

頂点AIを使用した埋め込みモデルの探索

ベクトル埋め込みは、セマンティック検索や異常検出など、多くの高度なAIアプリケーションの基本です。この記事では、文の埋め込みとベクトル表現に焦点を当てた埋め込みの基礎的な理解を提供します。平均プーリングやコサインの類似性などの実用的な手法を調査し、BERTを使用してデュアルエンコーダーのアーキテクチャを掘り下げ、詐欺検出やコンテンツモデレーションなどのタスクの頂点AIを使用した異常検出のアプリケーションを調べます。
主要な学習目標
- 連続ベクトル空間内の単語、文、およびその他のデータ型を表す際のベクトル埋め込みの役割を把握します。
- トークン化とトークンの埋め込みが文レベルの埋め込みにどのように寄与するかを理解します。
- 頂点AIを使用して埋め込みモデルを展開するための重要な概念とベストプラクティスを学び、実際のAIの課題に対処します。
- 強化された分析と意思決定のための埋め込みモデルを統合することにより、頂点AIを使用してアプリケーションを最適化および拡張する方法を発見します。
- デュアルエンコーダーモデルの実践的なエクスペリエンストレーニングを獲得し、アーキテクチャとトレーニングプロセスを定義します。
- 分離林のような方法を使用して異常検出を実装して、類似性の埋め込みに基づいて外れ値を特定します。
*この記事は、***データサイエンスブログソンの一部です。
目次
- 頂点埋め込みの理解
- 文の埋め込みが説明されました
- 文の埋め込みにおけるコサインの類似性
- デュアルエンコーダーモデルのトレーニング
- 質問を回答するためのデュアルエンコーダー
- デュアルエンコーダートレーニングプロセス
- 頂点AIを使用した埋め込みを活用します
- スタックオーバーフローからのデータセットの作成
- テキストの埋め込みを生成します
- バッチ埋め込み生成
- 異常識別
- 外れ値検出のための分離林
- 結論
- よくある質問
頂点埋め込みの理解
ベクトル埋め込みは、定義された空間内の単語または文を表します。これらのベクトルの近接性は類似性を意味します。より近いベクトルは、セマンティックな類似性の大きさを示します。最初は主にNLPで使用されていましたが、そのアプリケーションは画像、ビデオ、オーディオ、グラフに拡張されています。顕著なマルチモーダル学習モデルであるClipは、画像とテキストの埋め込みの両方を生成します。
ベクトル埋め込みの主要なアプリケーションには次のものがあります。
- LLMSは、入力トークン変換後のトークン埋め込みとしてそれらを利用します。
- セマンティック検索では、クエリに対する最も関連性の高い回答を見つけるために採用されています。
- 検索拡張生成(RAG)では、文の埋め込みにより、関連情報のチャンクの検索が促進されます。
- 推奨システムは、それらを使用して製品を表現し、関連項目を特定します。
ぼろきれパイプラインにおける文の埋め込みの重要性を調べましょう。
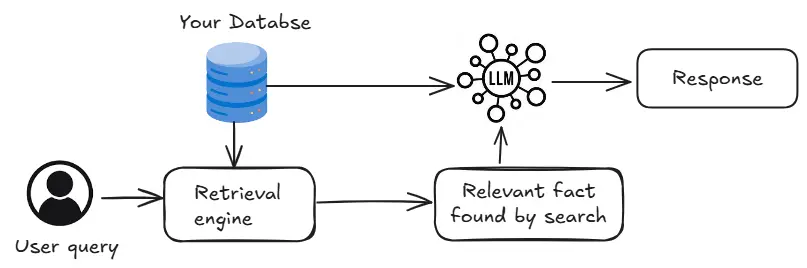
上記の図の検索エンジンは、ユーザークエリに関連するデータベース情報を識別します。トランスベースのクロスエンコーダーは、クエリをすべての情報と比較して、関連性を分類できます。ただし、これは遅いです。ベクトルデータベースは、埋め込みを保存し、類似性検索を使用することにより、より高速な代替手段を提供しますが、精度はわずかに低くなる場合があります。
文の埋め込みを理解する
文の埋め込みは、数学的操作をトークン埋め込みに適用することによって作成されます。これは、多くの場合、BertやGPTなどの事前に訓練されたモデルによって生成されます。次のコードは、文を生成したトークン埋め込みの平均プーリングを示しています。
model_name = "./models/bert-base-uncased"
tokenizer = berttokenizer.from_pretrained(model_name)
Model = bertmodel.from_pretrained(model_name)
def get_sentence_embedding(cente):
encoded_input = tokenizer(cente、padding = true、truncation = true、return_tensors = 'pt')
attention_mask = encoded_input ['attention_mask']
torch.no_grad()を使用して:
output = model(** encoded_input)
token_embeddings = output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size())。float()
