

Pemilihan ciri melalui strategi pembelajaran pengukuhan

Pemilihan ciri ialah langkah penting dalam proses membina model pembelajaran mesin. Memilih ciri yang baik untuk model dan tugas yang ingin kami capai boleh meningkatkan prestasi.

Jika kita berurusan dengan set data berdimensi tinggi, maka memilih ciri adalah amat penting. Ia membolehkan model belajar dengan lebih pantas dan lebih baik. Ideanya adalah untuk mencari bilangan ciri yang optimum dan ciri yang paling bermakna.
Dalam artikel ini, kami akan memperkenalkan dan melaksanakan pemilihan ciri baharu melalui strategi pembelajaran pengukuhan. Kita mulakan dengan membincangkan pembelajaran pengukuhan, khususnya proses keputusan Markov. Ia adalah kaedah yang sangat baru dalam bidang sains data, terutamanya sesuai untuk pemilihan ciri. Kemudian ia memperkenalkan pelaksanaannya dan cara memasang dan menggunakan pustaka python (FSRLearing). Akhir sekali, contoh mudah digunakan untuk menunjukkan proses ini.
Pembelajaran Pengukuhan: Masalah Keputusan Markov untuk Pemilihan Ciri
Teknik pembelajaran pengukuhan (RL) boleh menjadi sangat berkesan dalam menyelesaikan masalah seperti penyelesaian permainan. Konsep pembelajaran pengukuhan adalah berdasarkan Markov Decision Process (MDP). Maksudnya di sini bukan untuk memahami definisi yang mendalam tetapi untuk mendapatkan pemahaman umum tentang cara ia berfungsi dan bagaimana ia boleh berguna untuk masalah kita. Dalam pembelajaran pengukuhan, agen belajar dengan berinteraksi dengan persekitarannya. Ia membuat keputusan dengan memerhatikan keadaan semasa dan isyarat ganjaran, dan akan menerima maklum balas positif atau negatif berdasarkan tindakan yang dipilih. Matlamat ejen adalah untuk memaksimumkan ganjaran terkumpul dengan mencuba tindakan yang berbeza. Konsep penting pembelajaran peneguhan
Pemikiran di sebalik pembelajaran peneguhan ialah agen bermula dari persekitaran yang tidak diketahui. Operasi carian untuk menyelesaikan misi. Ejen akan lebih cenderung untuk memilih beberapa tindakan di bawah pengaruh keadaan semasa dan tindakan yang dipilih sebelum ini. Setiap kali keadaan baharu dicapai dan tindakan diambil, ejen menerima ganjaran. Berikut ialah parameter utama yang perlu kita tentukan untuk pemilihan ciri:
Nyatakan, tindakan, ganjaran, cara memilih tindakan
Pertama, subset ciri yang terdapat dalam set data. Sebagai contoh, jika set data mempunyai tiga ciri (umur, jantina, ketinggian) ditambah label, keadaan yang mungkin adalah seperti berikut:
[] --> Empty set [Age], [Gender], [Height] --> 1-feature set [Age, Gender], [Gender, Height], [Age, Height] --> 2-feature set [Age, Gender, Height] --> All-feature set
Dalam keadaan, susunan ciri tidak penting, kita perlu melihat at it Buat koleksi, bukan senarai ciri.
Mengenai tindakan, kita boleh beralih daripada satu subset kepada mana-mana subset ciri yang belum diterokai. Dalam masalah pemilihan ciri, tindakan adalah untuk memilih ciri yang belum diterokai dalam keadaan semasa dan menambahnya ke keadaan seterusnya. Berikut adalah beberapa tindakan yang mungkin:
[Age] -> [Age, Gender] [Gender, Height] -> [Age, Gender, Height]
Berikut adalah contoh tindakan yang mustahil:
[Age] -> [Age, Gender, Height] [Age, Gender] -> [Age] [Gender] -> [Gender, Gender]
Kami telah menentukan keadaan dan tindakan, bukan ganjarannya lagi. Ganjaran adalah nombor nyata yang digunakan untuk menilai kualiti negeri.
