
 Technology peripherals
AI
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world
Technology peripherals
AI
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world
Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world

When developing robot learning methods, if large and diverse data sets can be integrated and combined with powerful expressive models (such as Transformer), then it is expected to develop generalization capabilities and widely applicable strategies so that robots can learn to handle a variety of different tasks well. For example, these strategies allow robots to follow natural language instructions, perform multi-stage behaviors, adapt to various environments and goals, and even apply to different robot forms.
However, the powerful models that have recently appeared in the field of robot learning are all trained using supervised learning methods. Therefore, the performance of the resulting strategy is limited by the extent to which human demonstrators can provide high-quality demonstration data. There are two reasons for this restriction.
- First, we want robotic systems to be more proficient than human teleoperators, leveraging the full potential of the hardware to complete tasks quickly, smoothly, and reliably.
- Second, we hope that the robot system will be better at automatically accumulating experience, rather than relying entirely on high-quality demonstrations.
In principle, reinforcement learning can provide these two abilities at the same time.
There have been some promising developments recently, showing that large-scale robot reinforcement learning can be successful in a variety of application scenarios, such as robots’ grabbing and stacking capabilities, and learning with human-specified Different tasks with rewards, learning multi-task strategies, learning goal-based strategies, and robot navigation. However, research shows that if reinforcement learning is used to train powerful models such as Transformer, it is more difficult to effectively instantiate at scale
Google DeepMind recently proposed Q-Transformer, which aims to Combining large-scale robot learning based on diverse real-world data sets with a modern policy architecture based on powerful Transformers

- Thesis: https://q-transformer.github.io/assets/q-transformer.pdf
- Project: https: //q-transformer.github.io/
Although in principle, using Transformer directly to replace the existing architecture ( Such as ResNets or smaller convolutional neural networks) are conceptually simple, but designing a scheme that can effectively utilize this architecture is very difficult. Large models are only effective when they can use large and diverse data sets - small, narrow models do not require and benefit from this ability
Although there have been previous studies using simulated data to create such datasets, the most representative data comes from the real world.
Therefore, DeepMind stated that the focus of this research is to utilize Transformer through offline reinforcement learning and integrate previously collected large data sets
Offline reinforcement Learning methods are trained using previously available data, with the goal of deriving the most effective possible strategy based on a given data set. Of course, this dataset can also be enhanced with additional automatically collected data, but the training process is separate from the data collection process, which provides an additional workflow for large-scale robotic applications
In terms of using the Transformer model to implement reinforcement learning, another big problem is designing a reinforcement learning system that can effectively train this model. Effective offline reinforcement learning methods usually perform Q-function estimation through time-difference updates. Since Transformer models a discrete token sequence, the Q function estimation problem can be converted into a discrete token sequence modeling problem, and an appropriate loss function can be designed for each token in the sequence.
The method adopted by DeepMind is a discretization scheme by dimension. This is to avoid the exponential explosion of the action base. Specifically, each dimension of the action space is treated as an independent time step in reinforcement learning. Different bins in the discretization correspond to different actions. This dimensionally discretized scheme allows us to use a simple discrete action Q-learning method with a conservative regularizer to handle distribution transitions
DeepMind proposes a specialized A regularizer that aims to minimize the value of unused actions. Research shows that this method can effectively learn a narrow range of demo-like data, and can also learn a wider range of data with exploration noise
Finally, they also used a hybrid update mechanism that combined Monte Carlo and n-step regression with temporal difference backups. The results show that this approach can improve the performance of Transformer-based offline reinforcement learning methods on large-scale robot learning problems.
The main contribution of this research is Q-Transformer, which is a method for offline reinforcement learning of robots based on the Transformer architecture. Q-Transformer tokenizes Q-values by dimension and has been successfully applied to large-scale and diverse robotics datasets, including real-world data. Figure 1 shows the components of Q-Transformer

DeepMind conducted experimental evaluations, including simulation experiments and large-scale real-world experiments, aiming for rigorous comparison and actual verification. Among them, we adopted a large-scale text-based multi-task strategy for learning and verified the effectiveness of Q-Transformer
In real-world experiments, the data set they used contained 38,000 successful demonstrations and 20,000 failed automatically collected scenarios. The data was collected by 13 robots on more than 700 tasks. Q-Transformer outperforms previously proposed architectures for large-scale robotic reinforcement learning, as well as Transformer-based models such as the previously proposed Decision Transformer.
