

玩转python爬虫之cookie使用方法

之前一篇文章我们学习了爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用。
为什么要使用Cookie呢?
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
在此之前呢,我们必须先介绍一个opener的概念。
1.Opener
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
2.Cookielib
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的CookieJar类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
1)获取Cookie保存到变量
首先,我们先利用CookieJar对象实现获取cookie的功能,存储到变量中,先来感受一下
import urllib2
import cookielib
#声明一个CookieJar对象实例来保存cookie
cookie = cookielib.CookieJar()
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler=urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#此处的open方法同urllib2的urlopen方法,也可以传入request
response = opener.open('http://www.baidu.com')
for item in cookie:
print 'Name = '+item.name
print 'Value = '+item.value
我们使用以上方法将cookie保存到变量中,然后打印出了cookie中的值,运行结果如下
Name = BAIDUID Value = B07B663B645729F11F659C02AAE65B4C:FG=1 Name = BAIDUPSID Value = B07B663B645729F11F659C02AAE65B4C Name = H_PS_PSSID Value = 12527_11076_1438_10633 Name = BDSVRTM Value = 0 Name = BD_HOME Value = 0
2)保存Cookie到文件
在上面的方法中,我们将cookie保存到了cookie这个变量中,如果我们想将cookie保存到文件中该怎么做呢?这时,我们就要用到
FileCookieJar这个对象了,在这里我们使用它的子类MozillaCookieJar来实现Cookie的保存
import cookielib
import urllib2
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
#利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器
handler = urllib2.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib2.build_opener(handler)
#创建一个请求,原理同urllib2的urlopen
response = opener.open("http://www.baidu.com")
#保存cookie到文件
cookie.save(ignore_discard=True, ignore_expires=True)
关于最后save方法的两个参数在此说明一下:
官方解释如下:
ignore_discard: save even cookies set to be discarded.
ignore_expires: save even cookies that have expiredThe file is overwritten if it already exists
由此可见,ignore_discard的意思是即使cookies将被丢弃也将它保存下来,ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中,我们查看一下内容,附图如下
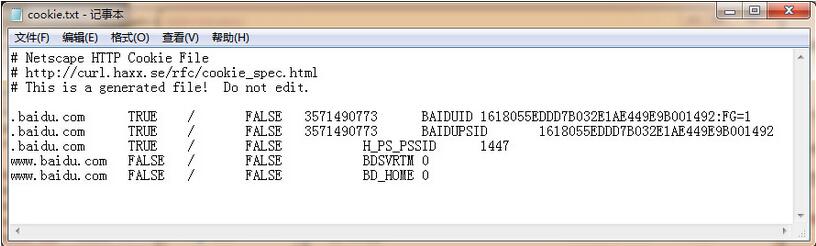
3)从文件中获取Cookie并访问
那么我们已经做到把Cookie保存到文件中了,如果以后想使用,可以利用下面的方法来读取cookie并访问网站,感受一下
import cookielib
import urllib2
#创建MozillaCookieJar实例对象
cookie = cookielib.MozillaCookieJar()
#从文件中读取cookie内容到变量
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
#创建请求的request
req = urllib2.Request("http://www.baidu.com")
#利用urllib2的build_opener方法创建一个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
response = opener.open(req)
print response.read()
设想,如果我们的 cookie.txt 文件中保存的是某个人登录百度的cookie,那么我们提取出这个cookie文件内容,就可以用以上方法模拟这个人的账号登录百度。
4)利用cookie模拟网站登录
下面我们以我们学校的教育系统为例,利用cookie实现模拟登录,并将cookie信息保存到文本文件中,来感受一下cookie大法吧!
注意:密码我改了啊,别偷偷登录本宫的选课系统 o(╯□╰)o
import urllib
import urllib2
import cookielib
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
postdata = urllib.urlencode({
'stuid':'201200131012',
'pwd':'23342321'
})
#登录教务系统的URL
loginUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login'
#模拟登录,并把cookie保存到变量
result = opener.open(loginUrl,postdata)
#保存cookie到cookie.txt中
cookie.save(ignore_discard=True, ignore_expires=True)
#利用cookie请求访问另一个网址,此网址是成绩查询网址
gradeUrl = 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre'
#请求访问成绩查询网址
result = opener.open(gradeUrl)
print result.read()
以上程序的原理如下
创建一个带有cookie的opener,在访问登录的URL时,将登录后的cookie保存下来,然后利用这个cookie来访问其他网址。
如登录之后才能查看的成绩查询呀,本学期课表呀等等网址,模拟登录就这么实现啦,是不是很酷炫?
好,小伙伴们要加油哦!我们现在可以顺利获取网站信息了,接下来就是把网站里面有效内容提取出来,下一篇文章我们去会会正则表达式!

핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

드림위버 CS6
시각적 웹 개발 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)



 PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP와 Python : 다른 패러다임이 설명되었습니다
Apr 18, 2025 am 12:26 AM
PHP는 주로 절차 적 프로그래밍이지만 객체 지향 프로그래밍 (OOP)도 지원합니다. Python은 OOP, 기능 및 절차 프로그래밍을 포함한 다양한 패러다임을 지원합니다. PHP는 웹 개발에 적합하며 Python은 데이터 분석 및 기계 학습과 같은 다양한 응용 프로그램에 적합합니다.
 PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP와 Python 중에서 선택 : 가이드
Apr 18, 2025 am 12:24 AM
PHP는 웹 개발 및 빠른 프로토 타이핑에 적합하며 Python은 데이터 과학 및 기계 학습에 적합합니다. 1.PHP는 간단한 구문과 함께 동적 웹 개발에 사용되며 빠른 개발에 적합합니다. 2. Python은 간결한 구문을 가지고 있으며 여러 분야에 적합하며 강력한 라이브러리 생태계가 있습니다.
 숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
숭고한 코드 파이썬을 실행하는 방법
Apr 16, 2025 am 08:48 AM
Sublime 텍스트로 Python 코드를 실행하려면 먼저 Python 플러그인을 설치 한 다음 .py 파일을 작성하고 코드를 작성한 다음 CTRL B를 눌러 코드를 실행하면 콘솔에 출력이 표시됩니다.
 PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP와 Python : 그들의 역사에 깊은 다이빙
Apr 18, 2025 am 12:25 AM
PHP는 1994 년에 시작되었으며 Rasmuslerdorf에 의해 개발되었습니다. 원래 웹 사이트 방문자를 추적하는 데 사용되었으며 점차 서버 측 스크립팅 언어로 진화했으며 웹 개발에 널리 사용되었습니다. Python은 1980 년대 후반 Guidovan Rossum에 의해 개발되었으며 1991 년에 처음 출시되었습니다. 코드 가독성과 단순성을 강조하며 과학 컴퓨팅, 데이터 분석 및 기타 분야에 적합합니다.
 Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript : 학습 곡선 및 사용 편의성
Apr 16, 2025 am 12:12 AM
Python은 부드러운 학습 곡선과 간결한 구문으로 초보자에게 더 적합합니다. JavaScript는 가파른 학습 곡선과 유연한 구문으로 프론트 엔드 개발에 적합합니다. 1. Python Syntax는 직관적이며 데이터 과학 및 백엔드 개발에 적합합니다. 2. JavaScript는 유연하며 프론트 엔드 및 서버 측 프로그래밍에서 널리 사용됩니다.
 Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang vs. Python : 성능 및 확장 성
Apr 19, 2025 am 12:18 AM
Golang은 성능과 확장 성 측면에서 Python보다 낫습니다. 1) Golang의 컴파일 유형 특성과 효율적인 동시성 모델은 높은 동시성 시나리오에서 잘 수행합니다. 2) 해석 된 언어로서 파이썬은 천천히 실행되지만 Cython과 같은 도구를 통해 성능을 최적화 할 수 있습니다.
 vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
vscode에서 코드를 작성하는 위치
Apr 15, 2025 pm 09:54 PM
Visual Studio Code (VSCODE)에서 코드를 작성하는 것은 간단하고 사용하기 쉽습니다. vscode를 설치하고, 프로젝트를 만들고, 언어를 선택하고, 파일을 만들고, 코드를 작성하고, 저장하고 실행합니다. VSCODE의 장점에는 크로스 플랫폼, 무료 및 오픈 소스, 강력한 기능, 풍부한 확장 및 경량 및 빠른가 포함됩니다.
 메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장으로 파이썬을 실행하는 방법
Apr 16, 2025 pm 07:33 PM
메모장에서 Python 코드를 실행하려면 Python 실행 파일 및 NPPEXEC 플러그인을 설치해야합니다. Python을 설치하고 경로를 추가 한 후 nppexec 플러그인의 명령 "Python"및 매개 변수 "{current_directory} {file_name}"을 구성하여 Notepad의 단축키 "F6"을 통해 Python 코드를 실행하십시오.
