

myql5.7.7优化配置参数_MySQL

# Other default tuning values # MySQL Server Instance Configuration File # ---------------------------------------------------------------------- # Generated by the MySQL Server Instance Configuration Wizard # # # Installation Instructions # ---------------------------------------------------------------------- # # On Linux you can copy this file to /etc/my.cnf to set global options, # mysql-data-dir/my.cnf to set server-specific options # ( for this installation) or to # ~/.my.cnf to set user-specific options. # # On Windows you should keep this file in the installation directory # of your server (e.g. C:\Program Files\MySQL\MySQL Server X.Y). To # make sure the server reads the config file use the startup option # "--defaults-file". # # To run run the server from the command line, execute this in a # command line shell, e.g. # mysqld --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini" # # To install the server as a Windows service manually, execute this in a # command line shell, e.g. # mysqld --install MySQLXY --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini" # # And then execute this in a command line shell to start the server, e.g. # net start MySQLXY # # # Guildlines for editing this file # ---------------------------------------------------------------------- # # In this file, you can use all long options that the program supports. # If you want to know the options a program supports, start the program # with the "--help" option. # # More detailed information about the individual options can also be # found in the manual. # # For advice on how to change settings please see # http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html # # # CLIENT SECTION # ---------------------------------------------------------------------- # # The following options will be read by MySQL client applications. # Note that only client applications shipped by MySQL are guaranteed # to read this section. If you want your own MySQL client program to # honor these values, you need to specify it as an option during the # MySQL client library initialization. # [client] no-beep # pipe # socket=0.0 port=3306 [mysql] default-character-set=utf8 # SERVER SECTION # ---------------------------------------------------------------------- # # The following options will be read by the MySQL Server. Make sure that # you have installed the server correctly (see above) so it reads this # file. # # server_type=3 [mysqld] # The next three options are mutually exclusive to SERVER_PORT below. # skip-networking # enable-named-pipe # shared-memory # shared-memory-base-name=MYSQL # The Pipe the MySQL Server will use # socket=MYSQL # The TCP/IP Port the MySQL Server will listen on port=3306 # Path to installation directory. All paths are usually resolved relative to this. # basedir="C:/Program Files/MySQL/MySQL Server 5.7/" basedir = "C:\ProgramData\MySQL\MySQL Server 5.7" # Path to the database root datadir="C:\ProgramData\MySQL\MySQL Server 5.7\Data" tmpdir = "C:\ProgramData\MySQL\MySQL Server 5.7\Data" socket = "C:\ProgramData\MySQL\MySQL Server 5.7\Data\mysql.sock" # The default character set that will be used when a new schema or table is # created and no character set is defined character-set-server=utf8 # The default storage engine that will be used when create new tables when default-storage-engine=INNODB explicit_defaults_for_timestamp = true # Set the SQL mode to strict sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" # Enable Windows Authentication # plugin-load=authentication_windows.dll # General and Slow logging. log-output=FILE general-log=1 general_log_file="MS-20150605JTJQ.log" slow-query-log=1 slow_query_log_file="MS-20150605JTJQ-slow.log" long_query_time=10 # Binary Logging. log-bin="MS-20150605JTJQ-bin" # Error Logging. log-error="MS-20150605JTJQ.err" # Server Id. server-id=1 # The maximum amount of concurrent sessions the MySQL server will # allow. One of these connections will be reserved for a user with # SUPER privileges to allow the administrator to login even if the # connection limit has been reached. max_connections=2000 # Query cache is used to cache SELECT results and later return them # without actual executing the same query once again. Having the query # cache enabled may result in significant speed improvements, if your # have a lot of identical queries and rarely changing tables. See the # "Qcache_lowmem_prunes" status variable to check if the current value # is high enough for your load. # Note: In case your tables change very often or if your queries are # textually different every time, the query cache may result in a # slowdown instead of a performance improvement. query_cache_size=0 # The number of open tables for all