

エージェントラグを使用してインテリジェントFAQチャットボットを構築する方法

AIエージェントは現在、大小さまざまな企業の一部です。病院のフォームに記入したり、法的文書をチェックしたり、ビデオ映像の分析やカスタマーサポートの処理から、あらゆる種類のタスクにAIエージェントがあります。多くの場合、企業は顧客のニーズを理解し、会社のガイドラインに基づいて解決できる顧客サポートスタッフの雇用に数十万ドルを費やしています。今日、FAQに答えるためのインテリジェントなチャットボットを持っていると、カスタマーサービスを効率的に改善できます。この記事では、エージェントRAG(検索拡張生成)、Langgraph、およびChromadbを使用して、数秒で顧客クエリを解決できるFAQチャットボットを構築する方法を学びます。
目次
- エージェントのぼろきれについて簡単に説明します
- インテリジェントFAQチャットボットのアーキテクチャ
- インテリジェントFAQチャットボットの構築に関する実践的な実装
- ステップ1:依存関係をインストールします
- ステップ2:必要なライブラリをインポートします
- ステップ3:OpenAI APIキーを設定します
- ステップ4:データセットをダウンロードします
- ステップ5:マッピングの部門名の定義
- ステップ6:ヘルパー関数を定義します
- ステップ7:Langgraphエージェントコンポーネントを定義します
- ステップ8:グラフ関数を定義します
- ステップ9:エージェントの実行を開始します
- ステップ10:エージェントのテスト
- 結論
エージェントのぼろきれについて簡単に説明します
ラグは最近のホットなトピックです。誰もがぼろきれについて話しており、その上にアプリケーションを構築しています。 RAGは、LLMSがリアルタイムデータにアクセスできるようにするため、LLMSがこれまで以上に正確になります。ただし、従来のRAGシステムは、最適な検索方法を選択したり、検索ワークフローを変更したり、マルチステップの推論を提供したりすると失敗する傾向があります。これは、エージェントラグが入ってくる場所です。
エージェントラグは、AIエージェントの機能をITに組み込むことにより、従来のRAGを強化します。この超大国を使用すると、ぼろきれはクエリの性質に基づいてワークフローを動的に変更し、マルチステップの推論を行い、マルチステップ検索も行うことができます。ツールをエージェントRAGシステムに統合することもでき、いつ使用するツールを動的に決定できます。全体として、精度が向上し、システムがより効率的でスケーラブルになります。
エージェントのRAGワークフローの例を次に示します。
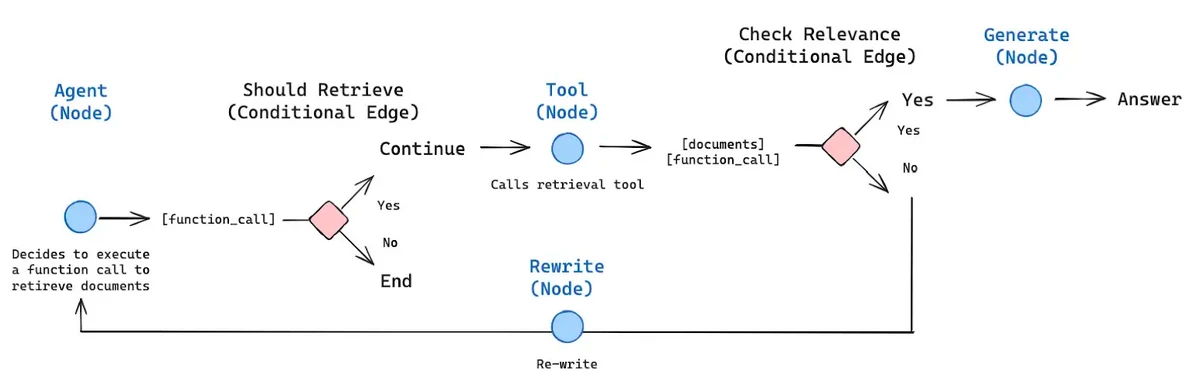
上の画像は、エージェントRAGフレームワークのアーキテクチャを示しています。 AIエージェントは、RAGと組み合わせると、特定の条件下で決定を下すことができる方法を示しています。画像は、条件付きノードがある場合、エージェントが提供されたコンテキストに基づいて選択するエッジを決定することを明確に示しています。
また、読む:LLMエージェントの10のビジネスアプリケーション
インテリジェントFAQチャットボットのアーキテクチャ
次に、構築するチャットボットのアーキテクチャに飛び込みます。私たちは、それがどのように機能し、その重要なコンポーネントが何であるかを調査します。
次の図は、システムの全体的な構造を示しています。 Langgraphを使用してこれを実装します。これは、LangchainのオープンソースAIエージェントフレームワークです。
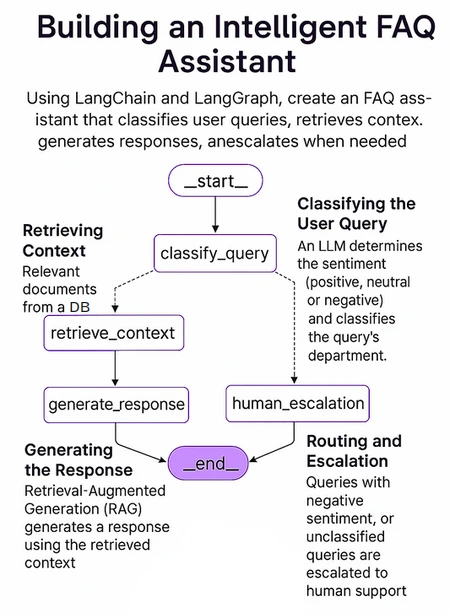
システムの重要なコンポーネントには次のものがあります。
- Langgraph:複雑でマルチエージェント、環状グラフベースのエージェントを効率的に作成する強力なオープンソースAIエージェントフレームワーク。これらのエージェントは、ワークフロー全体で状態を維持でき、複雑なクエリを効率的に処理できます。
- LLM:ユーザーの指示に従い、それに応じてその知識の最高に応じて返信できる効率的で強力な大規模な言語モデル。ここでは、OpenaiのO4-Miniを使用します。これは、速度、手頃な価格、ツールの使用に特化した小さな推論モデルです。
