

Was ist der asynchrone Mechanismus von Redis?

1. Redis-Blockierungspunkte
Objekte, die mit Redis-Instanzen interagieren, und Vorgänge, die während der Interaktion auftreten:
Client: Netzwerk-E/A, Hinzufügen von Schlüssel-Wert-Paaren, Lösch-, Änderungs- und Abfragevorgänge, Datenbankvorgänge;
Disk: RDB-Snapshots generieren, AOF-Protokolle aufzeichnen und AOF-Protokolle neu schreiben;
Master-Slave-Knoten: Die Master-Bibliothek generiert und überträgt RDB-Dateien, die Slave-Bibliothek empfängt RDB-Dateien, löscht die Datenbank und lädt RDB-Dateien ;
Cluster-Instanzen aufteilen: Hash-Slot-Informationen an andere Instanzen übertragen und Daten migrieren.
4 Die Beziehung zwischen klasseninteraktiven Objekten und spezifischen Vorgängen:
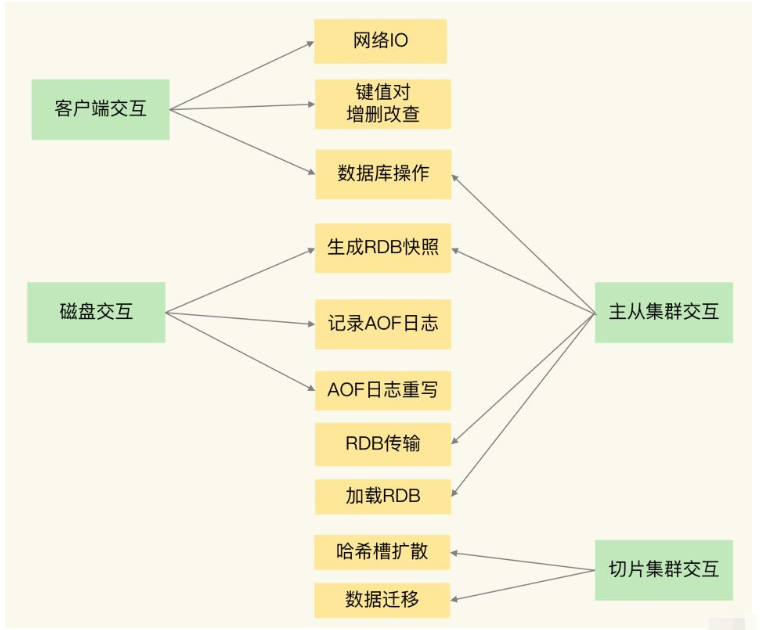
Blockierungspunkte bei der Interaktion mit Clients:
Netzwerk-IO ist manchmal langsam, aber Redis verwendet IO-Mehrkanal-Wiederverwendungsmechanismen, die den Hauptmechanismus verhindern Dadurch wird verhindert, dass der Thread immer auf das Eintreffen von Netzwerkverbindungen oder -anforderungen wartet, sodass Netzwerk-E/A kein Faktor ist, der dazu führt, dass Redis blockiert. Die Hauptaufgabe des Redis-Hauptthreads besteht darin, die Operationen zum Hinzufügen, Löschen, Ändern und Abfragen von Schlüssel-Wert-Paaren durchzuführen, die mit dem Client interagieren. Hochkomplexe Vorgänge zum Hinzufügen, Löschen, Ändern und Abfragen werden Redis definitiv blockieren.
Der Standard zur Beurteilung der Komplexität einer Operation: Sehen Sie, ob die
Komplexität der Operation O(N)ist. Der erste Blockierungspunkt von Redis: vollständige Sammlungsabfrage und Aggregationsvorgang:
Die Komplexität von Vorgängen mit Sammlungen in Redis beträgt normalerweise O (N), daher müssen Sie bei der Verwendung darauf achten.