threads. Increasing this value # increases the number of file descriptors that mysqld requires. # Therefore you have to make sure to set the amount of open files # allowed to at least 4096 in the variable "open-files-limit" in # section [mysqld_safe] table_open_cache=2000 # Maximum size for internal (in-memory) temporary tables. If a table # grows larger than this value, it is automatically converted to disk # based table This limitation is for a single table. There can be many # of them. tmp_table_size=246M # How many threads we should keep in a cache for reuse. When a client # disconnects, the client's threads are put in the cache if there aren't # more than thread_cache_size threads from before. This greatly reduces # the amount of thread creations needed if you have a lot of new # connections. (Normally this doesn't give a notable performance # improvement if you have a good thread implementation.) thread_cache_size=300 #限定用于每个数据库线程的栈大小。默认设置足以满足大多数应用 thread_stack = 192k #*** MyISAM Specific options # The maximum size of the temporary file MySQL is allowed to use while # recreating the index (during REPAIR, ALTER TABLE or LOAD DATA INFILE. # If the file-size would be bigger than this, the index will be created # through the key cache (which is slower). #myisam_max_sort_file_size=100G # If the temporary file used for fast index creation would be bigger # than using the key cache by the amount specified here, then prefer the # key cache method. This is mainly used to force long character keys in # large tables to use the slower key cache method to create the index. #myisam_sort_buffer_size=37M # Size of the Key Buffer, used to cache index blocks for MyISAM tables. # Do not set it larger than 30% of your available memory, as some memory # is also required by the OS to cache rows. Even if you're not using # MyISAM tables, you should still set it to 8-64M as it will also be # used for internal temporary disk tables. key_buffer_size=512M # Size of the buffer used for doing full table scans of MyISAM tables. # Allocated per thread, if a full scan is needed. read_buffer_size=4M read_rnd_buffer_size=32M #*** INNODB Specific options *** # innodb_data_home_dir=0.0 # Use this option if you have a MySQL server with InnoDB support enabled # but you do not plan to use it. This will save memory and disk space # and speed up some things. # skip-innodb innodb_data_home_dir = "C:\ProgramData\MySQL\MySQL Server 5.7\Data\" # If set to 1, InnoDB will flush (fsync) the transaction logs to the # disk at each commit, which offers full ACID behavior. If you are # willing to compromise this safety, and you are running small # transactions, you may set this to 0 or 2 to reduce disk I/O to the # logs. Value 0 means that the log is only written to the log file and # the log file flushed to disk approximately once per second. Value 2 # means the log is written to the log file at each commit, but the log # file is only flushed to disk approximately once per second. innodb_flush_log_at_trx_commit=0 # The size of the buffer InnoDB uses for buffering log data. As soon as # it is full, InnoDB will have to flush it to disk. As it is flushed # once per second anyway, it does not make sense to have it very large # (even with long transactions). innodb_log_buffer_size=16M # InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and # row data. The bigger you set this the less disk I/O is needed to # access data in tables. On a dedicated database server you may set this # parameter up to 80% of the machine physical memory size. Do not set it # too large, though, because competition of the physical memory may # cause paging in the operating system. Note that on 32bit systems you # might be limited to 2-3.5G of user level memory per process, so do not # set it too high. innodb_buffer_pool_size=256M # Size of each log file in a log group. You should set the combined size # of log files to about 25%-100% of your buffer pool size to avoid # unneeded buffer pool flush activity on log file overwrite. However, # note that a larger logfile size will increase the time needed for the # recovery process. innodb_log_file_size=128M # Number of threads allowed inside the InnoDB kernel. The optimal value # depends highly on the application, hardware as well as the OS # scheduler properties. A too high value may lead to thread thrashing. innodb_thread_concurrency=128 # The increment size (in MB) for extending the size of an auto-extend InnoDB system tablespace file when it becomes full. innodb_autoextend_increment=1000 # The number of regions that the InnoDB buffer pool is divided into. # For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency, # by reducing contention as different threads read and write to cached