

DECO: 純粋な畳み込みクエリベースの検出器は DETR を超えています。


タイトル: DECO: ConvNets を使用したクエリベースのエンドツーエンド オブジェクト検出
論文: https://arxiv.org/pdf/2312.13735 .pdf
ソースコード: https://github.com/xinghaochen/DECO
原文: https://zhuanlan.zhihu.com/p/686011746@王云河
はじめに
# Detection Transformer (DETR) の導入後、物体検出の分野で大流行が起こり、その後の多くの研究により、精度と速度の点で元の DETR が改善されました。しかし、トランスフォーマーが視界を完全に支配できるかどうかについては議論が続いている。 ConvNeXt や RepLKNet などのいくつかの研究は、CNN 構造が視覚分野において依然として大きな可能性を秘めていることを示しています。
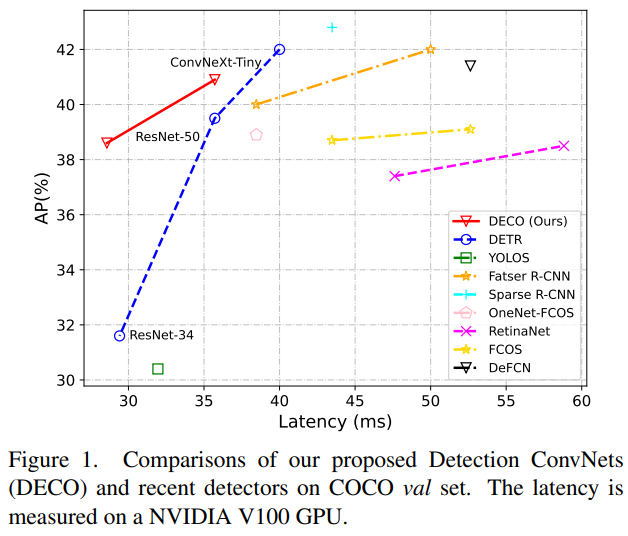
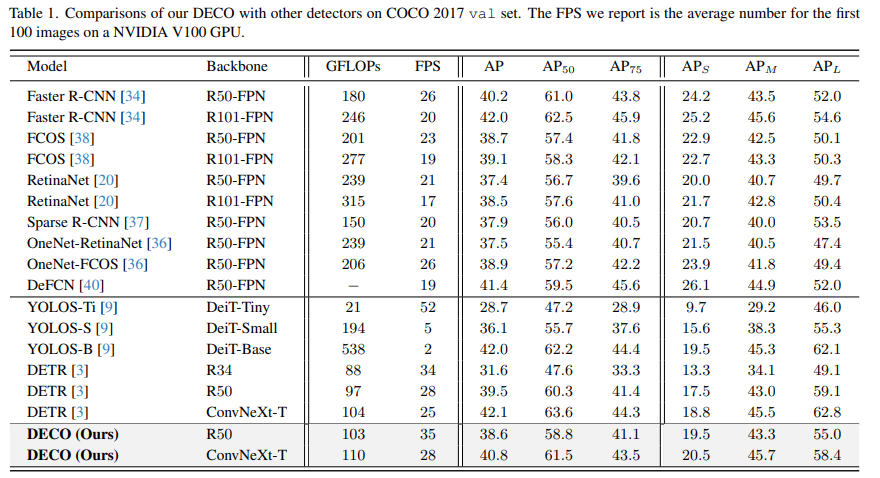
私たちの研究では、純粋な畳み込みアーキテクチャを使用して、高性能の DETR のようなフレームワーク検出器を取得する方法を検討しています。 DETR に敬意を表して、私たちはこのアプローチを DECO (Detection ConvNets) と呼びます。 DETR と同様の構造設定を使用し、異なるバックボーンを使用した DECO は、COCO で 38.6% と 40.8% の AP、V100 で 35 FPS と 28 FPS を達成し、DETR よりも優れたパフォーマンスを達成しました。 RT-DETR と同様のマルチスケール機能などのモジュールと組み合わせることで、DECO は 47.8% AP および 34 FPS の速度を達成し、全体的なパフォーマンスは多くの DETR 改善手法と比較して優れた利点をもたらしました。
手法
ネットワークアーキテクチャ
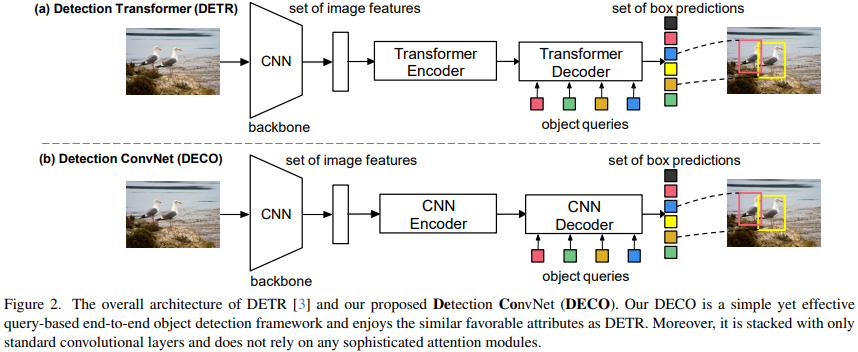
DETRの主な特徴は、Transformer Encoder-Decoderの構造を使用して入力画像を処理することです。クエリのセットは画像特徴と対話し、指定された数の検出フレームを直接出力できるため、NMS などの後処理操作への依存を排除できます。私たちが提案した DECO の全体的なアーキテクチャは DETR と似ており、画像の特徴を抽出するための Backbone、Query と対話するための Encoder-Decoder 構造、そして最終的に特定の数の検出結果を出力する機能も含まれています。唯一の違いは、DECO のエンコーダとデコーダが純粋な畳み込み構造であるため、DECO は純粋な畳み込みで構成されるクエリベースのエンドツーエンド検出器であることです。
Encoder
DETR のエンコーダ構造の置換は比較的簡単で、エンコーダ構造を形成するために 4 つの ConvNeXt ブロックを使用することにしました。具体的には、エンコーダの各層は、7x7 深さの畳み込み、LayerNorm 層、1x1 畳み込み、GELU アクティベーション関数、および別の 1x1 畳み込みを積み重ねることによって実装されます。また、DETRでは、Transformerアーキテクチャが入力に対して順列不変性を持つため、エンコーダの各層の入力に位置エンコーディングを追加する必要がありますが、畳み込みで構成されるEncoderの場合、位置エンコーディングを追加する必要はありません
Decoder
