
 Périphériques technologiques
IA
Génération de rapports financiers multimodaux à l'aide de Llamaindex
Périphériques technologiques
IA
Génération de rapports financiers multimodaux à l'aide de Llamaindex
Génération de rapports financiers multimodaux à l'aide de Llamaindex

Dans de nombreuses applications du monde réel, les données ne sont pas purement textuelles - il peut inclure des images, des tables et des graphiques qui aident à renforcer le récit. Un générateur de rapports multimodal vous permet d'incorporer à la fois du texte et des images dans une sortie finale, ce qui rend vos rapports plus dynamiques et visuellement riches.
Cet article décrit comment construire un tel pipeline en utilisant:
- llamaindex pour orchestrer des moteurs d'analyse de documents et de requête,
- Openai Modèles linguistiques pour l'analyse textuelle,
- llamaparse pour extraire à la fois du texte et des images de documents PDF,
- Une configuration d'observabilité utilisant Arisez Phoenix (via Llamatrace) pour l'exploitation forestière et le débogage.
Le résultat final est un pipeline qui peut traiter un jeu de diapositives PDF entier - à la fois le texte et les visuels - et générer un rapport structuré contenant à la fois du texte et des images.
Objectifs d'apprentissage
- Comprendre comment intégrer le texte et les visuels pour une génération efficace de rapport financier à l'aide de pipelines multimodaux.
- Apprenez à utiliser Llamaindex et Llamaparse pour une génération de rapports financiers améliorée avec des résultats structurés.
- Explorez le llamaparse pour extraire efficacement le texte et les images des documents PDF.
- Configurez l'observabilité en utilisant Arize Phoenix (via Llamatrace) pour l'exploitation forestière et le débogage des pipelines complexes.
- Créez un moteur de requête structuré pour générer des rapports qui entrelacer les résumés de texte avec des éléments visuels.
Cet article a été publié dans le cadre du Data Science Blogathon.
Table of contents
- Overview of the Process
- Step-by-Step Implementation
- Step 1: Install and Import Dependencies
- Step 2: Set Up Observability
- Step 3: Load the data – Obtain Your Slide Deck
- Step 4: Set Up Models
- Step 5: Parse the Document with LlamaParse
- Step 6: Associate Text and Images
- Step 7: Build a Summary Index
- Step 8: Define a Structured Output Schema
- Step 9: Create a Structured Query Engine
- Conclusion
- Frequently Asked Questions
Aperçu du processus
La construction d'un générateur de rapport multimodal implique la création d'un pipeline qui intègre de manière transparente des éléments textuels et visuels à partir de documents complexes comme les PDF. Le processus commence par l'installation des bibliothèques nécessaires, telles que Llamaindex pour l'analyse de documents et l'orchestration de requête, et Llamaparse pour extraire à la fois du texte et des images. L'observabilité est établie en utilisant Arize Phoenix (via Llamatrace) pour surveiller et déboguer le pipeline.
Une fois la configuration terminée, le pipeline traite un document PDF, analysant son contenu en texte structuré et rendant des éléments visuels comme les tables et les graphiques. Ces éléments analysés sont ensuite associés, créant un ensemble de données unifié. Un SummaryIndex est conçu pour permettre des informations de haut niveau, et un moteur de requête structuré est développé pour générer des rapports qui mélangent une analyse textuelle avec des visuels pertinents. Le résultat est un générateur de rapports dynamique et interactif qui transforme les documents statiques en sorties multimodales riches adaptées aux requêtes utilisateur.
Implémentation étape par étape
Suivez ce guide détaillé pour créer un générateur de rapport multimodal, de la configuration des dépendances à la génération de sorties structurées avec du texte et des images intégrés. Chaque étape garantit une intégration transparente de Llamaindex, Llamaparse et Arize Phoenix pour un pipeline efficace et dynamique.