pages. innodb_buffer_pool_instances=8 # Determines the number of threads that can enter InnoDB concurrently. innodb_concurrency_tickets=5000 # Specifies how long in milliseconds (ms) a block inserted into the old sublist must stay there after its first access before # it can be moved to the new sublist. innodb_old_blocks_time=1000 # It specifies the maximum number of .ibd files that MySQL can keep open at one time. The minimum value is 10. innodb_open_files=300 # When this variable is enabled, InnoDB updates statistics during metadata statements. innodb_stats_on_metadata=0 # When innodb_file_per_table is enabled (the default in 5.6.6 and higher), InnoDB stores the data and indexes for each newly created table # in a separate .ibd file, rather than in the system tablespace. innodb_file_per_table=1 # Use the following list of values: 0 for crc32, 1 for strict_crc32, 2 for innodb, 3 for strict_innodb, 4 for none, 5 for strict_none. innodb_checksum_algorithm=0 # The number of outstanding connection requests MySQL can have. # This option is useful when the main MySQL thread gets many connection requests in a very short time. # It then takes some time (although very little) for the main thread to check the connection and start a new thread. # The back_log value indicates how many requests can be stacked during this short time before MySQL momentarily # stops answering new requests. # You need to increase this only if you expect a large number of connections in a short period of time. back_log=80 # If this is set to a nonzero value, all tables are closed every flush_time seconds to free up resources and # synchronize unflushed data to disk. # This option is best used only on systems with minimal resources. flush_time=0 # The minimum size of the buffer that is used for plain index scans, range index scans, and joins that do not use # indexes and thus perform full table scans. join_buffer_size=128M # The maximum size of one packet or any generated or intermediate string, or any parameter sent by the # mysql_stmt_send_long_data() C API function. max_allowed_packet=1024M # If more than this many successive connection requests from a host are interrupted without a successful connection, # the server blocks that host from performing further connections. max_connect_errors=2000 # Changes the number of file descriptors available to mysqld. # You should try increasing the value of this option if mysqld gives you the error "Too many open files". open_files_limit=4161 # Set the query cache type. 0 for OFF, 1 for ON and 2 for DEMAND. query_cache_type=0 # If you see many sort_merge_passes per second in SHOW GLOBAL STATUS output, you can consider increasing the # sort_buffer_size value to speed up ORDER BY or GROUP BY operations that cannot be improved with query optimization # or improved indexing. sort_buffer_size=32M # The number of table definitions (from .frm files) that can be stored in the definition cache. # If you use a large number of tables, you can create a large table definition cache to speed up opening of tables. # The table definition cache takes less space and does not use file descriptors, unlike the normal table cache. # The minimum and default values are both 400. table_definition_cache=1400 # Specify the maximum size of a row-based binary log event, in bytes. # Rows are grouped into events smaller than this size if possible. The value should be a multiple of 256. binlog_row_event_max_size=8K # If the value of this variable is greater than 0, a replication slave synchronizes its master.info file to disk. # (using fdatasync()) after every sync_master_info events. sync_master_info=10000 # If the value of this variable is greater than 0, the MySQL server synchronizes its relay log to disk. # (using fdatasync()) after every sync_relay_log writes to the relay log. sync_relay_log=10000 # If the value of this variable is greater than 0, a replication slave synchronizes its relay-log.info file to disk. # (using fdatasync()) after every sync_relay_log_info transactions. sync_relay_log_info=10000 #批量插入数据缓存大小,可以有效提高插入效率,默认为8M bulk_insert_buffer_size = 64M interactive_timeout = 120 wait_timeout = 120 log-bin-trust-function-creators=1

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1245
24
14
1423
52
1317
25
1268
29
1245
24

 PHP バージョン 5.4 の新機能: 呼び出し可能な型ヒント パラメーターを使用して呼び出し可能な関数またはメソッドを受け入れる方法
Jul 29, 2023 pm 09:19 PM
PHP バージョン 5.4 の新機能: 呼び出し可能な型ヒント パラメーターを使用して呼び出し可能な関数またはメソッドを受け入れる方法
Jul 29, 2023 pm 09:19 PM
PHP5.4 バージョンの新機能: 呼び出し可能な型ヒント パラメーターを使用して呼び出し可能な関数またはメソッドを受け入れる方法 はじめに: PHP5.4 バージョンでは、非常に便利な新機能が導入されています。呼び出し可能な型ヒント パラメーターを使用して、呼び出し可能な関数またはメソッドを受け入れることができます。この新機能により、追加のチェックや変換を行わずに、関数やメソッドで対応する呼び出し可能なパラメーターを直接指定できるようになります。この記事では、呼び出し可能な型ヒントの使用法を紹介し、いくつかのコード例を示します。
 製品パラメータとは何を意味しますか?