これに比べて、Decoder の置き換えははるかに複雑です。デコーダの主な機能は、画像の特徴およびクエリと完全に対話し、クエリが画像の特徴情報を完全に認識して、画像内のターゲットの座標とカテゴリを予測できるようにすることです。デコーダには主に 2 つの入力が含まれます。エンコーダの特徴出力と学習可能なクエリ ベクトル (クエリ) のセットです。 Decoder の主な構造は、Self-Interaction Module (SIM) と Cross-Interaction Module (CIM) の 2 つのモジュールに分割されます。
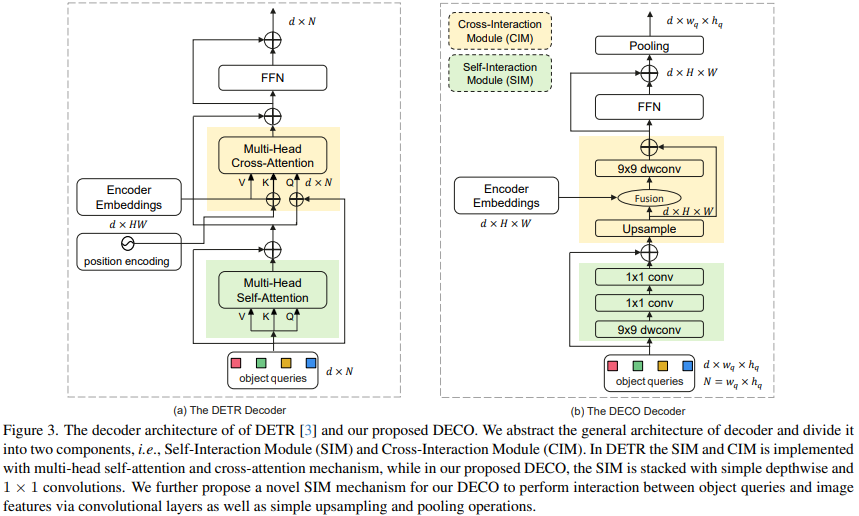
ここでは、SIM モジュールは主にクエリの出力と上位のデコーダー層を統合しています。構造のこの部分は、9x9 の深さ方向の畳み込みを使用して、いくつかの畳み込み層で構成できます。 1x1 畳み込みは、それぞれ空間次元とチャネル次元で情報の相互作用を実行し、必要なターゲット情報を完全に取得し、それを後続の CIM モジュールに送信して、ターゲット検出機能をさらに抽出します。クエリはランダムに初期化されたベクトルのセットです。この数によって、検出器が最終的に出力する検出フレームの数が決まります。その具体的な値は、実際のニーズに応じて調整できます。 DECO では、すべての構造が畳み込みで構成されているため、クエリを 2 次元に変換します (たとえば、100 個のクエリは 10x10 次元になります)。
CIM モジュールの主な機能は、画像の特徴とクエリが完全に相互作用できるようにすることで、クエリが画像の特徴情報を完全に認識して、画像内のターゲットの座標とカテゴリを予測できるようにすることです。 Transformer 構造の場合、クロス アテンション メカニズムを使用することでこの目標を達成するのは簡単ですが、畳み込み構造の場合、2 つの機能をどのように完全に相互作用させるかが最大の困難です。
SIM 出力と異なるサイズのエンコーダー出力のグローバル機能を融合するには、まず 2 つを空間的に位置合わせしてから融合する必要があります。まず、SIM 出力で最近傍アップサンプリングを実行します。

アップサンプリングされた特徴をエンコーダーによって出力されるグローバル特徴と同じサイズにし、アップサンプリングされた特徴をエンコーダーによって出力されるグローバル特徴と融合してから、特徴の深度畳み込みを入力します。インタラクション、残りの入力を追加します:
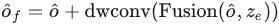
最後に、インタラクションされた特徴は FNN を介したチャネル情報インタラクションに使用され、ターゲット番号にプールされて出力埋め込みを取得します。デコーダ:
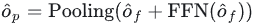
最後に、後続の分類と回帰のために出力埋め込みを検出ヘッドに送信します。
マルチスケール機能
元の DETR と同様、上記のフレームワークによって得られた DECO にも共通の欠点があります。それは、高精度に大きな影響を与えるマルチスケール機能の欠如です。ターゲット検出です。変形可能な DETR は、マルチスケールの変形可能なアテンション モジュールを使用して、さまざまなスケールの機能を統合しますが、このメソッドはアテンション オペレーターと強く結合されているため、DECO で直接使用することはできません。 DECO がマルチスケール特徴を処理できるようにするために、Decoder によって出力された特徴の後に、RT-DETR によって提案されたクロススケール特徴融合モジュールを使用します。実際、DETRの誕生以降、一連の改善手法が導き出されており、DECOにも応用できる戦略も数多くあると考えておりますので、ご興味のある方はぜひご議論いただければと思います。