Method overview
In order to use Transformer for Q learning, DeepMind takes the approach of discretizing and autoregressive processing of the action space
To learn a Q function using TD learning, the classic method is based on the Bellman update rule
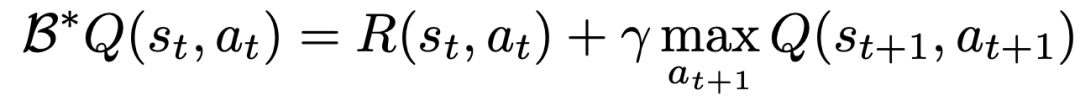
##The researchers modified the Bellman update so that it can be performed for each action dimension by converting the original MDP of the problem into an MDP in which each action dimension is treated as a step of Q-learning.
Specifically, for a given action dimension d_A, the new Bellman update rule can be expressed as:
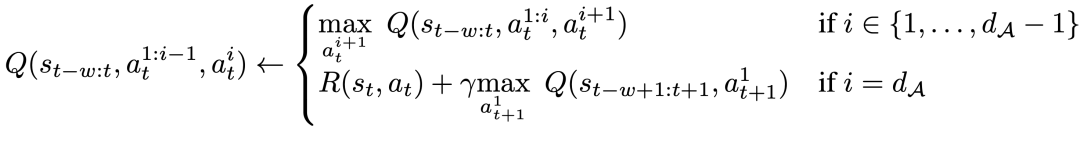
This means that for each intermediate action dimension, maximize the next action dimension given the same state, and for the last action dimension, use the next state's An action dimension. This decomposition ensures that the maximization in the Bellman update remains tractable, while also ensuring that the original MDP problem can still be solved.
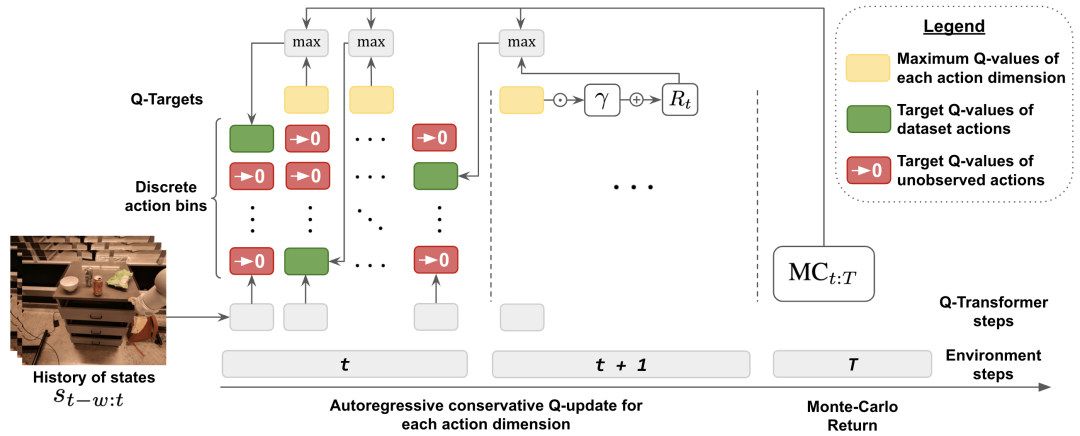
In order to take into account distribution changes during the offline learning process, DeepMind also introduced a simple regularization technology, It is to minimize the value of unseen actions.
