

An easy way to process large machine learning data sets in Python

Intended audience for this article:
- People who want to perform Pandas/NumPy operations on large data sets.
- People who want to use Python to perform machine learning tasks on big data.

This article will use .csv format files to demonstrate various operations of python, as well as other formats such as arrays, text files, etc.
Why can’t we use pandas for large machine learning datasets?
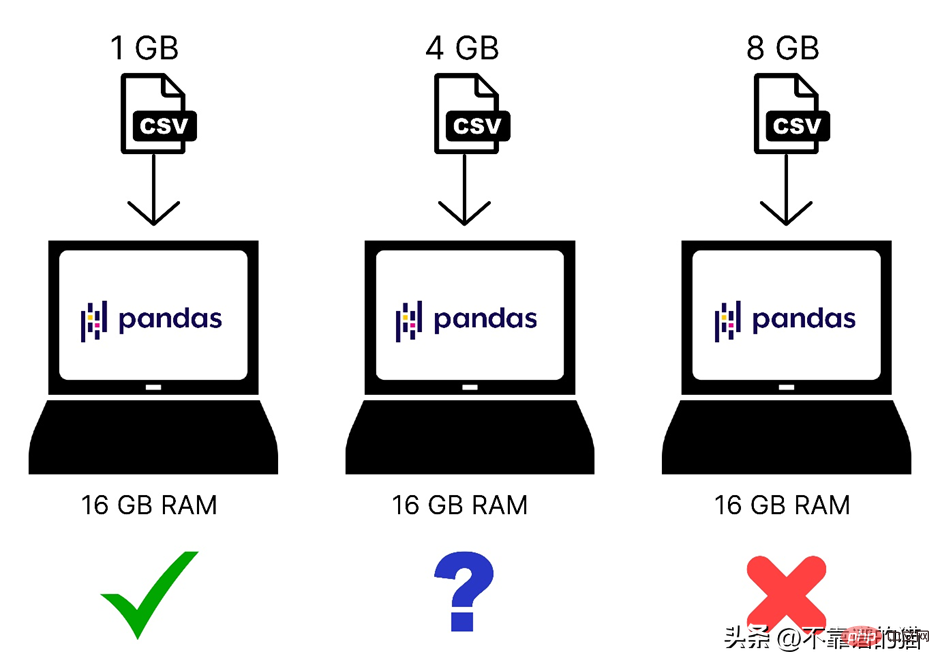
We know that Pandas uses computer memory (RAM) to load your machine learning dataset, but if your computer has 8 GB of memory (RAM), then why pandas still cannot load a 2 GB dataset Woolen cloth? The reason is that loading a 2 GB file using Pandas requires not only 2 GB of RAM, but more memory as the total memory requirement depends on the size of the dataset and the operations you will perform on that dataset.
Here's a quick comparison of different sized datasets loaded into computer memory:
Additionally, Pandas only uses one core of the operating system, which Making processing very slow. In other words, we can say that pandas does not support parallelism (breaking a problem into smaller tasks).
Assuming that the computer has 4 cores, the following figure shows the number of cores used by pandas when loading a CSV file:
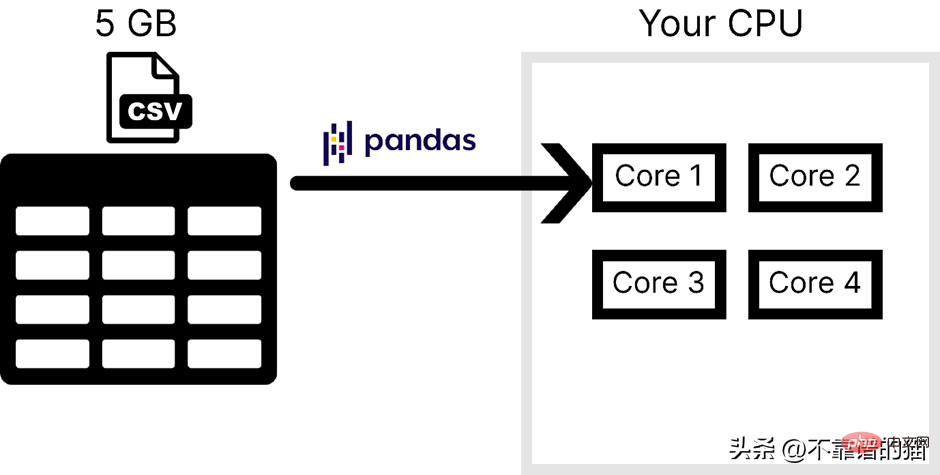
Pandas is generally not used to handle large-scale machine learning The main reasons for the data set are the following two points, one is the computer memory usage, and the other is the lack of parallelism. In NumPy and Scikit-learn, the same problem is faced for large data sets.
To solve these two problems, you can use a python library called Dask, which enables us to perform various operations such as pandas, NumPy, and ML on large data sets.
How does Dask work?
Dask loads your data set in partitions, while pandas usually uses the entire machine learning data set as a dataframe. In Dask, each partition of a dataset is considered a pandas dataframe.
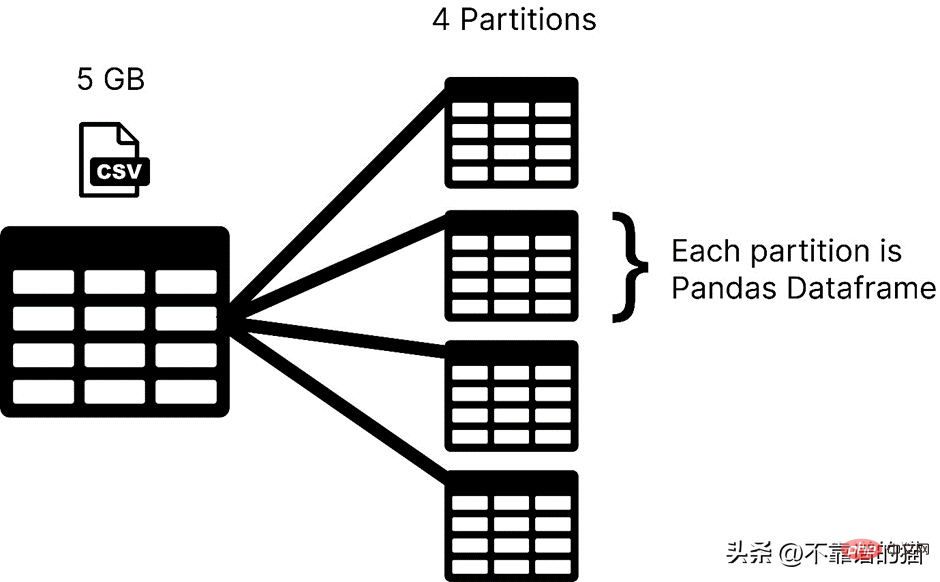
#Dask loads one partition at a time, so you don't have to worry about memory allocation errors.
