
 Technology peripherals
AI
Meta's innovative SOTA model can generate amazing videos based on one sentence, setting off an Internet craze!
Technology peripherals
AI
Meta's innovative SOTA model can generate amazing videos based on one sentence, setting off an Internet craze!
Meta's innovative SOTA model can generate amazing videos based on one sentence, setting off an Internet craze!

I’ll give you a paragraph and ask you to make a video, can you do it?
Meta said, I can do it.
You heard it right: using AI, you can also become a filmmaker!
Recently, Meta has launched a new AI model with a very straightforward name: Make-A-Video.
How powerful is this model?
With just one sentence, the scene of "Three Horses Galloping" can be realized.

Even LeCun said that what is supposed to come will always come.

The visual effects are stunning
Without further ado, let’s just look at the effects.
Two kangaroos are busy cooking in the kitchen (whether it can be eaten is another matter)

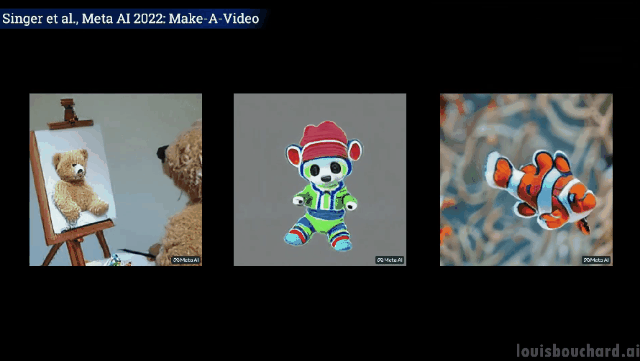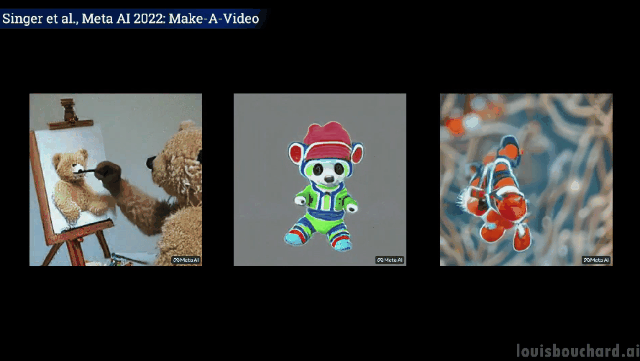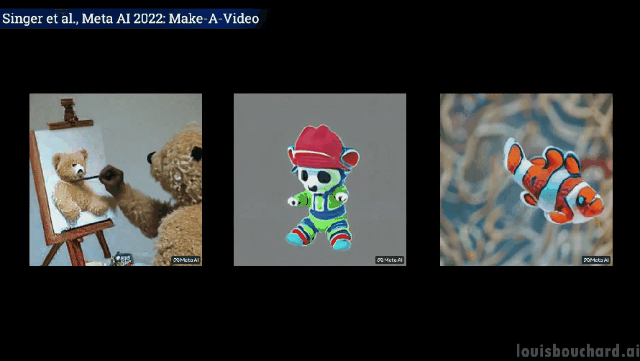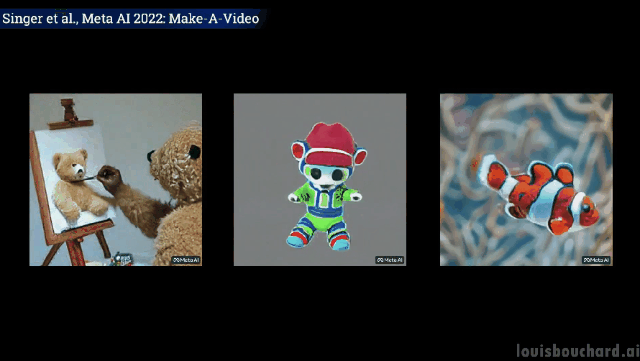
Close shot: The painter is painting on the canvas

The world of two people walking in the heavy rain (with uniform steps)

The horse is drinking water

Ballet girl dancing on the skyscraper

A golden retriever is eating ice cream (paws have evolved) on a beautiful tropical beach in summer

The cat owner is watching TV with the remote control (paws have evolved)

A teddy bear gives Draw your own self-portrait

Unexpected but reasonable, the dog takes the ice cream, the cat takes the remote control and the teddy bear draws " "Hands" have indeed "evolved" like humans! (Tactical Backward)
Of course, in addition to turning text into video, Make-A-Video can also turn static images into Gifs.
input Output:

Input:

Output: (The light seems a bit out of place)

Convert 2 still images to GIF, input the meteorite image

##Output:

And, turn the video into a video?
input Output:

input Output:

Today, Meta released its latest research MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA.

Paper address: https://makeavideo.studio/Make-A-Video.pdf


Obviously, it is to generate a video.
A superhero dog wearing a red cape flies in the sky
Compared to generating images, generating videos is much more difficult. Not only do we need to generate multiple frames of the same subject and scene, we also have to make them timely and coherent.
This increases the complexity of the image generation task - we cannot simply use DALLE to generate 60 images and then stitch them into a video. The effect will be very poor and unrealistic.

