

给你八分钟搞定dedeCMS(织梦内容管理系统)_PHP教程

<span 第1分钟_dedeCMS概述</span>
织梦内容管理系统(DedeCms) 以简单、实用、开源而闻名,是国内最知名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统,在经历了二年多的发展,目前的版本无论在功能,还是在易用性方面,都有了长足的发展,DedeCms免费版的主要目标用户锁定在个人站长,功能更专注于个人网站或中小型门户的构建,当然也不乏有企业用户和学校等在使用本系统。织梦内容管理系统(DedeCms)基于PHP+MySQL的技术架构,完全开源加上强大稳定的技术架构,使你无论是目前打算做个小型网站,还是想让网站在不断壮大后系仍能得到随意扩充都有充分的保证。
更多信息 :织梦内容管理系统 织梦_百科
<span 第2分钟_dedeCMS安装</span>
操作系统:Windows 7
下载和安装php运行环境:WAMP5
下载dedeCMS :http://www.dedecms.com/products/dedecms/downloads/ 我下载的是:dedeCMS V5.7
解压缩后放入到wamp的www目录下面:

运行WAMP,打开浏览器输入:http://localhost:2000/install/进行安装
<span 第3分钟_进入CMS后台</span>
安装成功后,可以进入后台登陆界面进行后台管理操作

这里要说的是:

最初看这个界面的时候,很陌生,只是知道界面有很多功能,但是不是很清楚他们干啥用的...
我是用dedeCMS来做一个官网,所以用的的功能不是很多.
<span 第4分钟_核心</span>
这里主要是生成网站的导航,并且可以像导航中添加文章...(这里我特别强调,原因是我很喜欢这里的这个思想...把导航中所有的内容都可以用文章的形式来表示出来)
这里是工作的第一步,至少我是这么认为的..
<span 第5分钟_系统</span>
在系统这一栏目中,我们需要的是设置一些我们的系统变量,在这里设置好了系统变量了以后,方便我们在之后的开发过程中灵活的调用这些变量
<span 第6分钟_模板</span>
在dedeCMS中,最灵活的应该就是系统提供的模版,在这里,我们可以把我们的页面编辑成为模版,然后被调用....
更多模版标签:http://help.dedecms.com/v53/archives/tag/
<span 第7分钟_生成</span>
在上一分钟中,我们写好了我们自己的模版后,我们需要使用这些模版,我们可以在导航栏目中调用这些模版,最后生成我们的页面.
在这里我需要强调的是,这里涉及到缓存的东东,我们有必要使用:一键更新网站-->更新所有...因为在我做的时候,就碰到过由于缓存的问题,是我都不敢相信我到底哪里出错啦...
<span 第8分钟_预览页面</span>
上面都没出错的话,你现在就可以浏览你的页面啦....
写在末尾:dedeCMS是一个不错的东东,在这里给大家伙推荐一下..
更多帮助:http://help.dedecms.com

