Python組み込み型strソースコード解析

1 Unicode
コンピュータ ストレージの基本単位は 8 ビットで構成されるバイトです。英語は 26 文字といくつかの記号のみで構成されているため、英語の文字はバイト単位で直接格納できます。ただし、他の言語 (中国語、日本語、韓国語など) では、文字数が多いため、エンコードに複数のバイトを使用する必要があります。
コンピューター技術の普及に伴い、非ラテン文字エンコーディング技術は発展を続けていますが、依然として 2 つの大きな制限があります。
複数の言語をサポートしていません。ある言語のエンコード スキームを別の言語に使用することはできません
統一された標準はありません。たとえば、中国語には GBK、GB2312、GB18030
などの複数のエンコード標準があります。
エンコード方式が統一されていないため、開発者は異なるエンコード間で変換を行ったり来たりする必要があり、必然的に多くのエラーが発生します。このような不一致の問題を解決するために、Unicode 標準が提案されました。 Unicode は、世界中のほとんどの書記体系を整理してエンコードし、コンピュータが統一された方法でテキストを処理できるようにします。 Unicode には現在 140,000 文字以上が含まれており、当然ながら複数の言語をサポートしています。 (Unicode の uni は「unification」の語源です)
2 Python における Unicode
2.1 Unicode オブジェクトの利点
Python 3 以降、Unicode は str オブジェクトの内部で使用されます。を表すため、ソース コードでは Unicode オブジェクトになります。 Unicode 表現を使用する利点は、プログラムのコア ロジックが Unicode を均一に使用し、入力層と出力層でのみデコードおよびエンコードする必要があるため、さまざまなエンコードの問題を最大限に回避できることです。
図は次のとおりです:

>>> sys.getsizeof('ab') - sys.getsizeof('a') 1 >>> sys.getsizeof('一二') - sys.getsizeof('一') 2 >>> sys.getsizeof('????????') - sys.getsizeof('????') 4
- PyUnicode_1BYTE_KIND: すべての文字コード ポイントは U 0000 の間にあります。および U 00FF
- PyUnicode_2BYTE_KIND: すべての文字コード ポイントが U 0000 から U FFFF の間にあり、少なくとも 1 つの文字のコード ポイントが U 00FF## より大きい #PyUnicode_1BYTE_KIND: すべての文字コード ポイントは U 0000 ~ U 10FFFF であり、少なくとも 1 つの文字のコード ポイントが U FFFF
- ##対応する列挙は次のとおりです。 ##