The following is a comparison of using dask to load machine learning datasets of different sizes in computer memory:
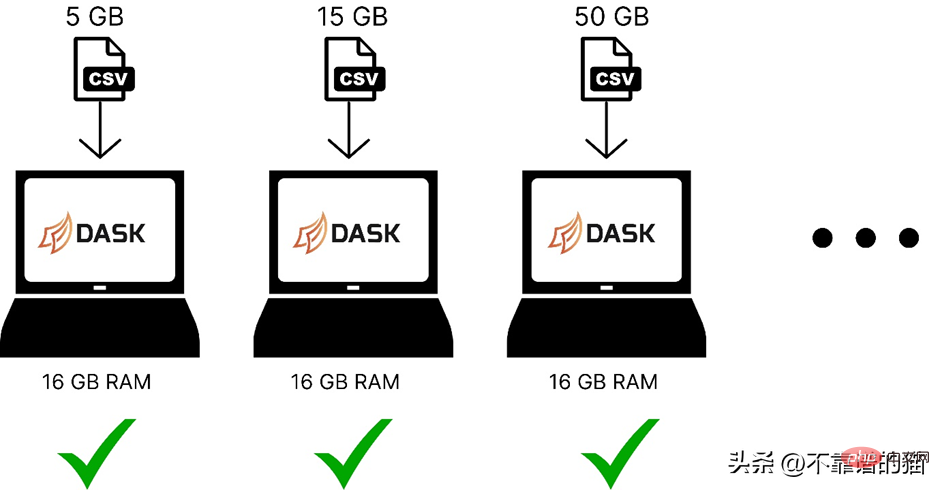
Dask solves the problem of parallelism because it will The data is split into multiple partitions, each using a separate core, which makes calculations on the dataset faster.
Assuming the computer has 4 cores, here is how dask loads a 5 GB csv file:
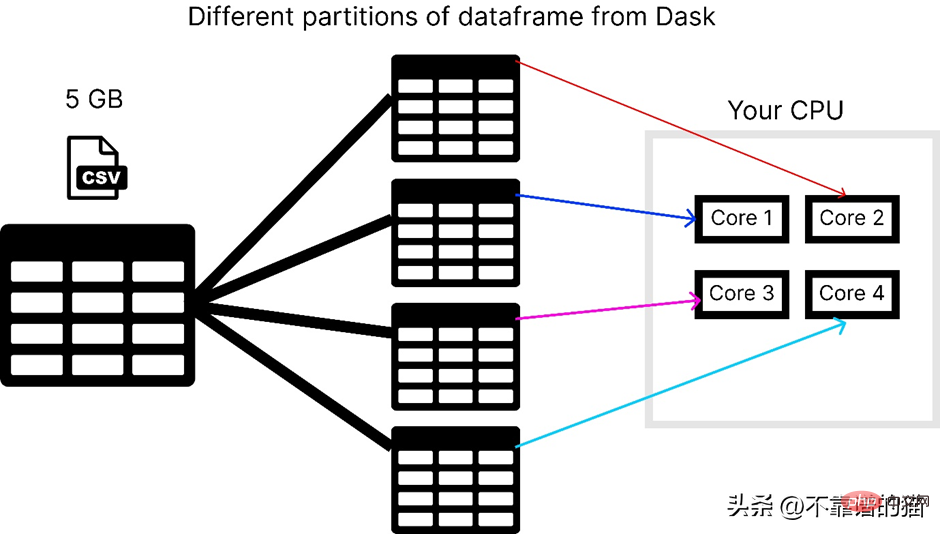
To use the dask library you can use the following Command to install:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>
Dask has several modules like dask.array, dask.dataframe and dask.distributed which will only work if you have installed the corresponding libraries like NumPy, pandas and Tornado respectively .
How to use dask to process large CSV files?
dask.dataframe is used to process large csv files, first I tried to import a dataset of size 8 GB using pandas.
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)
It threw memory allocation error in my 16 GB RAM laptop.
Now, try to import the same 8 GB data using dask.dataframe
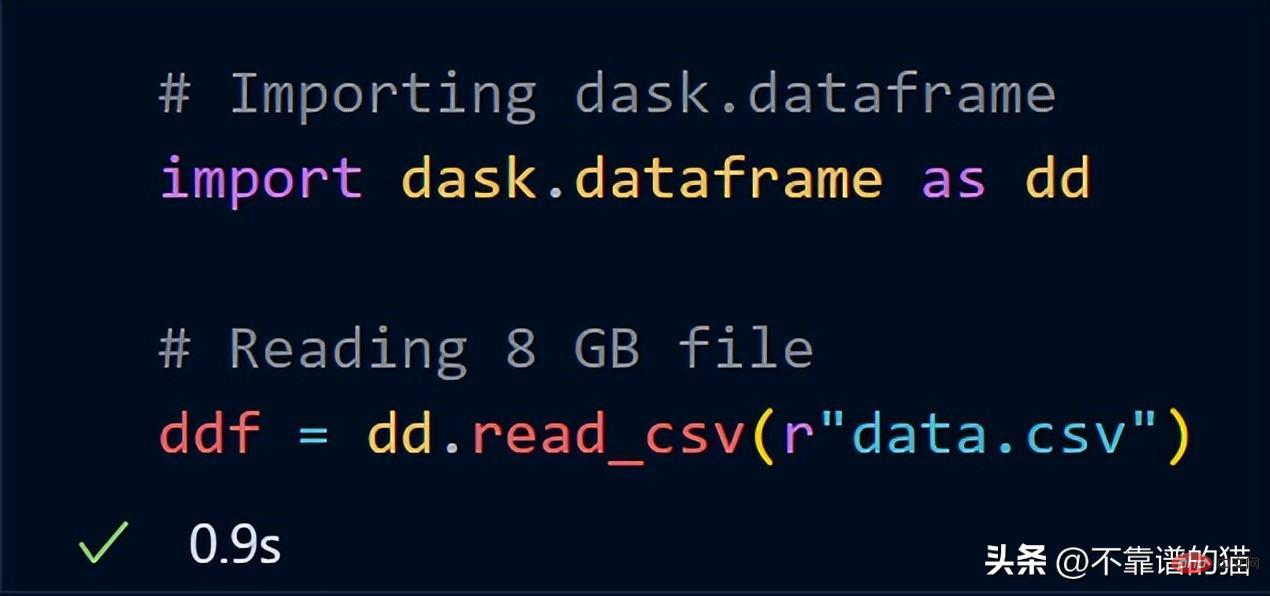
dask took just a second to load the entire 8 GB file into ddf in variables.
