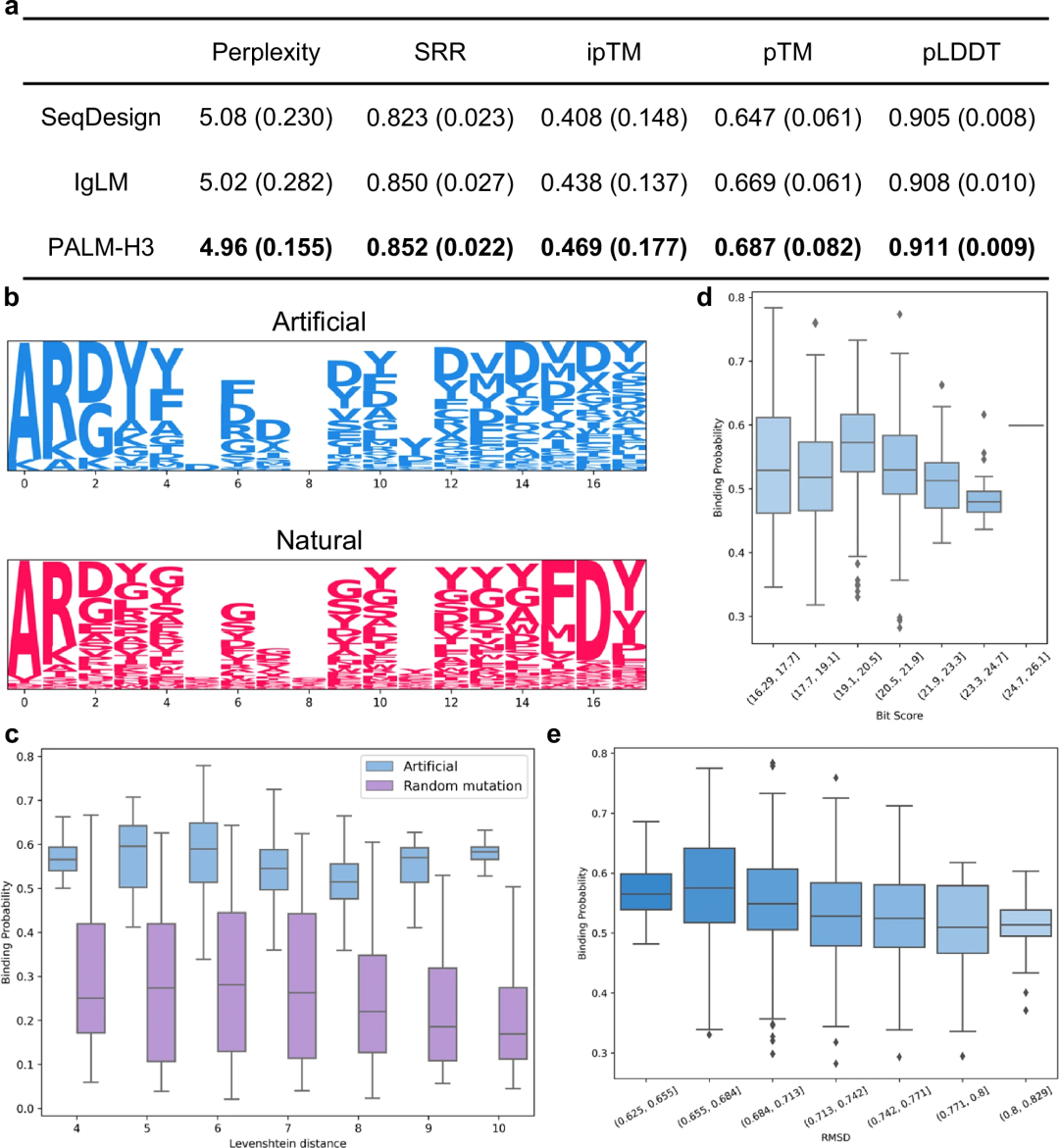
Insgesamt zeigen die Ergebnisse, dass PALM-H3 im Gegensatz zu natürlichen Antikörpern in der Lage ist, eine Vielzahl von Antikörpersequenzen mit hohen Bindungsaffinitäten zu erzeugen.
