

用Python解析XML的几种常见方法的介绍

一、简介
XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用。它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性。
python解析XML常见的有三种方法:一是xml.dom.*模块,它是W3C DOM API的实现,若需要处理DOM API则该模块很适合,注意xml.dom包里面有许多模块,须区分它们间的不同;二是xml.sax.*模块,它是SAX API的实现,这个模块牺牲了便捷性来换取速度和内存占用,SAX是一个基于事件的API,这就意味着它可以“在空中”处理庞大数量的的文档,不用完全加载进内存;三是xml.etree.ElementTree模块(简称 ET),它提供了轻量级的Python式的API,相对于DOM来说ET 快了很多,而且有很多令人愉悦的API可以使用,相对于SAX来说ET的ET.iterparse也提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便。
二、详解
解析的xml文件(country.xml):
在CODE上查看代码片派生到我的代码片
<?xml version="1.0"?>
<data>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
1、xml.etree.ElementTree
ElementTree生来就是为了处理XML,它在Python标准库中有两种实现:一种是纯Python实现的,如xml.etree.ElementTree,另一种是速度快一点的xml.etree.cElementTree。注意:尽量使用C语言实现的那种,因为它速度更快,而且消耗的内存更少。
在CODE上查看代码片派生到我的代码片
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
这是一个让Python不同的库使用相同API的一个比较常用的办法,而从Python 3.3开始ElementTree模块会自动寻找可用的C库来加快速度,所以只需要import xml.etree.ElementTree就可以了。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/evn python
#coding:utf-8
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
import sys
try:
tree = ET.parse("country.xml") #打开xml文档
#root = ET.fromstring(country_string) #从字符串传递xml
root = tree.getroot() #获得root节点
except Exception, e:
print "Error:cannot parse file:country.xml."
sys.exit(1)
print root.tag, "---", root.attrib
for child in root:
print child.tag, "---", child.attrib
print "*"*10
print root[0][1].text #通过下标访问
print root[0].tag, root[0].text
print "*"*10
for country in root.findall('country'): #找到root节点下的所有country节点
rank = country.find('rank').text #子节点下节点rank的值
name = country.get('name') #子节点下属性name的值
print name, rank
#修改xml文件
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
运行结果:
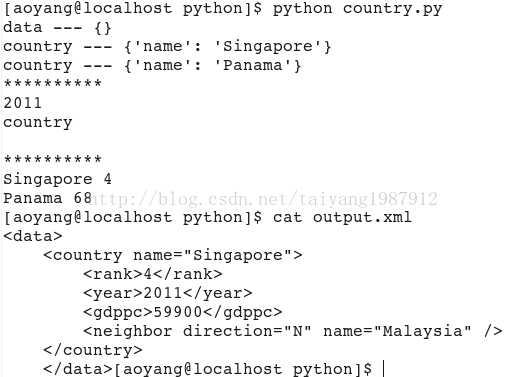
参考:https://docs.python.org/2/library/xml.etree.elementtree.html
2、xml.dom.*
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。一个 DOM 的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。python中用xml.dom.minidom来解析xml文件,例子如下:
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开XML文档
DOMTree = xml.dom.minidom.parse("country.xml")
Data = DOMTree.documentElement
if Data.hasAttribute("name"):
print "name element : %s" % Data.getAttribute("name")
# 在集合中获取所有国家
Countrys = Data.getElementsByTagName("country")
# 打印每个国家的详细信息
for Country in Countrys:
print "*****Country*****"
if Country.hasAttribute("name"):
print "name: %s" % Country.getAttribute("name")
rank = Country.getElementsByTagName('rank')[0]
print "rank: %s" % rank.childNodes[0].data
year = Country.getElementsByTagName('year')[0]
print "year: %s" % year.childNodes[0].data
gdppc = Country.getElementsByTagName('gdppc')[0]
print "gdppc: %s" % gdppc.childNodes[0].data
for neighbor in Country.getElementsByTagName("neighbor"):
print neighbor.tagName, ":", neighbor.getAttribute("name"), neighbor.getAttribute("direction")
运行结果:

参考:https://docs.python.org/2/library/xml.dom.html
3、xml.sax.*
SAX是一种基于事件驱动的API,利用SAX解析XML牵涉到两个部分:解析器和事件处理器。其中解析器负责读取XML文档,并向事件处理器发送事件,如元素开始跟元素结束事件;而事件处理器则负责对事件作出相应,对传递的XML数据进行处理。python中使用sax方式处理xml要先引入xml.sax中的parse函数,还有xml.sax.handler中的ContentHandler。常使用在如下的情况下:一、对大型文件进行处理;二、只需要文件的部分内容,或者只需从文件中得到特定信息;三、想建立自己的对象模型的时候。
ContentHandler类方法介绍
(1)characters(content)方法
调用时机:
从行开始,遇到标签之前,存在字符,content的值为这些字符串。
从一个标签,遇到下一个标签之前, 存在字符,content的值为这些字符串。
从一个标签,遇到行结束符之前,存在字符,content的值为这些字符串。
标签可以是开始标签,也可以是结束标签。
(2)startDocument()方法
文档启动的时候调用。
(3)endDocument()方法
解析器到达文档结尾时调用。
(4)startElement(name, attrs)方法
遇到XML开始标签时调用,name是标签的名字,attrs是标签的属性值字典。
(5)endElement(name)方法
遇到XML结束标签时调用。
在CODE上查看代码片派生到我的代码片
#coding=utf-8
#!/usr/bin/python
import xml.sax
class CountryHandler(xml.sax.ContentHandler):
def __init__(self):
self.CurrentData = ""
self.rank = ""
self.year = ""
self.gdppc = ""
self.neighborname = ""
self.neighbordirection = ""
# 元素开始事件处理
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "country":
print "*****Country*****"
name = attributes["name"]
print "name:", name
elif tag == "neighbor":
name = attributes["name"]
direction = attributes["direction"]
print name, "->", direction
# 元素结束事件处理
def endElement(self, tag):
if self.CurrentData == "rank":
print "rank:", self.rank
elif self.CurrentData == "year":
print "year:", self.year
elif self.CurrentData == "gdppc":
print "gdppc:", self.gdppc
self.CurrentData = ""
# 内容事件处理
def characters(self, content):
if self.CurrentData == "rank":
self.rank = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "gdppc":
self.gdppc = content
if __name__ == "__main__":
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# turn off namepsaces
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = CountryHandler()
parser.setContentHandler(Handler)
parser.parse("country.xml")
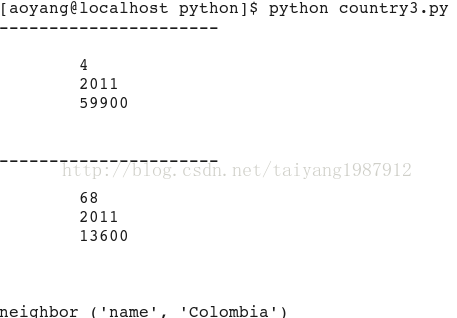
运行结果:

4、libxml2和lxml解析xml
libxml2是使用C语言开发的xml解析器,是一个基于MIT License的免费开源软件,多种编程语言都有基于它的实现,python中的libxml2模块有点小不足的是:xpathEval()接口不支持类似模板的用法,但不影响使用,因libxml2采用C语言开发的,因此在使用API接口的方式上难免会有点不适应。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
import libxml2
doc = libxml2.parseFile("country.xml")
for book in doc.xpathEval('//country'):
if book.content != "":
print "----------------------"
print book.content
for node in doc.xpathEval("//country/neighbor[@name = 'Colombia']"):
print node.name, (node.properties.name, node.properties.content)
doc.freeDoc()
lxml是以libxml2为基础采用python语言开发的,从使用层面上说比lxml更适合python开发者,且xpath()接口支持类似模板的用法。
在CODE上查看代码片派生到我的代码片
#!/usr/bin/python
#coding=utf-8
import lxml.etree
doc = lxml.etree.parse("country.xml")
for node in doc.xpath("//country/neighbor[@name = $name]", name = "Colombia"):
print node.tag, node.items()
for node in doc.xpath("//country[@name = $name]", name = "Singapore"):
print node.tag, node.items()

三、总结
(1)Python中XML解析可用的类库或模块有xml、libxml2 、lxml 、xpath等,需要深入了解的还需参考相应的文档。
(2)每一种解析方式都有自己的优点和缺点,选择前可以综合各个方面的性能考虑。
(3)若有不足,请留言,在此先感谢!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang은 성능과 확장 성 측면에서 Python보다 낫습니다. 1) Golang의 컴파일 유형 특성과 효율적인 동시성 모델은 높은 동시성 시나리오에서 잘 수행합니다. 2) 해석 된 언어로서 파이썬은 천천히 실행되지만 Cython과 같은 도구를 통해 성능을 최적화 할 수 있습니다.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
 Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성
Apr 19, 2025 am 12:20 AM
Python은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.