Let's see the output of the ddf variable.
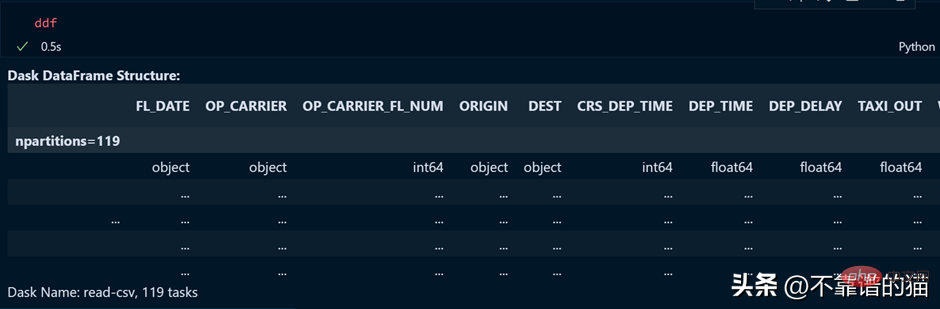
As you can see, the execution time is 0.5 seconds, and it is shown here that it has been divided into 119 partitions.
You can also check the number of partitions of your dataframe using:
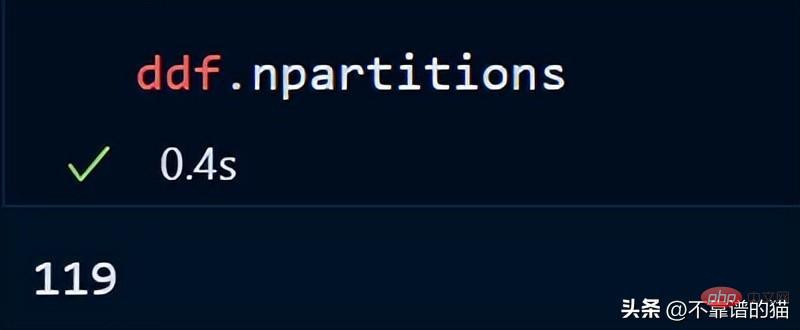
By default, dask loads my 8 GB CSV file into 119 Partitions (each partition size is 64MB), this is done based on the available physical memory and the number of cores of the computer.
I can also specify my own number of partitions using the blocksize parameter when loading the CSV file.
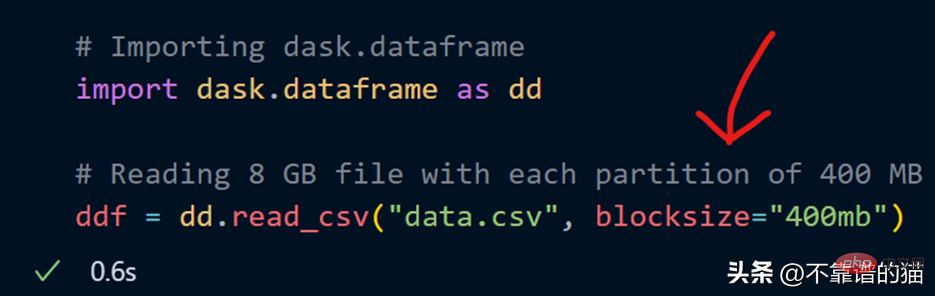
Now a blocksize parameter with a string value of 400MB is specified, which makes each partition size 400 MB, let’s see how many partitions there are
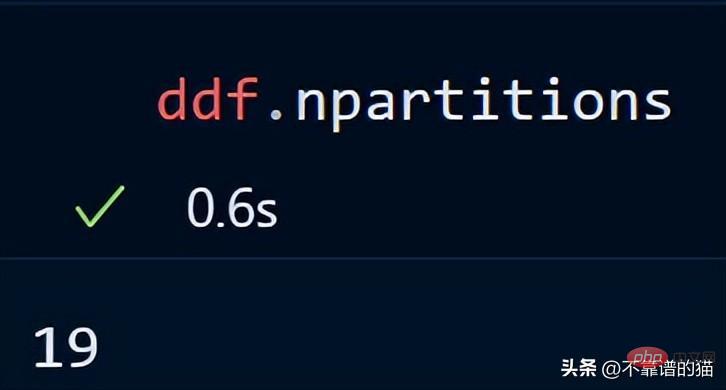
Key Point: When using Dask DataFrames, a good rule of thumb is to keep partitions under 100MB.
Use the following method to call a specific partition of the dataframe:
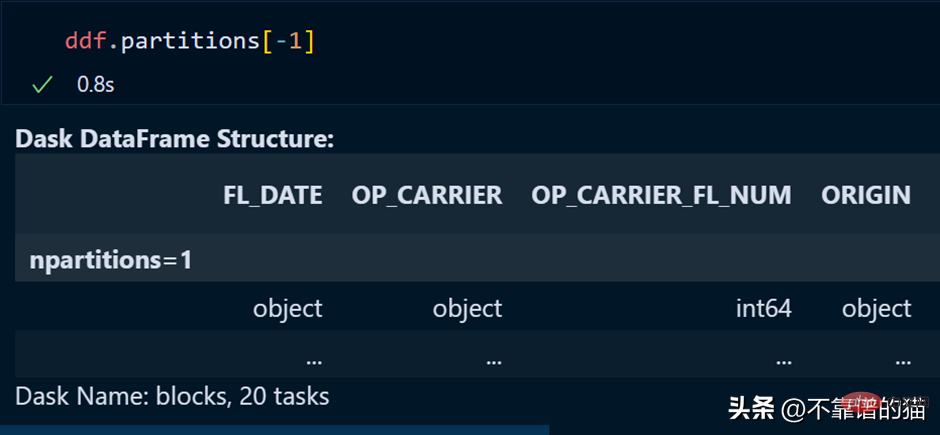
You can also call the last partition by using a negative index, just like we are calling the list as the last element.
Let's see the shape of the dataset:
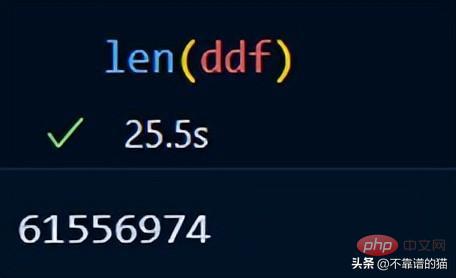
You can use len() to check the number of rows of the dataset:
Dask already includes a sample dataset. I'll use time series data to show you how dask performs mathematical operations on a data set.