In order to speed up learning, they also used the Monte Carlo return method. This approach not only uses return-to-go for a given episode, but also uses n-step returns that can skip dimensionally maximized
Experimental results
In experiments, DeepMind evaluated Q-Transformer, covering a range of real-world tasks. At the same time, they also limited the data to only 100 human demos per task
In the demos, in addition to the demos, they also added automatically collected failures Event fragments to create a dataset. This dataset contains 38,000 positive examples from the demo and 20,000 automatically collected negative examples
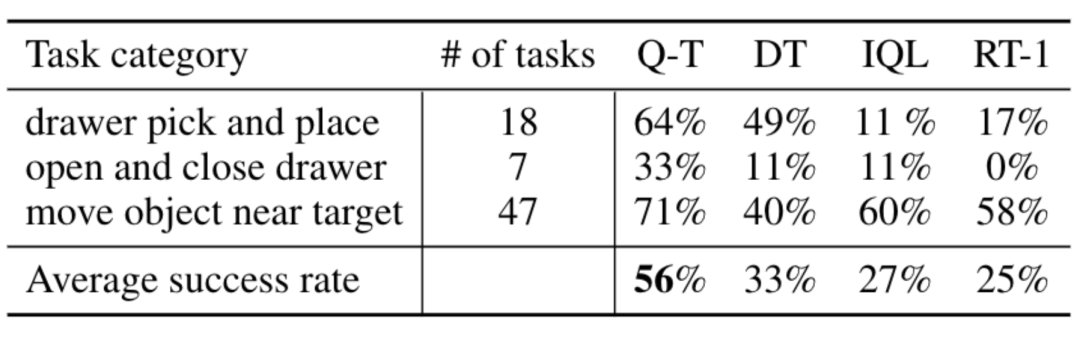

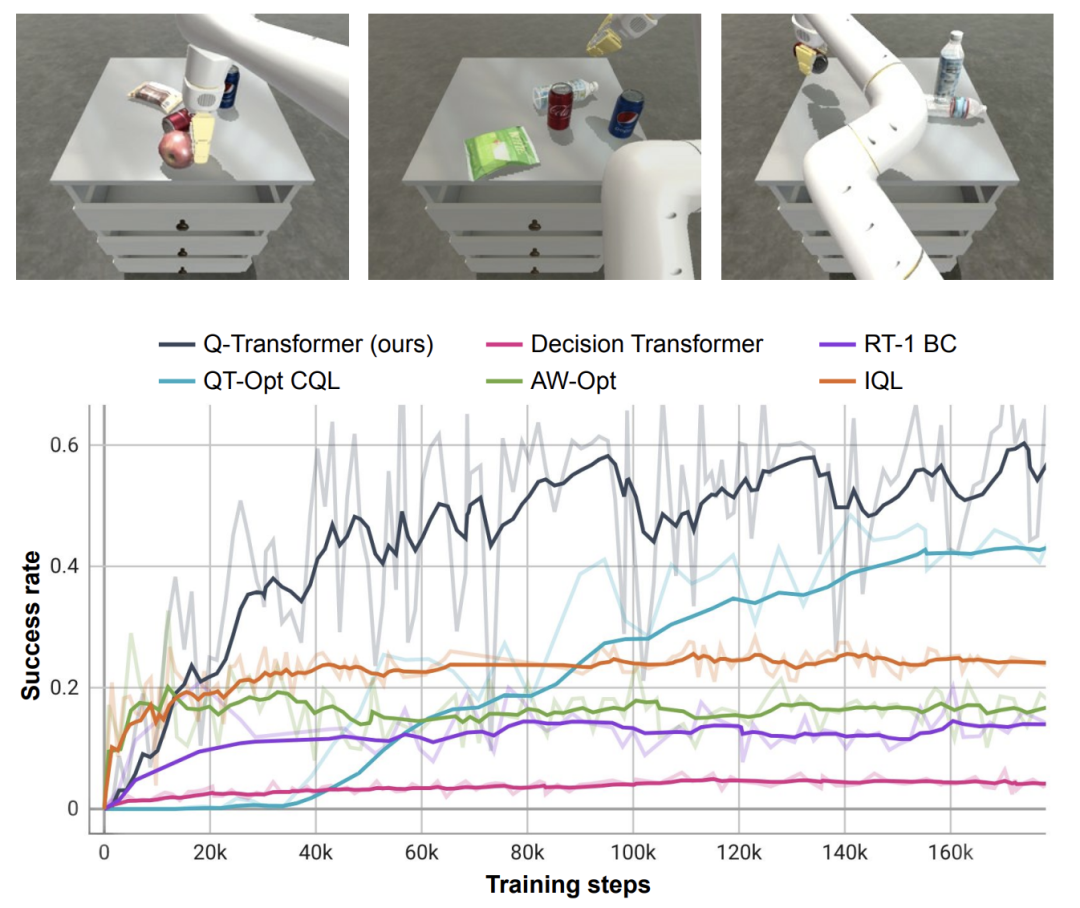
Compared to baseline methods such as RT-1, IQL, and Decision Transformer (DT), Q-Transformer can effectively utilize automatic event fragments to significantly improve its ability to use skills, including from the drawer Pick up and place objects, move objects near the target, and open and close drawers.
The researchers also tested the newly proposed method on a difficult simulated object retrieval task - in this task, only about 8% of the data were positive examples. The rest are noisy negative examples.
