

CS - 第 5 週

データ構造
情報構造 は、メモリ内の情報を整理する形式です。メモリ内のデータを整理するにはさまざまな方法があります。
抽象データ構造 は、私たちが概念的に想像する構造です。これらの抽象構造に慣れると、将来的にデータ構造を実際に実装することが容易になります。
スタックとキュー
キュー は、抽象データ構造の形式です。
キューのデータ構造は、FIFO (先入れ先出し、「最初に追加された要素が最初に出力される」) ルールに従って機能します。
これは、アトラクションで列に並んでいる人々の例として想像できます。列の先頭の人が先に乗り、最後の人が最後に乗ります。
キューを使用して次の操作を実行できます:
- エンキュー: キューの最後に新しい要素を追加します。
- デキュー: キューの先頭から要素を削除します。
スタック データ構造は、LIFO (後入れ先出し、「最後に追加された要素が最初に出力される」) ルールに従って機能します。
たとえば、キッチンでお皿を積み重ねる場合、最後のお皿が最初に取り出されます。
- プッシュ: 新しい要素をスタックに置きます。
- Pop: スタックから要素を削除します。
配列
配列 は、メモリにデータを順番に格納する方法です。配列は次のように視覚化できます:


:
 要素を配列に移動して新しい値を追加すると、新しい値は新しく割り当てられたメモリ内の古い不要な値に上書きされます。
要素を配列に移動して新しい値を追加すると、新しい値は新しく割り当てられたメモリ内の古い不要な値に上書きされます。
このアプローチの欠点は、新しい要素が追加されるたびに配列全体をコピーする必要があることです。
4 をメモリの別の場所に置いたらどうなるでしょうか?そして、4 はメモリ内の配列要素と連続していないため、定義により、これは配列ではなくなります。
場合によっては、プログラマが必要以上のメモリを割り当てることがあります(例: 30 要素の場合は 300)。しかし、これはシステム リソースを無駄にし、ほとんどの場合、追加のメモリは不要であるため、これは悪い設計です。したがって、特定のニーズに応じてメモリを割り当てることが重要です。
リンクされたリスト
リンク リスト は、C プログラミング言語で最も強力なデータ構造の 1 つです。これらを使用すると、異なるメモリ領域にある値を 1 つのリストに結合できます。また、必要に応じてリストを動的に拡大または縮小することもできます。

各 ノード は 2 つの値を保存します:
- 値;
- は次のノードのメモリアドレスを保持するポインタです。 最後の node には、その後に他の要素がないことを示す NULL が含まれています。

リンクされたリストの最初の要素のアドレスをポインター (ポインター) に保存します。

C プログラミング言語では、ノード を次のように記述できます。
typedef struct node
{
int number;
struct node *next;
}
node;
リンクリスト:
を作成するプロセスを見てみましょう。- ノード *list: を宣言します。

- ノードにメモリを割り当てます:
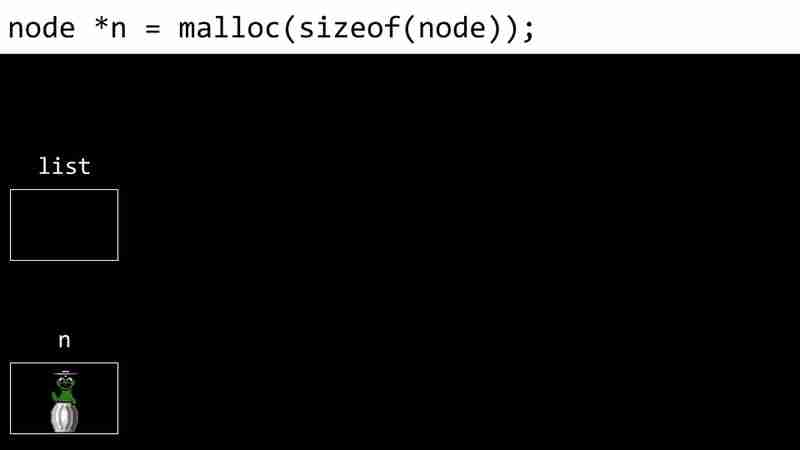
- ノードの値を入力します: n->number = 1:

- ノードの次のインデックスを NULL に設定します: n->next = NULL:

- リストを次のようにしましょう:

- 同じ順序で、値 2 を持つ新しいノードを作成します。

- 両方のノードを接続するために、n の次のインデックスをリストに設定します。

- そして最後に、リストを n に設定します。これで、2 つの要素で構成されるリンク リストが完成しました:

