

非常に長いシーケンス、非常に高速: 新世代の効率的な大規模言語モデルのための LASP シーケンス並列処理


AIxiv コラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
国際トップの GPT-4 128K、Claude 200K から、200 万語以上のテキスト、大規模言語モデル (LLM) をサポートする国内の「レッド フライド チキン」キミ チャットまでロングコンテキストテクノロジーが思わず巻き上がってしまう。世界で最も賢い頭脳が何かに取り組んでいるとき、その問題の重要性と困難さは自明です。
非常に長いコンテキストは、大規模モデルの生産性の価値を大幅に拡大する可能性があります。 AI の普及により、ユーザーは大規模なモデルを使って遊んだり、いくつかの頭の体操をしたりするだけでは満足できなくなり、真に生産性を向上させるために大規模なモデルを使用したいと考え始めています。結局のところ、以前は作成に 1 週間かかった PPT が、大規模なモデルに一連のプロンプト単語といくつかの参考ドキュメントを入力するだけで数分で生成できるようになりました。社会人としてこれを喜ばない人はいないでしょう。
最近、Lightning Attendant (TransNormerLLM)、State Space Modeling (Mamba)、Linear RNN (RWKV、HGRN、Griffin) などの新しい効率的なシーケンス モデリング手法が登場し、注目を集めています。研究の方向性。研究者たちは、すでに成熟した 7 年前の Transformer アーキテクチャを変革して、同等のパフォーマンスを備えながら線形の複雑さのみを備えた新しいアーキテクチャを取得することに熱心です。このタイプのアプローチはモデル アーキテクチャ設計に焦点を当てており、CUDA または Triton に基づいたハードウェア フレンドリーな実装を提供し、FlashAttendant のようなシングル カード GPU 内で効率的に計算できるようにします。
同時に、長いシーケンス トレーニングの別のコントローラーも別の戦略を採用しています。シーケンスの並列処理がますます注目を集めています。長いシーケンスをシーケンス次元で均等に分割された複数の短いシーケンスに分割し、その短いシーケンスを異なる GPU カードに分散して並列トレーニングし、カード間通信で補完することで、シーケンスの並列トレーニングの効果が達成されます。