In this task, Q-learning methods such as QT-Opt, IQL, AW-Opt and Q-Transformer usually perform better because they are able to leverage dynamic programming to learn the policy, And use negative examples to optimize
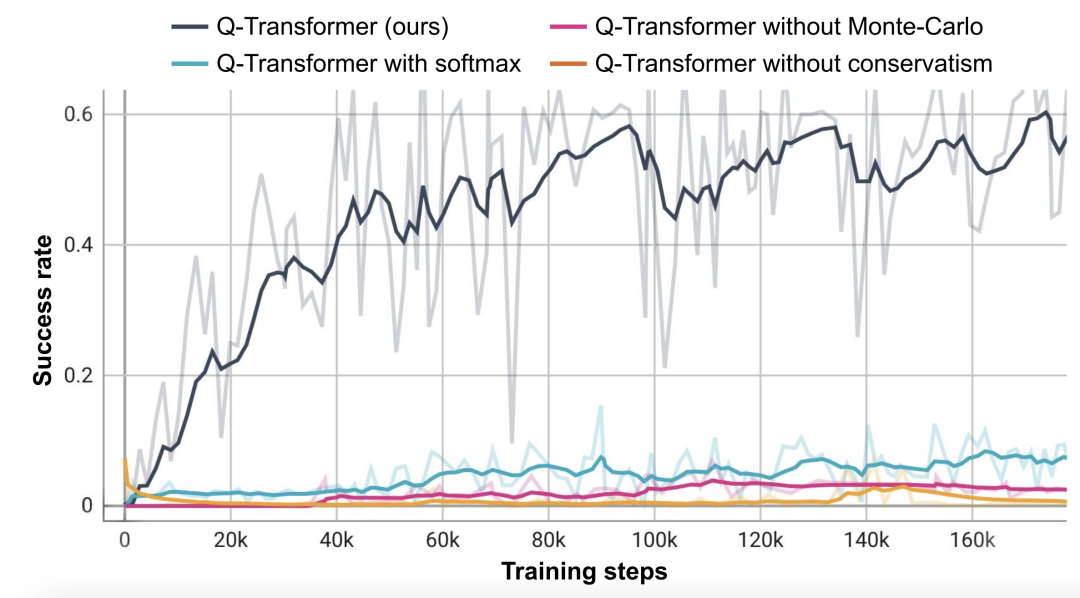
Based on this object-retrieval task, the researchers conducted an ablation experiment and found that conservative Both the regularizer and MC return are important to maintain performance. Performance is significantly worse if you switch to the Softmax regularizer, as this restricts the policy too much to the data distribution. This shows that the regularizer selected by DeepMind here can better cope with this task.
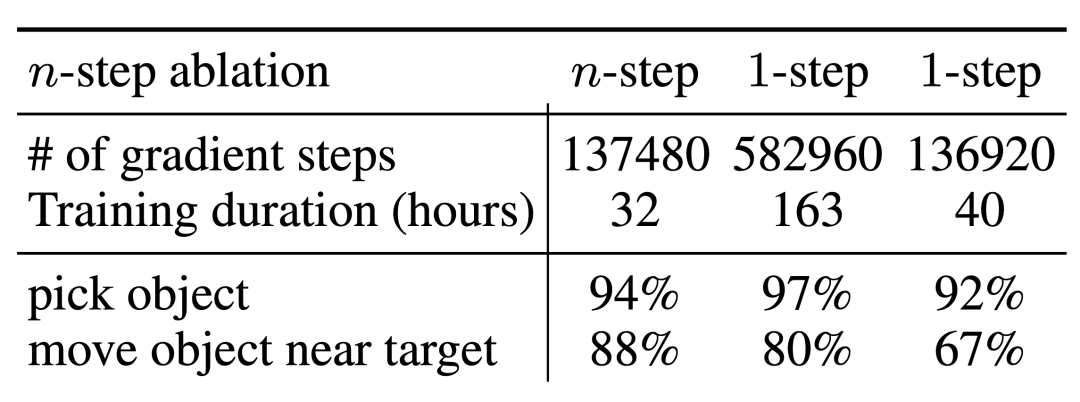
Their ablation experiments on n-step return found that although this may introduce bias, this method can Achieve equivalent high performance in significantly fewer gradient steps, effectively handling many problems
The researchers also tried Run Q-Transformer on larger datasets. They expanded the number of positive examples to 115,000 and the number of negative examples to 185,000, resulting in a data set containing 300,000 event clips. Using this large dataset, Q-Transformer is still able to learn and perform even better than the RT-1 BC benchmark

Finally, they combined the Q-function trained by Q-Transformer as an affordance model with a language planner, similar to SayCan
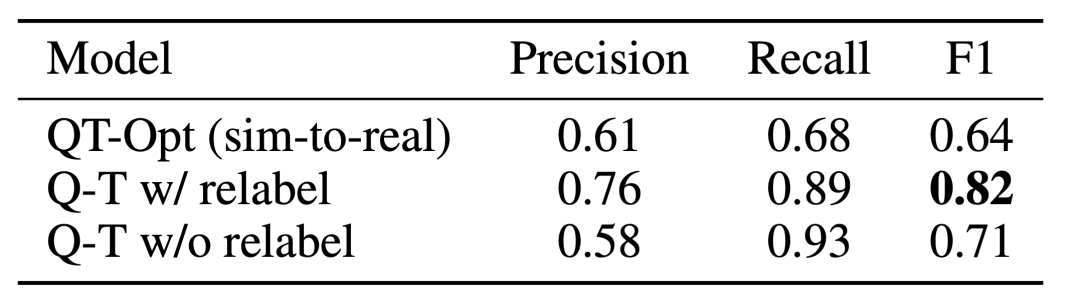
The effect of Q-Transformer affordance estimation is due to the previous Q function trained using QT-Opt; if the unsampled tasks are re-labeled as negative examples of the current task during training, the effect It can be better. Since Q-Transformer does not require the sim-to-real training used by QT-Opt training, it is easier to use Q-Transformer if a suitable simulation is lacking.
In order to test the complete "planning execution" system, they experimented with using Q-Transformer for simultaneous availability estimation and actual policy execution, and the results showed that it was better than the previous QT-Opt Combined with RT-1.