Zum Beispiel Mengenelemente,vollständige Abfrage, Operationen HGETALL, SMEMBERS und Aggregationsstatistiken, Operationen von Mengen wie Schnittmenge, Vereinigung und Differenz.
Der zweite Blockierungspunkt von Redis: Bigkey-LöschvorgangDer Löschvorgang der Sammlung selbst birgt auch potenzielle Blockierungsrisiken. Der Kern des Löschvorgangs besteht darin, den vom Schlüssel-Wert-Paar belegten Speicherplatz freizugeben. Das Freigeben von Speicher ist nur der erste Schritt, um den Speicherplatz effizienter zu verwalten. Wenn eine Anwendung Speicher freigibt, muss das Betriebssystem den freigegebenen Speicherblock in eine verknüpfte Liste freier Speicherblöcke für die anschließende Verwaltung und Neuzuweisung einfügen.
Drei Schlussfolgerungen werden gezogen:
Wenn die Anzahl der Elemente von 100.000 auf 1 Million steigt, nimmt das Löschen von 4 Hauptsammlungstypen zu. Die Zeit nimmt zu hat sich vom 5-fachen auf fast das 20-fache erhöht. 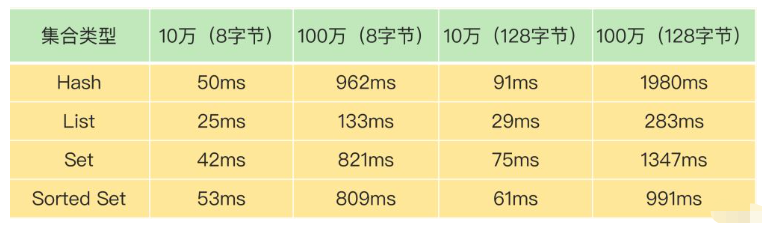
- Beim Löschen eines Satzes mit 1 Million Elementen beträgt die maximale Löschzeit hat einen absoluten Wert von 1,98 Sekunden erreicht. Unter normalen Umständen liegt die Reaktionszeit von Redis im Mikrosekundenbereich. Wenn die Ausführung eines Vorgangs jedoch fast 2 Sekunden dauert, wird der Hauptthread blockiert, was unvermeidlich ist.
- Der dritte Blockierungspunkt von Redis: Löschen der Datenbank
- Da das häufige Löschen von Schlüssel-Wert-Paaren einen potenziellen Blockierungspunkt darstellt, ist das Löschen der Datenbank (z. B. FLUSHDB- und FLUSHALL-Operationen) auch ein potenzieller Blockierungspunkt in der Redis-Datenbank Es besteht die Gefahr einer Blockierung, da dabei alle Schlüssel-Wert-Paare gelöscht und freigegeben werden. Der vierte Blockierungspunkt von Redis: Synchrones Schreiben von AOF-Protokollen
das Erstellen und Übertragen von RDB-Dateien durch untergeordnete Prozesse abgeschlossen
und der Hauptthread wird nicht blockiert.Aber nach dem Empfang der RDB-Datei muss die Slave-Bibliothek den Befehl FLUSHDB verwenden, um die aktuelle Datenbank zu löschen, was zufällig den dritten Blockierungspunkt erreicht.
Nach dem Löschen der aktuellen Datenbank muss die Slave-Bibliothek die RDB-Datei in den Speicher laden. Die Geschwindigkeit dieses Vorgangs hängt eng mit der Größe der RDB-Datei zusammen. Je größer die RDB-Datei, desto langsamer ist der Ladevorgang.
Blockierungspunkte bei der Interaktion mit Slicing-Cluster-Instanzen
Bei der Bereitstellung eines Redis-Slicing-Clusters müssen die jeder Redis-Instanz zugewiesenen Hash-Slot-Informationen zwischen verschiedenen Instanzen übertragen werden, wenn Lastausgleich erforderlich ist oder Instanzen hinzugefügt oder gelöscht werden , werden Daten zwischen verschiedenen Instanzen migriert. Die Informationsmenge im Hash-Slot ist jedoch nicht groß und die Datenmigration erfolgt inkrementell. Bei diesen beiden Arten von Vorgängen besteht nur ein geringes Risiko, dass der Redis-Hauptthread blockiert wird.
