
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask

실제 배포: 엔드투엔드 탐지 및 추적을 위한 동적 순차 네트워크

본 글은 자율주행하트 공개 계정의 승인을 받아 재인쇄되었습니다.
자체 개발 칩을 생산하는 몇몇 주요 제조업체를 제외하면 대부분의 자율주행 회사는 TensorRT와 분리될 수 없는 NVIDIA 칩을 사용할 것이라고 믿습니다. TensorRT는 다양한 NVIDIA GPU 하드웨어 플랫폼에서 실행되는 C++ 추론 프레임워크입니다. Pytorch, TF 또는 기타 프레임워크를 사용하여 훈련한 모델은 먼저 onnx 형식으로 변환한 다음 TensorRT 형식으로 변환한 다음 TensorRT 추론 엔진을 사용하여 모델을 실행함으로써 NVIDIA GPU에서 이 모델을 실행하는 속도를 향상시킬 수 있습니다. .
일반적으로 onnx와 TensorRT는 상대적으로 고정된 모델(모든 수준, 단일 분기 등의 고정된 입력 및 출력 형식 포함)만 지원하고 가장 바깥쪽 동적 입력만 지원합니다(onnx 내보내기는 Dynamic_axes 매개변수를 설정하여 결정할 수 있음) 차원의 동적 변화를 허용하기 위해) 그러나 인식 알고리즘의 최전선에서 활동하는 친구들은 중요한 개발 추세가 표적 탐지, 표적 추적, 궤도 예측, 의사 결정 계획 등을 포괄할 수 있는 end-2-end라는 것을 알게 될 것입니다. 구동 링크이며 전면 및 후면 프레임과 밀접한 관련이 있는 타이밍 모델이어야 합니다. 엔드투엔드 표적 탐지 및 표적 추적을 달성하는 MUTR3D 모델을 대표적인 예로 사용할 수 있습니다(모델 소개는 참조). :)
MOTR/MUTR3D에서는 진정한 엔드투엔드 다중 객체 추적을 달성하기 위한 라벨 할당 메커니즘의 이론과 예를 자세히 설명합니다. 자세한 내용을 보려면 링크를 클릭하십시오: https://zhuanlan.zhihu.com/p/609123786
이 모델을 TensorRT 형식으로 변환하고 정밀 정렬을 달성하는 경우, 심지어 fp16 정밀 정렬도 일련의 동적 요소에 직면할 수 있습니다. 예를 들어, 여러 if-else 분기, 하위 네트워크 입력 형태의 동적 변경, 동적 처리가 필요한 기타 작업 및 연산자 등
 Pictures
Pictures
MUTR3D 아키텍처 전체 프로세스에 많은 세부 사항이 포함되므로 상황이 다릅니다. 전체 네트워크의 참고 자료를 보거나 Google에서 검색해도 플러그 앤 플레이 솔루션을 찾기가 어렵습니다. 한 달 이상의 지속적인 분할과 실험을 통해 하나씩 해결할 수 있습니다. 그리고 블로거의 연습(TensorRT에 대한 이전 경험은 많지 않았고 그 성질을 이해하지 못했습니다). 저는 많은 두뇌를 사용했고 많은 함정을 밟았습니다. 마침내 성공적으로 변환하고 fp32/fp16 정밀 정렬을 달성했습니다. , 단순 표적 탐지에 비해 지연 증가가 매우 작았습니다. 여기에 간단한 요약을 하여 모두에게 참고가 되고자 합니다. (네, 그동안 리뷰를 쓰다 드디어 실습에 대해 글을 쓰게 되었습니다!)
1. 데이터 형식 문제
우선 MUTR3D의 데이터 형식이 꽤 특별합니다. , 그리고 모든 예제가 사용됩니다. 이는 각 쿼리가 더 많은 정보에 바인딩되고 더 쉬운 일대일 액세스를 위해 인스턴스로 패키징되기 때문입니다. 그러나 배포의 경우 입력과 출력은 텐서만 가능하므로 인스턴스 데이터는 반드시 필요합니다. 먼저 디스어셈블하면 여러 개의 텐서 변수가 되며, 현재 프레임의 쿼리 및 기타 변수가 모델에 생성되므로 이전 프레임에 보관된 쿼리 및 기타 변수만 입력하고 이 둘을 모델에 연결하면 됩니다. .