Jul 05, 2023 am 11:13 AM
製品パラメータとは何を意味しますか?
Jul 05, 2023 am 11:13 AM
製品パラメータは、製品属性の意味を指します。たとえば、衣類のパラメータには、ブランド、素材、モデル、サイズ、スタイル、生地、適用グループ、色などが含まれ、食品のパラメータには、ブランド、重量、素材、保健免許番号、適用グループ、色などが含まれ、家電のパラメータには、家電製品のパラメータが含まれます。ブランド、サイズ、色、原産地、適用可能な電圧、信号、インターフェース、電力などが含まれます。
 C++ 関数パラメータの型の安全性チェック
Apr 19, 2024 pm 12:00 PM
C++ 関数パラメータの型の安全性チェック
Apr 19, 2024 pm 12:00 PM
C++ パラメーターの型の安全性チェックでは、コンパイル時チェック、実行時チェック、静的アサーションを通じて関数が予期される型の値のみを受け入れるようにし、予期しない動作やプログラムのクラッシュを防ぎます。 コンパイル時の型チェック: コンパイラは型の互換性をチェックします。実行時の型チェック:dynamic_cast を使用して型の互換性をチェックし、一致しない場合は例外をスローします。静的アサーション: コンパイル時に型条件をアサートします。
 PHP 警告: in_array() に対する解決策にはパラメーターが必要です
Jun 22, 2023 pm 11:52 PM
PHP 警告: in_array() に対する解決策にはパラメーターが必要です
Jun 22, 2023 pm 11:52 PM
開発プロセス中に、次のようなエラー メッセージが表示される場合があります: PHPWarning: in_array()expectsparameter。このエラー メッセージは、in_array() 関数を使用するときに表示されます。関数のパラメータの受け渡しが正しくないことが原因である可能性があります。このエラー メッセージの解決策を見てみましょう。まず、in_array() 関数の役割を明確にする必要があります。配列に値が存在するかどうかを確認します。この関数のプロトタイプは次のとおりです: in_a
 指定された値を引数として受け取る逆双曲線正弦関数の値を見つける C++ プログラム
Sep 17, 2023 am 10:49 AM
指定された値を引数として受け取る逆双曲線正弦関数の値を見つける C++ プログラム
Sep 17, 2023 am 10:49 AM
双曲線関数は、円の代わりに双曲線を使用して定義され、通常の三角関数と同等です。ラジアン単位で指定された角度から双曲線正弦関数の比率パラメーターを返します。しかし、その逆、つまり別の言い方をすればいいのです。双曲線正弦から角度を計算したい場合は、双曲線逆正弦演算のような逆双曲線三角関数演算が必要です。このコースでは、C++ で双曲線逆サイン (asinh) 関数を使用し、ラジアン単位の双曲線サイン値を使用して角度を計算する方法を説明します。双曲線逆正弦演算は次の式に従います -$$\mathrm{sinh^{-1}x\:=\:In(x\:+\:\sqrt{x^2\:+\:1})}ここで\:In\:is\:自然対数\:(log_e\:k)
 i9-12900Hパラメータ評価リスト
Feb 23, 2024 am 09:25 AM
i9-12900Hパラメータ評価リスト
Feb 23, 2024 am 09:25 AM