enum PyUnicode_Kind { /* String contains only wstr byte characters. This is only possible when the string was created with a legacy API and _PyUnicode_Ready() has not been called yet. */ PyUnicode_WCHAR_KIND = 0, /* Return values of the PyUnicode_KIND() macro: */ PyUnicode_1BYTE_KIND = 1, PyUnicode_2BYTE_KIND = 2, PyUnicode_4BYTE_KIND = 4 };ログイン後にコピーさまざまな分類に従って、さまざまなストレージ ユニットを選択します:
/* Py_UCS4 and Py_UCS2 are typedefs for the respective unicode representations. */ typedef uint32_t Py_UCS4; typedef uint16_t Py_UCS2; typedef uint8_t Py_UCS1;
対応する関係は次のとおりです:
テキスト タイプ| 文字ストレージ ユニット サイズ (バイト) | PyUnicode_1BYTE_KIND | |
|---|---|---|
| 1 | ##PyUnicode_2BYTE_KIND | |
| 2 | PyUnicode_4BYTE_KIND | |
| 4 | Unicode の内部ストレージ構造はテキスト タイプによって異なるため、タイプの種類は Unicode オブジェクトのパブリック フィールドとして保存する必要があります。 Python は内部的にいくつかのフラグ ビットを Unicode パブリック フィールドとして定義します: (作成者のレベルが限られているため、ここにあるすべてのフィールドは後続のコンテンツでは紹介されません。これについては後ほど自分で学ぶことができます。頑張ってください~) |
interned: interned メカニズムを維持するかどうか
kind: type、基礎となる文字の記憶単位のサイズを区別するために使用されます
compact: メモリ割り当て方法、オブジェクトとテキスト バッファーが分離されているかどうか
asscii: テキストがすべて純粋な ASCII かどうか
-
PyUnicode_New 関数を通じて、テキスト文字数のサイズと最大文字数に従って、maxchar が Unicode オブジェクトを初期化します。この関数は主に、maxchar に基づいて最もコンパクトな文字格納ユニットと Unicode オブジェクトの基礎となる構造を選択します。 (ソース コードは比較的長いため、ここには記載しません。ご自身で理解してください。以下の表形式で示します) )
| 128 <= maxchar < 256 | 256 <= maxchar < 65536 | 65536 <= maxchar < MAX_UNICODE | ||
|---|---|---|---|---|
| PyUnicode_1BYTE_KIND | PyUnicode_2BYTE_KIND | PyUnicode_4BYTE_KIND | ascii | |
| 0 | 0 | 0 | 文字格納単位サイズ (バイト) | |
| 1 | 2 | 4 | 基礎構造 | |
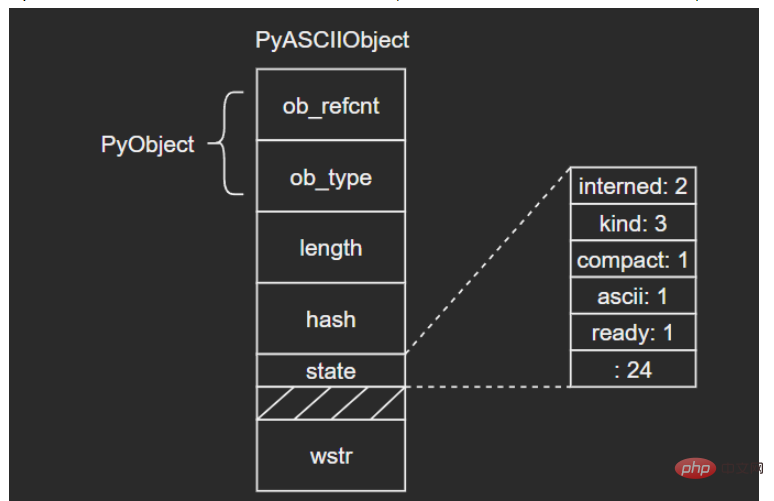