2 .padding은 입력 동적 형태 문제를 해결합니다
입력 선주문 프레임 쿼리 및 기타 변수의 경우 중요한 문제는 형태가 불확실하다는 것입니다. 이는 MUTR3D가 이전 프레임에서 대상을 감지한 쿼리만 유지하기 때문입니다. 이 문제는 상대적으로 해결하기 쉽습니다. 가장 간단한 방법은 패딩, 즉 고정된 크기로 패딩하는 것입니다. 쿼리의 경우 패딩에 모두 0을 사용할 수 있습니다. 적절한 숫자는 자체 데이터를 기반으로 한 실험을 통해 결정될 수 있습니다. 너무 적으면 목표를 쉽게 놓치고, 너무 많으면 공간을 낭비하게 됩니다. onnx의 Dynamic_axes 파라미터는 동적 입력을 구현할 수 있지만 후속 변환기에서 계산한 크기를 포함하므로 문제가 있을 수 있습니다. 아직 시도해보지 않았지만 독자들은 시도해 볼 수 있습니다
3. 패딩이 주 변환기의 self-attention 모듈에 미치는 영향
특수 연산자를 사용하지 않으면 패딩 후 ONNX 및 TensorRT로 성공적으로 변환할 수 있습니다. 실제로 이런 상황이 발생해야 하지만 이는 이 기사의 범위를 벗어납니다. 예를 들어, MUTR3D에서는 프레임 간 참조점을 이동할 때 torch.linalg.inv 연산자를 사용하여 의사 역행렬을 찾는 기능이 지원되지 않습니다. 지원되지 않는 연산자를 발견하면 교체를 시도해야 합니다. 작동하지 않으면 모델 외부에서만 사용할 수 있습니다. 숙련된 사람도 자신의 연산자를 작성할 수 있습니다. 하지만 이 단계는 모델의 전처리 및 후처리에 배치될 수 있기 때문에 모델 외부로 이동하기로 결정했습니다. 자체 연산자를 작성하는 것이 더 어려울 것입니다
성공적인 변환이 모든 것이 잘 된다는 것을 의미하지는 않습니다. 대답은 종종 '아니요'입니다. 정확도 차이가 매우 크다는 것을 알 수 있습니다. 이는 모델에 모듈이 많기 때문입니다. 먼저 첫 번째 이유에 대해 이야기해 보겠습니다. Transformer의 self-attention 단계에서는 여러 쿼리 간의 정보 상호작용이 발생합니다. 그러나 원본 모델은 대상이 한 번 감지된 쿼리(모델에서는 활성 쿼리라고 함)만 유지하며 이러한 쿼리만 현재 프레임의 쿼리와 상호 작용해야 합니다. 그리고 이제는 유효하지 않은 쿼리가 많이 채워지기 때문에 모든 쿼리가 함께 상호 작용하면 필연적으로 결과에 영향을 미치게 됩니다
이 문제에 대한 해결책은 DN-DETR[1]에서 영감을 얻었는데, 이는 nn.MultiheadAttention의 'attn_mask' 매개변수에 해당하는 attention_mask를 사용하는 것입니다. 그 기능은 처음에는 정보 상호 작용이 필요하지 않은 쿼리를 차단하는 것입니다. 이는 NLP에서 모든 문장이 현재 요구 사항을 정확히 충족하는 일관되지 않은 길이로 설정되어 있기 때문입니다. True는 차단해야 하는 쿼리를 나타내고 False는 유효한 쿼리를 나타냅니다.
attention 마스크 다이어그램 attention_mask를 계산하는 로직이 조금 복잡하기 때문에 TensorRT를 연산하고 변환할 때 새로운 문제가 발생할 수 있으므로 모델 외부에서 계산하여 모델에 입력 변수로 입력한 후 전달해야 합니다. 다음은 샘플 코드입니다. 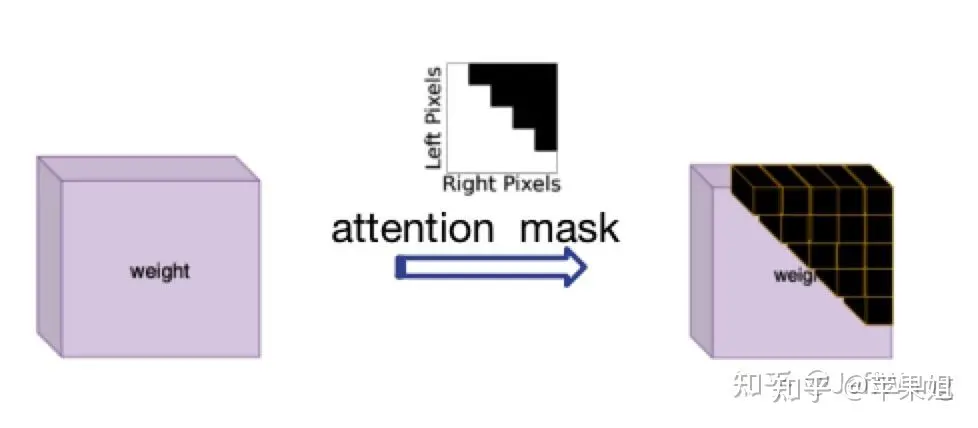
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
로그인 후 복사
