

CDKTFを使用してAWS ECSにスプリングブートAPIを展開する方法は?

Java開発者がAWS ECSにスプリングブートAPIを展開する方法を尋ねたとき、私はそれをCDKTF(Terraform for Terraformのクラウド開発キット)の最新の更新に飛び込む絶好の機会だと思った。
前の記事では、Pythonなどの汎用プログラミング言語を使用してインフラストラクチャをコード(IAC)として記述できるフレームワークであるCDKTFを導入しました。それ以来、CDKTFは最初のGAリリースに達し、再訪するのに最適な時期になりました。この記事では、CDKTFを使用してAWS ECSにスプリングブートAPIを展開します。私のgithubレポでこの記事のコードを見つけます。
アーキテクチャの概要
実装に飛び込む前に、展開することを目的としたアーキテクチャを確認しましょう:
この図から、アーキテクチャを03レイヤーに分解できます。
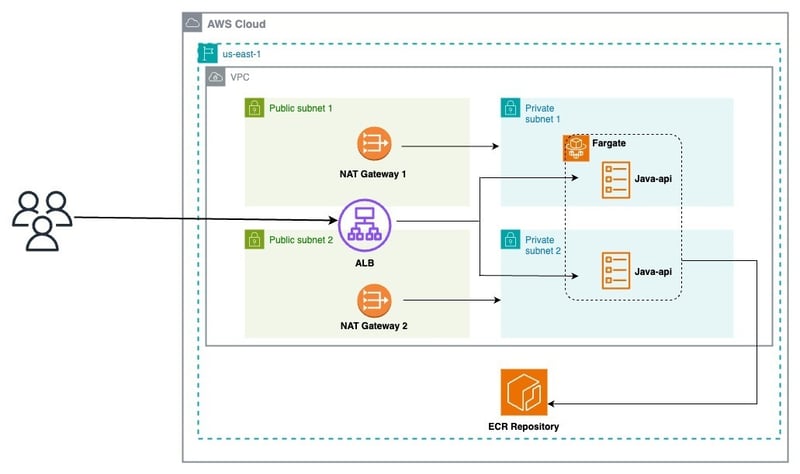
ネットワーク
:- vpc
パブリックおよびプライベートサブネット
- インターネットゲートウェイ
- natゲートウェイ
- インフラストラクチャ
- アプリケーションロードバランサー(alb)
リスナー
- ecsクラスター
- サービススタック
- ターゲットグループ
ecsサービス
- タスクの定義
- ステップ1:スプリングブートアプリケーションをコンテナ化します
展開しているJava APIは、githubで入手できます。
3つのエンドポイントを備えた単純なREST APIを定義します:
/ping
:文字列「ポン」を返します。このエンドポイントは、APIの応答性をテストするのに役立ちます。また、モニタリングのためにプロメテウスカウンターメトリックを増加させます- /healthCheck:「OK」を返し、アプリケーションが正しく実行されていることを確認するためにヘルスチェックエンドポイントとして機能します。 /pingのように、観察可能性のためにプロメテウスカウンターを更新します。
- /hello:名前クエリパラメーター(デフォルトは「world」にデフォルト)を受け入れ、「hello、[name]!」などのパーソナライズされた挨拶を返します。このエンドポイントは、プロメテウスカウンターとも統合されています
- dockerfile:を追加しましょう
アプリケーションの展開の準備ができました!