Darüber hinaus überprüften die Forscher die Leistung von PALM-H3 durch ClusPro und SnugDock. PALM-H3 ist in der Lage, Antikörper gegen ein stabilisierendes Peptid in der HR2-Region von SARS-CoV-2, der CDRH3-Sequenz, zu erzeugen. Es wurde eine neuartige CDRH3-Sequenz generiert und bestätigt, dass die generierte Sequenz GRREAAWALA im Vergleich zur nativen CDHR3-Sequenz GKAAGTFDS ein verbessertes Targeting von Antigen-stabilisierenden Peptiden aufweist.
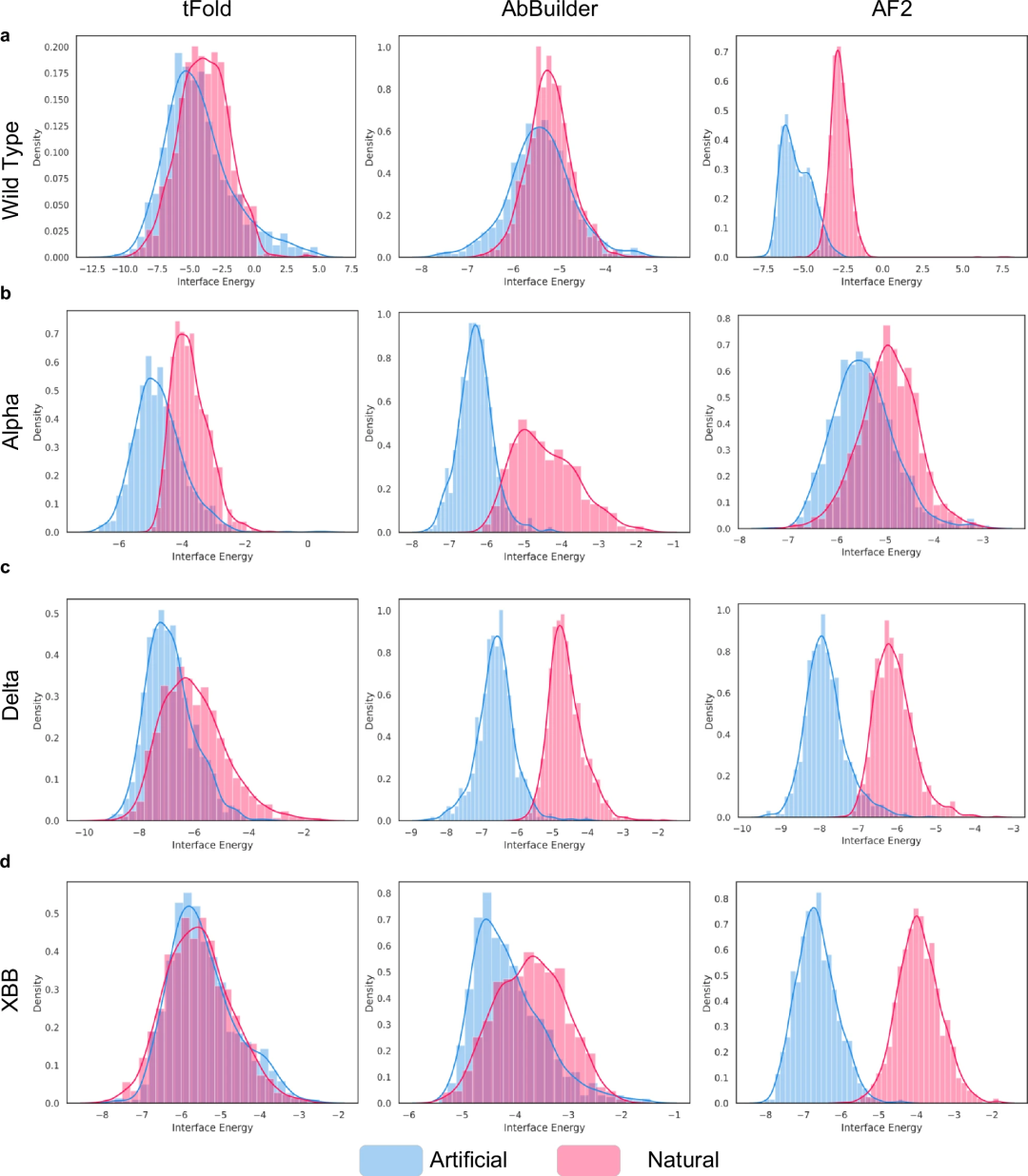
Darüber hinaus ist PALM-H3 in der Lage, Antikörper mit höherer Affinität gegen die neu auftretende CDRH3-Sequenz der SARS-CoV-2-Variante XBB zu erzeugen. Die resultierende Sequenz AKDSRTSPLRLDYS hat eine stärkere Affinität zu XBB als ihre Quelle ASEVLDNLRDGYNF.
