

Normalisation par lots: théorie et implémentation TensorFlow

La formation en réseau neuronal profond fait souvent face à des obstacles comme la disparition / explosion de gradients et le changement de covariable interne, le ralentissement de l'entraînement et le gêne d'apprentissage. Les techniques de normalisation offrent une solution, la normalisation par lots (BN) étant particulièrement importante. BN accélère la convergence, améliore la stabilité et améliore la généralisation dans de nombreuses architectures d'apprentissage en profondeur. Ce tutoriel explique la mécanique de BN, ses fondements mathématiques et la mise en œuvre de TensorFlow / Keras.
La normalisation dans l'apprentissage automatique standardise les données d'entrée, en utilisant des méthodes telles que la mise à l'échelle Min-Max, la normalisation des scores Z et les transformations de journal en fonctionnalités de sauvetage. Cela atténue les effets aberrants, améliore la convergence et garantit une comparaison des fonctionnalités équitables. Les données normalisées garantissent une contribution aux caractéristiques égales au processus d'apprentissage, empêchant les fonctionnalités à plus grande échelle de dominer et de conduisant à des performances sous-optimales du modèle. Il permet au modèle d'identifier plus efficacement les modèles significatifs.
Les défis de formation en profondeur comprennent:
- Shift de covariable interne: Les changements de distribution des activations entre les couches pendant la formation, l'adaptation et l'apprentissage.
- Les gradients de disparition / explosion: Les gradients deviennent trop petits ou grands pendant la rétropropagation, entravant des mises à jour efficaces de poids.
- Sensibilité d'initialisation: Les poids initiaux influencent fortement l'entraînement; Une mauvaise initialisation peut entraîner une convergence lente ou échouée.
La normalisation par lots les aborde en normalisant les activations au sein de chaque mini-lots, en stabilisant la formation et en améliorant les performances du modèle.
La normalisation par lots normalise les activations d'une couche dans un mini-lot pendant l'entraînement. Il calcule la moyenne et la variance des activations pour chaque fonctionnalité, puis se normalise en utilisant ces statistiques. Les paramètres apprenables (γ et β) sont à l'échelle et décalent les activations normalisées, permettant au modèle d'apprendre la distribution d'activation optimale.

Source: Yintai Ma et Diego Klabjan.
BN est généralement appliqué après la transformation linéaire d'une couche (par exemple, la multiplication matricielle dans les couches ou la convolution entièrement connectées dans les couches convolutionnelles) et avant la fonction d'activation non linéaire (par exemple, RELU). Les composants clés sont les statistiques de mini-lots (moyenne et variance), la normalisation et la mise à l'échelle / décalage avec des paramètres apprenables.
BN aborde le décalage de covariable interne en normalisant les activations au sein de chaque mini-lots, ce qui rend les entrées aux couches suivantes plus stables. Cela permet une convergence plus rapide avec des taux d'apprentissage plus élevés et réduit la sensibilité à l'initialisation. Il régulise également, empêchant le sur-ajustement en réduisant la dépendance à des modèles d'activation spécifiques.
Mathématiques de la normalisation par lots:
BN fonctionne différemment pendant la formation et l'inférence.
Formation:
- Normalisation: Moyenne (μ B ) et la variance (σ b 2 ) sont calculées pour chaque caractéristique dans un mini-dossier:
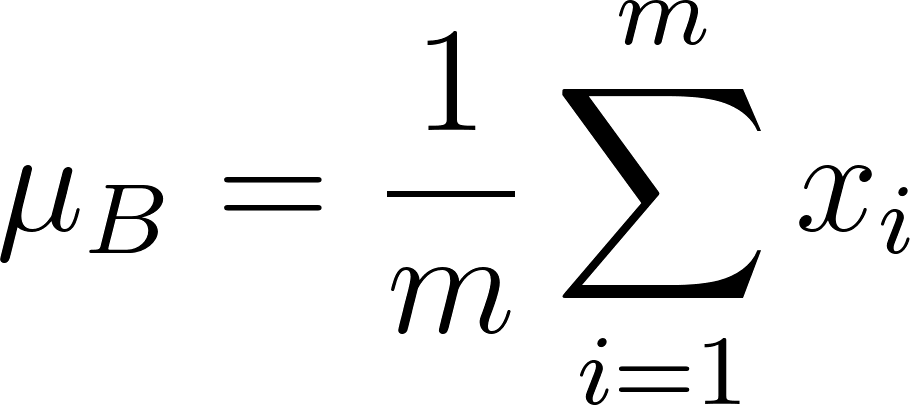

Les activations (x i ) sont normalisées:
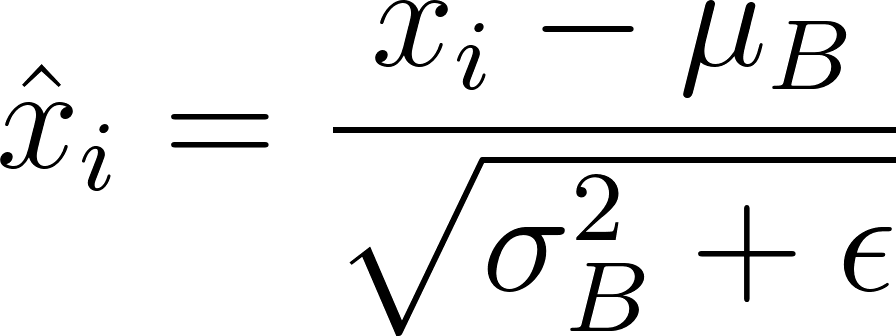
(ε est une petite constante pour la stabilité numérique).
- Échelle et décalage: Paramètres apprenables γ et β Scale and Shift:

Inférence: Les statistiques par lots sont remplacées par des statistiques de fonctionnement (moyenne et variance) calculées pendant la formation en utilisant une moyenne mobile (facteur de momentum α):


Ces statistiques de course et les γ et β appris sont utilisés pour la normalisation pendant l'inférence.
Implémentation TensorFlow:
import tensorflow as tf
from tensorflow import keras
# Load and preprocess MNIST data (as described in the original text)
# ...
# Define the model architecture
model = keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(64, (3, 3), activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation='softmax')
])
# Compile and train the model (as described in the original text)
# ...Considérations d'implémentation:
- Placement: après transformations linéaires et avant les fonctions d'activation.
- Taille du lot: Les tailles de lots plus grandes fournissent des statistiques de lots plus précises.
- régularisation: bn introduit un effet de régularisation.
Limites et défis:
- Architectures non convolutionnelles: l'efficacité de BN est réduite dans les RNN et les transformateurs.
- Tailles de petites lots: Statistiques de lots moins fiables.
- frais généraux de calcul: Augmentation de la mémoire et du temps de formation.
Limitations d'atténuation: La normalisation du lot adaptative, la normalisation virtuelle des lots et les techniques de normalisation hybride peuvent répondre à certaines limitations.
Variants et extensions: La normalisation de la couche, la normalisation du groupe, la normalisation des instances, la renormalisation par lots et la normalisation du poids offrent des alternatives ou des améliorations en fonction des besoins spécifiques.
Conclusion: La normalisation par lots est une technique puissante améliorant la formation en réseau neuronal profond. N'oubliez pas ses avantages, ses détails de mise en œuvre et ses limites, et considérez ses variantes pour des performances optimales dans vos projets.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1677
1677
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Tout en travaillant sur une IA agentique, les développeurs se retrouvent souvent à naviguer dans les compromis entre la vitesse, la flexibilité et l'efficacité des ressources. J'ai exploré le cadre de l'IA agentique et je suis tombé sur Agno (plus tôt c'était Phi-
 Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
La version comprend trois modèles distincts, GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano, signalant une évolution vers des optimisations spécifiques à la tâche dans le paysage du modèle grand langage. Ces modèles ne remplacent pas immédiatement les interfaces orientées utilisateur comme
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simuler les lancements de fusée avec Rocketpy: un guide complet Cet article vous guide à travers la simulation des lancements de fusées haute puissance à l'aide de Rocketpy, une puissante bibliothèque Python. Nous couvrirons tout, de la définition de composants de fusée à l'analyse de Simula
 Deepcoder-14b: la compétition open source à O3-MinI et O1
Apr 26, 2025 am 09:07 AM
Deepcoder-14b: la compétition open source à O3-MinI et O1
Apr 26, 2025 am 09:07 AM
Dans un développement significatif pour la communauté de l'IA, Agetica et ensemble AI ont publié un modèle de codage d'IA open source nommé Deepcoder-14b. Offrir des capacités de génération de code à égalité avec des concurrents à source fermée comme OpenAI
 L'invite: Chatgpt génère de faux passeports
Apr 16, 2025 am 11:35 AM
L'invite: Chatgpt génère de faux passeports
Apr 16, 2025 am 11:35 AM
Le géant de la puce Nvidia a déclaré lundi qu'il commencerait à fabriquer des superordinateurs d'IA - des machines qui peuvent traiter de grandes quantités de données et exécuter des algorithmes complexes - entièrement aux États-Unis pour la première fois. L'annonce intervient après le président Trump Si
 Gen-4 de la piste AI: Comment Ai Montage peut-il aller au-delà de l'absurdité
Apr 16, 2025 am 11:45 AM
Gen-4 de la piste AI: Comment Ai Montage peut-il aller au-delà de l'absurdité
Apr 16, 2025 am 11:45 AM
L'industrie cinématographique, aux côtés de tous les secteurs créatifs, du marketing numérique aux médias sociaux, se dresse à un carrefour technologique. Alors que l'intelligence artificielle commence à remodeler tous les aspects de la narration visuelle et à changer le paysage du divertissement
 Guy Peri aide à savourer l'avenir de McCormick grâce à la transformation des données
Apr 19, 2025 am 11:35 AM
Guy Peri aide à savourer l'avenir de McCormick grâce à la transformation des données
Apr 19, 2025 am 11:35 AM
Guy Peri est le principal officier des informations et du numérique de McCormick. Bien que seulement sept mois dans son rôle, Peri fait rapidement progresser une transformation complète des capacités numériques de l'entreprise. Sa concentration sur la carrière sur les données et l'analyse informe
