

スノーフレークスノーパーク:包括的な紹介

Snowpark:雪だるまを使用したdatabase機械学習
従来の機械学習には、データベースから大規模なデータセットをモデルトレーニング環境に移動することがよくあります。 これは、今日の大規模なデータセットではますます非効率的になっています。 Snowflake Snowparkは、Databaseで処理を可能にすることでこれに対処します。 SnowParkは、Snowflakeのクラウド内で直接コード(Python、Java、Scala)を実行するライブラリとランタイムを提供し、データの動きを最小限に抑え、セキュリティを強化します。
なぜスノーパークを選ぶのか?Snowparkにはいくつかの重要な利点があります:
- DATABASE処理:データ転送なしで好みの言語を使用してスノーフレークデータを操作して分析します。 パフォーマンスの改善:
- スノーフレークのスケーラブルアーキテクチャを活用して、効率的な処理 コストの削減: インフラストラクチャ管理オーバーヘッドを最小限に抑えます。
- 馴染みのあるツール: JupyterやVSコードなどの既存のツールと統合し、おなじみのライブラリ(Pandas、Scikit-Learn、Xgboost)を利用します。
- 始めましょう:ステップバイステップガイド このチュートリアルでは、SnowParkを使用してハイパーパラメーターチューニングモデルの構築を示しています
コンドラ環境を作成し、必要なライブラリをインストールします(
、- 、
- 、
、、、
snowflake-snowpark-python)。pandas)。pyarrownumpymatplotlibseabornデータの摂取:ipykernelサンプルデータ(シーボーンダイヤモンドデータセットなど)をスノーフレークテーブルにインポートします。 (注:実際のシナリオでは、通常、既存のスノーフレークデータベースを使用して作業します。) -
SnowParkセッションの作成:資格情報(アカウント名、ユーザー名、パスワード)を使用してSnowflakeへの接続を確立します。
-
データの読み込み:SnowParkセッションを使用して、データにアクセスしてSnowParkデータフレームにロードします。
config.py.gitignoreSnowParkデータフレームの理解 SnowPark DataFramesは怠lazに動作し、最適化されたSQLクエリに変換する前に、操作の論理的表現を構築します。これは、Pandasの熱心な実行とは対照的であり、特に大きなデータセットで大きなパフォーマンスの向上を提供します。
SnowParkデータフレームを使用する -
ローカルマシンにデータを転送することは非現実的である大規模なデータセットにSnowParkデータフレームを使用します。 小さなデータセットの場合、パンダで十分です。 この方法により、SnowParkとPandasのデータフレーム間の変換が可能になります。 メソッドは、SQLクエリを直接実行するための代替手段を提供します。
SnowParkデータフレーム変換関数: Snowparkの変換関数( -
プリプロセシング:スノーフレークMLの
および - を使用して、プリプセスデータを使用します。
。を使用してパイプラインを保存します
)をトレーニングします。 データをPipelineOrdinalEncoderStandardScalerモデルトレーニング:joblibプリプロセッスされたデータを使用してxgboostモデル( 。
-
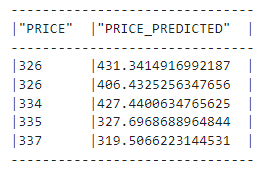
モデルの評価:
)などのメトリックを使用してモデルを評価します。XGBRegressorrmse(random_split()from -
ハイパーパラメーターチューニング:
mean_squared_errorを使用して、モデルハイパーパラメーターを最適化します。snowflake.ml.modeling.metrics モデルの保存:トレーニングされたモデルとそのメタデータをSnowflakeのモデルレジストリに保存します。
RandomizedSearchCV推論:- レジストリから保存されたモデルを使用して新しいデータに推論を実行します。
結論:
Snowparkは、データベース内の機械学習を実行するための強力で効率的な方法を提供します。 その怠zyな評価、馴染みのあるライブラリとの統合、およびモデルレジストリにより、大規模なデータセットを処理するための貴重なツールになります。 より高度な機能と機能については、SnowPark APIおよびML開発者ガイドを参照してください。Registry
注:画像URLは入力から保存されます。 フォーマットは、読みやすさと流れを改善するために調整されます。 技術的な詳細は保持されますが、言語はより簡潔になり、より多くの視聴者がアクセスしやすくなります。
F、snowflake.snowpark.functions、および.select()メソッドで使用されます。
.filter()探索的データ分析(EDA):.with_column()
データのクリーニング:
データ型が正しいことを確認し、前処理のニーズ(例えば、列の名前変更、データ型のキャスト、テキスト機能のクリーニングなど)を処理します。











以上がスノーフレークスノーパーク:包括的な紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
Meta Llama 3.2を始めましょう - 分析Vidhya
Apr 11, 2025 pm 12:04 PM
メタのラマ3.2:マルチモーダルとモバイルAIの前進 メタは最近、ラマ3.2を発表しました。これは、モバイルデバイス向けに最適化された強力なビジョン機能と軽量テキストモデルを特徴とするAIの大幅な進歩です。 成功に基づいてo
 10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
10生成AIコーディング拡張機能とコードのコードを探る必要があります
Apr 13, 2025 am 01:14 AM
ねえ、忍者をコーディング!その日はどのようなコーディング関連のタスクを計画していますか?このブログにさらに飛び込む前に、コーディング関連のすべての問題について考えてほしいです。 終わり? - &#8217を見てみましょう
 AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
AVバイト:Meta' s llama 3.2、GoogleのGemini 1.5など
Apr 11, 2025 pm 12:01 PM
今週のAIの風景:進歩、倫理的考慮、規制の議論の旋風。 Openai、Google、Meta、Microsoftのような主要なプレーヤーは、画期的な新しいモデルからLEの重要な変化まで、アップデートの急流を解き放ちました
 従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
従業員へのAI戦略の販売:Shopify CEOのマニフェスト
Apr 10, 2025 am 11:19 AM
Shopify CEOのTobiLütkeの最近のメモは、AIの能力がすべての従業員にとって基本的な期待であると大胆に宣言し、会社内の重大な文化的変化を示しています。 これはつかの間の傾向ではありません。これは、pに統合された新しい運用パラダイムです
 GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
GPT-4o vs Openai O1:新しいOpenaiモデルは誇大広告に値しますか?
Apr 13, 2025 am 10:18 AM
導入 Openaiは、待望の「Strawberry」アーキテクチャに基づいて新しいモデルをリリースしました。 O1として知られるこの革新的なモデルは、推論能力を強化し、問題を通じて考えられるようになりました
 ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
ビジョン言語モデル(VLM)の包括的なガイド
Apr 12, 2025 am 11:58 AM
導入 鮮やかな絵画や彫刻に囲まれたアートギャラリーを歩くことを想像してください。さて、各ピースに質問をして意味のある答えを得ることができたらどうでしょうか?あなたは尋ねるかもしれません、「あなたはどんな話を言っていますか?
 最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
最高の迅速なエンジニアリング技術の最新の年次編集
Apr 10, 2025 am 11:22 AM
私のコラムに新しいかもしれない人のために、具体化されたAI、AI推論、AIのハイテクブレークスルー、AIの迅速なエンジニアリング、AIのトレーニング、AIのフィールディングなどのトピックなど、全面的なAIの最新の進歩を広く探求します。
 SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLに列を追加する方法は? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQLの変更テーブルステートメント:データベースに列を動的に追加する データ管理では、SQLの適応性が重要です。 その場でデータベース構造を調整する必要がありますか? Alter Tableステートメントはあなたの解決策です。このガイドの詳細は、コルを追加します