C プログラミング言語では、このプロセスのコードを次のように記述できます。
typedef struct node
{
int number;
struct node *next;
}
node;
リンクされたリストを使用する場合、いくつかの欠点があります。
- メモリの増加: 各要素について、要素自体の値だけでなく、次の要素へのポインタも保存する必要があります。
- インデックスによる要素の呼び出し: 配列ではインデックスによって特定の要素を呼び出すことができますが、リンクされたリストではそれは不可能です。特定の要素の位置を見つけるには、最初の要素から始めて、すべての要素を順番に調べる必要があります。
木
二分探索木 (BST) は、データの効率的な保存、検索、取得を可能にする情報構造です。
ソートされた一連の数値を与えてみましょう:

中央の要素を上部に配置し、中央の要素より小さい値を左側に、大きい値を右側に配置します。

ポインターを使用して各要素を相互に接続します。

次のコードは、BST:
を実装する方法を示しています。
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
}
node;
int main(int argc, char *argv[])
{
// Linked list'ni e'lon qilamiz
node *list = NULL;
// Har bir buyruq qatori argumenti uchun
for (int i = 1; i < argc; i++)
{
// Argumentni butun songa o‘tkazamiz
int number = atoi(argv[i]);
// Yangi element uchun xotira ajratamiz
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = number;
n->next = NULL;
// Linked list'ning boshiga node'ni qo‘shamiz
n->next = list;
list = n;
}
// Linked list elementlarini ekranga chiqaramiz
node *ptr = list;
while (ptr != NULL)
{
printf("%i\n", ptr->number);
ptr = ptr->next;
}
// Xotirani bo‘shatamiz
ptr = list;
while (ptr != NULL)
{
node *next = ptr->next;
free(ptr);
ptr = next;
}
}
各ノードにメモリを割り当て、その値が数値に格納されるため、各ノードには左右のインジケーターがあります。 print_tree 関数は、各ノードを左から右へ順次再帰的に出力します。 free_tree 関数は、データ構造のすべてのノードをメモリから再帰的に解放します。
BSTの利点:
- ダイナミズム: 要素を効率的に追加または削除できます。
- 検索効率: 各検索でツリーの半分が検索から除外されるため、BST で指定された要素を検索するのにかかる時間は O(log n) です。
BST の欠点:
- ツリーのバランスが崩れた場合(例えば、すべての要素が一列に配置された場合)、検索効率はO(n)まで低下します。
- 各ノードの左ポインタと右ポインタの両方を保存する必要があるため、コンピュータのメモリ消費量が増加します。
辞書
Dictionary は辞書のようなもので、単語とその定義、その要素 key (key) と value が含まれています。 (値)があります。
Dictionary に要素をクエリすると、O(1) 時間で要素が返されます。辞書は、ハッシュを通じてまさにこの速度を提供できます。
ハッシュ は、特別なアルゴリズムを使用して、入力配列内のデータをビットのシーケンスに変換するプロセスです。
ハッシュ関数は、任意の長さの文字列から固定長ビットの文字列を生成するアルゴリズムです。
ハッシュ テーブル は、配列とリンク リストの優れた組み合わせです。次のように想像できます:

衝突 (衝突) は、2 つの異なる入力が 1 つのハッシュ値を生成する場合です。上の画像では、衝突する要素がリンク リストとして接続されています。ハッシュ関数を改良することで、衝突の確率を下げることができます。
ハッシュ関数の簡単な例は次のとおりです。
typedef struct node
{
int number;
struct node *next;
}
node;
この記事では CS50x 2024 のソースを使用しています。
以上がCS - 第 5 週の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1419
52
1311
25
1262
29
1235
24
14
1419
52
1311
25
1262
29
1235
24