実験
クエリの数やデコーダー層の数を変えるなど、主要なアーキテクチャを変更せずに、COCO で実験を行い、DECO と DETR を比較しました。 DETR の Transformer 構造と、上で説明した畳み込み構造を組み合わせます。 DECO は DETR よりも優れた精度と高速なトレードオフを実現していることがわかります。
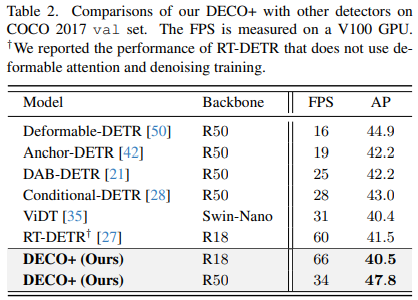
また、以下の図に示すように、DECO をマルチスケール機能と、多くの DETR バリアントを含むより多くのターゲット検出方法と比較しました。DECO が非常に優れた成果を達成していることがわかります。良好な結果が得られ、以前の多くの検出器よりも優れたパフォーマンスを達成しました。
この記事の DECO の構造は、Decoder で選択された特定の融合戦略 (加算、ドット乗算、連結) やそこへのクエリなど、多くのアブレーション実験と視覚化を経ています。また、最適な結果を達成するためのディメンションの設定方法に関する興味深い発見もいくつかあります。より詳細な結果と議論については、元の記事を参照してください。
概要
この記事は、複雑な Transformer アーキテクチャを使用せずに、クエリベースのエンドツーエンドのターゲット検出フレームワークを構築できるかどうかを検討することを目的としています。バックボーン ネットワークと畳み込みエンコーダ/デコーダ構造を含む、Detection ConvNet (DECO) と呼ばれる新しい検出フレームワークが提案されています。 DECO エンコーダを慎重に設計し、新しいメカニズムを導入することにより、DECO デコーダは畳み込み層を介してターゲット クエリと画像特徴の間の相互作用を実現できます。 COCO ベンチマークで以前の検出器との比較が行われ、DECO はシンプルさにもかかわらず、検出精度と実行速度の点で競争力のあるパフォーマンスを達成しました。具体的には、ResNet-50 および ConvNeXt-Tiny バックボーンを使用して、DECO は、それぞれ 35 FPS および 28 FPS に設定された COCO 検証セットで 38.6% と 40.8% の AP を達成し、DET モデルを上回りました。 DECO が物体検出フレームワークの設計に新しい視点を提供することが期待されています。
以上がDECO: 純粋な畳み込みクエリベースの検出器は DETR を超えています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7779
7779
 15
1644
14
1399
52
1296
25
1234
29
15
1644
14
1399
52
1296
25
1234
29

 ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップの写真を集中させる方法はたくさんあり、FlexBoxを使用する必要はありません。水平にのみ中心にする必要がある場合、テキスト中心のクラスで十分です。垂直または複数の要素を中央に配置する必要がある場合、FlexBoxまたはグリッドがより適しています。 FlexBoxは互換性が低く、複雑さを高める可能性がありますが、グリッドはより強力で、学習コストが高くなります。メソッドを選択するときは、長所と短所を比較検討し、ニーズと好みに応じて最も適切な方法を選択する必要があります。
 H5ページの生産はフロントエンド開発ですか?
