
 Technologie-Peripheriegeräte
KI
DECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!
Technologie-Peripheriegeräte
KI
DECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!
DECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!


Titel: DECO: Query-Based End-to-End Object Detection with ConvNets
Papier: https://arxiv.org/pdf/2312.13735.pdf
Quellcode: https://github.com / xinghaochen/DECO
Originaltext: https://zhuanlan.zhihu.com/p/686011746@王云河
Einführung
Nach der Einführung des Detection Transformer (DETR) gab es einen Boom im Bereich der Zielerkennung , und viele nachfolgende Studien konzentrierten sich auf die Genauigkeit. Im Hinblick auf Geschwindigkeit und Geschwindigkeit wurden gegenüber dem ursprünglichen DETR Verbesserungen vorgenommen. Die Diskussion geht jedoch weiter, ob Transformers das visuelle Feld vollständig dominieren können. Einige Studien wie ConvNeXt und RepLKNet zeigen, dass CNN-Strukturen im Sichtfeld noch großes Potenzial haben.
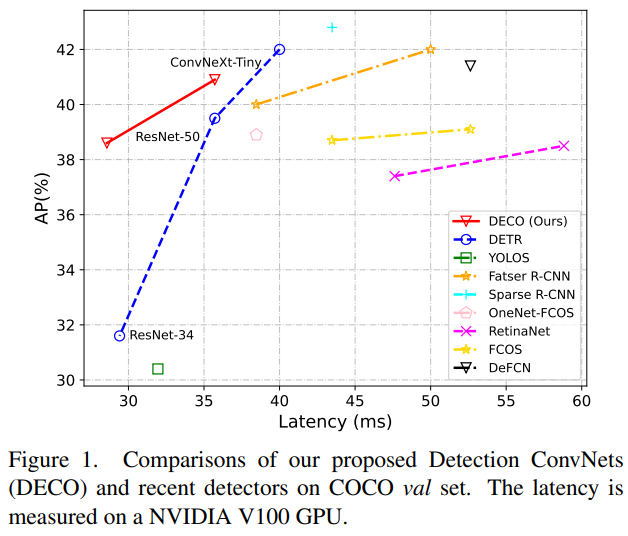
Was wir in dieser Arbeit untersuchen, ist, wie man die Architektur der „reinen Faltung“ nutzen kann, um einen DETR-ähnlichen Framework-Detektor mit hoher Leistung zu erhalten. Als Hommage an DETR nennen wir unseren Ansatz (Detection ConvNets). Unter Verwendung einer ähnlichen Struktureinstellung wie DETR und der Verwendung unterschiedlicher Backbones erreichte DECO 38,6 % und 40,8 % AP auf COCO und 35 FPS und 28 FPS auf V100 und erzielte damit eine bessere Leistung als DETR. In Kombination mit Modulen wie RT-DETR-ähnlichen Multiskalenfunktionen erreichte DECO eine Geschwindigkeit von 47,8 % AP und 34 FPS. Die Gesamtleistung weist im Vergleich zu vielen DETR-Verbesserungsmethoden gute Vorteile auf. DECOMethode
Netzwerkarchitektur
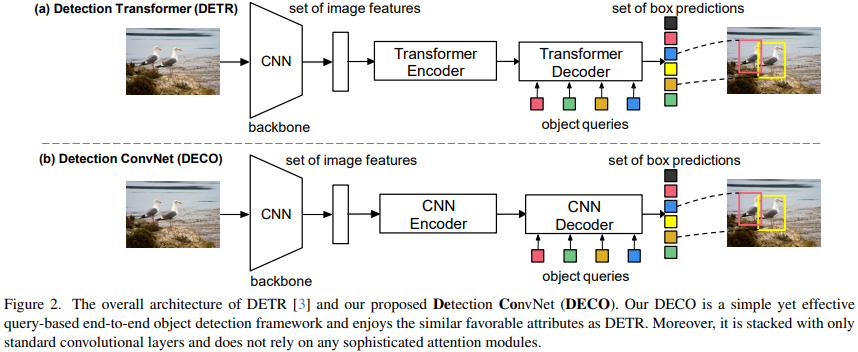 Die Hauptfunktion von DETR besteht darin, die Struktur von Transformer Encoder-Decoder zu verwenden, um mit einem Eingabebild zu interagieren, indem ein Satz von Abfragen verwendet wird, um mit Bildfunktionen zu interagieren, und ein bestimmtes direkt ausgegeben werden kann Dadurch entfällt die Abhängigkeit von Nachbearbeitungsvorgängen wie NMS. Die von uns vorgeschlagene Gesamtarchitektur von DECO ähnelt DETR. Sie umfasst außerdem Backbone für die Bildmerkmalsextraktion, eine Encoder-Decoder-Struktur für die Interaktion mit Query und gibt schließlich eine bestimmte Anzahl von Erkennungsergebnissen aus. Der einzige Unterschied besteht darin, dass DECOs Encoder und Decoder reine Faltungsstrukturen sind, sodass DECO ein abfragebasierter End-to-End-Detektor ist, der aus reiner Faltung besteht.