Therefore, we need a model that can understand the world in a more powerful way and allow it to generate a coherent series of images based on this level of understanding. Only then can the images blend together seamlessly. In other words, our goal is to simulate a world and then simulate its records. How to do it?
According to previous ideas, researchers would use a large number of text-video pairs to train the model, but in the current situation, this processing method is not realistic. Because these data are difficult to obtain, and the training cost is very expensive.
Therefore, the researchers opened their minds and adopted a completely new approach.
They chose to develop a text-to-image model and then apply it to video.
Coincidentally, some time ago, Meta developed Make-A-Scene, a model from text to image.
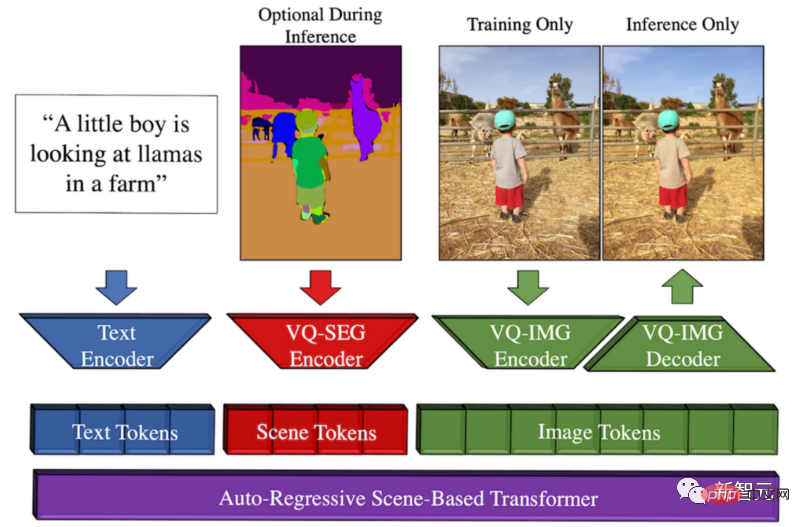
Make-A-Scene method overview
This model generates The opportunity is that Meta wants to promote creative expression, combining this text-to-image trend with the previous sketch-to-image model, resulting in a wonderful fusion between text and sketch-conditioned image generation.
This means we can quickly sketch a cat and write out what kind of image we want. Following the guidance of sketches and text, this model will produce the perfect illustration we want in seconds.

You can think of this multi-modal generative AI approach as a Dall-E model with more control over generation because it Quick sketches can also be used as input.
The reason why it is called multi-modal is because it can take multiple modalities as input, such as text and images. In contrast, Dall-E can only generate images from text.
In order to generate a video, the dimension of time needs to be added, so the researchers added a spatio-temporal pipeline to the Make-A-Scene model.
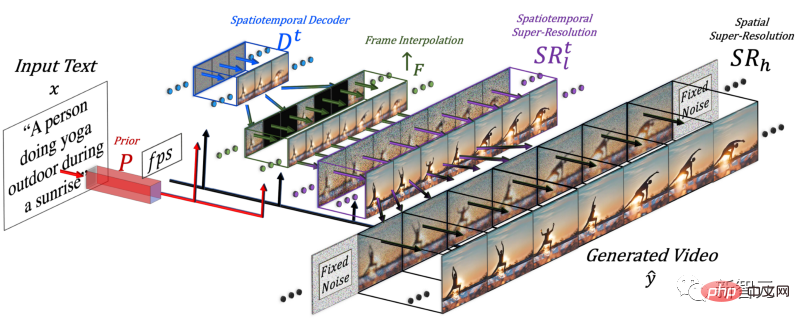
After adding the time dimension, this model does not generate just one picture, but generates 16 low-resolution pictures to create a A coherent short video.
This method is actually similar to the text-to-image model, but the difference is that it adds one-dimensional convolution on the basis of conventional two-dimensional convolution.
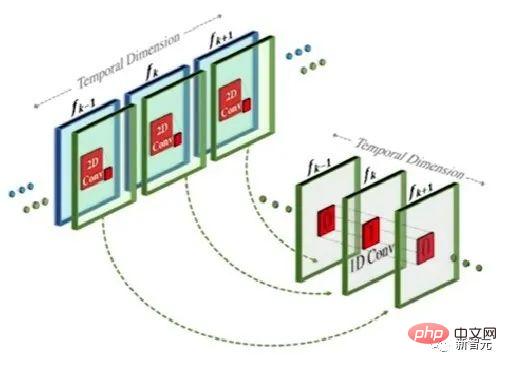
By simply adding a one-dimensional convolution, the researchers were able to keep the pre-trained two-dimensional convolution unchanged while adding a time dimension. Researchers can then train from scratch, reusing much of the code and parameters of the Make-A-Scene image model.
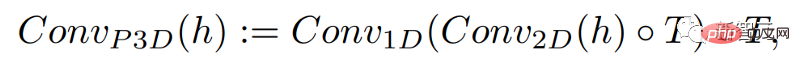
At the same time, the researchers also want to use text input to guide this model, which will be very similar to image models using CLIP embeddings.
In this case, the researchers increased the spatial dimension when mixing text features with image features, using the same method as above: retaining the attention module in the Make-A-Scene model , and add a one-dimensional attention module for time - copy-paste image generator model, repeat the generation module for one more dimension to get 16 initial frames.
But only relying on these 16 initial frames cannot generate a video.
Researchers need to produce a high-definition video from these 16 main frames. Their approach is to access previous and future frames and iteratively interpolate them in both the temporal and spatial dimensions simultaneously.
In this way, between these 16 initial frames, they generated new, larger frames based on the frames before and after, so that the motion became coherent and the overall video became Gotta be smooth.
This is done through a frame interpolation network, which can take existing images to fill in the gaps and generate intermediate information. In the spatial dimension, it does the same thing: enlarges the image, fills in the gaps in pixels, and makes the image more high-definition.