初期の Colossal-AI シーケンス並列処理から、Megatron シーケンス並列処理、DeepSpeed Ulysses、そして最近では Ring Attendance に至るまで、研究者はシーケンス並列処理のトレーニング効率を向上させるために、よりエレガントで効率的な通信メカニズムを設計し続けてきました。もちろん、これらの既知の方法はすべて、この記事ではソフトマックス アテンションと呼ぶ従来のアテンション メカニズム向けに設計されています。これらの手法はすでにさまざまな専門家によって分析されているため、この記事では詳しく説明しません。

論文タイトル: Linear Attendance Sequence Parallelism 論文アドレス: https://arxiv.org /abs/2404.02882 - ##LASP コードアドレス: https://github.com/OpenNLPLab/LASP
なお、自然言語処理手法の名称には Linear Attend というものがありますが、これに限定されるものではなく、Lightning Attendant (TransNormerLLM)、State など広く利用可能です。空間モデリング (Mamba)、線形 RNN (RWKV、HGRN、Griffin) などの線形シーケンス モデリング手法。
LASP メソッドの紹介
LASP の考え方をよりよく理解するために、まず従来の Softmax Attend の計算式を確認してみましょう: O=softmax((QK^T)⊙M)V、ここで、Q、K、V、M、と O はそれぞれクエリ、キー、値、マスク、出力行列です。ここでの M は、一方向タスク (GPT など) の下三角の all-1 行列であり、双方向タスク (BERT など) では無視できます。つまり、双方向タスクのマスク行列はありません。以下、LASP を 4 つのポイントに分けて説明します。
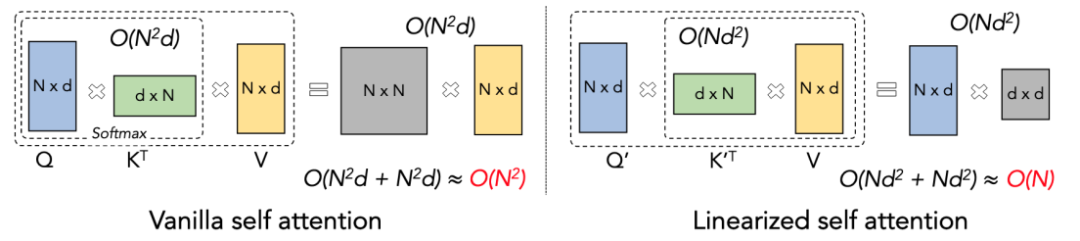
Linear Attendance Principle