Étape 1: Installer et importer les dépendances
Vous aurez besoin des bibliothèques suivantes en cours d'exécution sur Python 3.9.9:
- llama-index
- LLAMA-PARSE (Pour l'analyse de l'image texte)
- llama-index-callbacks-aze-phoenix (pour observabilité / journalisation)
- NEST_ASYNCIO (Pour gérer les boucles d'événements asynchrones dans les cahiers)
!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Étape 2: Configurer l'observabilité
Nous nous intégrons à API Llamatrace - Llamacloud (Arize Phoenix). Tout d'abord, obtenez une clé API à Llamatrace.com, puis configurez des variables d'environnement pour envoyer des traces à Phoenix.
La clé de l'API Phoenix peut être obtenue en s'inscrivant à Llamatrace ici, puis accédez au panneau inférieur gauche et cliquez sur «Clés» où vous devriez trouver votre clé API.
Par exemple:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)Étape 3: Chargez les données - Obtenez votre pont de diapositives
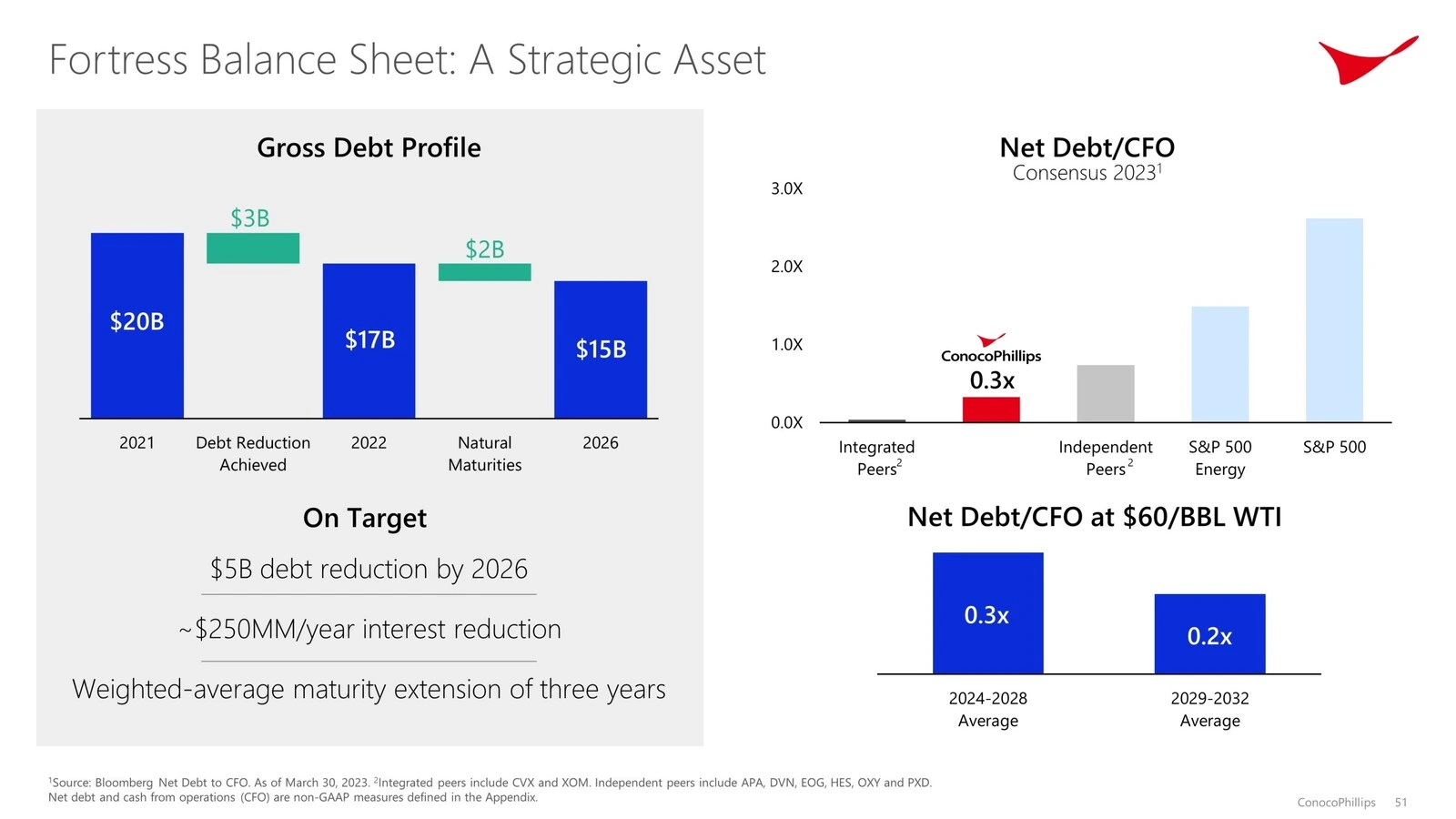
Pour la démonstration, nous utilisons le jeu de diapositives de la réunion des investisseurs de ConocoPhillips. Nous téléchargeons le PDF:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Vérifiez si le jeu de diapositives PDF se trouve dans le dossier de données, sinon le placez-le dans le dossier de données et nommez-le comme vous le souhaitez.