5. of padding on the 출력 결과위의 4가지 사항을 완료한 후 기본적으로 모델 변환 tensorRT의 논리에 문제가 없음을 확인할 수 있지만, 출력 결과를 여러 번 검증한 후에도 일부 프레임에서는 여전히 문제가 있습니다. 그런데 프레임별로 데이터를 분석해 보면 일부 프레임의 패딩 쿼리가 변환기 계산에 참여하지 않음에도 불구하고 더 높은 점수를 얻은 후 잘못된 결과를 얻을 수 있다는 것을 알 수 있습니다. 이런 상황은 실제로 데이터 양이 많을 때 가능합니다. 왜냐하면 패딩 쿼리는 초기값이 0만 있고 참조점도 [0,0]이기 때문입니다. 다른 랜덤 초기화 쿼리와는 달리 쿼리는 동일한 작업을 수행하기 때문입니다. 이는 결국 패딩 쿼리이므로 결과를 사용할 의도가 없으므로 필터링해야 합니다. 패딩 쿼리 결과를 필터링하는 방법은 무엇입니까? 쿼리를 채우는 토큰은 인덱스 위치일 뿐이며 구체적인 다른 정보는 없습니다. 인덱스 정보는 실제로 모델 외부에서 전달되는 포인트 3에서 사용된 어텐션 마스크에 기록됩니다. 이 마스크는 2차원이며 차원(행 또는 열) 중 하나를 사용하여 채워진 track_score를 0으로 직접 설정할 수 있습니다. 4단계의 주의 사항에 주의를 기울이십시오. 즉, 인덱스된 슬라이스 할당 대신 행렬 계산을 사용하려고 시도하고 계산을 부동 소수점 유형으로 변환해야 합니다. 다음은 코드 예입니다. obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
로그인 후 복사
6. track_id를 동적으로 업데이트하는 방법모델 본문 외에도 실제로 매우 중요한 단계가 있는데, 이는 모델의 중요한 요소이기도 한 track_id를 동적으로 업데이트하는 것입니다. 하지만 원래 모델에서는 track_id를 업데이트하는 방법이 상대적으로 복잡한 루프 판단입니다. 즉, Score thresh보다 높고 새 대상이면 새 obj_idx가 할당됩니다. 필터 점수 thresh보다 낮고 오래된 대상이면 해당 사라지는 시간 + 1, 사라지는 시간이 초과되면 해당 obj idx가 -1로 설정됩니다. 즉, 대상이 폐기됩니다. tensorRT는 if-else 다중 분기 문을 지원하지 않는다는 것을 알고 있습니다(음, 처음에는 몰랐습니다). 이는 업데이트된 track_id도 모델 외부에 배치되면 끝에 영향을 미칠 뿐만 아니라 -to-end 아키텍처이지만 QIM이 업데이트된 track_id를 기반으로 쿼리를 필터링하기 때문에 QIM을 사용할 수 없게 만듭니다. 따라서 업데이트된 track_id를 모델 내부에 넣으려면 머리를 써야 합니다.창의력을 활용하세요 다시 말하지만(거의 다 소모됨) if-else 문은 대체 불가능하지 않습니다. 예를 들어 조건을 마스크로 변환합니다(예: tensor[mask] = 0). 5에서는 tensorRT가 인덱스 슬라이스 할당 작업을 지원하지 않는다고 언급했지만 bool 인덱스 할당은 지원합니다. 텐서의 모양은 슬라이스 작업에 의해 암시적으로 변경될 수 있다고 추측됩니다. 그러나 많은 실험을 거친 후에는 그렇지 않습니다. 인덱스 할당은 모든 경우에 지원되지만 다음과 같은 문제가 발생합니다.
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
위 내용은 실제 배포: 엔드투엔드 탐지 및 추적을 위한 동적 순차 네트워크의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 자율주행 분야에서 Gaussian Splatting이 인기를 끌면서 NeRF가 폐기되기 시작한 이유는 무엇입니까?
Jan 17, 2024 pm 02:57 PM
자율주행 분야에서 Gaussian Splatting이 인기를 끌면서 NeRF가 폐기되기 시작한 이유는 무엇입니까?