Dalam masalah pemilihan ciri, satu ganjaran yang mungkin adalah untuk meningkatkan metrik ketepatan model yang sama dengan menambahkan ciri baharu. Berikut ialah contoh bagaimana ganjaran dikira:
[Age] --> Accuracy = 0.65 [Age, Gender] --> Accuracy = 0.76 Reward(Gender) = 0.76 - 0.65 = 0.11
Untuk setiap negeri yang kami lawati buat kali pertama, pengelas (model) dilatih menggunakan set ciri. Nilai ini disimpan dalam keadaan dan pengelas yang sepadan Proses melatih pengelas memakan masa dan susah payah, jadi kami hanya melatihnya sekali. Oleh kerana pengelas tidak mengambil kira susunan ciri, kita boleh menganggap masalah ini sebagai graf dan bukannya pokok. Dalam contoh ini, ganjaran untuk memilih "jantina" sebagai ciri baharu untuk model ialah perbezaan ketepatan antara keadaan semasa dan keadaan seterusnya.
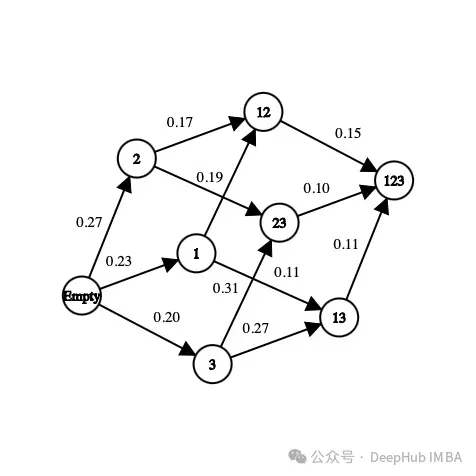
Dalam gambar di atas, setiap ciri dipetakan kepada nombor ("Umur" ialah 1, "Jantina" ialah 2 dan "Ketinggian" ialah 3). Bagaimanakah kita memilih keadaan seterusnya daripada keadaan semasa atau bagaimana kita meneroka alam sekitar?
Kita perlu mencari jalan yang optimum kerana jika kita meneroka semua set ciri yang mungkin dalam masalah dengan 10 ciri, bilangan keadaan akan menjadi
10! + 2 = 3 628 802
这里的+2是因为考虑一个空状态和一个包含所有可能特征的状态。我们不可能在每个状态下都训练一个模型,这是不可能完成的,而且这只是有10个特征,如果有100个特征那基本上就是无解了。
但是在强化学习方法中,我们不需要在所有的状态下都去训练一个模型,我们要为这个问题确定一些停止条件,比如从当前状态随机选择下一个动作,概率为epsilon(介于0和1之间,通常在0.2左右),否则选择使函数最大化的动作。对于特征选择是每个特征对模型精度带来的奖励的平均值。
这里的贪心算法包含两个步骤:
1、以概率为epsilon,我们在当前状态的可能邻居中随机选择下一个状态
2、选择下一个状态,使添加到当前状态的特征对模型的精度贡献最大。为了减少时间复杂度,可以初始化了一个包含每个特征值的列表。每当选择一个特性时,此列表就会更新。使用以下公式,更新是非常理想的:
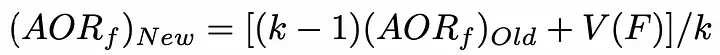
AORf:特征“f”带来的奖励的平均值
K: f被选中的次数
V(F):特征集合F的状态值(为了简单描述,本文不详细介绍)
所以我们就找出哪个特征给模型带来了最高的准确性。这就是为什么我们需要浏览不同的状态,在在许多不同的环境中评估模型特征的最全局准确值。
因为目标是最小化算法访问的状态数,所以我们访问的未访问过的状态越少,需要用不同特征集训练的模型数量就越少。因为从时间和计算能力的角度来看,训练模型以获得精度是最昂贵方法,我们要尽量减少训练的次数。
最后在任何情况下,算法都会停止在最终状态(包含所有特征的集合)而我们希望避免达到这种状态,因为用它来训练模型是最昂贵的。
上面就是我们针对于特征选择的强化学习描述,下面我们将详细介绍在python中的实现。
用于特征选择与强化学习的python库
有一个python库可以让我们直接解决这个问题。但是首先我们先准备数据
我们直接使用UCI机器学习库中的数据:
#Get the pandas DataFrame from the csv file (15 features, 690 rows) australian_data = pd.read_csv('australian_data.csv', header=None) #DataFrame with the features X = australian_data.drop(14, axis=1) #DataFrame with the labels y = australian_data[14]然后安装我们用到的库