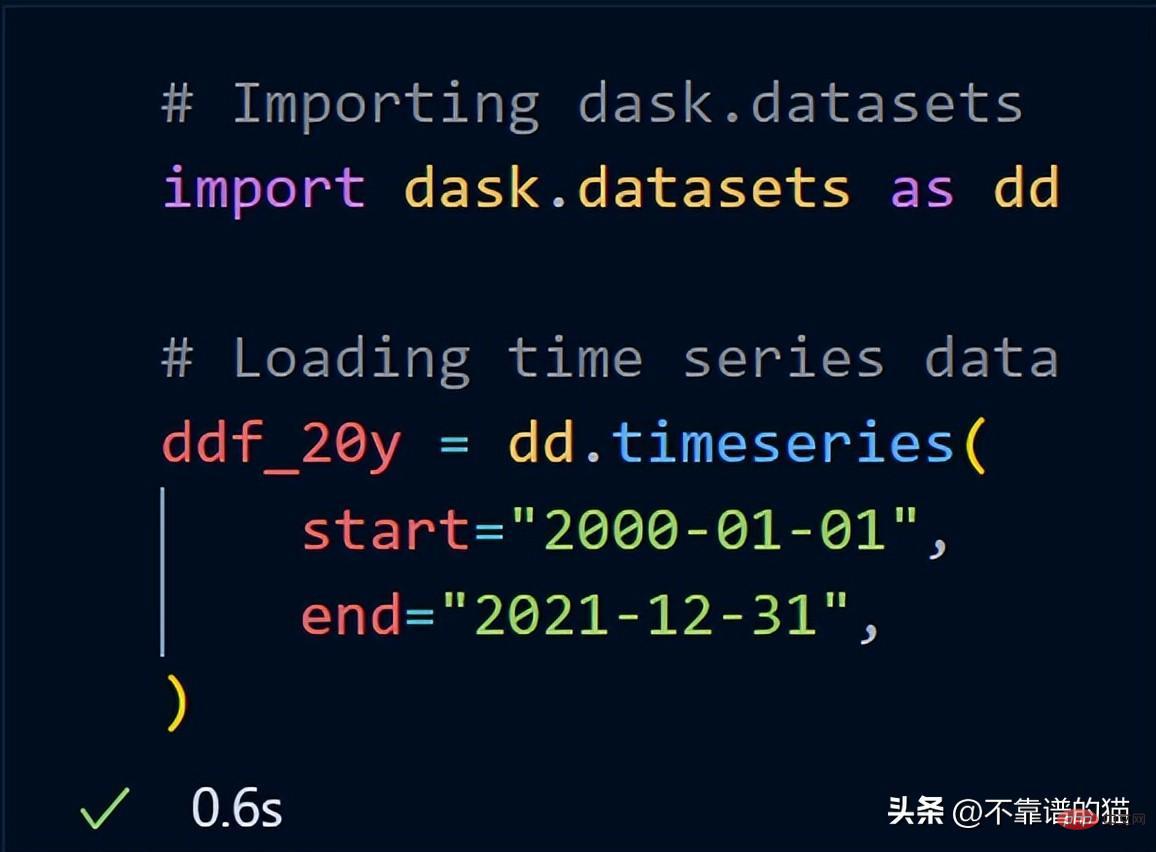
After importing dask.datasets, ddf_20y loaded the time series data from January 1, 2000 to December 31, 2021.
Let’s look at the number of partitions for our time series data.
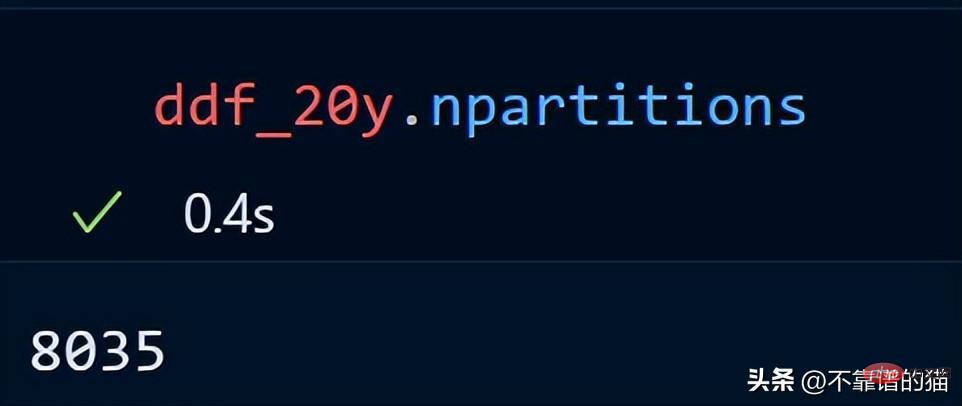
#The 20-year time series data is distributed across 8035 partitions.
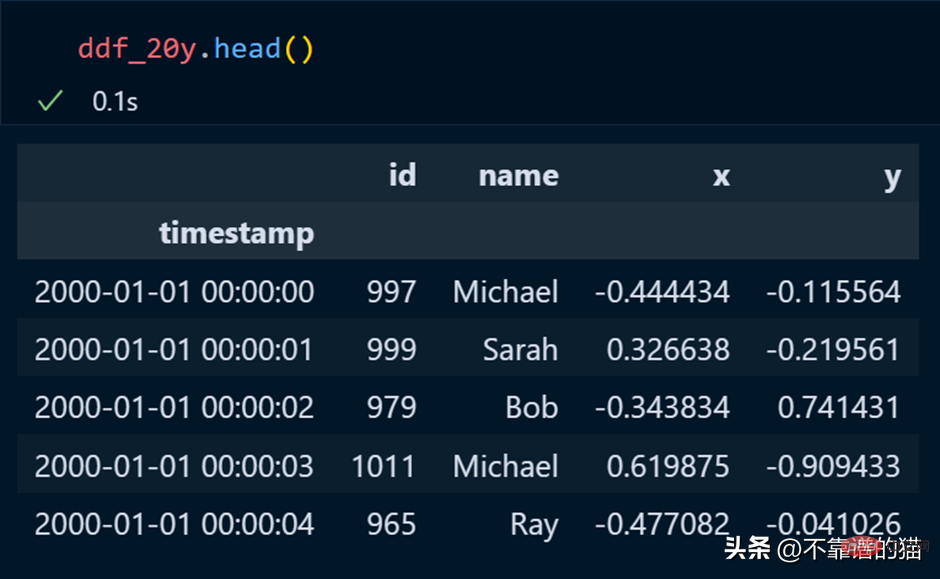
In pandas, we use head to print the first few rows of the data set, and the same is true for dask.