Die Hauptfunktion von DETR besteht darin, die Struktur von Transformer Encoder-Decoder zu verwenden, um mit einem Eingabebild zu interagieren, indem ein Satz von Abfragen verwendet wird, um mit Bildfunktionen zu interagieren, und ein bestimmtes direkt ausgegeben werden kann Dadurch entfällt die Abhängigkeit von Nachbearbeitungsvorgängen wie NMS. Die von uns vorgeschlagene Gesamtarchitektur von DECO ähnelt DETR. Sie umfasst außerdem Backbone für die Bildmerkmalsextraktion, eine Encoder-Decoder-Struktur für die Interaktion mit Query und gibt schließlich eine bestimmte Anzahl von Erkennungsergebnissen aus. Der einzige Unterschied besteht darin, dass DECOs Encoder und Decoder reine Faltungsstrukturen sind, sodass DECO ein abfragebasierter End-to-End-Detektor ist, der aus reiner Faltung besteht.
Encoder
Der Austausch der Encoder-Struktur von DETR ist relativ einfach. Wir entscheiden uns für die Verwendung von 4 ConvNeXt-Blöcken, um die Encoder-Struktur zu bilden. Konkret wird jede Schicht des Encoders durch Stapeln einer 7x7-Tiefenfaltung, einer LayerNorm-Schicht, einer 1x1-Faltung, einer GELU-Aktivierungsfunktion und einer weiteren 1x1-Faltung implementiert. Darüber hinaus muss in DETR, da die Transformer-Architektur eine Permutationsinvarianz gegenüber der Eingabe aufweist, der Eingabe jeder Encoderschicht eine Positionscodierung hinzugefügt werden. Für den Encoder, der aus Faltungen besteht, ist es jedoch nicht erforderlich, eine Positionscodierung hinzuzufügen
Decoder
Im Vergleich dazu ist der Austausch des Decoders deutlich komplizierter. Die Hauptfunktion des Decoders besteht darin, vollständig mit Bildmerkmalen und Query zu interagieren, sodass Query die Bildmerkmalsinformationen vollständig wahrnehmen und dadurch die Koordinaten und Kategorien von Zielen im Bild vorhersagen kann. Der Decoder umfasst hauptsächlich zwei Eingaben: die Feature-Ausgabe des Encoders und eine Reihe lernbarer Abfragevektoren (Query). Wir unterteilen die Hauptstruktur von Decoder in zwei Module: Self-Interaction Module (SIM) und Cross-Interaction Module (CIM).
