

Python中urllib+urllib2+cookielib模块编写爬虫实战

超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件、目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问、操作,从而获取我们想要的内容。对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了。
首先要说明的是,urllib2并非是urllib的升级版,虽然同样作为处理url的相关模块,个人推荐尽量使用urllib2的接口,但我们并不能用urllib2完全代替urllib,处理URL资源有时会需要urllib中的一些函数(如urllib.urllencode)来处理数据。但二者处理url的大致思想都是通过底层封装好的接口让我们能够对url像对本地文件一样进行读取等操作。
下面就是一个获取百度页面内容的代码:
import urllib2
connect= urllib2.Request('http://www.baidu.com')
url1 = urllib2.urlopen(connect)
print url.read()
短短4行在运行之后,就会显示出百度页面的源代码。它的机理是什么呢?
当我们使用urllib2.Request的命令时,我们就向百度搜索的url(“www.baidu.com”)发出了一次HTTP请求,并将该请求映射到connect变量中,当我们使用urllib2.urlopen操作connect后,就会将connect的值返回到url1中,然后我们就可以像操作本地文件一样对url1进行操作,比如这里我们就使用了read()函数来读取该url的源代码。
这样,我们就可以写一只属于自己的简单爬虫了~下面是我写的抓取天涯连载的爬虫:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen(a)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
事实上,上面的代码使用urlopen就可以达到相同的效果了:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
#a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen((url1+str(i)+url3)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
为什么我们还需要先对url进行request处理呢?这里需要引入opener的概念,当我们使用urllib处理url的时候,实际上是通过urllib2.OpenerDirector实例进行工作,他会自己调用资源进行各种操作如通过协议、打开url、处理cookie等。而urlopen方法使用的是默认的opener来处理问题,也就是说,相当的简单粗暴~对于我们post数据、设置header、设置代理等需求完全满足不了。
