
 Périphériques technologiques
IA
Tutoriel Deepchecks: Test d'apprentissage automatique automatisant
Périphériques technologiques
IA
Tutoriel Deepchecks: Test d'apprentissage automatique automatisant
Tutoriel Deepchecks: Test d'apprentissage automatique automatisant

Ce didacticiel explore les profondeurs des tests de validation des données et les tests de modèle d'apprentissage automatique, et exploite les actions GitHub pour les tests automatisés et la création d'artefacts. Nous couvrirons les principes de test d'apprentissage automatique, les fonctionnalités de profondeur et un flux de travail automatisé complet.

Image par auteur
Comprendre les tests d'apprentissage automatique
L'apprentissage automatique efficace nécessite des tests rigoureux au-delà des métriques de précision simple. Nous devons évaluer l'équité, la robustesse et les considérations éthiques, notamment la détection des biais, les faux positifs / négatifs, les mesures de performance, le débit et l'alignement avec l'éthique de l'IA. Cela implique des techniques telles que la validation des données, la validation croisée, le calcul des scores F1, l'analyse de la matrice de confusion et la détection de dérive (données et prédiction). Le fractionnement des données (train / test / validation) est crucial pour une évaluation fiable du modèle. L'automatisation de ce processus est la clé pour construire des systèmes d'IA fiables.
Pour les débutants, les principes fondamentaux de l'apprentissage automatique avec Python Skill Track offrent une base solide.
Deepchecks, une bibliothèque Python open source, simplifie des tests d'apprentissage automatique complets. Il propose des vérifications intégrées pour les performances du modèle, l'intégrité des données et la distribution, prenant en charge la validation continue pour un déploiement de modèle fiable.
Début avec Deepchecks
Installez les profondeurs en utilisant PIP:
pip install deepchecks --upgrade -q
Chargement et préparation des données (ensemble de données de prêt)
Nous utiliserons l'ensemble de données de données de prêt à partir de Datacamp.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head() 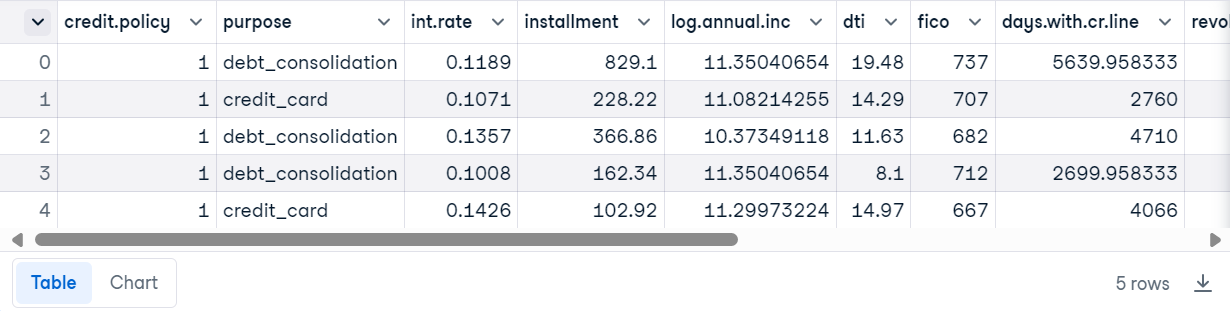
Créer un ensemble de données Deepchecks:
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Test d'intégrité des données
La suite d'intégrité des données de Deepchecks effectue des vérifications automatisées.
from deepchecks.tabular.suites import data_integrity integ_suite = data_integrity() suite_result = integ_suite.run(deep_loan_data) suite_result.show_in_iframe() # Use show_in_iframe for DataLab compatibility
Cela génère un rapport couvrant: corrélation d'étiquette de fonctionnalité, corrélation de fonction de fonctionnalité, vérification de valeur unique, détection spéciale des caractères, analyse de valeur nul, cohérence du type de données, décontrats de cordes, détection en double, validation de la longueur des chaînes, étiquettes contradictoires et détection des valeurs aberrantes.