| PyCompactUnicodeObject | PyCompactUnicodeObject | PyCompactUnicodeObject | 3 Unicode对象的底层结构体3.1 PyASCIIObjectC源码: typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
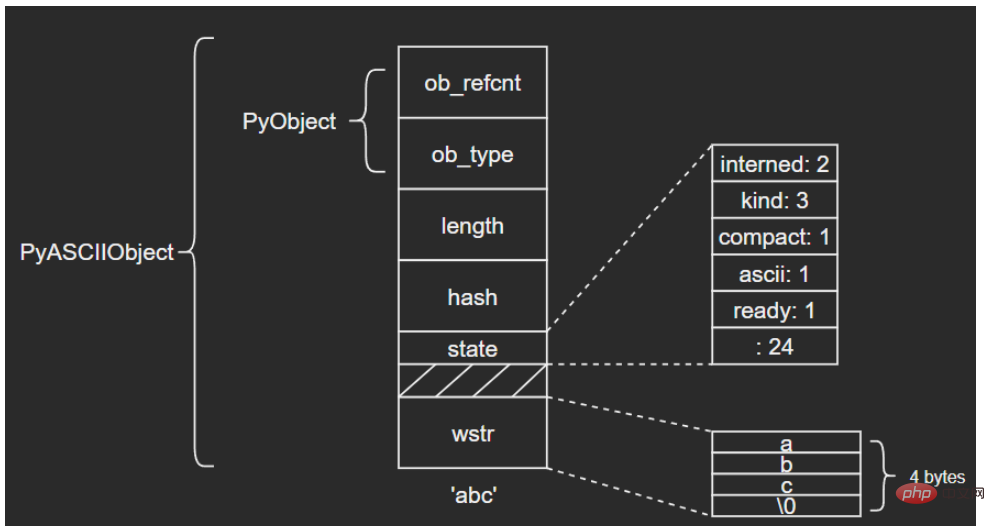
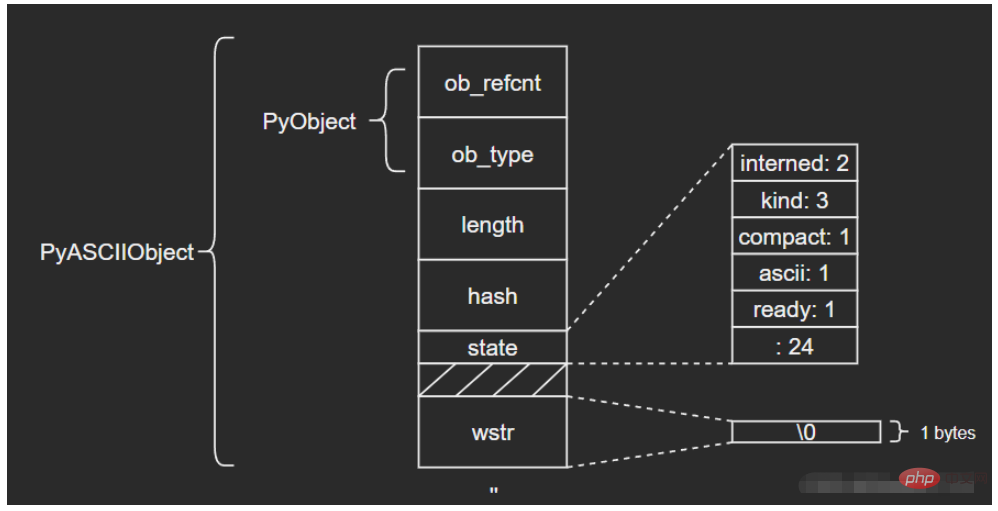
} PyASCIIObject;ログイン後にコピー 源码分析: length:文本长度 hash:文本哈希值 state:Unicode对象标志位 wstr:缓存C字符串的一个wchar_t指针,以“\0”结束(这里和我看的另一篇文章讲得不太一样,另一个描述是:ASCII文本紧接着位于PyASCIIObject结构体后面,我个人觉得现在的这种说法比较准确,毕竟源码结构体后面没有别的字段了) 图示如下: (注意这里state字段后面有一个4字节大小的空洞,这是结构体字段内存对齐造成的现象,主要是为了优化内存访问效率)
ASCII文本由wstr指向,以’abc’和空字符串对象’'为例:
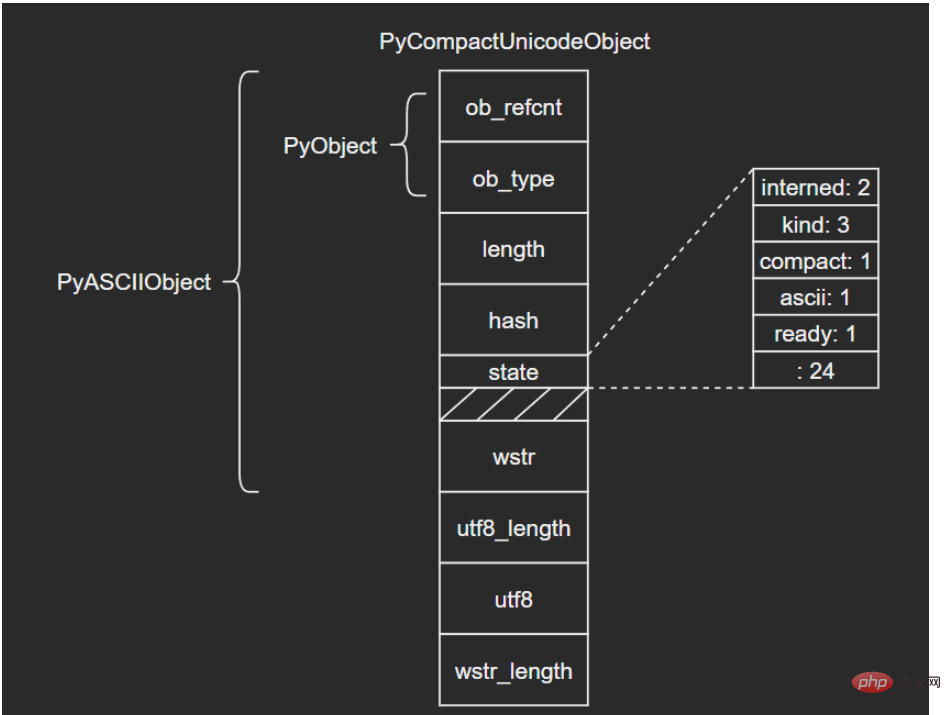
3.2 PyCompactUnicodeObject如果文本不全是ASCII,Unicode对象底层便由PyCompactUnicodeObject结构体保存。C源码如下: /* Non-ASCII strings allocated through PyUnicode_New use the
PyCompactUnicodeObject structure. state.compact is set, and the data
immediately follow the structure. */
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating \0. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;ログイン後にコピー PyCompactUnicodeObject在PyASCIIObject的基础上增加了3个字段: utf8_length:文本UTF8编码长度 utf8:文本UTF8编码形式,缓存以避免重复编码运算 wstr_length:wstr的“长度”(这里所谓的长度没有找到很准确的说法,笔者也不太清楚怎么能打印出来,大家可以自行研究下) 注意到,PyASCIIObject中并没有保存UTF8编码形式,这是因为ASCII本身就是合法的UTF8,这也是ASCII文本底层由PyASCIIObject保存的原因。 结构图示:
3.3 PyUnicodeObjectPyUnicodeObject则是Python中str对象的具体实现。C源码如下: /* Strings allocated through PyUnicode_FromUnicode(NULL, len) use the
PyUnicodeObject structure. The actual string data is initially in the wstr
block, and copied into the data block using _PyUnicode_Ready. */