Wenn die Redis-Cluster-Lösung verwendet und gleichzeitig bigkey migriert wird, wird der Hauptthread blockiert, da Redis-Cluster eine synchrone Migration verwendet.
Fünf Blockierungspunkte:
Vollständige Abfrage- und Aggregationsvorgänge festlegen;
Löschen der Datenbank;
AOF-Protokollsynchronisierung;
-
Aus der Bibliothek laden RDB-Datei.
2. Blockierungspunkte, die asynchron ausgeführt werden können
Um blockierende Vorgänge zu vermeiden, bietet Redis einen asynchronen Thread-Mechanismus:
Redis startet einige Unterthreads und übergibt dann einige Aufgaben an diese Unterthreads und lassen Sie sie im Hintergrund laufen. Abgeschlossen, ohne dass der Hauptthread diese Aufgaben ausführt. Dadurch wird vermieden, dass der Hauptthread blockiert wird.
Anforderungen für die asynchrone Ausführung von Operationen:
Eine Operation, die asynchron ausgeführt werden kann, ist keine Operation auf dem kritischen Pfad des Redis-Hauptthreads (der Client sendet die Anfrage an Redis und wartet darauf, dass Redis das Datenergebnis zurückgibt).
Nachdem der Haupt-Thread Operation 1 empfangen hat, muss Operation 1 keine bestimmten Daten an den Client zurückgeben. Der Haupt-Thread kann sie zur Fertigstellung an den Hintergrund-Sub-Thread übergeben, und zwar nur muss ein „OK“-Ergebnis an den Client zurückgeben.Wenn der untergeordnete Thread Operation 1 ausführt, sendet der Client Operation 2 an die Redis-Instanz. Der Client muss das von Operation 2 zurückgegebene Datenergebnis verwenden. Wenn Operation 2 kein Ergebnis zurückgibt, befindet sich der Client immer im Wartezustand . 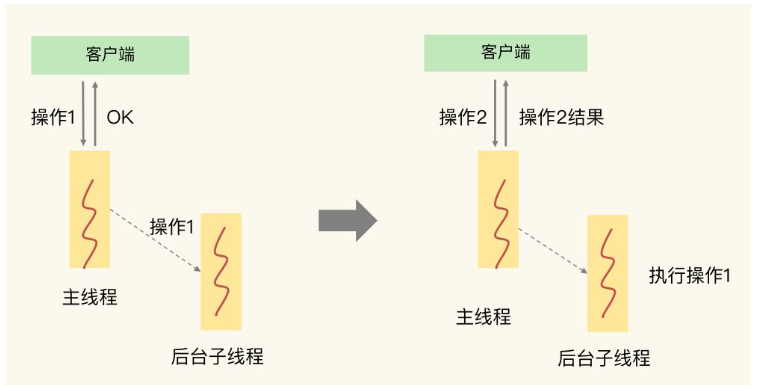
Operation 2 muss das Ergebnis an den Client zurückgeben. Es handelt sich um eine Operation auf dem kritischen Pfad, daher muss der Hauptthread diese Operation sofort abschließen.
Der Redis-Lesevorgang ist ein typischer Vorgang für den kritischen Pfad, da der Client nach dem Senden des Lesevorgangs auf die Rückgabe der gelesenen Daten zur anschließenden Datenverarbeitung wartet. Der erste Blockierungspunkt von Redis, „Sammlung, vollständige Abfrage und Aggregationsvorgang“, umfasst beide Lesevorgänge, und asynchrone Vorgänge können nicht ausgeführt werden.