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 10가지 권장 오픈 소스 무료 텍스트 주석 도구
Mar 26, 2024 pm 08:20 PM
10가지 권장 오픈 소스 무료 텍스트 주석 도구
Mar 26, 2024 pm 08:20 PM
텍스트 주석은 텍스트의 특정 내용에 해당하는 레이블이나 태그를 추가하는 작업입니다. 주요 목적은 특히 인공 지능 분야에서 더 심층적인 분석 및 처리를 위해 텍스트에 추가 정보를 제공하는 것입니다. 텍스트 주석은 인공 지능 애플리케이션의 지도형 기계 학습 작업에 매우 중요합니다. 자연어 텍스트 정보를 보다 정확하게 이해하고 텍스트 분류, 감정 분석, 언어 번역 등의 작업 성능을 향상시키기 위해 AI 모델을 훈련하는 데 사용됩니다. 텍스트 주석을 통해 우리는 AI 모델이 텍스트의 개체를 인식하고, 맥락을 이해하고, 새로운 유사한 데이터가 나타날 때 정확한 예측을 하도록 가르칠 수 있습니다. 이 기사에서는 주로 더 나은 오픈 소스 텍스트 주석 도구를 권장합니다. 1.라벨스튜디오https://github.com/Hu
 15가지 추천 오픈 소스 무료 이미지 주석 도구
Mar 28, 2024 pm 01:21 PM
15가지 추천 오픈 소스 무료 이미지 주석 도구
Mar 28, 2024 pm 01:21 PM
이미지 주석은 이미지 콘텐츠에 더 깊은 의미와 설명을 제공하기 위해 이미지에 레이블이나 설명 정보를 연결하는 프로세스입니다. 이 프로세스는 비전 모델을 훈련하여 이미지의 개별 요소를 보다 정확하게 식별하는 데 도움이 되는 기계 학습에 매우 중요합니다. 이미지에 주석을 추가함으로써 컴퓨터는 이미지 뒤의 의미와 맥락을 이해할 수 있으므로 이미지 내용을 이해하고 분석하는 능력이 향상됩니다. 이미지 주석은 컴퓨터 비전, 자연어 처리, 그래프 비전 모델 등 다양한 분야를 포괄하여 차량이 도로의 장애물을 식별하도록 지원하는 등 광범위한 애플리케이션을 보유하고 있습니다. 의료영상인식을 통한 질병진단. 이 기사에서는 주로 더 나은 오픈 소스 및 무료 이미지 주석 도구를 권장합니다. 1.마케센스
 전각 영문자를 반각 형태로 변환하는 실용적인 팁
Mar 26, 2024 am 09:54 AM
전각 영문자를 반각 형태로 변환하는 실용적인 팁
Mar 26, 2024 am 09:54 AM
전각 영문자를 반각 형태로 변환하는 실용팁 현대생활에서 우리는 영문자를 자주 접하게 되고, 컴퓨터나 휴대폰, 기타 기기를 사용할 때 영문자를 입력해야 하는 경우가 많습니다. 그러나 때로는 영어의 전각 문자를 접하게 되므로 반각 형식을 사용해야 합니다. 그렇다면 전각 영문자를 반각 형태로 변환하는 방법은 무엇일까요? 다음은 몇 가지 실용적인 팁입니다. 먼저, 전각 영문자 및 숫자는 입력방법에서 전각 위치를 차지하는 문자를 말하며, 반각 영문자 및 숫자는 전각 위치를 차지한다.
 권장 사항: 우수한 JS 오픈 소스 얼굴 감지 및 인식 프로젝트
Apr 03, 2024 am 11:55 AM
권장 사항: 우수한 JS 오픈 소스 얼굴 감지 및 인식 프로젝트
Apr 03, 2024 am 11:55 AM
얼굴 검출 및 인식 기술은 이미 상대적으로 성숙하고 널리 사용되는 기술입니다. 현재 가장 널리 사용되는 인터넷 응용 언어는 JS입니다. 웹 프런트엔드에서 얼굴 감지 및 인식을 구현하는 것은 백엔드 얼굴 인식에 비해 장점과 단점이 있습니다. 장점에는 네트워크 상호 작용 및 실시간 인식이 줄어 사용자 대기 시간이 크게 단축되고 사용자 경험이 향상된다는 단점이 있습니다. 모델 크기에 따라 제한되고 정확도도 제한됩니다. js를 사용하여 웹에서 얼굴 인식을 구현하는 방법은 무엇입니까? 웹에서 얼굴 인식을 구현하려면 JavaScript, HTML, CSS, WebRTC 등 관련 프로그래밍 언어 및 기술에 익숙해야 합니다. 동시에 관련 컴퓨터 비전 및 인공지능 기술도 마스터해야 합니다. 웹 측면의 디자인으로 인해 주목할 가치가 있습니다.
 대형 모델을 이해하는 Alibaba 7B 다중 모드 문서, 새로운 SOTA 획득
Apr 02, 2024 am 11:31 AM
대형 모델을 이해하는 Alibaba 7B 다중 모드 문서, 새로운 SOTA 획득
Apr 02, 2024 am 11:31 AM