- ベクトルデータベース:ベクトルデータベースは、通常データの数値表現であるベクトル埋め込みを保存、管理、取得するために使用されます。ここでは、オープンソースAIネイティブベクトルデータベースであるChromAdbを使用しています。類似性検索、セマンティック検索、およびベクトルデータを含むその他のタスクに依存するシステムに力を与えるように設計されています。
また読む:カスタマーサポートの音声エージェントを構築する方法
インテリジェントFAQチャットボットの構築に関する実践的な実装
ここで、上記で説明したアーキテクチャに基づいて、チャットボットのエンドツーエンドワークフローを実装します。詳細な説明、コード、およびサンプル出力を段階的に行います。始めましょう。
ステップ1:依存関係をインストールします
まず、必要なすべてのライブラリをJupyterノートブックにインストールすることから始めます。これには、Langchain、Langgraph、Langchain-Openai、Langchain-Community、Chromadb、Openai、Python-Dotenv、Pydantic、Pysqlite3などのライブラリが含まれます。
!pip install -q langchain langgraph langchain-openai langchain-community chromadb openai python-dotenv pydantic pysqlite3
ステップ2:必要なライブラリをインポートします
これで、このプロジェクトに必要な残りのすべてのライブラリをインポートする準備ができました。
OSをインポートします JSONをインポートします インポートリストのタイピング、TypedDict、注釈、DICTから dotenvインポートload_dotenvから #langchain&langgraph固有の輸入 langchain_openaiからchatopenaiをインポートし、openaiembedings langchain_core.promptsから、chatplompttemplate、messagesplaceholderからインポート Pydantic Import Basemodel、Fieldから langchain_core.messagesから、Import SystemMessage、Humanmessage、Aimessageから langchain_core.documentsからインポートドキュメントから langchain_community.vectorstoresからImport Chromaから langgraph.graphからImport Stategraph、end
ステップ3:OpenAI APIキーを設定します
OpenAIキーを入力して、環境変数として設定します。
GetPass Import getPassから openai_api_key = getPass( "Openai APIキー:") load_dotenv() os.getenv( "openai_api_key")
ステップ4:データセットをダウンロードします
さまざまな部門向けにJSON形式でサンプルFAQデータセットを作成しました。ドライブからダウンロードして解凍する必要があります。
!gdod 1j6pdiansfqzkozseuinnhd8w6glkke6w !unzip -o /content/blog_faq_files.zip
出力:
ステップ5:マッピングの部門名の定義
次に、当社のエージェントシステムがどのファイルがどの部門に属しているかを理解できるように、部門のマッピングを定義しましょう。
#部門名を定義します(摂取中に使用されるこれらの一致メタデータを確認してください)
部門= [
「カスタマーサポート」、
「製品情報」、
「ロイヤルティプログラム /報酬」
]
不明_department = "不明/その他"
faq_files = {
「カスタマーサポート」:「customer_support_faq.json」、
「製品情報」:「Product_information_faq.json」、