Löschvorgänge, die keine Rückgabe bestimmter Datenergebnisse an den Client erfordern, sind keine kritischen Pfadvorgänge. „Sowohl ‚Bigkey-Löschung‘ als auch ‚Datenbankfreigabe‘ beinhalten das Löschen von Daten, befinden sich jedoch nicht auf dem kritischen Pfad.“ Sie können Hintergrund-Subthreads verwenden, um Löschvorgänge asynchron durchzuführen.
„synchrones Schreiben des AOF-Protokolls“, um die Datenzuverlässigkeit sicherzustellen, muss die Redis-Instanz sicherstellen, dass die Vorgangsdatensätze im AOF-Protokoll auf die Festplatte geschrieben wurden. Obwohl dieser Vorgang ein Warten der Instanz erfordert, ist dies nicht der Fall Geben Sie bestimmte Datenergebnisse an die Instanz zurück. Daher kann ein untergeordneter Thread gestartet werden, um das AOF-Protokoll synchron zu schreiben.
Um Kunden Datenzugriffsdienste bereitzustellen, muss die vollständige RDB-Datei geladen werden. Diese Operation ist ebenfalls eine Operation auf dem kritischen Pfad und muss vom Hauptthread der Slave-Bibliothek ausgeführt werden.
Mit Ausnahme von „Sammlung vollständiger Abfrage- und Aggregationsvorgänge“ und „Laden von RDB-Dateien aus der Bibliothek“ liegen die an den anderen drei Blockierungspunkten beteiligten Vorgänge nicht auf dem kritischen Pfad. Sie können den asynchronen Sub-Thread-Mechanismus von Redis verwenden Erreichen Sie das Löschen und Löschen von Bigkeys. Die Datenbank und das AOF-Protokoll werden synchron geschrieben.
3. Asynchroner Sub-Thread-Mechanismus
Nachdem der Redis-Hauptthread gestartet wurde, verwendet er die vom Betriebssystem bereitgestellte Funktion pthread_create, um drei Sub-Threads zu erstellen, die für die asynchrone Ausführung von
AOF-Protokollschreibvorgängen verantwortlich sind Löschen von Wertpaaren und Schließen von Dateien.
Der Hauptthread interagiert mit den untergeordneten Threads über eine Aufgabenwarteschlange in Form einer verknüpften Liste. Wenn der Hauptthread den Vorgang zum Löschen des Schlüssel-Wert-Paares und zum Löschen der Datenbank empfängt, kapselt er den Vorgang in eine Aufgabe, stellt ihn in die Aufgabenwarteschlange und gibt dann eine Abschlussmeldung an den Client zurück, die den Löschvorgang anzeigt ist abgeschlossen.
Aber tatsächlich wurde der Löschvorgang zu diesem Zeitpunkt noch nicht ausgeführt. Nachdem der Hintergrund-Subthread die Aufgabe aus der Aufgabenwarteschlange gelesen hat, beginnt er, die Schlüssel-Wert-Paare tatsächlich zu löschen und den entsprechenden Speicherplatz freizugeben. Dieses asynchrone Löschen wird auch „Lazy Deletion“ (Lazy Free) genannt.
Wenn das AOF-Protokoll mit der Option everysec konfiguriert ist, kapselt der Hauptthread den AOF-Protokollschreibvorgang in eine Aufgabe und stellt sie in die Aufgabenwarteschlange. Eine Möglichkeit, es umzuschreiben, ist: Wenn der Hintergrund-Sub-Thread die Aufgabe liest, beginnt er selbst mit der Aufzeichnung im AOF-Protokoll, und der Haupt-Thread kann weiterlaufen, ohne auf das AOF-Protokoll angewiesen zu sein.
Asynchroner Sub-Thread-Ausführungsmechanismus in Redis:
Asynchrone Vorgänge zum Löschen von Schlüssel-Wert-Paaren und zum Löschen von Datenbanken sind Funktionen, die nach Redis 4.0 bereitgestellt werden. Redis bietet außerdem neue Befehle zum Ausführen dieser beiden Vorgänge:
Löschung von Schlüssel-Wert-Paaren: Der Sammlungstyp enthält eine große Anzahl von Elementen (z. B. wenn Millionen oder Dutzende Millionen Elemente gelöscht werden müssen), wird empfohlen, den Befehl UNLINK zu verwenden.