Linear Attendance は、Softmax Attendance の変形とみなすことができます。 Linear Attendance は計算量の多い Softmax 演算子を削除し、Attention の計算式は O=((QK^T)⊙M) V の簡潔な形式で記述することができます。ただし、一方向タスクにマスク行列 M が存在するため、この形式でも左乗算計算しか実行できません (つまり、最初に QK^T を計算します)。そのため、線形複雑度 O (N) を取得できません。 。ただし、双方向タスクの場合はマスク行列がないため、計算式はさらに O=(QK^T) V に簡略化できます。 Linear Attendant の賢い点は、行列乗算の結合法則を使用するだけで、その計算式が O=Q (K^T V) にさらに変換できることです。この計算形式は Linear と呼ばれます。この双方向のタスクでは、O (N) の複雑さを実現できることに注目してください。
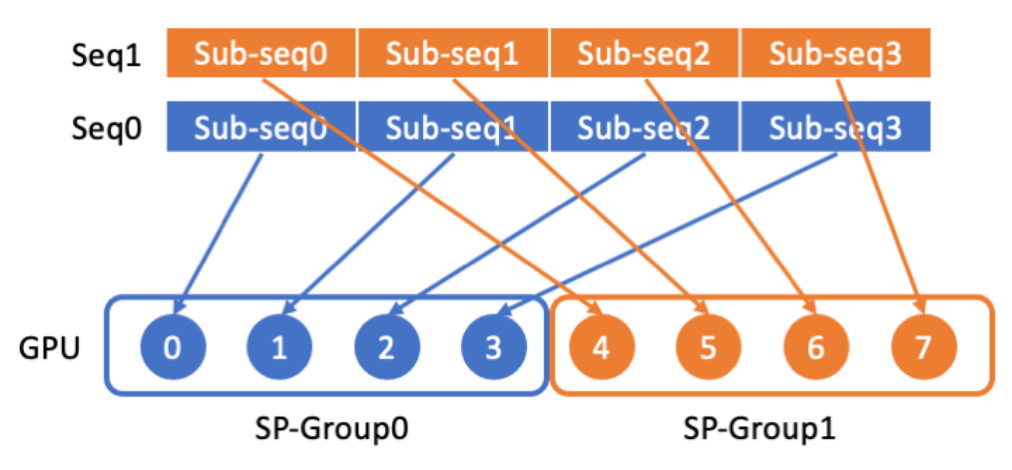
LASP データ分散
LASP はまず、長いシーケンス データをシーケンスの次元から複数の均等に分割されたサブシーケンスに分割します。次に、シーケンス並列通信グループ内のすべての GPU に分散され、各 GPU が後続のシーケンス並列計算用のサブシーケンスを持つようになります。
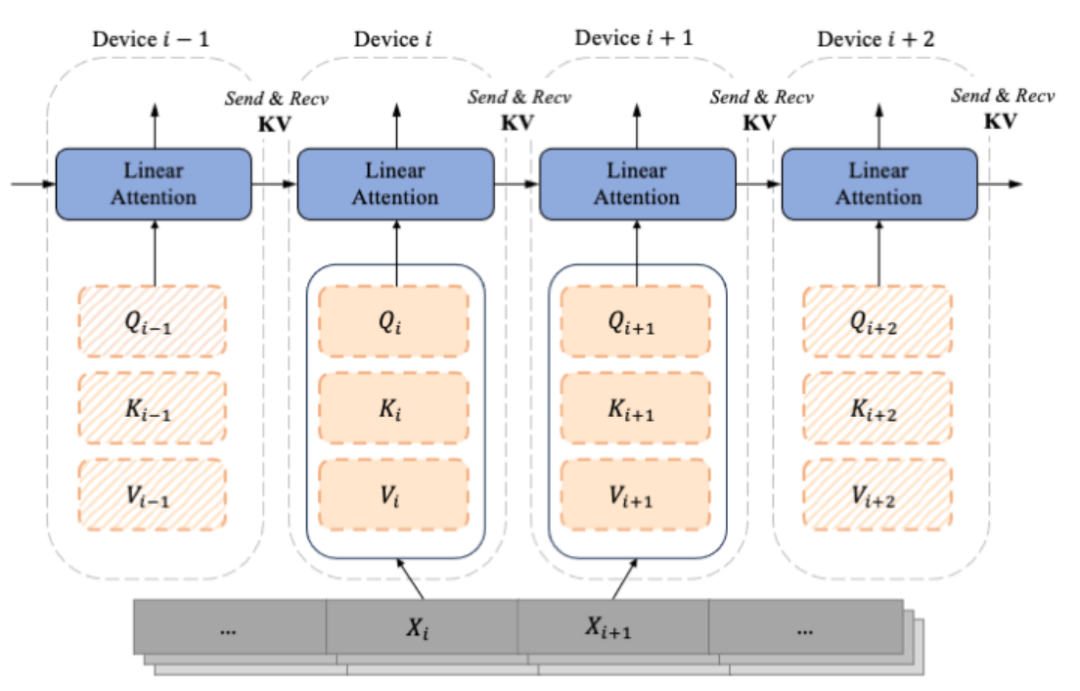
LASP コア メカニズム
デコーダのみの GPT のようなモデルが徐々に LLM の事実上の標準になるにつれて、LASP は設計は、一方通行のカジュアルなタスクのシナリオを十分に考慮しています。セグメント化されたサブシーケンス Xi から計算された、シーケンスの次元に従ってセグメント化された Qi、Ki、Vi は、チャンクとデバイス (つまり、GPU) に対応します。マスク行列の存在により、LASP 作成者は各チャンクに対応する Qi、Ki、Vi を 2 つのタイプ、つまりチャンク内とチャンク間で巧みに区別しています。このうち、イントラチャンクは、マスク行列がブロックに分割された後の対角線上のチャンクであり、マスク行列がまだ存在しており、左の乗算が依然として使用される必要があるチャンクであると考えられます。マスク行列の非対角線。マスク行列が存在すると、明らかに、より多くのチャンクが分割されると、対角線上のチャンクの割合が小さくなります。非対角上のチャンクの割合は、アテンションが計算するチャンクの数を増やすために使用できます。このうち、適切な乗算インターチャンクの計算では、前方計算中に、各デバイスはポイントツーポイント通信を使用して、前のデバイスの KV を受信し、自身の更新された KV を次のデバイスに送信する必要があります。逆に計算するとSendとReciveの対象がKVの傾きdKVになるだけで全く逆になります。順計算プロセスを次の図に示します。