ステップ2:AWS CDKTFをセットアップします
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]
2。
cdktfと依存関係をインストールします
CDKTFとその依存関係をインストールして、必要なツールを確保してください。
これにより、さまざまな言語の新しいプロジェクトをスピンアップできるCDKTF CLIがインストールされます。- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
実行して、新しいPythonプロジェクトを足場にすることができます:
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]
デフォルトで作成された多くのファイルがあり、すべての依存関係がインストールされています。 以下は初期のmain.pyfile:
です
- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
a
stackは、cdk for terraform(cdktf)が異なるテラフォーム構成にコンパイルするインフラストラクチャリソースのグループを表します。スタックは、アプリケーション内のさまざまな環境に対して個別の状態管理を可能にします。レイヤー間でリソースを共有するには、クロススタック参照を利用します。 1。
network_stack.pyファイルをプロジェクトに追加します次のコードを追加して、すべてのネットワークリソースを作成します。
$ npm install -g cdktf-cli@latest
ファイルを編集します:
# init the project using aws provider $ mkdir samples-fargate $ cd samples-fargate && cdktf init --template=python --providers=aws
次のコマンドを実行してTerraform構成ファイルを生成します。
これを
#!/usr/bin/env python
from constructs import Construct
from cdktf import App, TerraformStack
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
# define resources here
app = App()
MyStack(app, "aws-cdktf-samples-fargate")
app.synth()
$ mkdir infra $ cd infra && touch network_stack.py
VPCは、下の画像に示すように準備ができています:
from constructs import Construct
from cdktf import S3Backend, TerraformStack
from cdktf_cdktf_provider_aws.provider import AwsProvider
from cdktf_cdktf_provider_aws.vpc import Vpc
from cdktf_cdktf_provider_aws.subnet import Subnet
from cdktf_cdktf_provider_aws.eip import Eip
from cdktf_cdktf_provider_aws.nat_gateway import NatGateway
from cdktf_cdktf_provider_aws.route import Route
from cdktf_cdktf_provider_aws.route_table import RouteTable
from cdktf_cdktf_provider_aws.route_table_association import RouteTableAssociation
from cdktf_cdktf_provider_aws.internet_gateway import InternetGateway
class NetworkStack(TerraformStack):
def __init__(self, scope: Construct, ns: str, params: dict):
super().__init__(scope, ns)
self.region = params["region"]
# configure the AWS provider to use the us-east-1 region
AwsProvider(self, "AWS", region=self.region)
# use S3 as backend
S3Backend(
self,
bucket=params["backend_bucket"],
key=params["backend_key_prefix"] + "/network.tfstate",
region=self.region,
)
# create the vpc
vpc_demo = Vpc(self, "vpc-demo", cidr_block="192.168.0.0/16")
# create two public subnets
public_subnet1 = Subnet(
self,
"public-subnet-1",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}a",
cidr_block="192.168.1.0/24",
)
public_subnet2 = Subnet(
self,
"public-subnet-2",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}b",
cidr_block="192.168.2.0/24",
)
# create. the internet gateway
igw = InternetGateway(self, "igw", vpc_id=vpc_demo.id)
# create the public route table
public_rt = Route(
self,
"public-rt",
route_table_id=vpc_demo.main_route_table_id,
destination_cidr_block="0.0.0.0/0",
gateway_id=igw.id,
)
# create the private subnets
private_subnet1 = Subnet(
self,
"private-subnet-1",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}a",
cidr_block="192.168.10.0/24",
)
private_subnet2 = Subnet(
self,
"private-subnet-2",
vpc_id=vpc_demo.id,
availability_zone=f"{self.region}b",
cidr_block="192.168.20.0/24",
)
# create the Elastic IPs
eip1 = Eip(self, "nat-eip-1", depends_on=[igw])
eip2 = Eip(self, "nat-eip-2", depends_on=[igw])
# create the NAT Gateways
private_nat_gw1 = NatGateway(
self,
"private-nat-1",
subnet_id=public_subnet1.id,
allocation_id=eip1.id,
)
private_nat_gw2 = NatGateway(
self,
"private-nat-2",
subnet_id=public_subnet2.id,
allocation_id=eip2.id,
)
# create Route Tables
private_rt1 = RouteTable(self, "private-rt1", vpc_id=vpc_demo.id)
private_rt2 = RouteTable(self, "private-rt2", vpc_id=vpc_demo.id)
# add default routes to tables
Route(
self,
"private-rt1-default-route",
route_table_id=private_rt1.id,
destination_cidr_block="0.0.0.0/0",