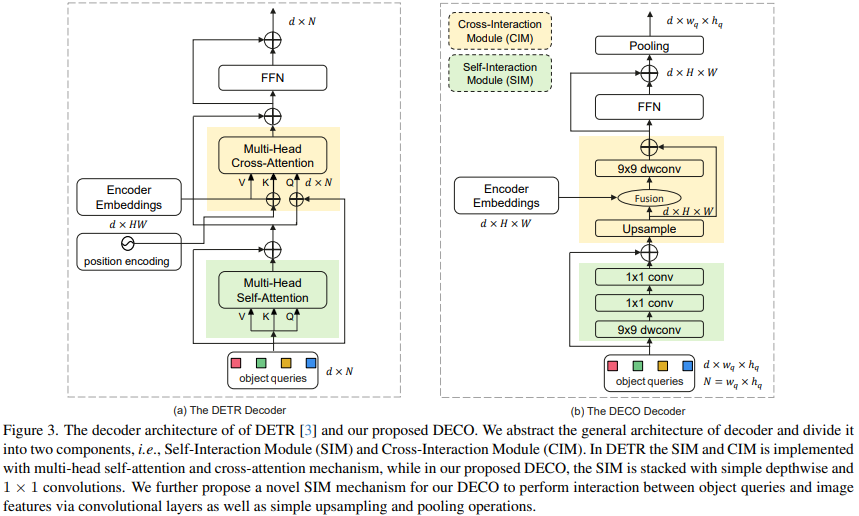 Hier integriert das SIM-Modul hauptsächlich die Ausgabe der Abfrage- und oberen Decoderschicht. Dieser Teil der Struktur kann aus mehreren Faltungsschichten bestehen, wobei eine 9x9-Tiefenfaltung und eine 1x1-Faltung in der räumlichen Dimension bzw. der Kanaldimension verwendet werden . Führen Sie einen Informationsaustausch durch, um die erforderlichen Zielinformationen vollständig zu erhalten, und senden Sie sie zur weiteren Extraktion der Zielerkennungsmerkmale an das nachfolgende CIM-Modul. Die Abfrage ist ein Satz zufällig initialisierter Vektoren. Diese Zahl bestimmt die Anzahl der vom Detektor letztendlich ausgegebenen Erkennungsrahmen. Ihr spezifischer Wert kann entsprechend den tatsächlichen Anforderungen angepasst werden. Da für DECO alle Strukturen aus Faltungen bestehen, wandeln wir Abfragen in zwei Dimensionen um. Beispielsweise können 100 Abfragen zu 10 x 10 Dimensionen werden.
Hier integriert das SIM-Modul hauptsächlich die Ausgabe der Abfrage- und oberen Decoderschicht. Dieser Teil der Struktur kann aus mehreren Faltungsschichten bestehen, wobei eine 9x9-Tiefenfaltung und eine 1x1-Faltung in der räumlichen Dimension bzw. der Kanaldimension verwendet werden . Führen Sie einen Informationsaustausch durch, um die erforderlichen Zielinformationen vollständig zu erhalten, und senden Sie sie zur weiteren Extraktion der Zielerkennungsmerkmale an das nachfolgende CIM-Modul. Die Abfrage ist ein Satz zufällig initialisierter Vektoren. Diese Zahl bestimmt die Anzahl der vom Detektor letztendlich ausgegebenen Erkennungsrahmen. Ihr spezifischer Wert kann entsprechend den tatsächlichen Anforderungen angepasst werden. Da für DECO alle Strukturen aus Faltungen bestehen, wandeln wir Abfragen in zwei Dimensionen um. Beispielsweise können 100 Abfragen zu 10 x 10 Dimensionen werden.
Die Hauptfunktion des CIM-Moduls besteht in der vollständigen Interaktion zwischen Bildmerkmalen und Query, sodass Query die Bildmerkmalsinformationen vollständig wahrnehmen und dadurch die Koordinaten und Kategorien von Zielen im Bild vorhersagen kann. Für die Transformer-Struktur ist es einfach, dieses Ziel durch die Verwendung des Queraufmerksamkeitsmechanismus zu erreichen, aber für die Faltungsstruktur ist die vollständige Interaktion mit den beiden Funktionen die größte Schwierigkeit.