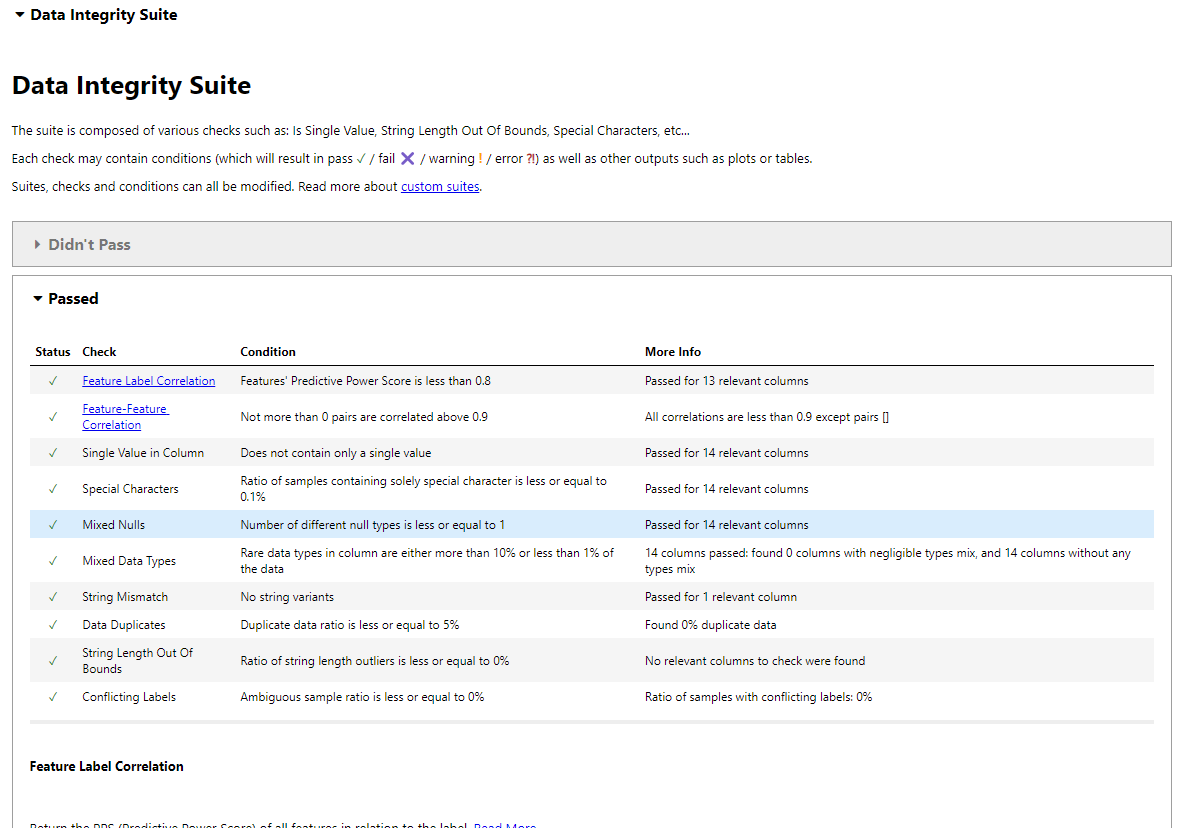
Enregistrer le rapport:
suite_result.save_as_html()
Exécution de test individuel
Pour l'efficacité, exécutez des tests individuels:
from deepchecks.tabular.checks import IsSingleValue, DataDuplicates result = IsSingleValue().run(deep_loan_data) print(result.value) # Unique value counts per column result = DataDuplicates().run(deep_loan_data) print(result.value) # Duplicate sample count
Évaluation du modèle avec Deepchecks
Nous allons entraîner un modèle d'ensemble (régression logistique, forêt aléatoire, bayes naïve gaussien) et l'évaluer à l'aide de profondeurs.
pip install deepchecks --upgrade -q
Le rapport d'évaluation du modèle comprend: les courbes ROC, les performances faibles du segment, la détection des fonctionnalités inutilisées, la comparaison des performances des tests de train, l'analyse de la dérive de prédiction, les comparaisons simples du modèle, le temps d'inférence du modèle, les matrices de confusion, et plus encore.