LASP コードの実装
LASP の計算効率を向上させるためGPU 上で、Intra-Chunk と Inter-Chunk の計算にそれぞれ Kernel Fusion を実行し、KV と dKV の更新計算を Intra-Chunk と Inter-Chunk の計算に統合しました。さらに、バックプロパゲーション中にアクティベーション KV を再計算するのを避けるために、著者らは順伝播計算の直後にアクティベーション KV を GPU の HBM に保存することを選択しました。後続のバックプロパゲーション中に、LASP は KV に直接アクセスして使用します。 HBM に格納される KV サイズは d x d であり、シーケンス長 N の影響をまったく受けないことに注意してください。入力シーケンス長 N が長い場合、KV のメモリ フットプリントは重要ではなくなります。著者は、単一 GPU 内に Triton によって実装された Lightning Attendance を実装して、HBM と SRAM の間の IO オーバーヘッドを削減し、それによって単一カードの Linear Attendant 計算を高速化しました。
さらに詳細を知りたい読者は、論文内のアルゴリズム 2 (LASP 順方向プロセス) とアルゴリズム 3 (LASP 逆方向プロセス)、および論文内の詳細な導出プロセスを参照してください。
トラフィック分析
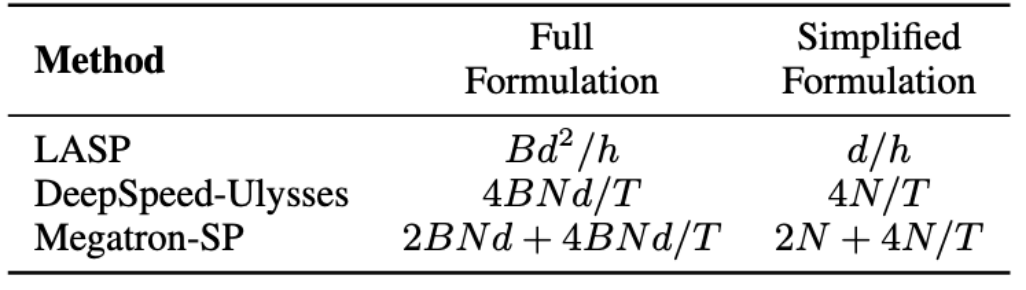
LASP アルゴリズムでは、順伝播には各 Linear Attendee モジュール層での KV アクティベーション通信が必要であることに注意してください。トラフィックは Bd^2/h です。ここで、B はバッチ サイズ、h はヘッドの数です。対照的に、Megatron-SP は、各 Transformer 層の 2 つの Layer Norm 層の後に All-Gather 操作を使用し、Attention 層と FFN 層の後に Reduce-Scatter 操作を使用します。これにより通信が行われます。数量は 2BNd 4BNd/T です。ここで、Tはシーケンスの並列次元です。 DeepSpeed-Ulysses は、All-to-All セット通信操作を使用して、各アテンション モジュール層の入力 Q、K、V および出力 O を処理し、その結果、通信量は 4BNd/T になります。 