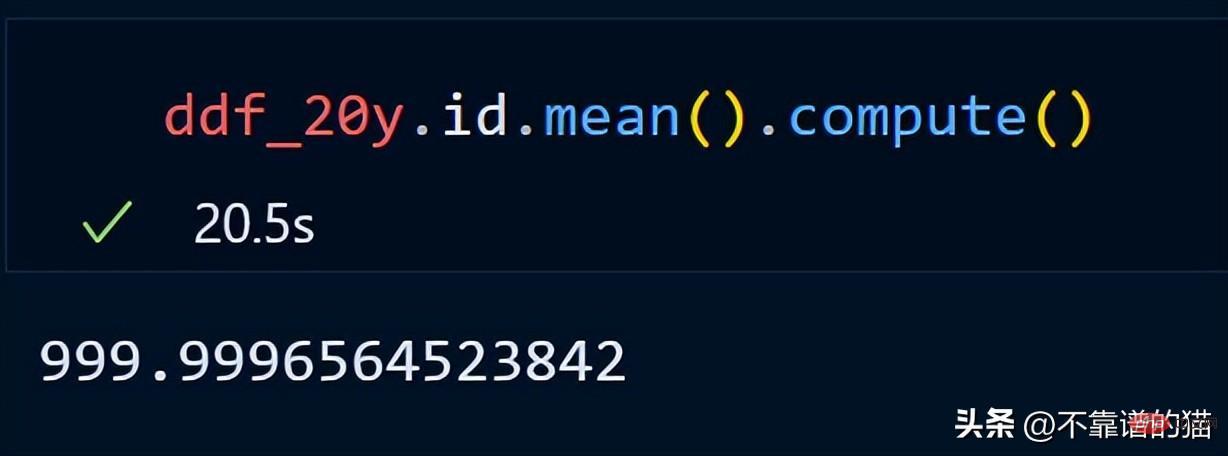
Let’s calculate the average of the id column.
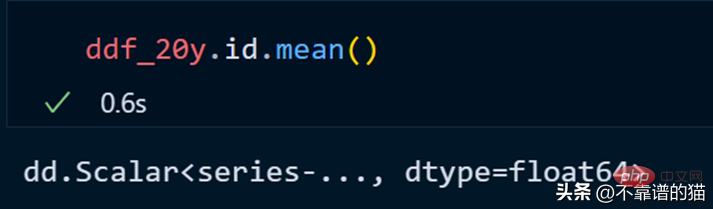
dask does not print the total number of rows of the dataframe because it uses lazy calculations (the output is not displayed until needed). To display the output, we can use the compute method.
Suppose I want to normalize each column of the data set (convert the value to between 0 and 1), the Python code is as follows:
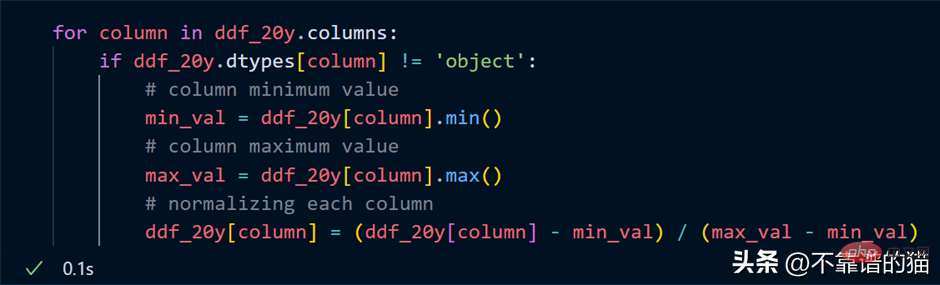
Loop through the columns, find the minimum and maximum values for each column, and normalize the columns using a simple mathematical formula.
Key point: In our normalization example, don't think that actual numerical calculations happen, it's just lazy evaluation (the output is never shown to you until it's needed).
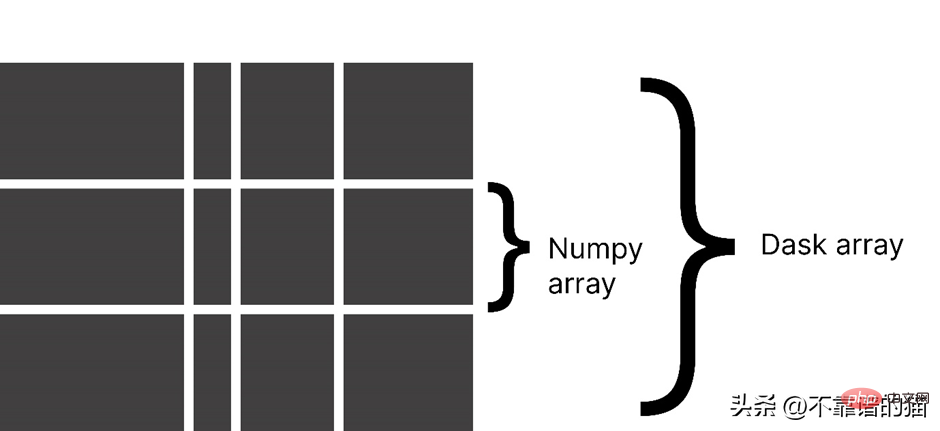
Why use Dask array?
Dask divides an array into small chunks, where each chunk is a NumPy array.
dask.arrays is used to handle large arrays. The following Python code uses dask to create a 10000 x 10000 array and store it in the x variable.