Sortie JSON:
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()Exemple de test individuel (dérive d'étiquette):
from sklearn.model_selection import train_test_split from deepchecks.tabular import Dataset label_col = 'not.fully.paid' deep_loan_data = Dataset(loan_data, label=label_col, cat_features=["purpose"])
Automatisation avec les actions GitHub
Cette section détaille la configuration d'un flux de travail GitHub Actions pour automatiser la validation des données et les tests de modèle. Le processus consiste à créer un référentiel, à ajouter des données et des scripts Python (data_validation.py, train_validation.py) et de configurer un flux de travail GitHub Actions (main.yml) pour exécuter ces scripts et enregistrer les résultats sous forme d'artefacts. Des étapes détaillées et des extraits de code sont fournis dans l'entrée d'origine. Reportez-vous au référentiel kingabzpro/Automating-Machine-Learning-Testing pour un exemple complet. Le flux de travail utilise les actions actions/checkout, actions/setup-python et actions/upload-artifact.
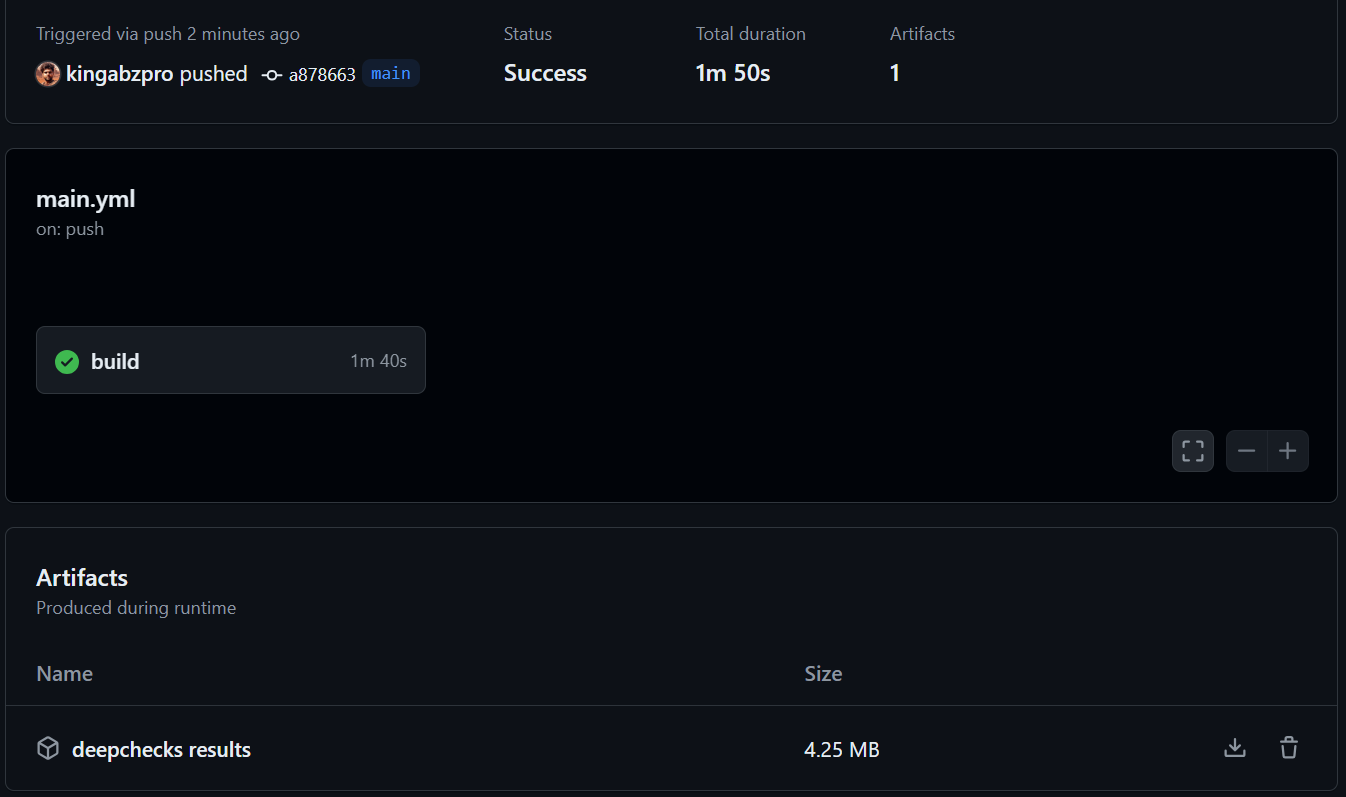
Conclusion
Les tests d'apprentissage automatique automatisant à l'aide de Deepchecks et des actions GitHub améliorent considérablement l'efficacité et la fiabilité. La détection précoce des problèmes améliore la précision du modèle et l'équité. Ce tutoriel fournit un guide pratique pour mettre en œuvre ce flux de travail, permettant aux développeurs de créer des systèmes d'IA plus robustes et dignes de confiance. Considérez le spécialiste de l'apprentissage automatique avec une piste de carrière Python pour un développement ultérieur dans ce domaine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1677
1677
 14
1431
52
1334
25
1280
29
1257
24
14
1431
52
1334
25
1280
29
1257
24

 Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Comment construire des agents d'IA multimodaux à l'aide d'AGNO Framework?