Étape 4: Configurer les modèles
Vous avez besoin d'un modèle d'incorporation et d'un LLM. Dans cet exemple:
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Ensuite, vous les enregistrez comme par défaut pour Llamaindex:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm
Étape 5: Analyser le document avec Llamaparse
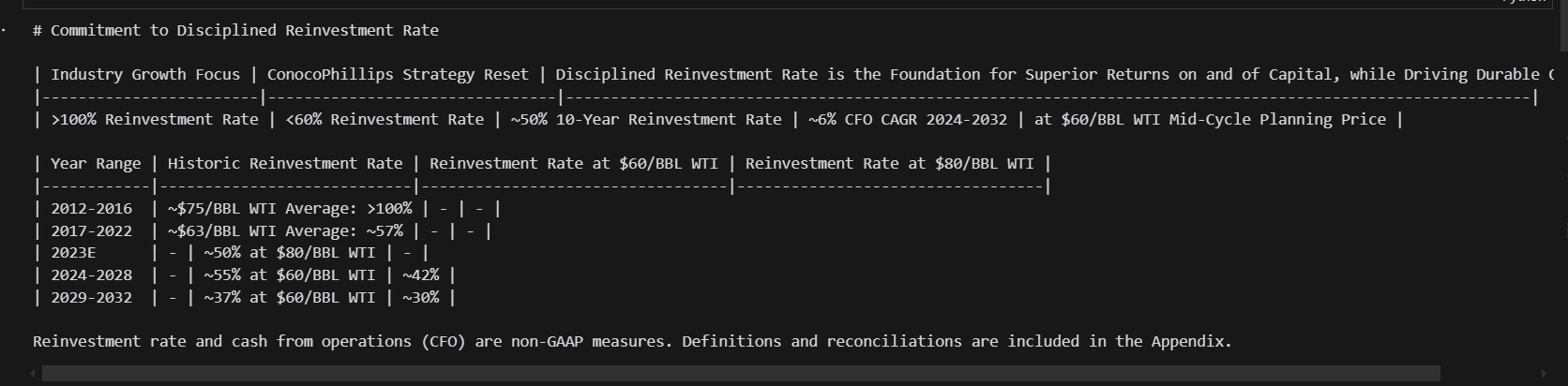
llamaparse peut extraire du texte et des images (via un grand modèle multimodal). Pour chaque page PDF, il revient:
- Texte de marque (avec des tables, des en-têtes, des puces, etc.)
- Une image rendue (enregistrée localement)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])
print(md_json_list[1].keys())

!pip install -U llama-index-callbacks-arize-phoenix import nest_asyncio nest_asyncio.apply()
Étape 6: Associer le texte et les images
Nous créons une liste d'objets TextNode (structure de données de Llamaindex) pour chaque page. Chaque nœud a des métadonnées sur le numéro de page et le chemin du fichier d'image correspondant:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
) 
Étape 7: Créez un indice de résumé
Avec ces nœuds de texte en main, vous pouvez créer un résumé deindex:
import os
import requests
# Create the directories (ignore errors if they already exist)
os.makedirs("data", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/files/2023-conocophillips-aim-presentation.pdf"
# Download and save to data/conocophillips.pdf
response = requests.get(url)
with open("data/conocophillips.pdf", "wb") as f:
f.write(response.content)
print("PDF downloaded to data/conocophillips.pdf")Le Résumé de l'Index garantit que vous pouvez facilement récupérer ou générer des résumés de haut niveau sur l'ensemble du document.