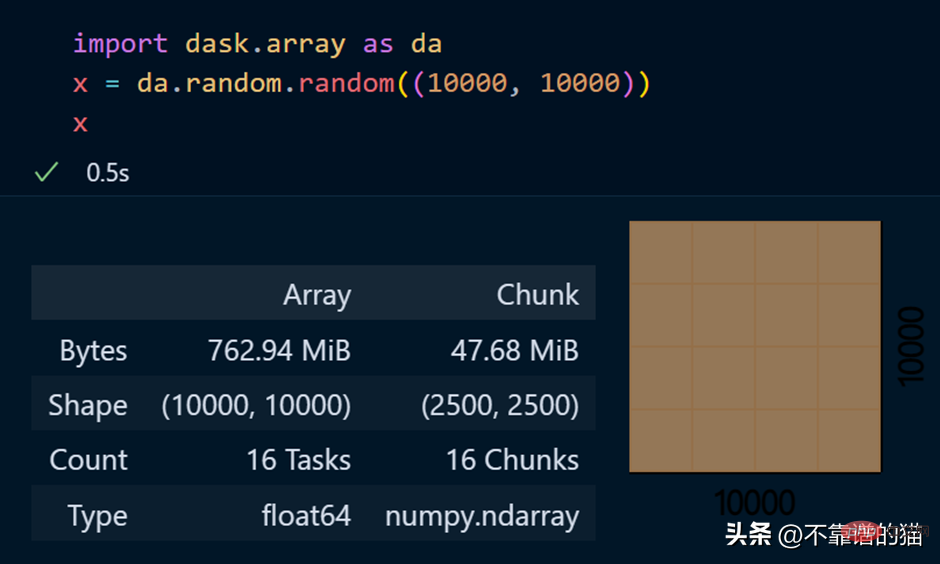
Calling the x variable produces various information about the array.
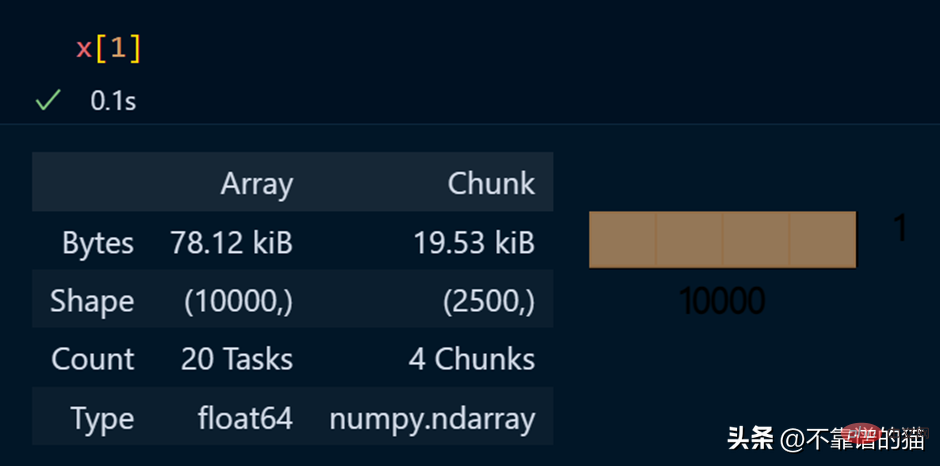
View specific elements of an array
Python example of performing mathematical operations on a dask array:
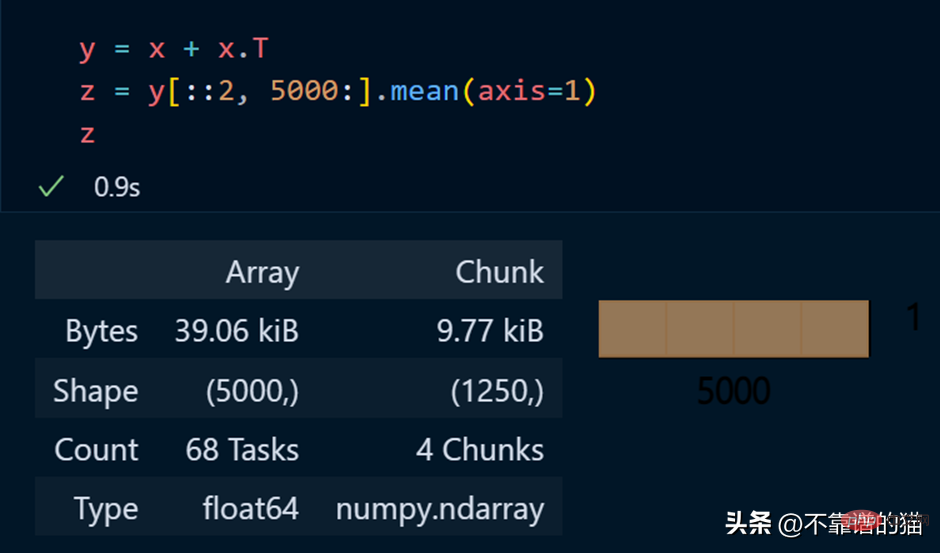
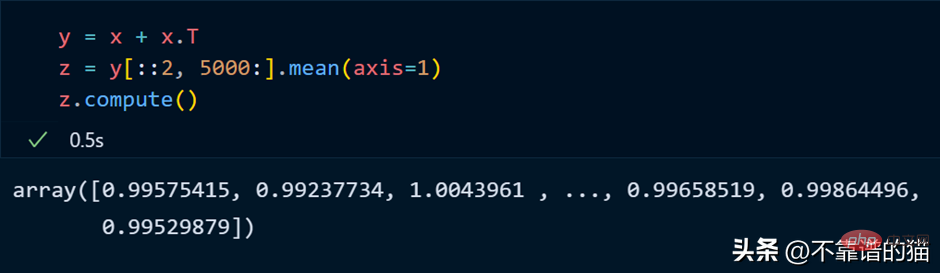
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
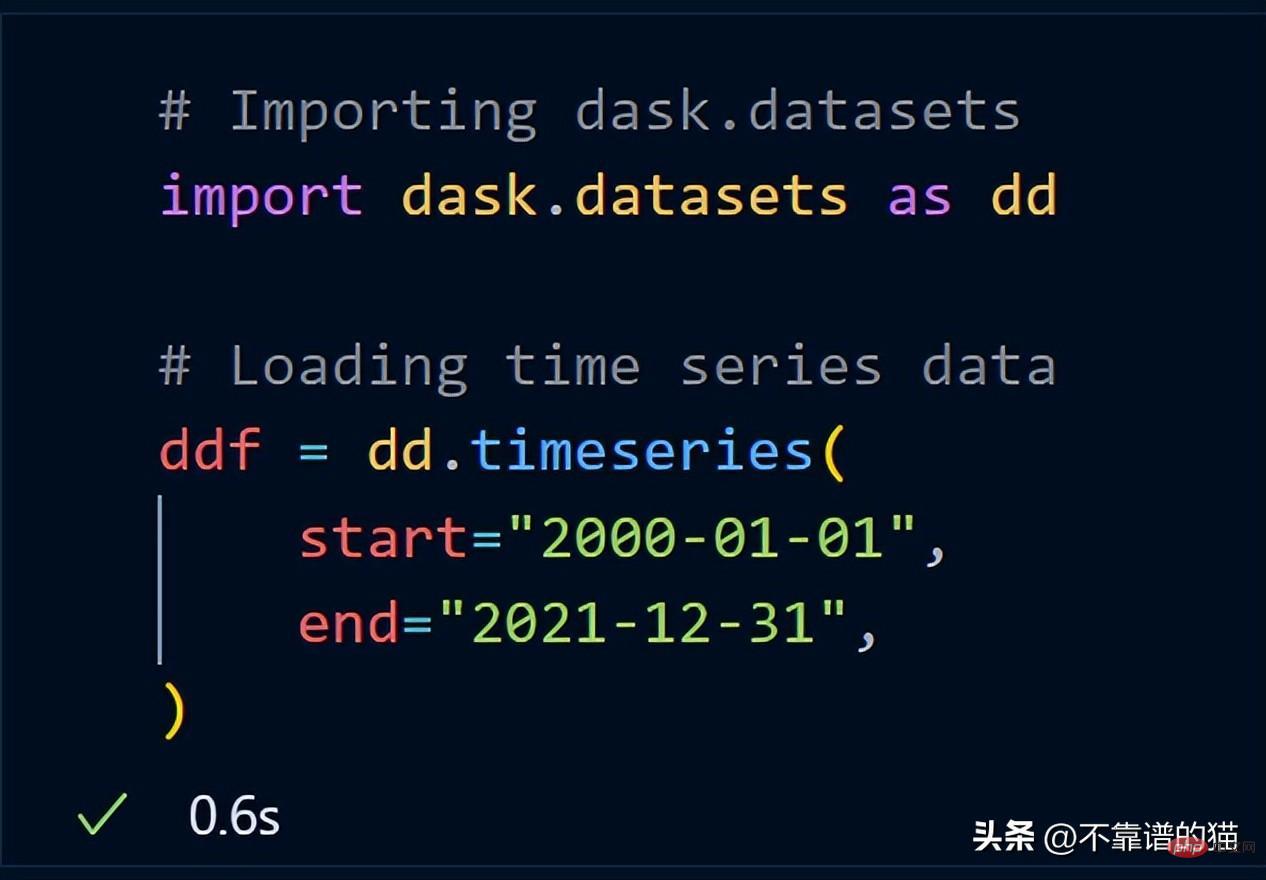
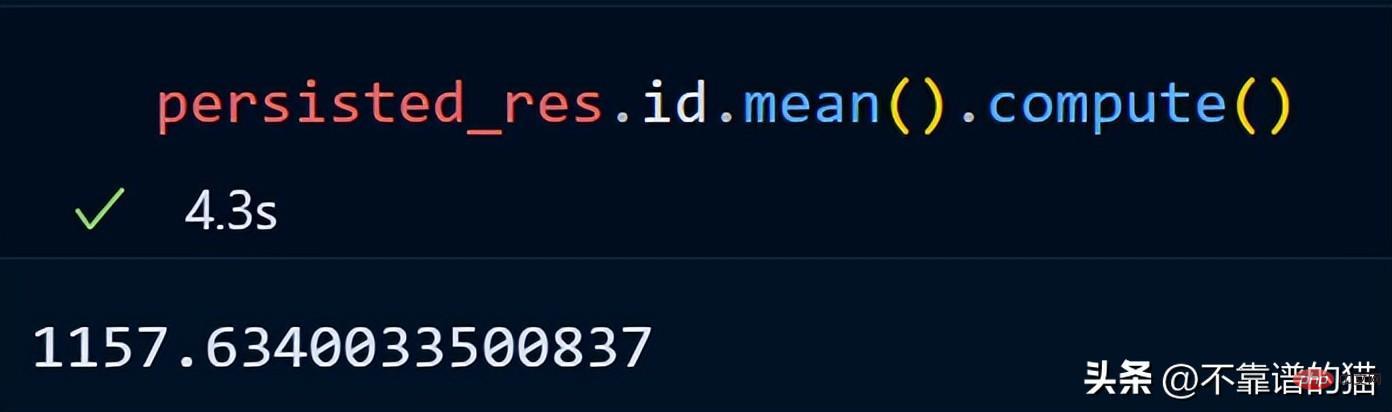
让我们取数据集的一个子集并计算该子集的总行数。
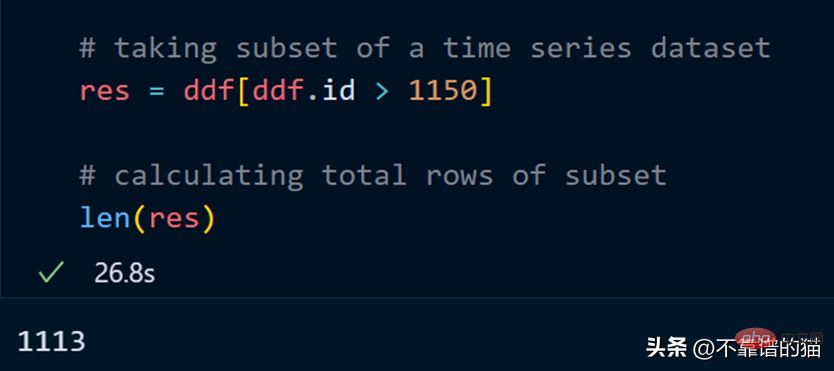
计算总行数需要 27 秒。
我们现在使用 persist 方法:
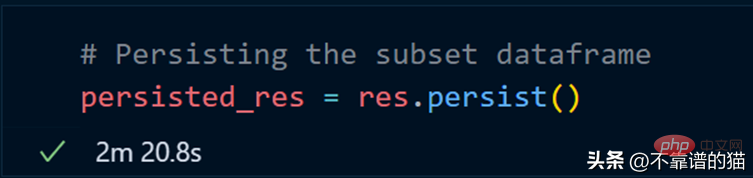
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
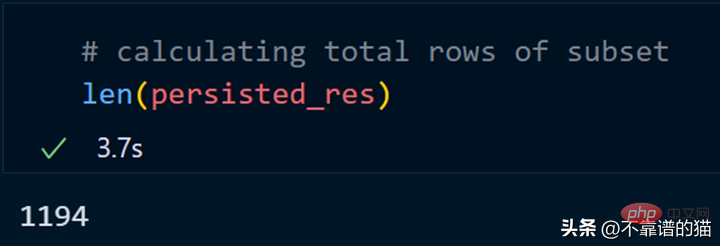