因此,当面对稍微高点的需求时,我们就需要通过urllib2.build_opener()来创建属于自己的opener,这部分内容我会在下篇博客中详细写~
而对于一些没有特别要求的网站,仅仅使用urllib的2个模块其实就可以获取到我们想要的信息了,但是一些需要模拟登陆或者需要权限的网站,就需要我们处理cookies后才能顺利抓取上面的信息,这时候就需要Cookielib模块了。cookielib 模块就是专门用来处理cookie相关了,其中比较常用的方法就是能够自动处理cookie的CookieJar()了,它可以自动存储HTTP请求生成的cookie,并向传出HTTP的请求中自动添加cookie。正如我前文所提到的,想要使用它的话,需要创建一个新的opener:
import cookielib, urllib2 cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
经过这样的处理后,cookie的问题就解决了~
而想要将cookies输出出来的话,使用print cj._cookies.values()命令后就可以了~
抓取豆瓣同城、登陆图书馆查询图书归还
在掌握了urllib几个模块的相关用法后,接下来就是进入实战步骤了~
(一)抓取豆瓣网站同城活动
豆瓣北京同城活动 该链接指向豆瓣同城活动的列表,向该链接发起request:
# encoding=utf-8 import urllib import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) url="http://beijing.douban.com/events/future-all?start=0" req=urllib2.Request(url) event=urllib2.urlopen(req) str1=event.read()
我们会发现返回的html代码中,除了我们需要的信息之外,还夹杂了大量的页面布局代码:

如上图所示,我们只需要中间那些关于活动的信息。而为了提取信息,我们就需要正则表达式了~
正则表达式是一种跨平台的字符串处理工具/方法,通过正则表达式,我们可以比较轻松的提取字符串中我们想要的内容~
这里不做详细介绍了,个人推荐余晟老师的正则指引,挺适合新手入门的。下面给出正则表达式的大致语法:
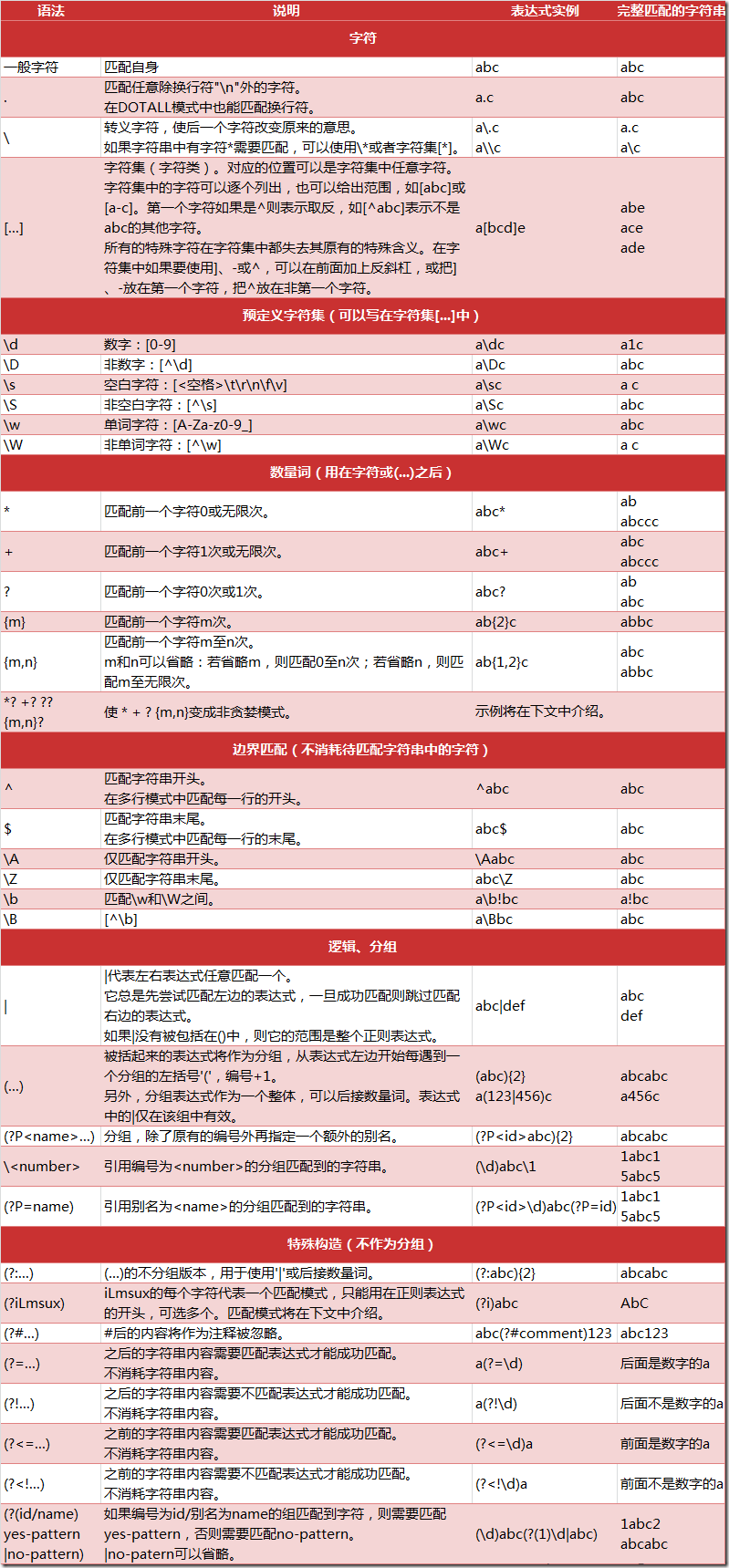
这里我使用捕获分组,将活动四要素(名称,时间,地点,费用)为标准进行分组,得到的表达式如下:
regex=re.compile(r'summary">([\d\D]*?)[\d\D]*?class="hidden-xs">([\d\D]*?)