「ロイヤルティプログラム /報酬」:「loyalty_program_faq.json」、
}ステップ6:ヘルパー関数を定義します
JSONファイルからFAQをロードし、ChromADBに保存するヘルパー関数を定義します。
1。Load_FAQS(…): JSONファイルからFAQをロードし、ALL_FAQSというリストに保存するヘルパー関数です。
def load_faqs(file_paths:dict [str、str]) - > dict [str、list [dict [str、str]]]:
"" "各部門のJSONファイルからQAペアをロードします。" ""
all_faqs = {}
print( "FAQの読み込み...")
deptの場合、file_paths.items()のfile_path:
試す:
open(file_path、 'r'、encoding = 'utf-8')をf:
all_faqs [dept] = json.load(f)
print(f "-Loaded {len(all_faqs [dept])} faqs for {dept}")
filenotfounderrorを除く:
print(f " - 警告:{dept}にはFAQファイルが見つかりません:{file_path}。スキップ。")
json.jsondecodeerrorを除く:
印刷(f " - エラー:{file_path}から{dept}のjsonをデコードできませんでした。スキップ。")
all_faqsを返します2。Setup_chroma_vector_store(…):この関数は、chromadbをセットアップしてベクトル埋め込みを保存します。このために、まず、Chromaデータベースファイルを含むディレクトリであるChroma構成IEを定義します。次に、FAQをLangchainの文書に変換します。正確なRAGの定義済み形式であるメタデータとページコンテンツが含まれます。質問と回答を組み合わせて、より良い文脈を取得するか、答えを埋め込むことができます。メタデータの部門名と同様に質問を維持しています。
#ChromADB構成
chroma_persist_directory = "./chroma_db_store"
chroma_collection_name = "chatbot_faqs"
def setup_chroma_vector_store(
all_faqs:dict [str、list [dict [str、str]]]、
Persip_directory:str、
collection_name:str、
embedding_model:openaiembedings、
) - >クロマ:
"" "FAQデータとメタデータを備えたChroma Vectorストアを作成またはロードします。" ""
文書= []
print( "\ n -npreparing documents for vector store ...")
部門の場合、ALL_FAQS.ITEMS()のFAQ:
FAQのFAQの場合:
#Q&Aを組み合わせてコンテキストの埋め込みを改善するか、回答を埋め込んでください
#content = f "question:{faq ['question']} \ nanswer:{faq ['answer']}"
content = faq ['answer']#回答だけを埋め込むことがよくありますが、FAQ取得に効果的です
doc = document(
page_content = content、
メタデータ= {
「部門」:部門、
「質問」:FAQ ['質問']#潜在的なディスプレイのためにメタデータに質問を続けてください
}
))
documents.append(doc)
印刷(f "合計ドキュメント準備:{len(documents)}")
ドキュメントでない場合:
Raise ValueError(「ベクトルストアに追加するドキュメントは見つかりません。FAQの読み込みを確認してください。」)
print(f "初期化Chromadb Vector Store(Persistence:{staves_directory})...")