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
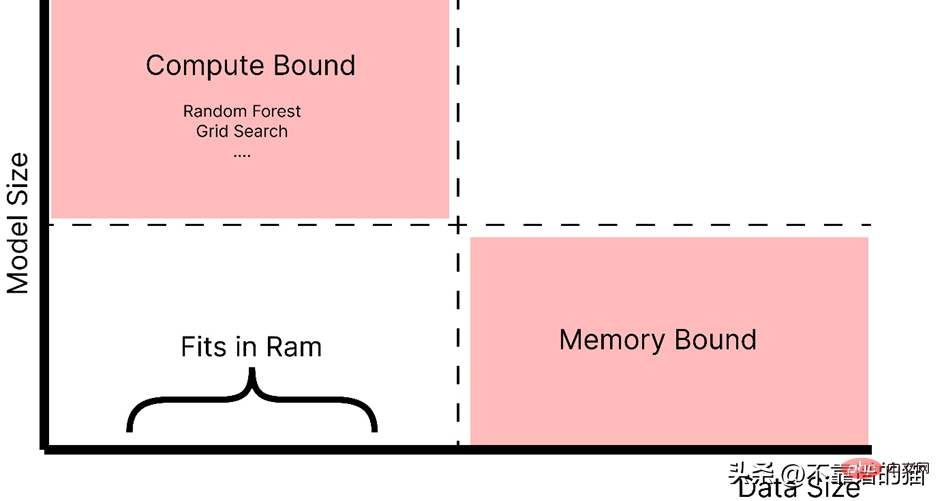
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
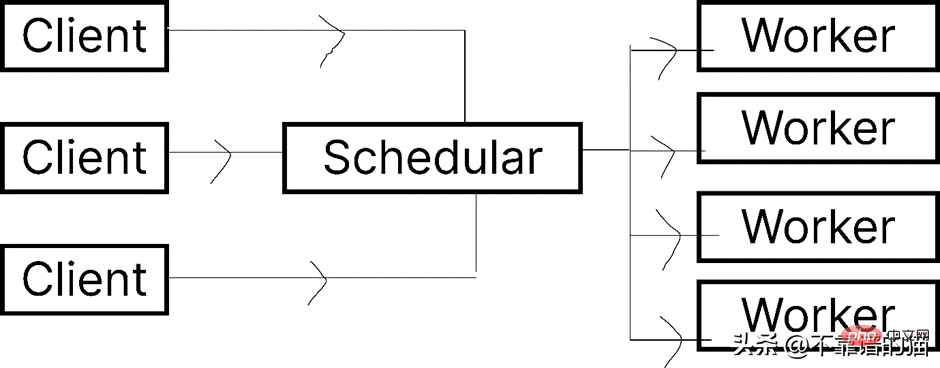
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
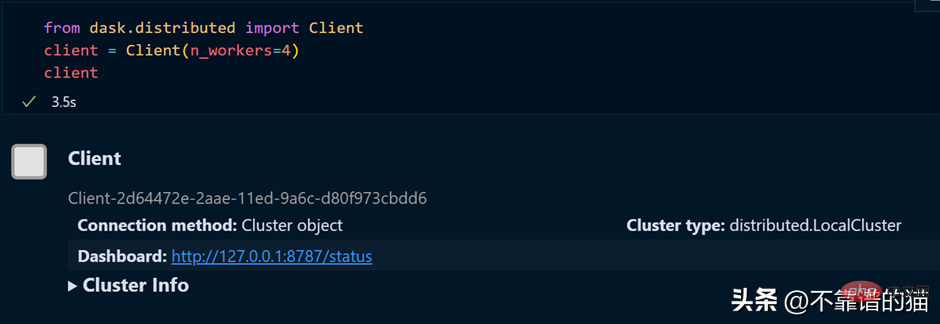
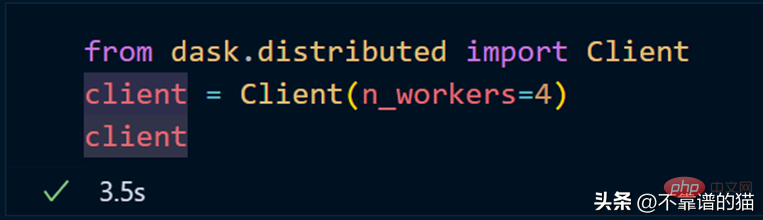
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
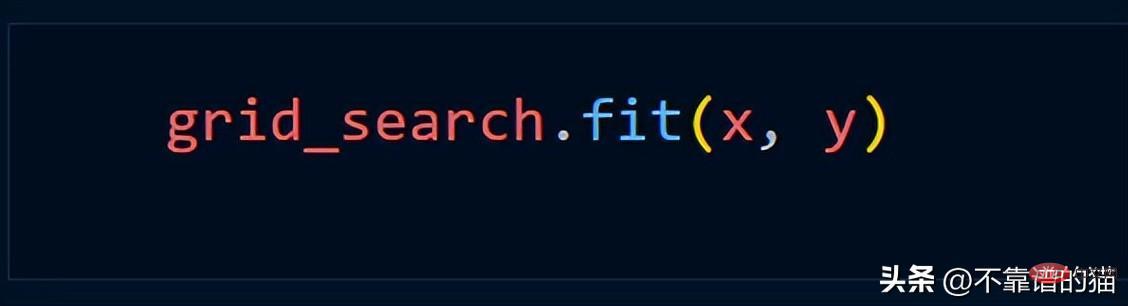
Assuming we use the Grid_Search method, we usually use the following Python code
Use dask.distributed to create a cluster:
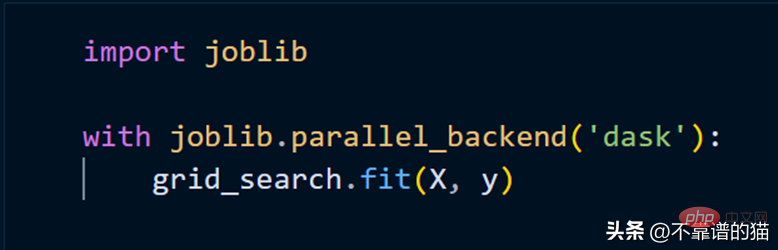
To fit the scikit-learn model using clusters, we only need to use joblib.
The above is the detailed content of An easy way to process large machine learning data sets in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1670
1670
 14
1428
52
1329
25
1274
29
1256
24
14
1428
52
1329
25
1274
29
1256
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang vs. Python: Performance and Scalability
Apr 19, 2025 am 12:18 AM
Golang is better than Python in terms of performance and scalability. 1) Golang's compilation-type characteristics and efficient concurrency model make it perform well in high concurrency scenarios. 2) Python, as an interpreted language, executes slowly, but can optimize performance through tools such as Cython.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