总体代码如下:
# -*- coding: utf-8 -*-
#---------------------------------------
# program:豆瓣同城爬虫
# author:GisLu
# data:2014-02-08
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
#正则提取
def search(str1):
regex=re.compile(r'summary">([\d\D]*?)</span>[\d\D]*?class="hidden-xs">([\d\D]*?)<time[\d\D]*?<li title="([\d\D]*?)">[\d\D]*?strong>([\d\D]*?)</strong>')
for i in regex.finditer(str1):
print "活动名称:",i.group(1)
a=i.group(2)
b=a.replace('</span>','')
print b.replace('\n','')
print '活动地点:',i.group(3)
c=i.group(4).decode('utf-8')
print '费用:',c
#获取url
for i in range(0,5):
url="http://beijing.douban.com/events/future-all?start="
url=url+str(i*10)
req=urllib2.Request(url)
event=urllib2.urlopen(req)
str1=event.read()
search(str1)
在这里需要注意一下编码的问题,因为我使用的版本还是python2.X,所以在内部汉字字符串传递的时候需要来回转换,比如在最后打印“费用“这一项的时候,必须使用
i.group(4).decode('utf-8') 将group(4元组中的ASCII码转换为utf8格式才行,否则会发现输出的是乱码。
而在python中,正则模块re提供了两种常用的全局查找方式:findall 和 finditer,其中findall是一次性处理完毕,比较消耗资源;而finditer则是迭代进行搜索,个人比较推荐使用这一方法。
最后得到的结果如下,大功告成~

(二)模拟登陆图书馆系统查询书籍归还情况
既然我们能够通过python向指定网站发出请求获取信息,那么自然也能通过python模拟浏览器进行登陆等操作~
而模拟的关键,就在于我们向指定网站服务器发送的信息需要和浏览器的格式一模一样才行~
这就需要分析出我们想要登陆的那个网站接受信息的方式。通常我们需要对浏览器的信息交换进行抓包~
抓包软件中,目前比较流行的是wireshark,相当强大~不过对于我们新手来说,IE、Foxfire或者chrome自带的工具就足够我们使用了~
这里就以本人学校的图书馆系统为例子~
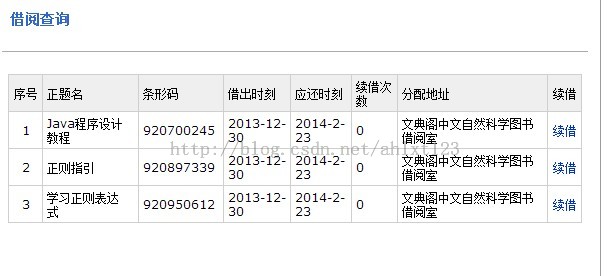
我们可以通过模拟登陆,最后进入图书管理系统查询我们借阅的图书归还情况。首先要进行抓包分析我们需要发送哪些信息才能成功模拟浏览器进行登陆操作。
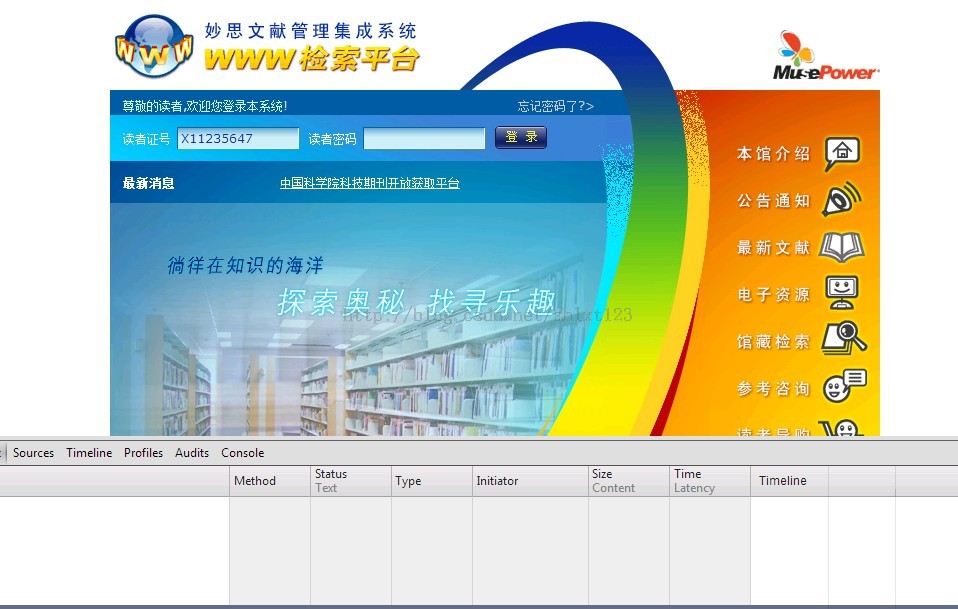
我使用的是chrome浏览器,在登陆页面按F12调出chrome自带的开发工具,选择network项就可以输入学号密码选择登陆了。
观察登陆过程中的网络活动,果然发现可疑分子了:

分析这个post指令后,可以确认其就是发送登陆信息(账号、密码等)的关键命令。
还好我们学校比较穷,网站做的一般,这个包完全没有加密~那么剩下的就很简单了~记下headers跟post data就OK了~
其中headers中有很多实用的信息,一些网站可能会根据user-Agent来判断你是否是爬虫程序从而决定是否允许你访问,而Referer则是很多网站常常用来反盗链的,如果服务器接收到的请求中referer与管理员设定的规则不符,那么服务器也会拒绝发送资源。
而post data就是我们在登录过程中浏览器向登陆服务器post的信息了,通常账户、密码之类的数据都包含在里面。这里往往还有一些其他的数据如布局等信息也要发送出去,这些信息通常我们在操作浏览器的时候没有任何存在感,但没了他们服务器是不会响应我们滴。
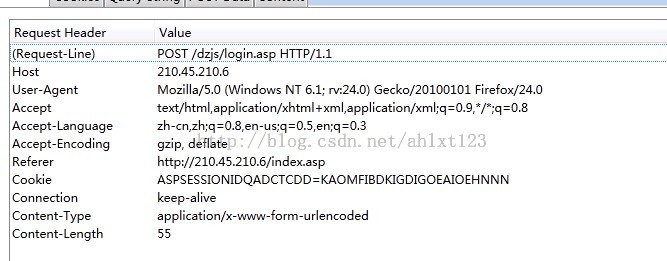
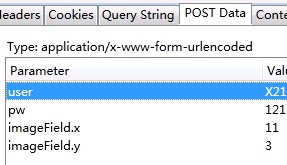