Jan 17, 2024 pm 02:57 PM
위에 작성됨 및 저자의 개인적인 이해 3DGS(3차원 가우스플래팅)는 최근 몇 년간 명시적 방사선장 및 컴퓨터 그래픽 분야에서 등장한 혁신적인 기술입니다. 이 혁신적인 방법은 수백만 개의 3D 가우스를 사용하는 것이 특징이며, 이는 주로 암시적 좌표 기반 모델을 사용하여 공간 좌표를 픽셀 값에 매핑하는 NeRF(Neural Radiation Field) 방법과 매우 다릅니다. 명시적인 장면 표현과 미분 가능한 렌더링 알고리즘을 갖춘 3DGS는 실시간 렌더링 기능을 보장할 뿐만 아니라 전례 없는 수준의 제어 및 장면 편집 기능을 제공합니다. 이는 3DGS를 차세대 3D 재구성 및 표현을 위한 잠재적인 게임 체인저로 자리매김합니다. 이를 위해 우리는 처음으로 3DGS 분야의 최신 개발 및 관심사에 대한 체계적인 개요를 제공합니다.
 자율주행 시나리오에서 롱테일 문제를 해결하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:44 PM
자율주행 시나리오에서 롱테일 문제를 해결하는 방법은 무엇입니까?
Jun 02, 2024 pm 02:44 PM
어제 인터뷰 도중 롱테일 관련 질문을 해본 적이 있느냐는 질문을 받아서 간략하게 요약해볼까 생각했습니다. 자율주행의 롱테일 문제는 자율주행차의 엣지 케이스, 즉 발생 확률이 낮은 가능한 시나리오를 말한다. 인지된 롱테일 문제는 현재 단일 차량 지능형 자율주행차의 운영 설계 영역을 제한하는 주요 이유 중 하나입니다. 자율주행의 기본 아키텍처와 대부분의 기술적인 문제는 해결되었으며, 나머지 5%의 롱테일 문제는 점차 자율주행 발전을 제한하는 핵심이 되었습니다. 이러한 문제에는 다양한 단편적인 시나리오, 극단적인 상황, 예측할 수 없는 인간 행동이 포함됩니다. 자율 주행에서 엣지 시나리오의 "롱테일"은 자율주행차(AV)의 엣지 케이스를 의미하며 발생 확률이 낮은 가능한 시나리오입니다. 이런 희귀한 사건
 카메라 또는 LiDAR를 선택하시겠습니까? 강력한 3D 객체 감지 달성에 대한 최근 검토
Jan 26, 2024 am 11:18 AM
카메라 또는 LiDAR를 선택하시겠습니까? 강력한 3D 객체 감지 달성에 대한 최근 검토
Jan 26, 2024 am 11:18 AM
0. 전면 작성&& 자율주행 시스템은 다양한 센서(예: 카메라, 라이더, 레이더 등)를 사용하여 주변 환경을 인식하고 알고리즘과 모델을 사용하는 고급 인식, 의사결정 및 제어 기술에 의존한다는 개인적인 이해 실시간 분석과 의사결정을 위해 이를 통해 차량은 도로 표지판을 인식하고, 다른 차량을 감지 및 추적하며, 보행자 행동을 예측하는 등 복잡한 교통 환경에 안전하게 작동하고 적응할 수 있게 되므로 현재 널리 주목받고 있으며 미래 교통의 중요한 발전 분야로 간주됩니다. . 하나. 하지만 자율주행을 어렵게 만드는 것은 자동차가 주변에서 일어나는 일을 어떻게 이해할 수 있는지 알아내는 것입니다. 이를 위해서는 자율주행 시스템의 3차원 객체 감지 알고리즘이 주변 환경의 객체의 위치를 포함하여 정확하게 인지하고 묘사할 수 있어야 하며,
 Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
Stable Diffusion 3 논문이 드디어 공개되고, 아키텍처의 세부 사항이 공개되어 Sora를 재현하는 데 도움이 될까요?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3의 논문이 드디어 나왔습니다! 이 모델은 2주 전에 출시되었으며 Sora와 동일한 DiT(DiffusionTransformer) 아키텍처를 사용합니다. 출시되자마자 큰 화제를 불러일으켰습니다. 이전 버전과 비교하여 StableDiffusion3에서 생성된 이미지의 품질이 크게 향상되었습니다. 이제 다중 테마 프롬프트를 지원하고 텍스트 쓰기 효과도 향상되었으며 더 이상 잘못된 문자가 표시되지 않습니다. StabilityAI는 StableDiffusion3이 800M에서 8B 범위의 매개변수 크기를 가진 일련의 모델임을 지적했습니다. 이 매개변수 범위는 모델이 많은 휴대용 장치에서 직접 실행될 수 있어 AI 사용이 크게 줄어든다는 것을 의미합니다.