Um die globalen Funktionen des SIM-Ausgangs und des Encoder-Ausgangs mit unterschiedlichen Größen zu verschmelzen, müssen wir die beiden zunächst räumlich ausrichten und dann verschmelzen. Zuerst führen wir ein Next-Neighbor-Upsampling am SIM-Ausgang durch:

damit nach dem Upsampling Die Features haben die gleiche Größe wie die vom Encoder ausgegebenen globalen Features, und dann werden die hochgetasteten Features mit den vom Encoder ausgegebenen globalen Features fusioniert, gehen dann zur Feature-Interaktion in eine tiefe Faltung ein und fügen dann die verbleibende Eingabe hinzu:
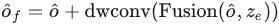
Schließlich werden die interagierten Merkmale über FNN gegen Kanalinformationen ausgetauscht und dann zur Zielnummer zusammengefasst, um die Ausgabeeinbettung des Decoders zu erhalten:
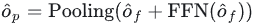
Schließlich senden wir die erhaltene Ausgabeeinbettung zur anschließenden Klassifizierung an den Erkennungskopf und Rückschritt.
Multiskalenfunktionen
Wie das ursprüngliche DETR weist das durch das obige Framework erhaltene DECO einen gemeinsamen Nachteil auf, nämlich das Fehlen von Multiskalenfunktionen, was einen großen Einfluss auf die hochpräzise Zielerkennung hat. Deformable DETR integriert Merkmale verschiedener Skalen mithilfe eines deformierbaren Aufmerksamkeitsmoduls mit mehreren Skalen. Diese Methode ist jedoch stark mit dem Aufmerksamkeitsoperator gekoppelt und kann daher nicht direkt auf unserem DECO verwendet werden. Damit DECO Multi-Scale-Features verarbeiten kann, verwenden wir nach den vom Decoder ausgegebenen Features ein von RT-DETR vorgeschlagenes Cross-Scale-Feature-Fusion-Modul. Tatsächlich wurden nach der Geburt von DETR eine Reihe von Verbesserungsmethoden abgeleitet. Wir glauben, dass viele Strategien auch auf DECO anwendbar sind, und wir hoffen, dass interessierte Menschen dies gemeinsam diskutieren können.
Experiment
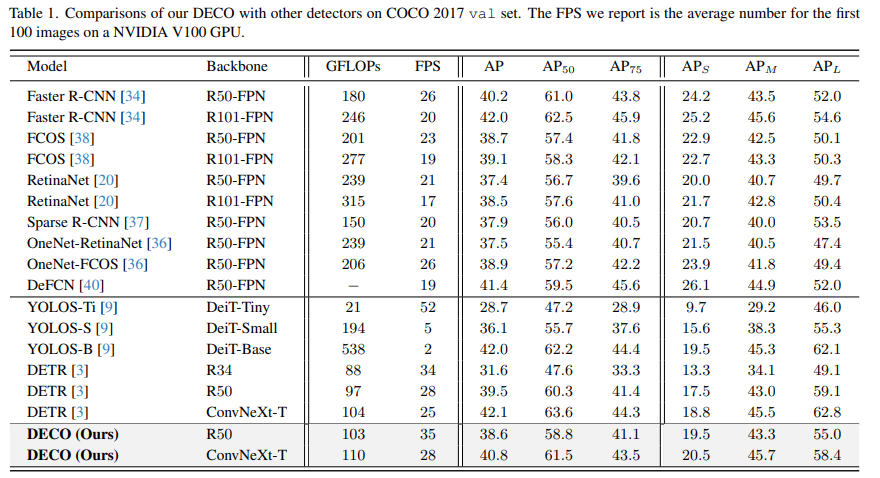
Wir haben Experimente mit COCO durchgeführt und DECO und DETR verglichen, während die Hauptarchitektur unverändert blieb, z. B. die Anzahl der Abfragen konsistent blieb, die Anzahl der Decoderschichten unverändert blieb usw. und nur der Transformer in DETR geändert wurde Die Struktur wird durch unsere oben beschriebene Faltungsstruktur ersetzt. Es ist ersichtlich, dass DECO eine bessere Genauigkeit und einen schnelleren Kompromiss als DETR erreicht hat.