pip install FSRLearning
直接导入
from FSRLearning import Feature_Selector_RL
Feature_Selector_RL类就可以创建一个特性选择器。我们需要以下的参数
feature_number (integer): DataFrame X中的特性数量
feature_structure (dictionary):用于图实现的字典
eps (float [0;1]):随机选择下一状态的概率,0为贪婪算法,1为随机算法
alpha (float [0;1]):控制更新速率,0表示不更新状态,1表示经常更新状态
gamma (float[0,1]):下一状态观察的调节因子,0为近视行为状态,1为远视行为
nb_iter (int):遍历图的序列数
starting_state (" empty "或" random "):如果" empty ",则算法从空状态开始,如果" random ",则算法从图中的随机状态开始
所有参数都可以机型调节,但对于大多数问题来说,迭代大约100次就可以了,而epsilon值在0.2左右通常就足够了。起始状态对于更有效地浏览图形很有用,但它非常依赖于数据集,两个值都可以测试。
我们可以用下面的代码简单地初始化选择器:
fsrl_obj = Feature_Selector_RL(feature_number=14, nb_iter=100)
与大多数ML库相同,训练算法非常简单:
results = fsrl_obj.fit_predict(X, y)
下面是输出的一个例子:
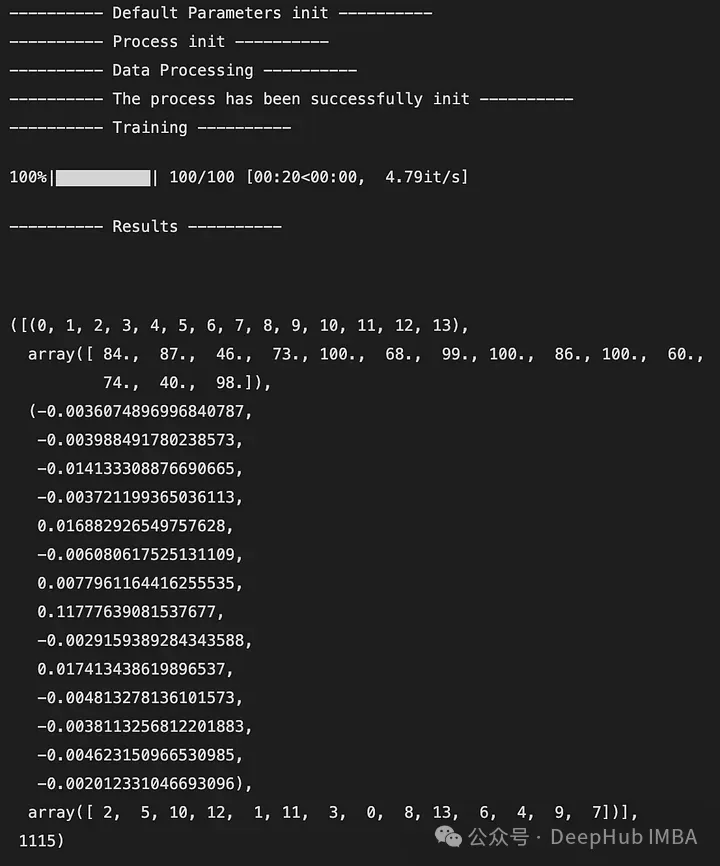
输出是一个5元组,如下所示:
DataFrame X中特性的索引(类似于映射)
特征被观察的次数
所有迭代后特征带来的奖励的平均值
从最不重要到最重要的特征排序(这里2是最不重要的特征,7是最重要的特征)
全局访问的状态数
还可以与Scikit-Learn的RFE选择器进行比较。它将X, y和选择器的结果作为输入。
fsrl_obj.compare_with_benchmark(X, y, results)
输出是在RFE和FSRLearning的全局度量的每一步选择之后的结果。它还输出模型精度的可视化比较,其中x轴表示所选特征的数量,y轴表示精度。两条水平线是每种方法的准确度中值。
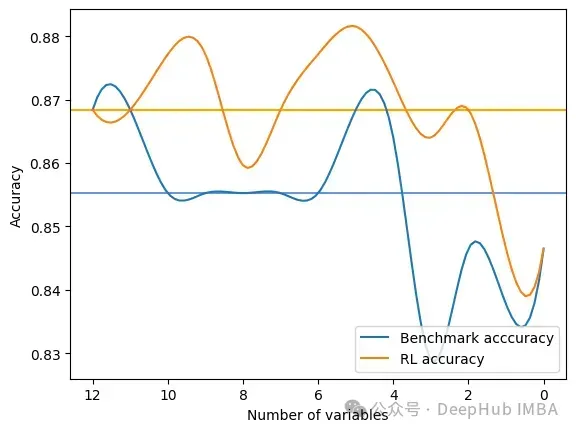
Average benchmark accuracy : 0.854251012145749, rl accuracy : 0.8674089068825909 Median benchmark accuracy : 0.8552631578947368, rl accuracy : 0.868421052631579 Probability to get a set of variable with a better metric than RFE : 1.0 Area between the two curves : 0.17105263157894512
可以看到RL方法总是为模型提供比RFE更好的特征集。
另一个有趣的方法是get_plot_ratio_exploration。它绘制了一个图,比较一个精确迭代序列中已经访问节点和访问节点的数量。
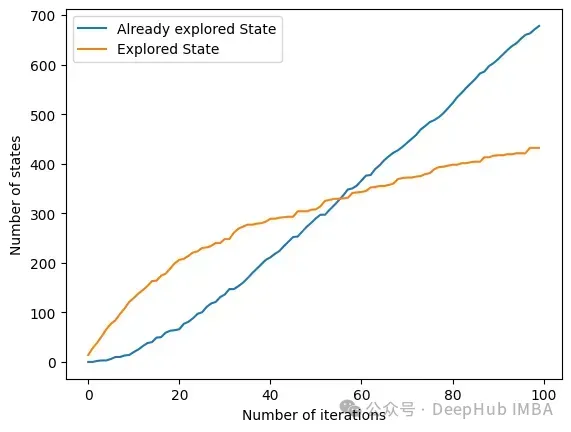
由于设置了停止条件,算法的时间复杂度呈指数级降低。即使特征的数量很大,收敛性也会很快被发现。下面的图表示一定大小的集合被访问的次数。
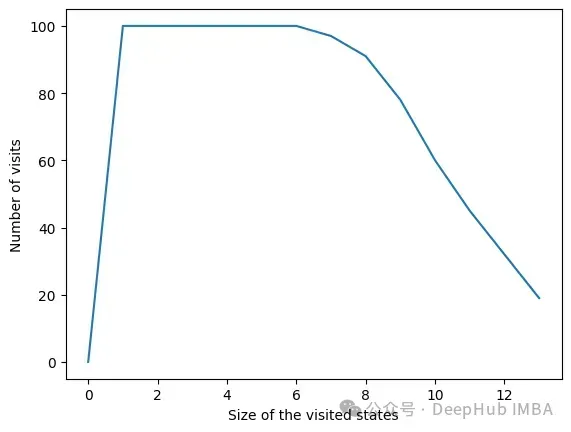
在所有迭代中,算法访问包含6个或更少变量的状态。在6个变量之外,我们可以看到达到的状态数量正在减少。这是一个很好的行为,因为用小的特征集训练模型比用大的特征集训练模型要快。
总结
我们可以看到RL方法对于最大化模型的度量是非常有效的。它总是很快地收敛到一个有趣的特性子集。该方法在使用FSRLearning库的ML项目中非常容易和快速地实现。
Atas ialah kandungan terperinci Pemilihan ciri melalui strategi pembelajaran pengukuhan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