nat_gateway_id=private_nat_gw1.id,
)
Route(
self,
"private-rt2-default-route",
route_table_id=private_rt2.id,
destination_cidr_block="0.0.0.0/0",
nat_gateway_id=private_nat_gw2.id,
)
# associate routes with subnets
RouteTableAssociation(
self,
"public-rt-association",
subnet_id=private_subnet2.id,
route_table_id=private_rt2.id,
)
RouteTableAssociation(
self,
"private-rt1-association",
subnet_id=private_subnet1.id,
route_table_id=private_rt1.id,
)
RouteTableAssociation(
self,
"private-rt2-association",
subnet_id=private_subnet2.id,
route_table_id=private_rt2.id,
)
# terraform outputs
self.vpc_id = vpc_demo.id
self.public_subnets = [public_subnet1.id, public_subnet2.id]
self.private_subnets = [private_subnet1.id, private_subnet2.id]
 2。
2。
ファイルをプロジェクトに追加します

main.py
ファイルを編集します:
#!/usr/bin/env python
from constructs import Construct
from cdktf import App, TerraformStack
from infra.network_stack import NetworkStack
ENV = "dev"
AWS_REGION = "us-east-1"
BACKEND_S3_BUCKET = "blog.abdelfare.me"
BACKEND_S3_KEY = f"{ENV}/cdktf-samples"
class MyStack(TerraformStack):
def __init__(self, scope: Construct, id: str):
super().__init__(scope, id)
# define resources here
app = App()
MyStack(app, "aws-cdktf-samples-fargate")
network = NetworkStack(
app,
"network",
{
"region": AWS_REGION,
"backend_bucket": BACKEND_S3_BUCKET,
"backend_key_prefix": BACKEND_S3_KEY,
},
)
app.synth()
を展開します
$ cdktf synth
$ cdktf deploy network
プロジェクトに
service_stack.py
$ cd infra && touch infra_stack.py
次のコードを追加して、すべてのECSサービスリソースを作成します。

main.pyを更新します(最後に?):
サービスstackを展開します
from constructs import Construct
from cdktf import S3Backend, TerraformStack
from cdktf_cdktf_provider_aws.provider import AwsProvider
from cdktf_cdktf_provider_aws.ecs_cluster import EcsCluster
from cdktf_cdktf_provider_aws.lb import Lb
from cdktf_cdktf_provider_aws.lb_listener import (
LbListener,
LbListenerDefaultAction,
LbListenerDefaultActionFixedResponse,
)
from cdktf_cdktf_provider_aws.security_group import (
SecurityGroup,
SecurityGroupIngress,
SecurityGroupEgress,
)
class InfraStack(TerraformStack):
def __init__(self, scope: Construct, ns: str, network: dict, params: dict):
super().__init__(scope, ns)
self.region = params["region"]
# Configure the AWS provider to use the us-east-1 region
AwsProvider(self, "AWS", region=self.region)
# use S3 as backend
S3Backend(
self,
bucket=params["backend_bucket"],
key=params["backend_key_prefix"] + "/load_balancer.tfstate",
region=self.region,
)
# create the ALB security group
alb_sg = SecurityGroup(
self,
"alb-sg",
vpc_id=network["vpc_id"],
ingress=[
SecurityGroupIngress(
protocol="tcp", from_port=80, to_port=80, cidr_blocks=["0.0.0.0/0"]
)
],
egress=[
SecurityGroupEgress(
protocol="-1", from_port=0, to_port=0, cidr_blocks=["0.0.0.0/0"]
)
],
)
# create the ALB
alb = Lb(
self,
"alb",
internal=False,
load_balancer_type="application",
security_groups=[alb_sg.id],
subnets=network["public_subnets"],
)
# create the LB Listener
alb_listener = LbListener(
self,
"alb-listener",
load_balancer_arn=alb.arn,
port=80,
protocol="HTTP",
default_action=[
LbListenerDefaultAction(
type="fixed-response",
fixed_response=LbListenerDefaultActionFixedResponse(
content_type="text/plain",
status_code="404",
message_body="Could not find the resource you are looking for",
),
)
],
)
# create the ECS cluster
cluster = EcsCluster(self, "cluster", name=params["cluster_name"])
self.alb_arn = alb.arn
self.alb_listener = alb_listener.arn
self.alb_sg = alb_sg.id
self.cluster_id = cluster.id
AWS ECS Fargateに新しいサービスを展開するためのすべてのリソースを正常に作成しました。
以下を実行して、スタックのリストを取得します
...
CLUSTER_NAME = "cdktf-samples"
...
infra = InfraStack(
app,
"infra",
{
"vpc_id": network.vpc_id,
"public_subnets": network.public_subnets,
},
{
"region": AWS_REGION,
"backend_bucket": BACKEND_S3_BUCKET,
"backend_key_prefix": BACKEND_S3_KEY,
"cluster_name": CLUSTER_NAME,
},
)
...