Darüber hinaus überwindet PALM-H3 nicht nur die lokalen optimalen Fallstricke traditioneller sequentieller Mutationsstrategien, sondern erzeugt im Vergleich zum E-EVO-Ansatz auch Antikörper mit höherer Antigenbindungsaffinität. Dies unterstreicht die Vorteile von PALM-H3 beim Antikörperdesign, das eine effizientere Erkundung des Sequenzraums und die Erzeugung hochaffiner Binder ermöglicht, die auf spezifische Epitope abzielen.
In-vitro-Experimente
Darüber hinaus führten die Forscher auch In-vitro-Experimente durch, darunter Western Blot, Oberflächenplasmonresonanzanalyse und Pseudovirus-Neutralisierung Das Experiment lieferte einen wichtigen Nachweis für die Wirksamkeit des von PALM-H3 entwickelten Antikörpers.
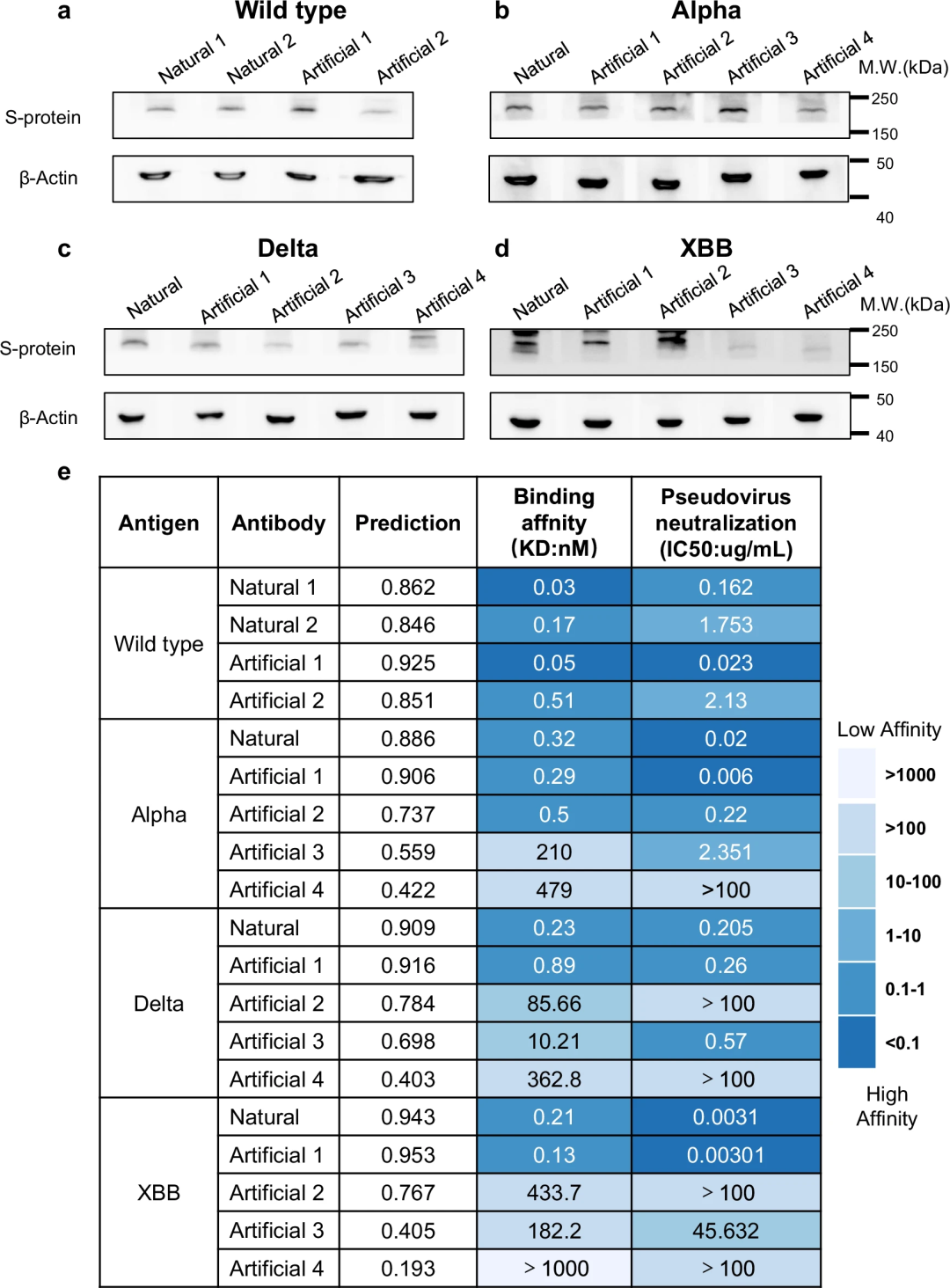
PALM-H3 Zwei Antikörper, die gegen die Spike-Proteine der SARS-CoV-2-Wildtyp-, Alpha-, Delta- und neutralisierende Wirkung von Antikörpern. Die robusten empirischen Ergebnisse dieser Nasslaborexperimente ergänzen rechnerische Vorhersagen und Analysen und bestätigen die Fähigkeit von PALM-H3 und A2binder, wirksame Antikörper mit hoher Spezifität und Affinität für bekannte und neue Antigene zu erzeugen und auszuwählen.