Anotasi imej ialah proses mengaitkan label atau maklumat deskriptif dengan imej untuk memberi makna dan penjelasan yang lebih mendalam kepada kandungan imej. Proses ini penting untuk pembelajaran mesin, yang membantu melatih model penglihatan untuk mengenal pasti elemen individu dalam imej dengan lebih tepat. Dengan menambahkan anotasi pada imej, komputer boleh memahami semantik dan konteks di sebalik imej, dengan itu meningkatkan keupayaan untuk memahami dan menganalisis kandungan imej. Anotasi imej mempunyai pelbagai aplikasi, meliputi banyak bidang, seperti penglihatan komputer, pemprosesan bahasa semula jadi dan model penglihatan graf Ia mempunyai pelbagai aplikasi, seperti membantu kenderaan dalam mengenal pasti halangan di jalan raya, dan membantu dalam proses. pengesanan dan diagnosis penyakit melalui pengecaman imej perubatan. Artikel ini terutamanya mengesyorkan beberapa alat anotasi imej sumber terbuka dan percuma yang lebih baik. 1.Makesen
 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Artikel ini akan memperkenalkan cara mengenal pasti pemasangan lampau dan kekurangan dalam model pembelajaran mesin secara berkesan melalui keluk pembelajaran. Underfitting dan overfitting 1. Overfitting Jika model terlampau latihan pada data sehingga ia mempelajari bunyi daripadanya, maka model tersebut dikatakan overfitting. Model yang dipasang terlebih dahulu mempelajari setiap contoh dengan sempurna sehingga ia akan salah mengklasifikasikan contoh yang tidak kelihatan/baharu. Untuk model terlampau, kami akan mendapat skor set latihan yang sempurna/hampir sempurna dan set pengesahan/skor ujian yang teruk. Diubah suai sedikit: "Punca overfitting: Gunakan model yang kompleks untuk menyelesaikan masalah mudah dan mengekstrak bunyi daripada data. Kerana set data kecil sebagai set latihan mungkin tidak mewakili perwakilan yang betul bagi semua data. 2. Underfitting Heru
 Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Pada tahun 1950-an, kecerdasan buatan (AI) dilahirkan. Ketika itulah penyelidik mendapati bahawa mesin boleh melakukan tugas seperti manusia, seperti berfikir. Kemudian, pada tahun 1960-an, Jabatan Pertahanan A.S. membiayai kecerdasan buatan dan menubuhkan makmal untuk pembangunan selanjutnya. Penyelidik sedang mencari aplikasi untuk kecerdasan buatan dalam banyak bidang, seperti penerokaan angkasa lepas dan kelangsungan hidup dalam persekitaran yang melampau. Penerokaan angkasa lepas ialah kajian tentang alam semesta, yang meliputi seluruh alam semesta di luar bumi. Angkasa lepas diklasifikasikan sebagai