cente_embeding = torch.sum(token_embeddings * input_mask_expanded、1) / torch.clamp(input_mask_expanded.sum(1)、min = 1e-9)
return tente_embeding.flatten()。tolist()このコードはBERTモデルをロードし、平均プーリングを使用して文埋め込みを計算する関数を定義します。
文の埋め込みのコサインの類似性
コサインの類似性は、2つのベクトル間の類似性を測定し、文の埋め込みを比較するのに適しています。次のコードは、コサインの類似性と視覚化を実装します。
defosine_similarity_matrix(feature):
norms = np.linalg.norm(feature、axis = 1、keepdims = true)
remarized_features = feature / norms
類似性_matrix = np.inner(remarized_features、remormized_features)
rounded_similarity_matrix = np.round(signility_matrix、4)
Runited_similarity_matrixを返します
def plot_similarity(ラベル、機能、回転):
sim = cosine_similarity_matrix(feature)
sns.set_theme(font_scale = 1.2)
g = sns.heatmap(sim、xticklabels = labels、yticklabels = labels、vmin = 0、vmax = 1、cmap = "ylorrd")
g.set_xticklabels(ラベル、回転=回転)
g.set_title( "セマンティックテキストの類似性")
g
メッセージ= [
# テクノロジー
「私は仕事にMacBookを使用することを好みます。」、
「AIは人間の仕事を引き継いでいますか?」
「私のラップトップのバッテリーは速すぎて排出します。」
#スポーツ
「昨夜ワールドカップ決勝を見ましたか?」
「レブロン・ジェームズは信じられないほどのバスケットボール選手です。」
「週末にマラソンを走るのは楽しかった」、
# 旅行
「パリは訪れるべき美しい街です。」、
「夏に旅行するのに最適な場所は何ですか?」
「私はスイスアルプスでのハイキングが大好きです。」
# エンターテインメント
「最新のマーベル映画は素晴らしかった!」
「テイラー・スウィフトの歌を聴いていますか?」
「私は私のお気に入りのシリーズのシーズン全体を視聴しました。」
]
埋め込み= []
メッセージのtの場合:
emb = get_sentence_embedding(t)
Embeddings.Append(emb)
plot_similarity(メッセージ、埋め込み、90)このコードは、文を定義し、埋め込みを生成し、コサインの類似性を示すヒートマップをプロットします。結果は、予想外に高い類似性を示す可能性があり、デュアルエンコーダーのようなより正確な方法の探求を動機付けています。
(残りのセクションは同様の方法で続き、コア情報を維持し、画像の場所と形式を保持しながら、元のテキストを言い換えて再構築します。)
以上が頂点AIを使用した埋め込みモデルの探索の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1659
1659
 14
1416
52
1310
25
1258
29
1232
24
14
1416
52
1310
25
1258
29
1232
24

 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
導入 Openaiは、待望の「Strawberry」アーキテクチャに基づいて新しいモデルをリリースしました。 O1として知られるこの革新的なモデルは、推論能力を強化し、問題を通じて考えられるようになりました
 SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
 最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
私のコラムに新しいかもしれない人のために、具体化されたAI、AI推論、AIのハイテクブレークスルー、AIの迅速なエンジニアリング、AIのトレーニング、AIのフィールディングなどのトピックなど、全面的なAIの最新の進歩を広く探求します。