다중 모드 문서 이해 기능을 위한 새로운 SOTA! Alibaba mPLUG 팀은 최신 오픈 소스 작업인 mPLUG-DocOwl1.5를 출시했습니다. 이 작품은 고해상도 이미지 텍스트 인식, 일반 문서 구조 이해, 지침 따르기, 외부 지식 도입이라는 4가지 주요 과제를 해결하기 위한 일련의 솔루션을 제안했습니다. 더 이상 고민하지 말고 먼저 효과를 살펴보겠습니다. 복잡한 구조의 차트도 한 번의 클릭으로 인식하고 마크다운 형식으로 변환 가능: 다양한 스타일의 차트 사용 가능: 보다 자세한 텍스트 인식 및 위치 지정도 쉽게 처리 가능: 문서 이해에 대한 자세한 설명도 제공 가능: 아시다시피, " 문서 이해"는 현재 대규모 언어 모델 구현을 위한 중요한 시나리오입니다. 시장에는 문서 읽기를 지원하는 많은 제품이 있습니다. 그 중 일부는 주로 텍스트 인식을 위해 OCR 시스템을 사용하고 텍스트 처리를 위해 LLM을 사용합니다.
 단일 카드는 듀얼 카드보다 Llama를 70B 더 빠르게 실행합니다. Microsoft는 A100에 FP6을 넣었습니다 |
Apr 29, 2024 pm 04:55 PM
단일 카드는 듀얼 카드보다 Llama를 70B 더 빠르게 실행합니다. Microsoft는 A100에 FP6을 넣었습니다 |
Apr 29, 2024 pm 04:55 PM
FP8 이하의 부동 소수점 수량화 정밀도는 더 이상 H100의 "특허"가 아닙니다! Lao Huang은 모든 사람이 INT8/INT4를 사용하기를 원했고 Microsoft DeepSpeed 팀은 NVIDIA의 공식 지원 없이 A100에서 FP6을 실행하기 시작했습니다. 테스트 결과에 따르면 A100에 대한 새로운 방법 TC-FPx의 FP6 양자화는 INT4에 가깝거나 때로는 더 빠르며 후자보다 정확도가 더 높은 것으로 나타났습니다. 또한 오픈 소스로 제공되고 DeepSpeed와 같은 딥 러닝 추론 프레임워크에 통합된 엔드투엔드 대규모 모델 지원도 있습니다. 이 결과는 대형 모델 가속화에도 즉각적인 영향을 미칩니다. 이 프레임워크에서는 단일 카드를 사용하여 Llama를 실행하면 처리량이 듀얼 카드보다 2.65배 더 높습니다. 하나
 방금 출시되었습니다! 한 번의 클릭으로 애니메이션 스타일의 이미지를 생성할 수 있는 오픈 소스 모델
Apr 08, 2024 pm 06:01 PM
방금 출시되었습니다! 한 번의 클릭으로 애니메이션 스타일의 이미지를 생성할 수 있는 오픈 소스 모델
Apr 08, 2024 pm 06:01 PM
최신 AIGC 오픈소스 프로젝트인 AnimagineXL3.1을 소개하겠습니다. 이 프로젝트는 사용자에게 더욱 최적화되고 강력한 애니메이션 이미지 생성 경험을 제공하는 것을 목표로 하는 애니메이션 테마의 텍스트-이미지 모델의 최신 버전입니다. AnimagineXL3.1에서 개발 팀은 모델이 성능과 기능 면에서 새로운 수준에 도달할 수 있도록 여러 주요 측면을 최적화하는 데 중점을 두었습니다. 첫째, 이전 버전의 게임 캐릭터 데이터뿐만 아니라 다른 많은 유명 애니메이션 시리즈의 데이터도 훈련 세트에 포함하도록 훈련 데이터를 확장했습니다. 이러한 움직임은 모델의 지식 기반을 풍부하게 하여 다양한 애니메이션 스타일과 캐릭터를 더 완벽하게 이해할 수 있게 해줍니다. AnimagineXL3.1은 새로운 특수 태그 및 미학 세트를 소개합니다.
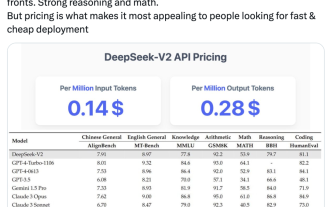 국내 오픈소스 MoE 지표 폭발: GPT-4 수준 기능, API 가격은 1%에 불과
May 07, 2024 pm 05:34 PM
국내 오픈소스 MoE 지표 폭발: GPT-4 수준 기능, API 가격은 1%에 불과
May 07, 2024 pm 05:34 PM
국내 최신 대형 오픈소스 MoE 모델은 출시 직후 인기를 끌었다. DeepSeek-V2의 성능은 GPT-4 수준에 도달하지만 오픈 소스이며 상업용으로 무료이며 API 가격은 GPT-4-Turbo의 1%에 불과합니다. 그래서 공개되자마자 많은 논란이 일었습니다. 공개된 성능 지표에 따르면 DeepSeekV2의 포괄적인 중국어 기능은 많은 오픈 소스 모델을 능가하는 동시에 GPT-4Turbo 및 Wenkuai 4.0과 같은 폐쇄 소스 모델도 첫 번째 단계에 있습니다. 종합적인 영어 능력 역시 LLaMA3-70B와 동일한 1계급에 속하며, 역시 MoE인 Mixtral8x22B를 능가합니다. 또한 지식, 수학, 추론, 프로그래밍 등에서도 좋은 성적을 보여줍니다. 그리고 128K 컨텍스트를 지원합니다. 이것을 상상해 보세요