Étape 8: Définissez un schéma de sortie structuré
Notre pipeline vise à produire une sortie finale avec des blocs de texte entrelacés et des blocs d'image. Pour cela, nous créons un modèle pydontique personnalisé (en utilisant le V2 pyndante ou assurant la compatibilité) avec deux types de blocs— textblock et ImageBlock - et un modèle parent Reportoutput :
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model="text-embedding-3-large") llm = OpenAI(model="gpt-4o")
Le point clé: reportoutput nécessite au moins un bloc d'image, en s'assurant que la réponse finale est multimodale.
Étape 9: Créez un moteur de requête structuré
llamaindex vous permet d'utiliser un «LLM structuré» (c'est-à-dire un LLM dont la sortie est automatiquement analysée dans un schéma spécifique). Voici comment:
from llama_index.core import Settings Settings.embed_model = embed_model Settings.llm = llm

print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("data/conocophillips.pdf")
md_json_list = md_json_objs[0]["pages"] 
print(md_json_list[10]["md"])

Conclusion
En combinant Llamaindex, Llamaparse et OpenAI, vous pouvez construire un générateur de rapports multimodal qui traite un PDF entier (avec du texte, des tables et des images) en une sortie structurée. Cette approche offre des résultats plus riches et plus informatifs - expressément ce dont les parties prenantes ont besoin pour glaner des informations critiques à partir de documents d'entreprise ou techniques complexes.
N'hésitez pas à adapter ce pipeline à vos propres documents, à ajouter une étape de récupération pour les grandes archives ou à intégrer des modèles spécifiques au domaine pour analyser les images sous-jacentes. Avec les fondations présentées ici, vous pouvez créer des rapports dynamiques, interactifs et visuellement riches qui vont bien au-delà des simples requêtes textuelles.
Un grand merci à Jerry Liu de Llamaindex pour avoir développé ce pipeline incroyable.
Les plats clés
- Transformez les PDF avec du texte et des visuels en formats structurés tout en préservant l'intégrité du contenu original en utilisant Llamaparse et Llamaindex.
- générer des rapports enrichis visuellement qui entrelacent des résumés textuels et des images pour une meilleure compréhension contextuelle.
- La génération de rapports financiers peut être améliorée en intégrant à la fois des éléments de texte et visuels pour des sorties plus perspicaces et dynamiques.
- Tirer parti de Llamaindex et Llamaparse rationalise le processus de génération de rapports financiers, garantissant des résultats précis et structurés.
- Récupérer les documents pertinents avant le traitement pour optimiser la génération de rapports pour les grandes archives.
- Améliorer l'analyse visuelle, incorporer des analyses spécifiques au graphique et combiner des modèles pour le traitement du texte et de l'image pour des informations plus profondes.
Les questions fréquemment posées
Q1. Qu'est-ce qu'un «générateur de rapports multimodal»?a. Un générateur de rapports multimodal est un système qui produit des rapports contenant plusieurs types de contenu - de texte et d'images, dans une sortie cohérente. Dans ce pipeline, vous analysez un PDF en éléments textuels et visuels, puis les combinez en un seul rapport final.
Q2. Pourquoi ai-je besoin d'installer Llama-Index-Callbacks-aze-Phoenix et de configurer l'observabilité?a. Des outils d'observabilité comme Arize Phoenix (via Llamatrace) vous permettent de surveiller et de déboguer le comportement du modèle, de suivre les requêtes et les réponses et d'identifier les problèmes en temps réel. Il est particulièrement utile pour traiter des documents importants ou complexes et plusieurs étapes basées sur LLM.
Q3. Pourquoi utiliser Llamaparse au lieu d'un extracteur de texte PDF standard?a. La plupart des extracteurs de texte PDF ne gèrent que du texte brut, perdant souvent le formatage, les images et les tables. Llamaparse est capable d'extraire à la fois du texte et des images (images de page rendues), ce qui est crucial pour construire des pipelines multimodaux où vous devez vous référer à des tables, des graphiques ou d'autres visuels.