Apr 05, 2025 pm 11:42 PM
H5ページの生産はフロントエンド開発ですか?
Apr 05, 2025 pm 11:42 PM
はい、H5ページの生産は、HTML、CSS、JavaScriptなどのコアテクノロジーを含むフロントエンド開発のための重要な実装方法です。開発者は、< canvas>の使用など、これらのテクノロジーを巧みに組み合わせることにより、動的で強力なH5ページを構築します。グラフィックを描画するタグまたはJavaScriptを使用して相互作用の動作を制御します。
 CSSを介してサイズ変更シンボルをカスタマイズし、背景色で均一にする方法は?
Apr 05, 2025 pm 02:30 PM
CSSを介してサイズ変更シンボルをカスタマイズし、背景色で均一にする方法は?
Apr 05, 2025 pm 02:30 PM
CSSでサイズ変更シンボルをカスタマイズする方法は、背景色で統一されています。毎日の開発では、調整など、ユーザーインターフェイスの詳細をカスタマイズする必要がある状況に遭遇することがよくあります...
 ラインブレイク後のスパンタグの間隔が小さすぎるという問題をエレガントに解決する方法は?
Apr 05, 2025 pm 06:00 PM
ラインブレイク後のスパンタグの間隔が小さすぎるという問題をエレガントに解決する方法は?
Apr 05, 2025 pm 06:00 PM
Webページレイアウトの新しいラインの後にスパンタグの間隔をエレガントに処理する方法は、複数のスパンを水平に配置する必要性に遭遇することがよくあります...
 JavaScriptまたはCSSを介してブラウザ印刷設定でページの上部と終了を制御する方法は?
Apr 05, 2025 pm 10:39 PM
JavaScriptまたはCSSを介してブラウザ印刷設定でページの上部と終了を制御する方法は?
Apr 05, 2025 pm 10:39 PM
JavaScriptまたはCSSを使用して、ブラウザの印刷設定のページの上部と端を制御する方法。ブラウザの印刷設定には、ディスプレイが...
 ブートストラップ用のコンテナに画像を集中させる方法
Apr 07, 2025 am 09:12 AM
ブートストラップ用のコンテナに画像を集中させる方法
Apr 07, 2025 am 09:12 AM
概要:ブートストラップを使用して画像を中心にする方法はたくさんあります。基本方法:MX-Autoクラスを使用して、水平に中央に配置します。 IMG-Fluidクラスを使用して、親コンテナに適応します。 Dブロッククラスを使用して、画像をブロックレベルの要素(垂直センタリング)に設定します。高度な方法:FlexBoxレイアウト:Justify-Content-CenterおよびAlign-Items-Centerプロパティを使用します。グリッドレイアウト:Place-Items:Centerプロパティを使用します。ベストプラクティス:不必要なネスティングやスタイルを避けてください。プロジェクトに最適な方法を選択してください。コードの維持可能性に注意を払い、興奮を追求するためにコードの品質を犠牲にしないでください
 モバイルターミナルでのマルチラインオーバーフローの省略と互換性のある方法は?
Apr 05, 2025 pm 10:36 PM
モバイルターミナルでのマルチラインオーバーフローの省略と互換性のある方法は?
Apr 05, 2025 pm 10:36 PM
VUE 2.0を使用してモバイルアプリケーションを開発する際に、さまざまなデバイスで省略されたモバイル端末のマルチローオーバーフローの互換性の問題は、テキストをオーバーフローする必要性に遭遇することがよくあります...
 フレックスレイアウトの下のテキストは省略されていますが、コンテナは開かれていますか?それを解決する方法は?
Apr 05, 2025 pm 11:00 PM
フレックスレイアウトの下のテキストは省略されていますが、コンテナは開かれていますか?それを解決する方法は?
Apr 05, 2025 pm 11:00 PM
フレックスレイアウトとソリューションの下でのテキストの過度の省略によるコンテナの開口部の問題が使用されます...