现在postdata 跟headers的格式我们全部知道了~模拟登陆就很简单了:
import urllib
#---------------------------------------
# @program:图书借阅查询
# @author:GisLu
# @data:2014-02-08
#---------------------------------------
import urllib2
import cookielib
import re
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
#登陆获取cookies
postdata=urllib.urlencode({
'user':'X1234564',
'pw':'demacialalala',
'imageField.x':'0',
'imageField.y':'0'})
rep=urllib2.Request(
url='http://210.45.210.6/dzjs/login.asp',
data=postdata
)
result=urllib2.urlopen(rep)
print result.geturl()
其中urllib.urlencode负责将postdata自动进行格式转换,而opener.addheaders则是在我们的opener处理器中为后续请求添加我们预设的headers。
测试后发现,登陆成功~~
那么剩下的就是找出图书借还查询所在页面的url,再用正则表达式提取出我们需要的信息了~~
整体代码如下:
import urllib
#---------------------------------------
# @program:图书借阅查询
# @author:GisLu
# @data:2014-02-08
#---------------------------------------
import urllib2
import cookielib
import re
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
#登陆获取cookies
postdata=urllib.urlencode({
'user':'X11134564',
'pw':'demacialalala',
'imageField.x':'0',
'imageField.y':'0'})
rep=urllib2.Request(
url='http://210.45.210.6/dzjs/login.asp',
data=postdata
)
result=urllib2.urlopen(rep)
print result.geturl()
#获取账目表
Postdata=urllib.urlencode({
'nCxfs':'1',
'submit1':'检索'})
aa=urllib2.Request(
url='http://210.45.210.6/dzjs/jhcx.asp',
data=Postdata
)
bb=urllib2.urlopen(aa)
cc=bb.read()
zhangmu=re.findall('tdborder4 >(.*?)</td>',cc)
for i in zhangmu:
i=i.decode('gb2312')
i=i.encode('gb2312')
print i.strip(' ')
下面是程序运行结果~


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
Python에서 비주얼 스튜디오 코드를 사용할 수 있습니다
Apr 15, 2025 pm 08:18 PM
VS 코드는 파이썬을 작성하는 데 사용될 수 있으며 파이썬 애플리케이션을 개발하기에 이상적인 도구가되는 많은 기능을 제공합니다. 사용자는 다음을 수행 할 수 있습니다. Python 확장 기능을 설치하여 코드 완료, 구문 강조 및 디버깅과 같은 기능을 얻습니다. 디버거를 사용하여 코드를 단계별로 추적하고 오류를 찾아 수정하십시오. 버전 제어를 위해 git을 통합합니다. 코드 서식 도구를 사용하여 코드 일관성을 유지하십시오. 라인 도구를 사용하여 잠재적 인 문제를 미리 발견하십시오.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