Apr 23, 2025 am 11:30 AM
Tout en travaillant sur une IA agentique, les développeurs se retrouvent souvent à naviguer dans les compromis entre la vitesse, la flexibilité et l'efficacité des ressources. J'ai exploré le cadre de l'IA agentique et je suis tombé sur Agno (plus tôt c'était Phi-
 Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
Openai change de mise au point avec GPT-4.1, priorise le codage et la rentabilité
Apr 16, 2025 am 11:37 AM
La version comprend trois modèles distincts, GPT-4.1, GPT-4.1 Mini et GPT-4.1 Nano, signalant une évolution vers des optimisations spécifiques à la tâche dans le paysage du modèle grand langage. Ces modèles ne remplacent pas immédiatement les interfaces orientées utilisateur comme
 Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique Vidhya
Apr 17, 2025 am 11:43 AM
Instruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulation et analyse de lancement de fusées à l'aide de Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simuler les lancements de fusée avec Rocketpy: un guide complet Cet article vous guide à travers la simulation des lancements de fusées haute puissance à l'aide de Rocketpy, une puissante bibliothèque Python. Nous couvrirons tout, de la définition de composants de fusée à l'analyse de Simula
 Deepcoder-14b: la compétition open source à O3-MinI et O1
Apr 26, 2025 am 09:07 AM
Deepcoder-14b: la compétition open source à O3-MinI et O1
Apr 26, 2025 am 09:07 AM
Dans un développement significatif pour la communauté de l'IA, Agetica et ensemble AI ont publié un modèle de codage d'IA open source nommé Deepcoder-14b. Offrir des capacités de génération de code à égalité avec des concurrents à source fermée comme OpenAI
 L'invite: Chatgpt génère de faux passeports
Apr 16, 2025 am 11:35 AM
L'invite: Chatgpt génère de faux passeports
Apr 16, 2025 am 11:35 AM
Le géant de la puce Nvidia a déclaré lundi qu'il commencerait à fabriquer des superordinateurs d'IA - des machines qui peuvent traiter de grandes quantités de données et exécuter des algorithmes complexes - entièrement aux États-Unis pour la première fois. L'annonce intervient après le président Trump Si
 Une invite peut contourner toutes les garanties de LLM majeures
Apr 25, 2025 am 11:16 AM
Une invite peut contourner toutes les garanties de LLM majeures
Apr 25, 2025 am 11:16 AM
Les recherches révolutionnaires de Hiddenlayer expose une vulnérabilité critique dans les principaux modèles de grande langue (LLM). Leurs résultats révèlent une technique de contournement universelle, surnommée "Policy Puppetry", capable de contourner presque tous les principaux LLM
 Guy Peri aide à savourer l'avenir de McCormick grâce à la transformation des données
Apr 19, 2025 am 11:35 AM
Guy Peri aide à savourer l'avenir de McCormick grâce à la transformation des données
Apr 19, 2025 am 11:35 AM
Guy Peri est le principal officier des informations et du numérique de McCormick. Bien que seulement sept mois dans son rôle, Peri fait rapidement progresser une transformation complète des capacités numériques de l'entreprise. Sa concentration sur la carrière sur les données et l'analyse informe