i9-12900H は 14 コア プロセッサです。使用されているアーキテクチャとテクノロジはすべて新しく、スレッドも非常に高速です。全体的な動作は優れており、いくつかのパラメータが改善されています。特に包括的で、ユーザーに優れたエクスペリエンスをもたらします。 。 i9-12900H パラメータ評価レビュー: 1. i9-12900H は、q1 アーキテクチャと 24576kb プロセス テクノロジを採用した 14 コア プロセッサで、20 スレッドにアップグレードされています。 2. 最大 CPU 周波数は 1.80! 5.00 ghz で、主にワークロードによって異なります。 3. 価格と比較すると、非常に適しており、価格性能比が非常に優れており、通常の使用が必要な一部のパートナーに非常に適しています。 i9-12900H のパラメータ評価とパフォーマンスの実行スコア
 100億個のパラメータを持つ言語モデルは実行できないのでしょうか? MIT の中国人医師が SmoothQuant 定量化を提案しました。これにより、メモリ要件が半分に減り、速度が 1.56 倍向上しました。
Apr 13, 2023 am 09:31 AM
100億個のパラメータを持つ言語モデルは実行できないのでしょうか? MIT の中国人医師が SmoothQuant 定量化を提案しました。これにより、メモリ要件が半分に減り、速度が 1.56 倍向上しました。
Apr 13, 2023 am 09:31 AM
大規模言語モデル (LLM) は優れたパフォーマンスを持っていますが、パラメーターの数は簡単に数千億に達する可能性があり、コンピューティング機器とメモリの需要が非常に大きいため、一般の企業にはそれを買う余裕がありません。量子化は一般的な圧縮操作であり、モデルの重みの精度を下げる (32 ビットから 8 ビットなど) ことにより、推論速度の高速化とメモリ要件の削減と引き換えにモデルのパフォーマンスの一部を犠牲にします。しかし、1,000 億を超えるパラメータを持つ LLM の場合、既存の圧縮方法ではモデルの精度を維持できず、ハードウェア上で効率的に実行することもできません。最近、MIT と NVIDIA の研究者が共同で、汎用のポストトレーニング量子化 (GPQ) を提案しました。
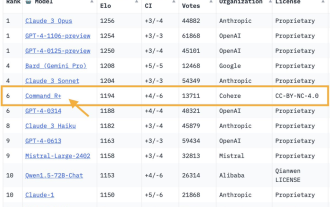 オープンソースモデルが初めてGPT-4を獲得!アリーナの最新戦闘レポートは白熱した議論を巻き起こしている、カルパシー: これが私が信頼する唯一のリストだ
Apr 10, 2024 pm 03:16 PM
オープンソースモデルが初めてGPT-4を獲得!アリーナの最新戦闘レポートは白熱した議論を巻き起こしている、カルパシー: これが私が信頼する唯一のリストだ
Apr 10, 2024 pm 03:16 PM
GPT-4を超えるオープンソースモデルが登場!大型モデル分野の最新バトルレポート: 1,040 億パラメータのオープンソース モデル CommandR+ が 6 位に上昇し、GPT-4-0314 と同点となり、GPT-4-0613 を上回りました。画像 これは、大型モデルの分野で GPT-4 を破った初の無差別重量モデルでもあります。大規模なモデル アリーナは、マスター Karpathy が信頼する唯一のテスト ベンチマークの 1 つです。 AI unicorn Cohere の CommandR+ の画像。この大規模モデルのスタートアップの共同創設者兼 CEO は、『トランスフォーマー』 (小麦収穫者と呼ばれる) の最年少著者、エイダン ゴメスにほかなりません。このバトルレポートが出るやいなや、ビッグモデルクラブの新たな波が始まった