3つの通信量の比較は下表のとおりです。ここで、d/h はヘッドの寸法で、通常は 128 に設定されます。実際のアプリケーションでは、LASP は N/T>=32 のときに理論上の最低の通信量を達成できます。さらに、LASP の通信量はシーケンス長 N やサブシーケンス長 C の影響を受けないため、大規模な GPU クラスターにわたる非常に長いシーケンスの並列計算にとって大きな利点となります。
データ シーケンス ハイブリッド パラレル
データ並列処理 (つまり、バッチレベルのデータ セグメンテーション) はすでに分散トレーニングされています。 通常の操作の場合、オリジナルのデータ並列処理 (PyTorch DDP) に基づいて、スライス データ並列処理は、より多くのグラフィックス メモリを節約するために進化しました。オリジナルの DeepSpeed ZeRO シリーズから、PyTorch によって正式にサポートされる FSDP に至るまで、スライス データ並列処理は十分に成熟しており、利用するユーザーが増えています。 LASP は、シーケンス レベルのデータ セグメンテーション手法として、PyTorch DDP、Zero-1/2/3、FSDP などのさまざまなデータ並列手法と互換性があります。これは間違いなく LASP ユーザーにとって朗報です。
精度実験
TransNormerLLM (TNL) と Linear Transformer の実験結果は、システム最適化手法として LASP をさまざまな DDP バックエンドと組み合わせることができることを示しています。どちらも Baseline と同等のパフォーマンスを実現できます。
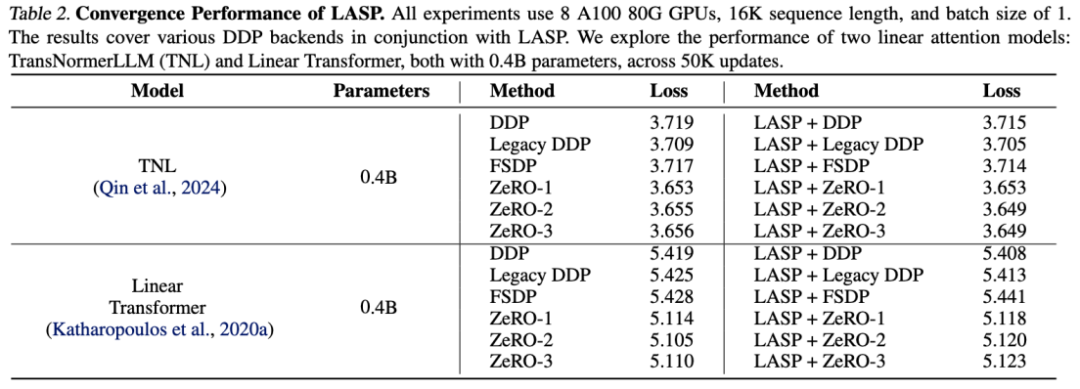
スケーラビリティの実験
効率的な通信メカニズム設計のおかげで、LASP は数百の GPU カードに簡単に拡張でき、優れた拡張性。
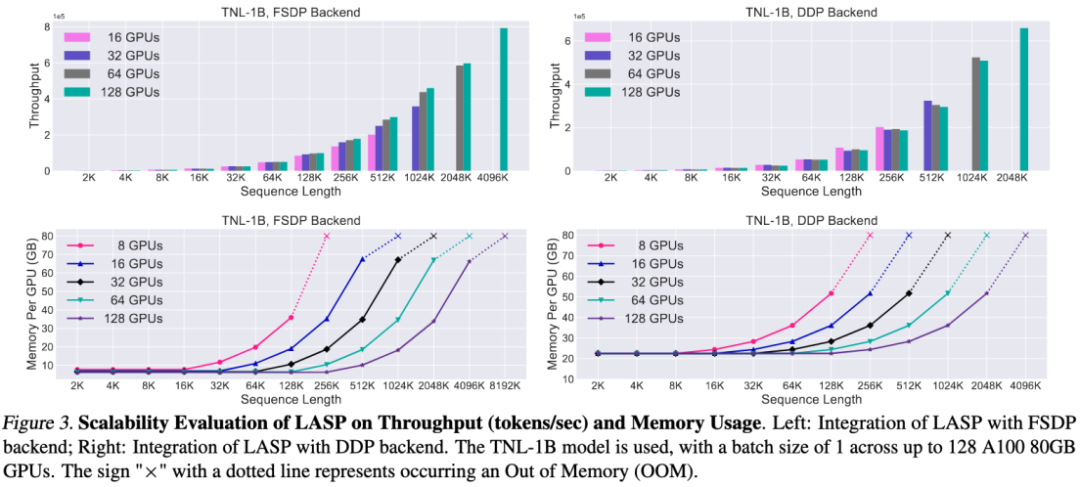
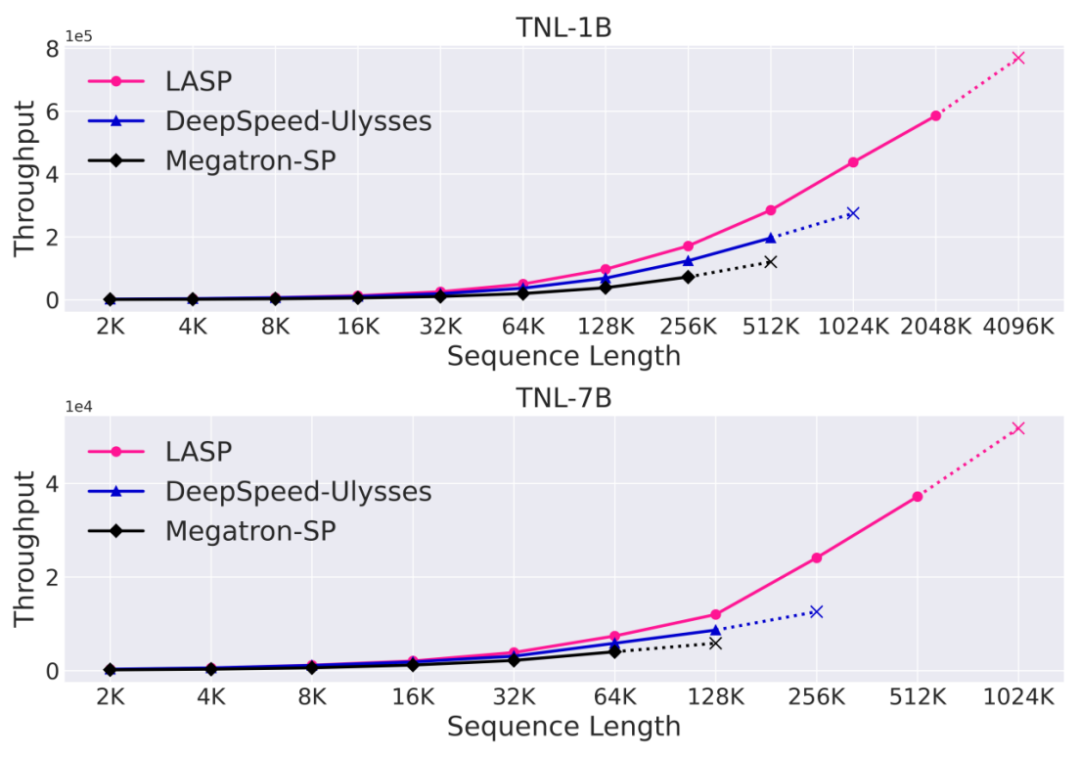
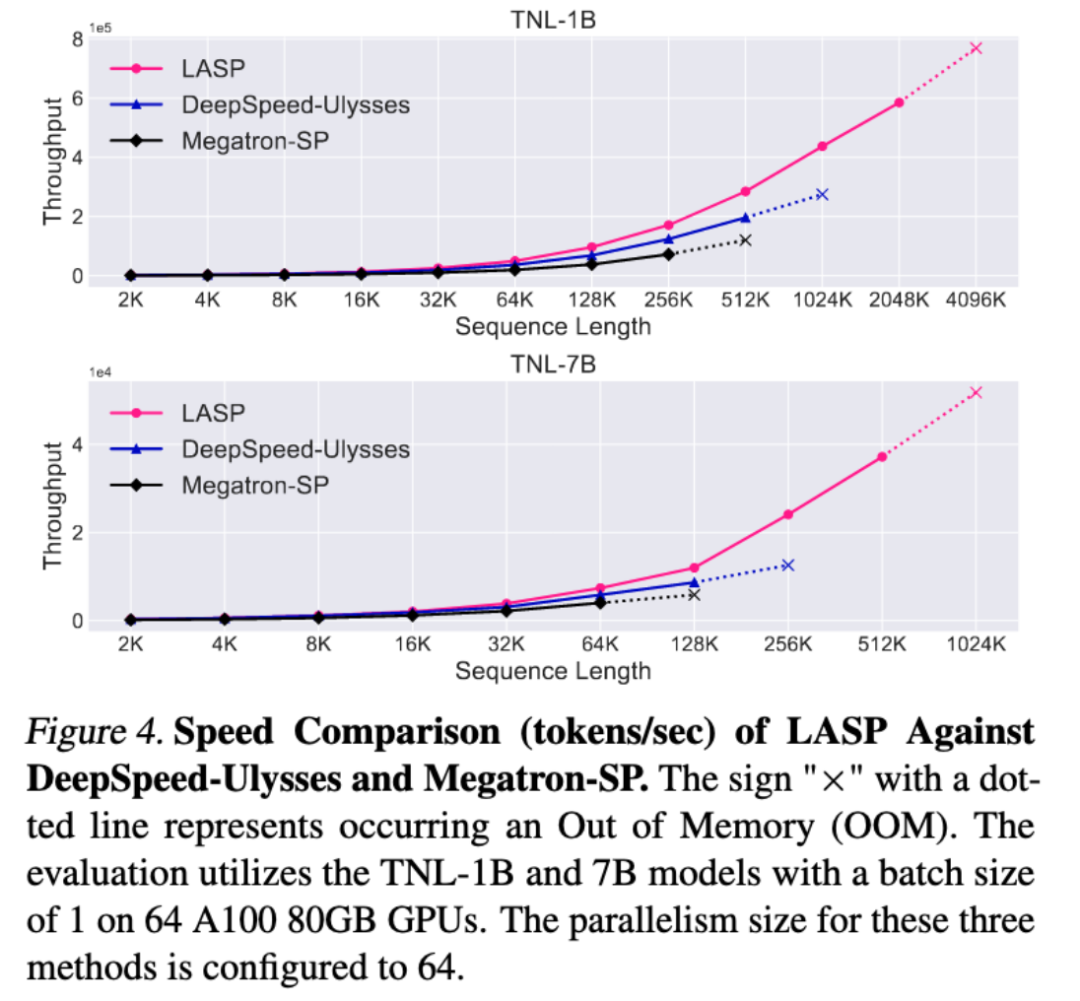
速度比較実験