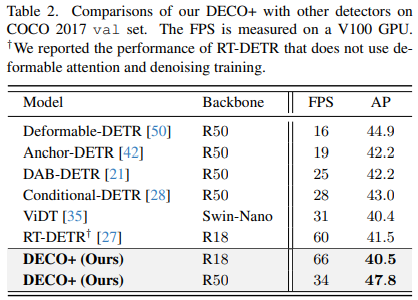
Wir haben DECO, das mit Multiskalenfunktionen ausgestattet ist, auch mit mehr Zielerkennungsmethoden verglichen, darunter viele Variationen von DETR. Wie Sie der Abbildung unten entnehmen können, hat DECO sehr gute Ergebnisse erzielt Leistung als viele frühere Detektoren.
Die DECO-Struktur im Artikel wurde vielen Ablationsexperimenten und Visualisierungen unterzogen, einschließlich der im Decoder ausgewählten spezifischen Fusionsstrategien (Addition, Punktmultiplikation, Concat) und der Einstellung der Abfragedimensionen, um optimale Ergebnisse zu erzielen. usw. gibt es auch einige interessante Erkenntnisse. Weitere detaillierte Ergebnisse und Diskussionen finden Sie im Originalartikel.
Zusammenfassung
In diesem Artikel soll untersucht werden, ob es möglich ist, ein abfragebasiertes End-to-End-Objekterkennungsframework zu erstellen, ohne eine komplexe Transformer-Architektur zu verwenden. Es wird ein neues Erkennungsframework namens Detection ConvNet (DECO) vorgeschlagen, das ein Backbone-Netzwerk und eine Faltungs-Encoder-Decoder-Struktur umfasst. Durch die sorgfältige Gestaltung des DECO-Encoders und die Einführung eines neuartigen Mechanismus ist der DECO-Decoder in der Lage, die Interaktion zwischen der Zielabfrage und den Bildmerkmalen durch Faltungsschichten zu erreichen. Beim COCO-Benchmark wurden Vergleiche mit früheren Detektoren angestellt, und trotz seiner Einfachheit erzielte DECO eine wettbewerbsfähige Leistung in Bezug auf Erkennungsgenauigkeit und Laufgeschwindigkeit. Insbesondere unter Verwendung der ResNet-50- und ConvNeXt-Tiny-Backbones erreichte DECO 38,6 % bzw. 40,8 % AP bei der COCO-Validierung, die auf 35 bzw. 28 FPS eingestellt war, und übertraf damit das DET-Modell. Es besteht die Hoffnung, dass DECO eine neue Perspektive für die Gestaltung von Objekterkennungs-Frameworks bietet.
Das obige ist der detaillierte Inhalt vonDECO: Ein rein auf Faltungsabfragen basierender Detektor übertrifft DETR!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!
Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1657
1657
 14
1415
52
1309
25
1257
29
1229
24
14
1415
52
1309
25
1257
29
1229
24

 Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Es gibt viele Möglichkeiten, Bootstrap -Bilder zu zentrieren, und Sie müssen keine Flexbox verwenden. Wenn Sie nur horizontal zentrieren müssen, reicht die Text-Center-Klasse aus. Wenn Sie vertikal oder mehrere Elemente zentrieren müssen, ist Flexbox oder Grid besser geeignet. Flexbox ist weniger kompatibel und kann die Komplexität erhöhen, während das Netz leistungsfähiger ist und höhere Lernkosten hat. Bei der Auswahl einer Methode sollten Sie die Vor- und Nachteile abwägen und die am besten geeignete Methode entsprechend Ihren Anforderungen und Vorlieben auswählen.
 Ist die H5-Seitenproduktion eine Front-End-Entwicklung?
Apr 05, 2025 pm 11:42 PM
Ist die H5-Seitenproduktion eine Front-End-Entwicklung?
Apr 05, 2025 pm 11:42 PM
Ja, die H5-Seitenproduktion ist eine wichtige Implementierungsmethode für die Front-End-Entwicklung, die Kerntechnologien wie HTML, CSS und JavaScript umfasst. Entwickler bauen dynamische und leistungsstarke H5 -Seiten auf, indem sie diese Technologien geschickt kombinieren, z. B. die Verwendung der & lt; canvas & gt; Tag, um Grafiken zu zeichnen oder JavaScript zu verwenden, um das Interaktionsverhalten zu steuern.
 Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Die Methode zur Anpassung der Größe der Größe der Größe der Größe in CSS ist mit Hintergrundfarben einheitlich. In der täglichen Entwicklung begegnen wir häufig Situationen, in denen wir die Details der Benutzeroberfläche wie Anpassung anpassen müssen ...
 Wie steuern Sie die obere und das Ende der Seiten in den Browser -Druckeinstellungen über JavaScript oder CSS?
Apr 05, 2025 pm 10:39 PM
Wie steuern Sie die obere und das Ende der Seiten in den Browser -Druckeinstellungen über JavaScript oder CSS?
Apr 05, 2025 pm 10:39 PM
So verwenden Sie JavaScript oder CSS, um die obere und das Ende der Seite in den Druckeinstellungen des Browsers zu steuern. In den Druckeinstellungen des Browsers gibt es eine Option, um zu steuern, ob das Display ist ...
 Wie kann man das Problem des zu kleinen Abstands von Spannweiten -Tags nach einer Linienpause elegant lösen?
Apr 05, 2025 pm 06:00 PM
Wie kann man das Problem des zu kleinen Abstands von Spannweiten -Tags nach einer Linienpause elegant lösen?
Apr 05, 2025 pm 06:00 PM
Wie man den Abstand von Span -Tags nach einer neuen Zeile im Webseitenlayout elegant umgeht.
 So stellen Sie die WordPress -Artikelliste an
Apr 20, 2025 am 10:48 AM
So stellen Sie die WordPress -Artikelliste an
Apr 20, 2025 am 10:48 AM
Es gibt vier Möglichkeiten, die WordPress -Artikelliste anzupassen: Verwenden Sie Themenoptionen, verwenden Plugins (z. B. die Bestellung von Post -Typen, WP -Postliste, Boxy -Sachen), Code (Einstellungen in der Datei functions.php hinzufügen) oder die WordPress -Datenbank direkt ändern.
 So zentrieren Sie Bilder in Behältern für Bootstrap
Apr 07, 2025 am 09:12 AM
So zentrieren Sie Bilder in Behältern für Bootstrap
Apr 07, 2025 am 09:12 AM
Übersicht: Es gibt viele Möglichkeiten, Bilder mit Bootstrap zu zentrieren. Grundlegende Methode: Verwenden Sie die MX-Auto-Klasse, um horizontal zu zentrieren. Verwenden Sie die IMG-Fluid-Klasse, um sich an den übergeordneten Container anzupassen. Verwenden Sie die D-Block-Klasse, um das Bild auf ein Element auf Blockebene (vertikale Zentrierung) einzustellen. Erweiterte Methode: Flexbox-Layout: Verwenden Sie die Eigenschaften der Rechtfertigungs-Content-Center- und Align-Item-Center. Gitterlayout: Verwenden Sie die Orts-Items: Center-Eigenschaft. Best Practice: Vermeiden Sie unnötige Verschachtelung und Stile. Wählen Sie die beste Methode für das Projekt. Achten Sie auf die Wartbarkeit des Codes und vermeiden Sie es, die Code -Qualität zu opfern, um die Aufregung zu verfolgen
 Master SQL Auswahlanweisungen: Ein umfassender Handbuch
Apr 08, 2025 pm 06:39 PM
Master SQL Auswahlanweisungen: Ein umfassender Handbuch
Apr 08, 2025 pm 06:39 PM
SQLSelect -Anweisung Detaillierte Erläuterung Die Auswahl der Auswahl ist der grundlegendste und am häufigsten verwendete Befehl in SQL, der zum Extrahieren von Daten aus Datenbanktabellen verwendet wird. Die extrahierten Daten werden als Ergebnismenge dargestellt. SELECT ERHEBT Syntax SelectColumn1, Spalte2, ... fromTable_NamewhereConditionOrdByColumn_Name [ASC | Desc]; Wählen Sie Anweisungskomponentenauswahlklausel (Select): Geben Sie die zu abgerufene Spalte an. Verwenden Sie *, um alle Spalten auszuwählen. Zum Beispiel: SELECTFIRST_NAME, LEST_NAMEFROMEMPOMEDES; Quellklausel (fr