To summarize, to generate videos, the researchers fine-tuned a text-to-image model. They took a powerful model that was already trained, tweaked and trained it to adapt to the video.
Because of the addition of spatial and temporal modules, simply adapting the model to this new data without having to retrain it saves a lot of cost.
This kind of retraining uses unlabeled videos and only needs to teach the model to understand the consistency of the video and video frames, which makes it easier to build the data set.
Finally, the researchers used the image optimization model again to improve the spatial resolution, and used the frame interpolation component to add more frames to make the video smoother.
Of course, the current results of Make-A-Video still have shortcomings, just like the text-to-image model. But we all know how rapid the progress in the field of AI is.
If you want to know more, you can refer to the Meta AI paper in the link. The community is also developing a PyTorch implementation, so stay tuned if you want to implement it yourself.
Author introduction
There are many Chinese researchers involved in this paper: Yin Xi, An Jie, Zhang Songyang , Qiyuan Hu.
Yin Xi, FAIR research scientist. Previously worked for Microsoft as a senior application scientist for Microsoft Cloud and AI. He received his PhD from the Department of Computer Science and Engineering at Michigan State University and his bachelor's degree in electrical engineering from Wuhan University in 2013. The main research areas are multi-modal understanding, large-scale target detection, face reasoning, etc.
Anjie is a doctoral student in the Department of Computer Science at the University of Rochester. Study under Professor Roger Bo. Previously received bachelor's and master's degrees from Peking University in 2016 and 2019. Research interests include computer vision, deep generative models, and AI art. Participated in Make-A-Video research as an intern.
Zhang Songyang is a doctoral student in the Department of Computer Science at the University of Rochester, studying under Professor Roger Bo. He received his bachelor's degree from Southeast University and his master's degree from Zhejiang University. Research interests include natural language moment localization, unsupervised grammar induction, skeleton-based action recognition, etc. Participated in Make-A-Video research as an intern.
Qiyuan Hu, then an AI Resident at FAIR, was engaged in research on multi-modal generative models that improve human creativity. She received her PhD in medical physics from the University of Chicago and worked on AI-assisted medical image analysis. Now working at Tempus Labs as a machine learning scientist.
Netizens were greatly shocked
Some time ago, major companies such as Google released their own text-to-image models, such as Parti, and so on.
Some even think that text-to-video generative models are still some time away.
Unexpectedly, Meta dropped a bombshell this time.
In fact, today, there is also a text-to-video generation model Phenaki, which has been submitted to ICLR 2023. Since it is still in the blind review stage, the author's institution is still unknown.

Netizens said that from DALLE to Stable Diffuson to Make-A-Video, everything happened too fast.

The above is the detailed content of Meta's innovative SOTA model can generate amazing videos based on one sentence, setting off an Internet craze!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
Steps to add and delete fields to MySQL tables
Apr 29, 2025 pm 04:15 PM
In MySQL, add fields using ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column, delete fields using ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop. When adding fields, you need to specify a location to optimize query performance and data structure; before deleting fields, you need to confirm that the operation is irreversible; modifying table structure using online DDL, backup data, test environment, and low-load time periods is performance optimization and best practice.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 Top 10 digital currency trading platforms: Top 10 safe and reliable digital currency exchanges
Apr 30, 2025 pm 04:30 PM
Top 10 digital currency trading platforms: Top 10 safe and reliable digital currency exchanges
Apr 30, 2025 pm 04:30 PM
The top 10 digital virtual currency trading platforms are: 1. Binance, 2. OKX, 3. Coinbase, 4. Kraken, 5. Huobi Global, 6. Bitfinex, 7. KuCoin, 8. Gemini, 9. Bitstamp, 10. Bittrex. These platforms all provide high security and a variety of trading options, suitable for different user needs.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How does deepseek official website achieve the effect of penetrating mouse scroll event?
Apr 30, 2025 pm 03:21 PM
How to achieve the effect of mouse scrolling event penetration? When we browse the web, we often encounter some special interaction designs. For example, on deepseek official website, �...