成熟したシーケンス並列手法である Megatron-SP および DeepSpeed-Ulysses と比較すると、LASP は最もトレーニングしやすい 長いシーケンスの長さは Megatron-SP の 8 倍、DeepSpeed-Ulysses の 4 倍で、速度はそれぞれ 136% と 38% 高速です。
結論
試用を容易にするために、作成者は、ダウンロードせずにすぐに使用できる LASP コード実装を提供しました。データを設定してモデル化し、PyTorch を使用するだけで、LASP の非常に長くて非常に高速なシーケンス並列機能を数分で体験できます。
コードポータル: https://github.com/OpenNLPLab/LASP
以上が非常に長いシーケンス、非常に高速: 新世代の効率的な大規模言語モデルのための LASP シーケンス並列処理の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
gitを介してローカルにプロジェクトをダウンロードするには、次の手順に従ってください。gitをインストールします。プロジェクトディレクトリに移動します。次のコマンドを使用してリモートリポジトリのクローニング:git clone https://github.com/username/repository-name.git
 gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
GITコードを更新する手順:コードをチェックしてください:gitクローンhttps://github.com/username/repo.git最新の変更を取得:gitフェッチマージの変更:gitマージオリジン/マスタープッシュ変更(オプション):gitプッシュオリジンマスター
 Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
ローカルGitコードを更新する方法は? Git Fetchを使用して、リモートリポジトリから最新の変更を引き出します。 Git Merge Origin/<リモートブランチ名>を使用して、地元のブランチへのリモート変更をマージします。合併から生じる競合を解決します。 Git Commit -M "Merge Branch< Remote Branch Name>"を使用してください。マージの変更を送信し、更新を適用します。
 gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitコードマージプロセス:競合を避けるために最新の変更を引き出します。マージするブランチに切り替えます。マージを開始し、ブランチをマージするように指定します。競合のマージ(ある場合)を解決します。ステージングとコミットマージ、コミットメッセージを提供します。
 Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
解決:gitのダウンロード速度が遅い場合、次の手順を実行できます。ネットワーク接続を確認し、接続方法を切り替えてみてください。 GIT構成の最適化:ポストバッファーサイズ(Git Config -Global HTTP.Postbuffer 524288000)を増やし、低速制限(GIT Config -Global HTTP.LowsPeedLimit 1000)を減らします。 Gitプロキシ(Git-ProxyやGit-LFS-Proxyなど)を使用します。別のGitクライアント(SourcetreeやGithubデスクトップなど)を使用してみてください。防火を確認してください
 PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
eコマースのウェブサイトを開発するとき、私は困難な問題に遭遇しました:大量の製品データで効率的な検索機能を達成する方法は?従来のデータベース検索は非効率的であり、ユーザーエクスペリエンスが低いです。いくつかの調査の後、私は検索エンジンタイプセンスを発見し、公式のPHPクライアントタイプセンス/タイプセンス-PHPを通じてこの問題を解決し、検索パフォーマンスを大幅に改善しました。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 Gitのブランチを削除する方法
Apr 17, 2025 pm 04:42 PM
Gitのブランチを削除する方法
Apr 17, 2025 pm 04:42 PM
次の手順でgitブランチを削除できます。1。ローカルブランチを削除します:git branch -d< branch -name>を使用してください。指示; 2。リモートブランチを削除します:git push< remote-name>を使用します。 - デレート< branch-name>指示; 3。保護されたブランチ:Git Config Branchを使用します。 < branch-name>。保護されている保護ブランチ設定を追加するためにtrueを保護します。