vector_store = Chroma(
collection_name = collection_name、
embedding_function = embedding_model、
Persist_directory = festing_directory、
))
試す:
vector_store = chroma.from_documents(
ドキュメント=ドキュメント、
Embedding = embedding_model、
Persist_directory = festing_directory、
collection_name = collection_name
))
print(f "chromadbを作成して入力した{len(documents)} documents。")
vector_store.persist()#作成後に持続性を確保します
print( "ベクトルストアが持続しました。")
create_eとしての例外を除く:
印刷(f "致命的なエラー:クロマベクターストアを作成できませんでした:{create_e}")
create_eを上げます
print( "Chromadbセットアップが完了しました。")
vector_storeを返しますステップ7:Langgraphエージェントコンポーネントを定義します
次に、ワークフローの主なコンポーネントであるAIエージェントコンポーネントを定義しましょう。
1。状態定義:実行中のエージェントの現在の状態を含むPythonクラスです。クエリ、センチメント、部門などの変数が含まれています。
class agentState(typedDict): クエリ:str 感情:str 部門:str コンテキスト:RAGのSTR#取得コンテキスト 応答:ユーザーへのSTR#最終応答 エラー:str |潜在的なエラーをキャプチャする#なし
2。Pydanticモデル:構造化されたLLM出力を確保するPydanticモデルをここで定義しました。 「ポジティブ」、「ネガティブ」、「ニュートラル」の3つの値を持つ感情と、LLMによって予測される部門名が含まれています。
class ClassificationResult(BaseModel):
"" "クエリ分類のための構造化出力" ""
センチメント:str = field(description = "クエリのセンチメント(ポジティブ、ニュートラル、ネガティブ)")
部門:str = field(description = f "リストから最も関連性の高い部門:{departments [nowed_department]}。3。ノード:次のノードは、各タスクを1つずつ処理するノード関数です。
- classify_query_node:クエリの性質に基づいて、受信クエリとターゲット部門名に分類されます。
- retaine_context_node:ベクトルデータベース上でragを実行し、部門名に基づいて結果をフィルタリングします。
- Generate_response_node:データベースからクエリと取得コンテキストに基づいて最終的な応答を生成します。
- human_escalation_node:感情が否定的であるか、ターゲット部門が不明の場合、クエリをヒューマンユーザーにエスカレートします。
- route_query:分類ノードのクエリと出力に基づいて次のステップを決定します。
#3。ノード
def classify_query_node(state:agentstate) - > dict [str、str]:
"" "
LLMを使用して、センチメントおよびターゲット部門のユーザークエリを分類します。
"" "
print( "---クエリの分類---")
query = state ["query"]
llm = chatopenai(model = "o4-mini"、api_key = openai_api_key)#信頼できる安価なモデルを使用します
#分類のためにプロンプトを準備します
prompt_template = chatprompttemplate.from_messages([
SystemMessage(
content = f "" "あなたは小売会社であるShopunowのエキスパートクエリ分類子です。
ユーザーのクエリを分析して、その感情と最も関連性の高い部門を決定します。
利用可能な部門は次のとおりです。{'、' .Join(部門)}。
クエリがこれらのいずれかに明確に収まらない場合、またはあいまいな場合は、部門を「{nownd_department}」に分類します。
クエリが不満、怒り、不満、または問題について不平を言っている場合、感情を「ネガティブ」と分類します。
クエリが質問をしている場合、情報を求めている、または中立的な声明の作成を行っている場合、感情を「中立」として分類します。
クエリが満足度、賞賛、または肯定的なフィードバックを表している場合、感情を「ポジティブ」として分類します。
構造化されたJSON出力形式でのみ応答します。 "" "
)、、
hummessage(content = f "ユーザークエリ:{query}")
]))
#構造化された出力を備えたLLMチェーン
classifier_chain = prompt_template | llm.with_structured_output(classificationResult)
試す:
結果:classificationResult = classifier_chain.invoke({})#入力が必要と思われるため、空のdictを渡す