$ cdktf deploy network infra
ステップ4:GitHubアクションワークフロー
展開を自動化するには、githubアクションワークフローを java-apiに統合しましょう。 GitHubアクションを有効にして、リポジトリの秘密と変数を設定した後、.github/workflows/deploy.ymlファイルを作成し、以下のコンテンツを追加します。
FROM maven:3.9-amazoncorretto-21 AS builder WORKDIR /app COPY pom.xml . COPY src src RUN mvn clean package # amazon java distribution FROM amazoncorretto:21-alpine COPY --from=builder /app/target/*.jar /app/java-api.jar EXPOSE 8080 ENTRYPOINT ["java","-jar","/app/java-api.jar"]


次のスクリプトを使用して展開をテストします(
ALB URLを自分のものに置き換えます):
- [**python (3.13)**](https://www.python.org/) - [**pipenv**](https://pipenv.pypa.io/en/latest/) - [**npm**](https://nodejs.org/en/)
ALBはトラフィックを提供する準備ができています!
最終的な考え
AWS CDKTFを活用することにより、Pythonを使用してクリーンで保守可能なIACコードを書くことができます。このアプローチは、AWS ECS FargateのスプリングブートAPIなどのコンテナ化されたアプリケーションの展開を簡素化します。CDKTFの柔軟性は、Terraformの堅牢な機能と組み合わされて、最新のクラウド展開に最適な選択肢となります。
CDKTFプロジェクトはインフラストラクチャ管理のための多くの興味深い機能を提供していますが、時々冗談を言っていることを認めなければなりません。CDKTFの経験はありますか?生産で使用しましたか?
あなたの経験を私たちとお気軽に共有してください。
以上がCDKTFを使用してAWS ECSにスプリングブートAPIを展開する方法は?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1664
1664
 14
1423
52
1317
25
1268
29
1243
24
14
1423
52
1317
25
1268
29
1243
24

 Python vs. C:比較されたアプリケーションとユースケース
Apr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケース
Apr 12, 2025 am 12:01 AM
Pythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
Python:ゲーム、GUIなど
Apr 13, 2025 am 12:14 AM
PythonはゲームとGUI開発に優れています。 1)ゲーム開発は、2Dゲームの作成に適した図面、オーディオ、その他の機能を提供し、Pygameを使用します。 2)GUI開発は、TKINTERまたはPYQTを選択できます。 TKINTERはシンプルで使いやすく、PYQTは豊富な機能を備えており、専門能力開発に適しています。
 2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチ
Apr 11, 2025 am 12:04 AM
2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Python vs. C:曲線と使いやすさの学習
Apr 19, 2025 am 12:20 AM
Pythonは学習と使用が簡単ですが、Cはより強力ですが複雑です。 1。Python構文は簡潔で初心者に適しています。動的なタイピングと自動メモリ管理により、使いやすくなりますが、ランタイムエラーを引き起こす可能性があります。 2.Cは、高性能アプリケーションに適した低レベルの制御と高度な機能を提供しますが、学習しきい値が高く、手動メモリとタイプの安全管理が必要です。
 2時間でどのくらいのPythonを学ぶことができますか?
Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?
Apr 09, 2025 pm 04:33 PM
2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
Pythonと時間:勉強時間を最大限に活用する
Apr 14, 2025 am 12:02 AM
限られた時間でPythonの学習効率を最大化するには、PythonのDateTime、時間、およびスケジュールモジュールを使用できます。 1. DateTimeモジュールは、学習時間を記録および計画するために使用されます。 2。時間モジュールは、勉強と休息の時間を設定するのに役立ちます。 3.スケジュールモジュールは、毎週の学習タスクを自動的に配置します。
 Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Python:自動化、スクリプト、およびタスク管理
Apr 16, 2025 am 12:14 AM
Pythonは、自動化、スクリプト、およびタスク管理に優れています。 1)自動化:OSやShutilなどの標準ライブラリを介してファイルバックアップが実現されます。 2)スクリプトの書き込み:Psutilライブラリを使用してシステムリソースを監視します。 3)タスク管理:スケジュールライブラリを使用してタスクをスケジュールします。 Pythonの使いやすさと豊富なライブラリサポートにより、これらの分野で優先ツールになります。
 Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査
Apr 10, 2025 am 09:41 AM
Pythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