Q4. Quel est l'avantage de l'utilisation d'un résumé de l'Index?a. SummaryIndex est une abstraction Llamaindex qui organise votre contenu (par exemple, les pages d'un PDF) afin qu'il puisse générer rapidement des résumés complets. Il aide à recueillir des informations de haut niveau à partir de longs documents sans avoir à les repousser manuellement ou à exécuter une requête de récupération pour chaque élément de données.
Q5. Comment puis-je m'assurer que le rapport final comprend au moins un bloc d'image?a. Dans le modèle Pyndantique ReportOutput, appliquez que la liste des blocs nécessite au moins un ImageBlock. Ceci est indiqué dans votre invite de système et votre schéma. Le LLM doit suivre ces règles, ou il ne produira pas de sortie structurée valide.
Le média présenté dans cet article ne appartient pas à l'analyse vidhya et est utilisé à la discrétion de l'auteur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Tout en travaillant sur une IA agentique, les développeurs se retrouvent souvent à naviguer dans les compromis entre la vitesse, la flexibilité et l'efficacité des ressources. J'ai exploré le cadre de l'IA agentique et je suis tombé sur Agno (plus tôt c'était Phi-
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
La version comprend trois modèles distincts, GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano, signalant une évolution vers des optimisations spécifiques à la tâche dans le paysage du modèle grand langage. Ces modèles ne remplacent pas immédiatement les interfaces orientées utilisateur comme
 Au-delà du drame de lama: 4 nouvelles références pour les modèles de grande langue
Apr 14, 2025 am 11:09 AM
Au-delà du drame de lama: 4 nouvelles références pour les modèles de grande langue
Apr 14, 2025 am 11:09 AM
Benchmarks en difficulté: une étude de cas de lama Début avril 2025, Meta a dévoilé sa suite de modèles Llama 4, avec des métriques de performance impressionnantes qui les ont placés favorablement contre des concurrents comme GPT-4O et Claude 3.5 Sonnet. Au centre du launc
 Nouveau cours court sur les modèles d'intégration par Andrew Ng
Apr 15, 2025 am 11:32 AM
Nouveau cours court sur les modèles d'intégration par Andrew Ng
Apr 15, 2025 am 11:32 AM
Déverrouiller la puissance des modèles d'intégration: une plongée profonde dans le nouveau cours d'Andrew Ng Imaginez un avenir où les machines comprennent et répondent à vos questions avec une précision parfaite. Ce n'est pas de la science-fiction; Grâce aux progrès de l'IA, cela devient un R
 Comment les jeux de TDAH, les outils de santé et les chatbots d'IA transforment la santé mondiale
Apr 14, 2025 am 11:27 AM
Comment les jeux de TDAH, les outils de santé et les chatbots d'IA transforment la santé mondiale
Apr 14, 2025 am 11:27 AM
Un jeu vidéo peut-il faciliter l'anxiété, se concentrer ou soutenir un enfant atteint de TDAH? Au fur et à mesure que les défis de la santé augmentent à l'échelle mondiale - en particulier chez les jeunes - les innovateurs se tournent vers un outil improbable: les jeux vidéo. Maintenant l'un des plus grands divertissements du monde Indus
 Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simuler les lancements de fusée avec Rocketpy: un guide complet Cet article vous guide à travers la simulation des lancements de fusées haute puissance à l'aide de Rocketpy, une puissante bibliothèque Python. Nous couvrirons tout, de la définition de composants de fusée à l'analyse de Simula
 Google dévoile la stratégie d'agent la plus complète au cloud prochain 2025
Apr 15, 2025 am 11:14 AM
Google dévoile la stratégie d'agent la plus complète au cloud prochain 2025
Apr 15, 2025 am 11:14 AM
Gemini comme fondement de la stratégie d'IA de Google Gemini est la pierre angulaire de la stratégie d'agent AI de Google, tirant parti de ses capacités multimodales avancées pour traiter et générer des réponses à travers le texte, les images, l'audio, la vidéo et le code. Développé par Deepm