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;ログイン後にコピー 3.4 示例在日常开发时,要结合实际情况注意字符串拼接前后的内存大小差别: >>> import sys >>> text = 'a' * 1000 >>> sys.getsizeof(text) 1049 >>> text += '????' >>> sys.getsizeof(text) 4080 ログイン後にコピー 4 interned机制如果str对象的interned标志位为1,Python虚拟机将为其开启interned机制, 源码如下:(相关信息在网上可以看到很多说法和解释,这里笔者能力有限,暂时没有找到最确切的答案,之后补充。抱拳~但是我们通过分析源码应该是能看出一些门道的) /* This dictionary holds all interned unicode strings. Note that references
to strings in this dictionary are *not* counted in the string's ob_refcnt.
When the interned string reaches a refcnt of 0 the string deallocation
function will delete the reference from this dictionary.
Another way to look at this is that to say that the actual reference
count of a string is: s->ob_refcnt + (s->state ? 2 : 0)
*/
static PyObject *interned = NULL;
void
PyUnicode_InternInPlace(PyObject **p)
{
PyObject *s = *p;
PyObject *t;
#ifdef Py_DEBUG
assert(s != NULL);
assert(_PyUnicode_CHECK(s));
#else
if (s == NULL || !PyUnicode_Check(s))
return;
#endif
/* If it's a subclass, we don't really know what putting
it in the interned dict might do. */
if (!PyUnicode_CheckExact(s))
return;
if (PyUnicode_CHECK_INTERNED(s))
return;
if (interned == NULL) {
interned = PyDict_New();
if (interned == NULL) {
PyErr_Clear(); /* Don't leave an exception */
return;
}
}
Py_ALLOW_RECURSION
t = PyDict_SetDefault(interned, s, s);
Py_END_ALLOW_RECURSION
if (t == NULL) {
PyErr_Clear();
return;
}
if (t != s) {
Py_INCREF(t);
Py_SETREF(*p, t);
return;
}
/* The two references in interned are not counted by refcnt.