Zusammenfassend lässt sich sagen, dass das vorgeschlagene PALM-H3 die Fähigkeit eines groß angelegten Antikörper-Vortrainings und die Wirksamkeit der globalen Merkmalsfusion integriert, was zu einer hervorragenden Affinitätsvorhersageleistung und der Fähigkeit zur Entwicklung hochaffiner Antikörper führt . Darüber hinaus machen die direkte Sequenzgenerierung und die interpretierbare Gewichtsvisualisierung es zu einem effizienten und interpretierbaren Werkzeug für die Entwicklung hochaffiner Antikörper.
Atas ialah kandungan terperinci Mereka bentuk antibodi dari awal, pasukan Tencent dan Universiti Peking telah melatih model bahasa besar dan menerbitkannya dalam sub-jurnal Nature. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1665
1665
 14
1424
52
1322
25
1270
29
1249
24
14
1424
52
1322
25
1270
29
1249
24

 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Model dialog NVIDIA ChatQA telah berkembang kepada versi 2.0, dengan panjang konteks disebut pada 128K
Jul 26, 2024 am 08:40 AM
Komuniti LLM terbuka ialah era apabila seratus bunga mekar dan bersaing Anda boleh melihat Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 dan banyak lagi. model yang cemerlang. Walau bagaimanapun, berbanding dengan model besar proprietari yang diwakili oleh GPT-4-Turbo, model terbuka masih mempunyai jurang yang ketara dalam banyak bidang. Selain model umum, beberapa model terbuka yang mengkhusus dalam bidang utama telah dibangunkan, seperti DeepSeek-Coder-V2 untuk pengaturcaraan dan matematik, dan InternVL untuk tugasan bahasa visual.
 Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Google AI memenangi pingat perak IMO Mathematical Olympiad, model penaakulan matematik AlphaProof telah dilancarkan dan pembelajaran pengukuhan kembali
Jul 26, 2024 pm 02:40 PM
Bagi AI, Olimpik Matematik tidak lagi menjadi masalah. Pada hari Khamis, kecerdasan buatan Google DeepMind menyelesaikan satu kejayaan: menggunakan AI untuk menyelesaikan soalan sebenar IMO Olimpik Matematik Antarabangsa tahun ini, dan ia hanya selangkah lagi untuk memenangi pingat emas. Pertandingan IMO yang baru berakhir minggu lalu mempunyai enam soalan melibatkan algebra, kombinatorik, geometri dan teori nombor. Sistem AI hibrid yang dicadangkan oleh Google mendapat empat soalan dengan betul dan memperoleh 28 mata, mencapai tahap pingat perak. Awal bulan ini, profesor UCLA, Terence Tao baru sahaja mempromosikan Olimpik Matematik AI (Anugerah Kemajuan AIMO) dengan hadiah berjuta-juta dolar Tanpa diduga, tahap penyelesaian masalah AI telah meningkat ke tahap ini sebelum Julai. Lakukan soalan secara serentak pada IMO Perkara yang paling sukar untuk dilakukan dengan betul ialah IMO, yang mempunyai sejarah terpanjang, skala terbesar dan paling negatif
 PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
Pada tahun 2023, hampir setiap bidang AI berkembang pada kelajuan yang tidak pernah berlaku sebelum ini. Pada masa yang sama, AI sentiasa menolak sempadan teknologi trek utama seperti kecerdasan yang terkandung dan pemanduan autonomi. Di bawah trend berbilang modal, adakah status Transformer sebagai seni bina arus perdana model besar AI akan digoncang? Mengapakah penerokaan model besar berdasarkan seni bina MoE (Campuran Pakar) menjadi trend baharu dalam industri? Bolehkah Model Penglihatan Besar (LVM) menjadi satu kejayaan baharu dalam penglihatan umum? ...Daripada surat berita ahli PRO 2023 laman web ini yang dikeluarkan dalam tempoh enam bulan lalu, kami telah memilih 10 tafsiran khas yang menyediakan analisis mendalam tentang aliran teknologi dan perubahan industri dalam bidang di atas untuk membantu anda mencapai matlamat anda dalam bidang baharu. tahun. Tafsiran ini datang dari Week50 2023
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Editor |. KX Retrosynthesis ialah tugas kritikal dalam penemuan ubat dan sintesis organik, dan AI semakin digunakan untuk mempercepatkan proses. Kaedah AI sedia ada mempunyai prestasi yang tidak memuaskan dan kepelbagaian terhad. Dalam amalan, tindak balas kimia sering menyebabkan perubahan molekul tempatan, dengan pertindihan yang besar antara bahan tindak balas dan produk. Diilhamkan oleh ini, pasukan Hou Tingjun di Universiti Zhejiang mencadangkan untuk mentakrifkan semula ramalan retrosintetik satu langkah sebagai tugas penyuntingan rentetan molekul, secara berulang menapis rentetan molekul sasaran untuk menghasilkan sebatian prekursor. Dan model retrosintetik berasaskan penyuntingan EditRetro dicadangkan, yang boleh mencapai ramalan berkualiti tinggi dan pelbagai. Eksperimen yang meluas menunjukkan bahawa model itu mencapai prestasi cemerlang pada set data penanda aras standard USPTO-50 K, dengan ketepatan 1 teratas 60.8%.
 Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Pandangan alam semula jadi: Ujian kecerdasan buatan dalam perubatan berada dalam keadaan huru-hara Apa yang perlu dilakukan?
Aug 22, 2024 pm 04:37 PM
Editor |. ScienceAI Berdasarkan data klinikal yang terhad, beratus-ratus algoritma perubatan telah diluluskan. Para saintis sedang membahaskan siapa yang harus menguji alat dan cara terbaik untuk melakukannya. Devin Singh menyaksikan seorang pesakit kanak-kanak di bilik kecemasan mengalami serangan jantung semasa menunggu rawatan untuk masa yang lama, yang mendorongnya untuk meneroka aplikasi AI untuk memendekkan masa menunggu. Menggunakan data triage daripada bilik kecemasan SickKids, Singh dan rakan sekerja membina satu siri model AI untuk menyediakan potensi diagnosis dan mengesyorkan ujian. Satu kajian menunjukkan bahawa model ini boleh mempercepatkan lawatan doktor sebanyak 22.3%, mempercepatkan pemprosesan keputusan hampir 3 jam bagi setiap pesakit yang memerlukan ujian perubatan. Walau bagaimanapun, kejayaan algoritma kecerdasan buatan dalam penyelidikan hanya mengesahkan perkara ini