print(f "分類結果:sentiment = '{result.sentiment}'、department = '{result.department}'")
戻る {
「センチメント」:result.sentiment.lower()、#remormize
「部門」:result.department
}
eとしての例外を除く:
印刷(f "分類中のエラー:{e}")
戻る {
「センチメント」:「ニュートラル」、#デフォルトのエラー
「部門」:不明_Department、
「エラー」:F「分類が失敗しました:{e}」
}
def retive_context_node(state:agentState) - > dict [str、str]:
"" "
クエリと部門に基づいて、ベクトルストアから関連するコンテキストを取得します。
"" "
print( "---取得コンテキスト---")
query = state ["query"]
部門= state ["部門"]
部門または部門ではない場合==不明_Department:
print( "Skipping retireval:部門不明または該当する部門。")
return {"context": ""、 "error": "有効な部門なしでコンテキストを取得できません。"}
#埋め込みモデルとベクトルストアアクセスを初期化します
embedding_model = openaiembeddings(api_key = openai_api_key)
vector_store = Chroma(
collection_name = chroma_collection_name、
embedding_function = embedding_model、
persist_directory = chroma_persist_directory、
))
retriever = vector_store.as_retriever(
search_type = "類似性"、
search_kwargs = {
'k':3、#トップ3の関連ドキュメントを取得します
'フィルター':{'部門':部門}#***クリティカル:部門ごとにフィルター***
}
))
試す:
retireved_docs = retriever.invoke(query)
retrieved_docsの場合:
context = "\ n \ n --- \ n \ n" .join([doc.page_content for doc in retirived_docs])
print(f "retirived {len(retriveved_docs)}部門のドキュメント '{department}'。")
#print(f "context snippet:{context [:200]} ...")#optional:log snippet
return {"context":context、 "error":none}
それ以外:
print( "この部門のベクターストアに関連する文書はありません。")
return {"context": ""、 "error": "関連するコンテキストは見つかりません。"}
eとしての例外を除く:
印刷(f "コンテキスト中のエラー:{e}")
return {"context": ""、 "error":f "取得障害:{e}"}
def generate_response_node(state:agentstate) - > dict [str、str]:
"" "
クエリと取得コンテキストに基づいてRAGを使用して応答を生成します。
"" "
print( "---生成応答(rag)---")
query = state ["query"]
Context = state ["context"]
llm = chatopenai(model = "o4-mini"、api_key = openai_api_key)#生成にもっと有能なモデルを使用できます
コンテキストではない場合:
print( "コンテキストが提供されておらず、一般的な応答を生成します。")
#取得が失敗したが、とにかくルーティングを決定した場合、フォールバック
Response_Text = "知識ベースでクエリに関連する特定の情報が見つかりませんでした。詳細を言い換えたり、提供したりできますか?」
return {"Response":Response_Text}
#ラグプロンプト
prompt_template = chatprompttemplate.from_messages([
SystemMessage(
content = f "" "あなたはShopunowの役立つAIチャットボットです。提供されたコンテキストでのみユーザーのクエリベース *のみ *に答えてください。
簡潔にして、クエリに直接対処します。コンテキストに答えが含まれていない場合は、はっきりと述べてください。
情報を構成しないでください。
コンテクスト:
---
{コンテクスト}
--- "" "
)、、
hummessage(content = f "ユーザークエリ:{query}")
]))
rag_chain = prompt_template | LLM
試す:
応答= rag_chain.invoke({})
Response_Text = Response.Content
print(f "生成されたrag応答:{response_text [:200]} ...")