 SIMPL: 자율 주행을 위한 간단하고 효율적인 다중 에이전트 동작 예측 벤치마크
Feb 20, 2024 am 11:48 AM
SIMPL: 자율 주행을 위한 간단하고 효율적인 다중 에이전트 동작 예측 벤치마크
Feb 20, 2024 am 11:48 AM
원제목: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 논문 링크: https://arxiv.org/pdf/2402.02519.pdf 코드 링크: https://github.com/HKUST-Aerial-Robotics/SIMPL 저자 단위: Hong Kong University of Science 및 기술 DJI 논문 아이디어: 이 논문은 자율주행차를 위한 간단하고 효율적인 모션 예측 기준선(SIMPL)을 제안합니다. 기존 에이전트 센트와 비교
 자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행과 궤도예측에 관한 글은 이 글이면 충분합니다!
Feb 28, 2024 pm 07:20 PM
자율주행 궤적 예측은 차량의 주행 과정에서 발생하는 다양한 데이터를 분석하여 차량의 향후 주행 궤적을 예측하는 것을 의미합니다. 자율주행의 핵심 모듈인 궤도 예측의 품질은 후속 계획 제어에 매우 중요합니다. 궤적 예측 작업은 풍부한 기술 스택을 보유하고 있으며 자율 주행 동적/정적 인식, 고정밀 지도, 차선, 신경망 아키텍처(CNN&GNN&Transformer) 기술 등에 대한 익숙함이 필요합니다. 시작하기가 매우 어렵습니다! 많은 팬들은 가능한 한 빨리 궤도 예측을 시작하여 함정을 피하기를 희망합니다. 오늘은 궤도 예측을 위한 몇 가지 일반적인 문제와 입문 학습 방법을 살펴보겠습니다. 관련 지식 입문 1. 미리보기 논문이 순서대로 되어 있나요? A: 먼저 설문조사를 보세요, p
 엔드투엔드(End-to-End)와 차세대 자율주행 시스템, 그리고 엔드투엔드 자율주행에 대한 몇 가지 오해에 대해 이야기해볼까요?
Apr 15, 2024 pm 04:13 PM
엔드투엔드(End-to-End)와 차세대 자율주행 시스템, 그리고 엔드투엔드 자율주행에 대한 몇 가지 오해에 대해 이야기해볼까요?
Apr 15, 2024 pm 04:13 PM
지난 달에는 몇 가지 잘 알려진 이유로 업계의 다양한 교사 및 급우들과 매우 집중적인 교류를 가졌습니다. 교환에서 피할 수 없는 주제는 자연스럽게 엔드투엔드와 인기 있는 Tesla FSDV12입니다. 저는 이 기회를 빌어 여러분의 참고와 토론을 위해 지금 이 순간 제 생각과 의견을 정리하고 싶습니다. End-to-End 자율주행 시스템을 어떻게 정의하고, End-to-End 해결을 위해 어떤 문제가 예상되나요? 가장 전통적인 정의에 따르면, 엔드 투 엔드 시스템은 센서로부터 원시 정보를 입력하고 작업과 관련된 변수를 직접 출력하는 시스템을 의미합니다. 예를 들어 이미지 인식에서 CNN은 기존의 특징 추출 + 분류기 방식에 비해 end-to-end 방식으로 호출할 수 있습니다. 자율주행 작업에서는 다양한 센서(카메라/LiDAR)로부터 데이터를 입력받아
 DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer 및 BEVDet4D를 크게 능가하는 책을 펼치세요!
Mar 21, 2024 pm 05:21 PM
본 논문에서는 자율 주행에서 다양한 시야각(예: 원근 및 조감도)에서 객체를 정확하게 감지하는 문제, 특히 원근(PV) 공간에서 조감(BEV) 공간으로 기능을 효과적으로 변환하는 방법을 탐구합니다. VT(Visual Transformation) 모듈을 통해 구현됩니다. 기존 방법은 크게 2D에서 3D로, 3D에서 2D로 변환하는 두 가지 전략으로 나뉩니다. 2D에서 3D로의 방법은 깊이 확률을 예측하여 조밀한 2D 특징을 개선하지만, 특히 먼 영역에서는 깊이 예측의 본질적인 불확실성으로 인해 부정확성이 발생할 수 있습니다. 3D에서 2D로의 방법은 일반적으로 3D 쿼리를 사용하여 2D 기능을 샘플링하고 Transformer를 통해 3D와 2D 기능 간의 대응에 대한 주의 가중치를 학습하므로 계산 및 배포 시간이 늘어납니다.