 C#対C:歴史、進化、将来の見通し
Apr 19, 2025 am 12:07 AM
C#対C:歴史、進化、将来の見通し
Apr 19, 2025 am 12:07 AM
C#とCの歴史と進化はユニークであり、将来の見通しも異なります。 1.Cは、1983年にBjarnestrostrupによって発明され、オブジェクト指向のプログラミングをC言語に導入しました。その進化プロセスには、C 11の自動キーワードとラムダ式の導入など、複数の標準化が含まれます。C20概念とコルーチンの導入、将来のパフォーマンスとシステムレベルのプログラミングに焦点を当てます。 2.C#は2000年にMicrosoftによってリリースされました。CとJavaの利点を組み合わせて、その進化はシンプルさと生産性に焦点を当てています。たとえば、C#2.0はジェネリックを導入し、C#5.0は非同期プログラミングを導入しました。これは、将来の開発者の生産性とクラウドコンピューティングに焦点を当てます。
 CとXMLの未来:新たなトレンドとテクノロジー
Apr 10, 2025 am 09:28 AM
CとXMLの未来:新たなトレンドとテクノロジー
Apr 10, 2025 am 09:28 AM
CとXMLの将来の開発動向は次のとおりです。1)Cは、プログラミングの効率とセキュリティを改善するためのC 20およびC 23の標準を通じて、モジュール、概念、CORoutinesなどの新しい機能を導入します。 2)XMLは、データ交換および構成ファイルの重要なポジションを引き続き占有しますが、JSONとYAMLの課題に直面し、XMLSchema1.1やXpath3.1の改善など、より簡潔で簡単な方向に発展します。
 Cの継続的な使用:その持久力の理由
Apr 11, 2025 am 12:02 AM
Cの継続的な使用:その持久力の理由
Apr 11, 2025 am 12:02 AM
C継続的な使用の理由には、その高性能、幅広いアプリケーション、および進化する特性が含まれます。 1)高効率パフォーマンス:Cは、メモリとハードウェアを直接操作することにより、システムプログラミングと高性能コンピューティングで優れたパフォーマンスを発揮します。 2)広く使用されている:ゲーム開発、組み込みシステムなどの分野での輝き。3)連続進化:1983年のリリース以来、Cは競争力を維持するために新しい機能を追加し続けています。
 Cマルチスレッドと並行性:並列プログラミングのマスタリング
Apr 08, 2025 am 12:10 AM
Cマルチスレッドと並行性:並列プログラミングのマスタリング
Apr 08, 2025 am 12:10 AM
cマルチスレッドと同時プログラミングのコア概念には、スレッドの作成と管理、同期と相互排除、条件付き変数、スレッドプーリング、非同期プログラミング、一般的なエラーとデバッグ技術、パフォーマンスの最適化とベストプラクティスが含まれます。 1)STD ::スレッドクラスを使用してスレッドを作成します。この例は、スレッドが完了する方法を作成し、待つ方法を示しています。 2)共有リソースを保護し、データ競争を回避するために、STD :: MutexおよびSTD :: LOCK_GUARDを使用するための同期と相互除外。 3)条件変数は、std :: condition_variableを介したスレッド間の通信と同期を実現します。 4)スレッドプールの例は、スレッドプールクラスを使用してタスクを並行して処理して効率を向上させる方法を示しています。 5)非同期プログラミングはSTD :: ASを使用します
 CおよびXML:関係とサポートの調査
Apr 21, 2025 am 12:02 AM
CおよびXML:関係とサポートの調査
Apr 21, 2025 am 12:02 AM
Cは、サードパーティライブラリ(TinyXML、PUGIXML、XERCES-Cなど)を介してXMLと相互作用します。 1)ライブラリを使用してXMLファイルを解析し、それらをC処理可能なデータ構造に変換します。 2)XMLを生成するときは、Cデータ構造をXML形式に変換します。 3)実際のアプリケーションでは、XMLが構成ファイルとデータ交換に使用されることがよくあり、開発効率を向上させます。
 Cディープダイブ:メモリ管理、ポインター、およびテンプレートの習得
Apr 07, 2025 am 12:11 AM
Cディープダイブ:メモリ管理、ポインター、およびテンプレートの習得
Apr 07, 2025 am 12:11 AM
Cのメモリ管理、ポインター、テンプレートはコア機能です。 1。メモリ管理は、新規および削除を通じてメモリを手動で割り当ててリリースし、ヒープとスタックの違いに注意を払います。 2。ポインターにより、メモリアドレスを直接操作し、注意して使用します。スマートポインターは管理を簡素化できます。 3.テンプレートは、一般的なプログラミングを実装し、コードの再利用性と柔軟性を向上させ、タイプの派生と専門化を理解する必要があります。
 Cコミュニティ:リソース、サポート、開発
Apr 13, 2025 am 12:01 AM
Cコミュニティ:リソース、サポート、開発
Apr 13, 2025 am 12:01 AM
C学習者と開発者は、Stackoverflow、RedditのR/CPPコミュニティ、CourseraおよびEDXコース、Github、Professional Consulting Services、およびCPPCONのオープンソースプロジェクトからリソースとサポートを得ることができます。 1. StackOverFlowは、技術的な質問への回答を提供します。 2。RedditのR/CPPコミュニティが最新ニュースを共有しています。 3。CourseraとEDXは、正式なCコースを提供します。 4. LLVMなどのGitHubでのオープンソースプロジェクトやスキルの向上。 5。JetBrainやPerforceなどの専門的なコンサルティングサービスは、技術サポートを提供します。 6。CPPCONとその他の会議はキャリアを助けます
 最新のCデザインパターン:スケーラブルで保守可能なソフトウェアの構築
Apr 09, 2025 am 12:06 AM
最新のCデザインパターン:スケーラブルで保守可能なソフトウェアの構築
Apr 09, 2025 am 12:06 AM
最新のCデザインモデルは、C 11以降の新機能を使用して、より柔軟で効率的なソフトウェアを構築するのに役立ちます。 1)ラムダ式とstd :: functionを使用して、オブザーバーパターンを簡素化します。 2)モバイルセマンティクスと完全な転送を通じてパフォーマンスを最適化します。 3)インテリジェントなポインターは、タイプの安全性とリソース管理を保証します。