return {"Response":Response_Text}
eとしての例外を除く:
print(f "応答中のエラー:{e}")
return {"response": "申し訳ありませんが、応答の生成中にエラーが発生しました。"、 "エラー":f "生成が失敗しました:{e}"}
def human_escalation_node(state:agentstate) - > dict [str、str]:
"" "
クエリが人間にエスカレートされることを示すメッセージを提供します。
"" "
print( "---人間のサポートへのエスカレート---")
理由= ""
state.get( "sentiment")== "否定"の場合:
理由=「クエリの性質のために」
elif state.get( "部門")== nownd_department:
理由=「あなたのクエリには特定の注意が必要なので、」
Response_text = f "{理由}これを人間のサポートチームにエスカレートする必要があります。彼らはあなたの要求を確認し、すぐにあなたに戻ってきます。
印刷(f "escalationメッセージ:{respons_text}")
return {"Response":Response_Text}
#4。条件付きルーティングロジック
def route_query(state:agentstate) - > str:
"" "分類結果に基づいて次のステップを決定します。" ""
print( "---ルーティング決定---")
Sentiment = state.get( "sentiment"、 "neutral")
department = state.get( "department"、unknown_department)
感情==「ネガティブ」または部門==不明_department:
print(f "ルーティングへのルーティング:human_escalation(sentiment:{sentiment}、department:{department})")
「human_escalation」を返す
それ以外:
print(f "ルーティングへのルーティング:retive_context(sentient:{sentiment}、department:{department})")
「retive_context」を返すステップ8:グラフ関数を定義します
グラフの関数を構築し、ノードとエッジをグラフに割り当てましょう。
#---グラフ定義---
def build_agent_graph(vector_store:chroma) - > stategraph:
"" "langgraphエージェントを構築します。" ""
graph = stategraph(agentState)
#ノードを追加します
graph.add_node( "classify_query"、classify_query_node)
graph.add_node( "retive_context"、retive_context_node)
graph.add_node( "generate_response"、generate_response_node)
graph.add_node( "human_escalation"、human_escalation_node)
#エントリポイントを設定します
graph.set_entry_point( "classify_query")
#エッジを追加します
graph.add_conditional_edges(
「classify_query」、#ソースノード
route_query、#functionルートを決定します
{#マッピング:route_query->宛先ノードの出力
"retive_context": "retive_context"、
「Human_Escalation」:「Human_Escalation」
}
))
graph.add_edge( "retive_context"、 "generate_response")
graph.add_edge( "generate_response"、end)
graph.add_edge( "human_escalation"、end)
#グラフをコンパイルします
#memory = sqliteSaver.from_conn_string( ":memory:")#inmemoryの持続性の例
app = graph.compile()#checkpointer =ステートフルな会話のためのメモリオプション
print( "\ nagentグラフが正常にコンパイルされました。")
アプリを返しますステップ9:エージェントの実行を開始します
次に、エージェントの初期化を行い、ワークフローの実行を開始します。
1. FAQをロードすることから始めましょう。
#1。FAQをロードします faqs_data = load_faqs(faq_files) faqs_dataではない場合: print( "エラー:FAQデータがロードされていない。終了。") 出口()
出力:

2。埋め込みモデルを設定します。ここでは、より速い検索のためにOpenAI埋め込みモデルをセットアップします。
#2。ベクトルストアのセットアップ embedding_model = openaiembeddings(api_key = openai_api_key) vector_store = setup_chroma_vector_store( faqs_data、 chroma_persist_directory、 chroma_collection_name、 Embedding_model ))
出力:

また読む:ぼろモデルに適した埋め込みを選択する方法は?
3.ここで、事前定義された関数を使用してエージェントを構築し、人魚図を使用してエージェントの流れを視覚化します。