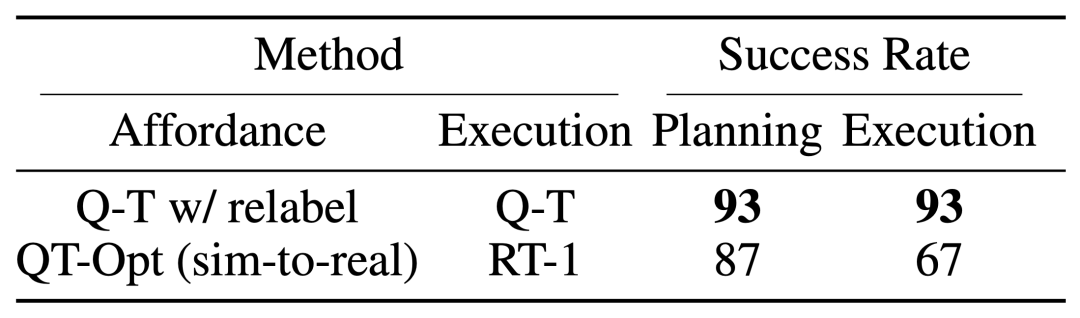
It can be observed from the example of the task affordance value of the given image that the Q-Transformer in the downstream " High-quality affordance values can be provided in the "Planning Execution" framework
Please read the original text for more details
The above is the detailed content of Google DeepMind: Combining large models with reinforcement learning to create an intelligent brain for robots to perceive the world. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
In MySQL, add fields using ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column, delete fields using ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop. When adding fields, you need to specify a location to optimize query performance and data structure; before deleting fields, you need to confirm that the operation is irreversible; modifying table structure using online DDL, backup data, test environment, and low-load time periods is performance optimization and best practice.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 Top 10 digital currency trading platforms: Top 10 safe and reliable digital currency exchanges
Apr 30, 2025 pm 04:30 PM
Top 10 digital currency trading platforms: Top 10 safe and reliable digital currency exchanges
Apr 30, 2025 pm 04:30 PM
The top 10 digital virtual currency trading platforms are: 1. Binance, 2. OKX, 3. Coinbase, 4. Kraken, 5. Huobi Global, 6. Bitfinex, 7. KuCoin, 8. Gemini, 9. Bitstamp, 10. Bittrex. These platforms all provide high security and a variety of trading options, suitable for different user needs.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How to achieve the effect of mouse scrolling event penetration? When we browse the web, we often encounter some special interaction designs. For example, on deepseek official website, �...