The deallocator will take care of this */
Py_REFCNT(s) -= 2;
_PyUnicode_STATE(s).interned = SSTATE_INTERNED_MORTAL;
}ログイン後にコピー 可以看到,源码前面还是做一些基本的检查。我们可以看一下37行和50行:将s添加到interned字典中时,其实s同时是key和value(这里我不太清楚为什么会这样做),所以s对应的引用计数是+2了的(具体可以看PyDict_SetDefault()的源码),所以在50行时会将计数-2,保证引用计数的正确。 考虑下面的场景: >>> class User:
def __init__(self, name, age):
self.name = name
self.age = age
>>> user = User('Tom', 21)
>>> user.__dict__
{'name': 'Tom', 'age': 21}ログイン後にコピー 由于对象的属性由dict保存,这意味着每个User对象都要保存一个str对象‘name’,这会浪费大量的内存。而str是不可变对象,因此Python内部将有潜在重复可能的字符串都做成单例模式,这就是interned机制。Python具体做法就是在内部维护一个全局dict对象,所有开启interned机制的str对象均保存在这里,后续需要使用的时候,先创建,如果判断已经维护了相同的字符串,就会将新创建的这个对象回收掉。 示例: 由不同运算生成’abc’,最后都是同一个对象: >>> a = 'abc' >>> b = 'ab' + 'c' >>> id(a), id(b), a is b (2752416949872, 2752416949872, True) ログイン後にコピー 以上がPython組み込み型strソースコード解析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。 このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。

ホットAIツール
Undresser.AI Undressリアルなヌード写真を作成する AI 搭載アプリ 
AI Clothes Remover写真から衣服を削除するオンライン AI ツール。 
Undress AI Tool脱衣画像を無料で 
Clothoff.ioAI衣類リムーバー 
Video Face Swap完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。 
人気の記事
KB5055523を修正する方法Windows 11にインストールできませんか?
3週間前
By DDD
KB5055518を修正する方法Windows 10にインストールできませんか?
3週間前
By DDD
<🎜>:死んだレール - オオカミの飼い主
4週間前
By DDD
<🎜>:庭を育てる - 完全な突然変異ガイド
2週間前
By DDD
R.E.P.O.のすべての敵とモンスターの強度レベル
4週間前
By 尊渡假赌尊渡假赌尊渡假赌
ホットツール
メモ帳++7.3.1使いやすく無料のコードエディター 
SublimeText3 中国語版中国語版、とても使いやすい 
ゼンドスタジオ 13.0.1強力な PHP 統合開発環境 
ドリームウィーバー CS6ビジュアル Web 開発ツール 
SublimeText3 Mac版神レベルのコード編集ソフト(SublimeText3)
ホットトピック
Java チュートリアル
 1657
1657
 14
14
CakePHP チュートリアル
1415
52
Laravel チュートリアル
1309
25
PHP チュートリアル
1257
29
C# チュートリアル
1229
24
 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。  PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。  PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。  Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。  Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
PythonコードをSublimeテキストで実行するには、最初にPythonプラグインをインストールし、次に.pyファイルを作成してコードを書き込み、Ctrl Bを押してコードを実行する必要があります。コードを実行すると、出力がコンソールに表示されます。  vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
Visual Studioコード(VSCODE)でコードを作成するのはシンプルで使いやすいです。 VSCODEをインストールし、プロジェクトの作成、言語の選択、ファイルの作成、コードの書き込み、保存して実行します。 VSCODEの利点には、クロスプラットフォーム、フリーおよびオープンソース、強力な機能、リッチエクステンション、軽量で高速が含まれます。  Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。  メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonコードを実行するには、Python実行可能ファイルとNPPEXECプラグインをインストールする必要があります。 Pythonをインストールしてパスを追加した後、nppexecプラグインでコマンド「python」とパラメーター "{current_directory} {file_name}"を構成して、メモ帳のショートカットキー「F6」を介してPythonコードを実行します。 
|