#3。エージェントグラフを作成します agent_app = build_agent_graph(vector_store) iPython.displayからインポートディスプレイ、画像、マークダウン display(image(agent_app.get_graph()。draw_mermaid_png()))
出力:

ステップ10:エージェントのテスト
ワークフローの最後の部分に到着しました。これまでに、いくつかのノードと機能を構築しています。今こそ、エージェントをテストして出力を確認する時です。
1.最初に、テストクエリを定義しましょう。
#エージェントをテストします test_queries = [ 「注文を追跡するにはどうすればよいですか?」 「返品ポリシーは何ですか?」 「「アーバンエクスプローラー」ジャケット素材について教えてください。」、 ]
2。次に、エージェントをテストしましょう。
print( "\ n ---テストエージェント---")
test_queriesのクエリについて:
print(f "\ ninput query:{query}")
#グラフの呼び出しの入力を定義します
inputs = {"query":query}
# 試す:
#グラフを呼び出します
#設定引数はオプションですが、必要に応じてステートフルな実行に役立ちます
#config = {"configureable":{"thread_id": "user_123"}}#config
final_state = agent_app.invoke(inputs)#、config = config)
印刷(f "最終国務省:{final_state.get( 'Department')}")
print(f "final state sentiment:{final_state.get( 'sentiment')}")
印刷(f "エージェント応答:{final_state.get( 'response')}")
final_state.get( 'エラー')の場合:
print(f "ERRORが遭遇しました:{final_state.get( 'error')}")
#Eを除くE:
#print(f "queryのエラー実行中のエージェントグラフ '{query}':{e}")
#トレースバックをインポートします
#traceback.print_exc()#デバッグ用の詳細なtracebackを印刷します
print( "\ n ---エージェントテストが完了しました---")print(“ \ n—テストエージェント - “)
出力:
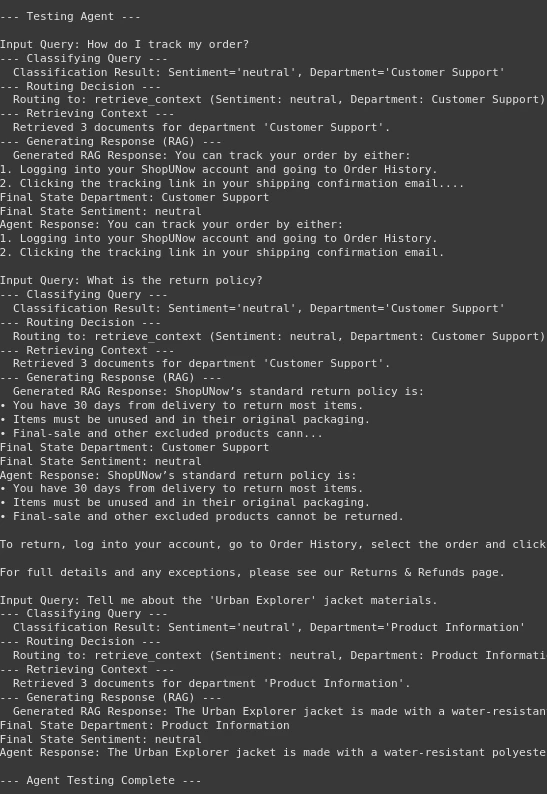
出力では、エージェントがうまく機能していることがわかります。まず、クエリを分類し、決定を検索ノードまたはヒューマンノードにルーティングします。次に、検索部分が登場し、ベクトルデータベースからコンテキストを正常に取得します。最後に、必要に応じて応答を生成します。したがって、インテリジェントなFAQチャットボットを作成しました。
ここでは、すべてのコードを使用してColabノートブックにアクセスできます。
結論
ここまで到達した場合、エージェントラグとランググラフを使用してインテリジェントなFAQチャットボットを構築する方法を学んだことを意味します。ここでは、推論して決定を下すことができるインテリジェントなエージェントを構築することはそれほど難しくないことがわかりました。私たちが構築したエージェントチャットボットは、コスト効率が高く、高速であり、質問や入力クエリのコンテキストを完全に理解することができます。ここで使用したアーキテクチャは完全にカスタマイズ可能です。つまり、特定のユースケースのエージェントのノードを編集できます。エージェントラグ、ランググラフ、およびChromaDBを使用すると、エージェントを作成することはこれほど簡単ではありませんでした。これまでそれほど簡単ではありません。このガイドで説明したものは、これらのツールを使用してより複雑なシステムを構築するための基礎的な知識を提供していると確信しています。
以上がエージェントラグを使用してインテリジェントFAQチャットボットを構築する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1321
25
1269
29
1249
24
14
1423
52
1321
25
1269
29
1249
24

 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
導入 Openaiは、待望の「Strawberry」アーキテクチャに基づいて新しいモデルをリリースしました。 O1として知られるこの革新的なモデルは、推論能力を強化し、問題を通じて考えられるようになりました
 ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 ラマ3.2を実行する3つの方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
ラマ3.2を実行する3つの方法-Analytics Vidhya
Apr 11, 2025 am 11:56 AM
メタのラマ3.2:マルチモーダルAIパワーハウス Metaの最新のマルチモーダルモデルであるLlama 3.2は、AIの大幅な進歩を表しており、言語理解の向上、精度の向上、および優れたテキスト生成機能を誇っています。 その能力t
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics Vidhya
Apr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics Vidhya
Apr 13, 2025 am 11:20 AM
導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