Datenbank löschen: Sie können die Option ASYNC nach den Befehlen FLUSHDB und FLUSHALL hinzufügen Lassen Sie den Hintergrund-Subthread die Datenbank asynchron löschen.
FLUSHDB ASYNC FLUSHALL AYSNC
Das obige ist der detaillierte Inhalt vonWas ist der asynchrone Mechanismus von Redis?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1677
1677
 14
1430
52
1333
25
1278
29
1257
24
14
1430
52
1333
25
1278
29
1257
24

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
So konfigurieren Sie die Ausführungszeit der Lua -Skript in CentOS Redis
Apr 14, 2025 pm 02:12 PM
Auf CentOS -Systemen können Sie die Ausführungszeit von LuA -Skripten einschränken, indem Sie Redis -Konfigurationsdateien ändern oder Befehle mit Redis verwenden, um zu verhindern, dass bösartige Skripte zu viele Ressourcen konsumieren. Methode 1: Ändern Sie die Redis -Konfigurationsdatei und suchen Sie die Redis -Konfigurationsdatei: Die Redis -Konfigurationsdatei befindet sich normalerweise in /etc/redis/redis.conf. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit einem Texteditor (z. B. VI oder Nano): Sudovi/etc/redis/redis.conf Setzen Sie die LUA -Skriptausführungszeit.
 So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
So verwenden Sie die Befehlszeile der Redis
Apr 10, 2025 pm 10:18 PM
Verwenden Sie das Redis-Befehlszeilen-Tool (REDIS-CLI), um Redis in folgenden Schritten zu verwalten und zu betreiben: Stellen Sie die Adresse und den Port an, um die Adresse und den Port zu stellen. Senden Sie Befehle mit dem Befehlsnamen und den Parametern an den Server. Verwenden Sie den Befehl Hilfe, um Hilfeinformationen für einen bestimmten Befehl anzuzeigen. Verwenden Sie den Befehl zum Beenden, um das Befehlszeilenwerkzeug zu beenden.
 So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
So implementieren Sie Redis -Zähler
Apr 10, 2025 pm 10:21 PM
Der Redis-Zähler ist ein Mechanismus, der die Speicherung von Redis-Schlüsselwertpaaren verwendet, um Zählvorgänge zu implementieren, einschließlich der folgenden Schritte: Erstellen von Zählerschlüssel, Erhöhung der Zählungen, Verringerung der Anzahl, Zurücksetzen der Zählungen und Erhalt von Zählungen. Die Vorteile von Redis -Zählern umfassen schnelle Geschwindigkeit, hohe Parallelität, Haltbarkeit und Einfachheit und Benutzerfreundlichkeit. Es kann in Szenarien wie Benutzerzugriffszählungen, Echtzeit-Metrikverfolgung, Spielergebnissen und Ranglisten sowie Auftragsverarbeitungszählung verwendet werden.
 So setzen Sie die Redis -Ablaufpolitik
Apr 10, 2025 pm 10:03 PM
So setzen Sie die Redis -Ablaufpolitik
Apr 10, 2025 pm 10:03 PM
Es gibt zwei Arten von RETIS-Datenverlaufstrategien: regelmäßige Löschung: periodischer Scan zum Löschen des abgelaufenen Schlüssels, der über abgelaufene Cap-Remove-Count- und Ablauf-Cap-Remove-Delay-Parameter festgelegt werden kann. LAZY LELETION: Überprüfen Sie nur, ob abgelaufene Schlüsseln gelöscht werden, wenn Tasten gelesen oder geschrieben werden. Sie können durch LazyFree-Lazy-Eviction, LazyFree-Lazy-Expire, LazyFree-Lazy-User-Del-Parameter eingestellt werden.
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