persekitaran yang melampau kerana keadaannya berbeza daripada di Bumi. Untuk terus hidup di angkasa, banyak faktor mesti dipertimbangkan dan langkah berjaga-jaga mesti diambil. Para saintis dan penyelidik percaya bahawa meneroka ruang dan memahami keadaan semasa segala-galanya boleh membantu memahami cara alam semesta berfungsi dan bersedia untuk menghadapi kemungkinan krisis alam sekitar
 Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Dalam istilah orang awam, model pembelajaran mesin ialah fungsi matematik yang memetakan data input kepada output yang diramalkan. Secara lebih khusus, model pembelajaran mesin ialah fungsi matematik yang melaraskan parameter model dengan belajar daripada data latihan untuk meminimumkan ralat antara output yang diramalkan dan label sebenar. Terdapat banyak model dalam pembelajaran mesin, seperti model regresi logistik, model pepohon keputusan, model mesin vektor sokongan, dll. Setiap model mempunyai jenis data dan jenis masalah yang berkenaan. Pada masa yang sama, terdapat banyak persamaan antara model yang berbeza, atau terdapat laluan tersembunyi untuk evolusi model. Mengambil perceptron penyambung sebagai contoh, dengan meningkatkan bilangan lapisan tersembunyi perceptron, kita boleh mengubahnya menjadi rangkaian neural yang mendalam. Jika fungsi kernel ditambah pada perceptron, ia boleh ditukar menjadi SVM. yang ini
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
MetaFAIR bekerjasama dengan Harvard untuk menyediakan rangka kerja penyelidikan baharu untuk mengoptimumkan bias data yang dijana apabila pembelajaran mesin berskala besar dilakukan. Adalah diketahui bahawa latihan model bahasa besar sering mengambil masa berbulan-bulan dan menggunakan ratusan atau bahkan ribuan GPU. Mengambil model LLaMA270B sebagai contoh, latihannya memerlukan sejumlah 1,720,320 jam GPU. Melatih model besar memberikan cabaran sistemik yang unik disebabkan oleh skala dan kerumitan beban kerja ini. Baru-baru ini, banyak institusi telah melaporkan ketidakstabilan dalam proses latihan apabila melatih model AI generatif SOTA Mereka biasanya muncul dalam bentuk lonjakan kerugian Contohnya, model PaLM Google mengalami sehingga 20 lonjakan kerugian semasa proses latihan. Bias berangka adalah punca ketidaktepatan latihan ini,
