
 Technologie-Peripheriegeräte
KI
So erstellen Sie einen intelligenten FAQ -Chatbot mit Agentic Rag
Technologie-Peripheriegeräte
KI
So erstellen Sie einen intelligenten FAQ -Chatbot mit Agentic Rag
So erstellen Sie einen intelligenten FAQ -Chatbot mit Agentic Rag

KI -Agenten sind jetzt ein Teil von Enterprises Big und Small. Von Ausfüllungsformularen in Krankenhäusern und Überprüfung rechtlicher Dokumente bis hin zur Analyse von Videomaterial und Umgang mit Kundenbetreuung haben wir KI -Agenten für alle Arten von Aufgaben. Unternehmen geben häufig Hunderttausende von Dollar für die Einstellung von Kundenunterstützungsmitarbeitern aus, die die Bedürfnisse eines Kunden verstehen und auf der Grundlage der Richtlinien des Unternehmens beheben können. Heute kann ein intelligenter Chatbot zur Beantwortung von FAQs den Kundenservice effizient verbessern. In diesem Artikel lernen wir, wie Sie einen FAQ -Chatbot erstellen, mit dem Kundenabfragen in Sekundenschnelle mit agentischer Lappen (Abruf Augmented Generation), Langgraph und Chromadb gelöst werden können.
Inhaltsverzeichnis
- Kurzliste über Agentenlappen
- Architektur des intelligenten FAQ -Chatbots
- Praktische Implementierung zum Aufbau des intelligenten FAQ-Chatbots
- Schritt 1: Abhängigkeiten installieren
- Schritt 2: Importierende Bibliotheken importieren
- Schritt 3: Richten Sie die OpenAI -API -Schlüssel ein
- Schritt 4: Laden Sie den Datensatz herunter
- Schritt 5: Definieren der Abteilungsnamen für die Zuordnung
- Schritt 6: Definieren Sie die Helferfunktionen
- Schritt 7: Definieren Sie die Langgraph -Agentenkomponenten
- Schritt 8: Definieren Sie die Graph -Funktion
- Schritt 9: Agentenausführung initiieren
- Schritt 10: Testen des Agenten
- Abschluss
Kurzliste über Agentenlappen
Rag ist heutzutage ein heißes Thema. Jeder spricht über Lappen und Bauanwendungen. RAG hilft LLMs, Zugriff auf die Echtzeitdaten zu erhalten, was LLMs genauer ist als je zuvor. Traditionelle Lappensysteme scheitern jedoch in der Regel, wenn es darum geht, die beste Abrufmethode auszuwählen, den Abruf-Workflow zu ändern oder mehrstufige Argumentation zu liefern. Hier kommt der agierende Lappen ins Spiel.
Der Agentenlag verbessert den traditionellen Lappen, indem die Fähigkeiten von AI -Agenten in ihn einbezogen werden. Mit dieser Supermacht können Lumpen den Workflow dynamisch auf der Art der Abfrage, der Multi-Stufe-Argumentation und dem mehrstufigen Abruf verändern. Wir können sogar Tools in das Agentenlag -System integrieren, und es kann dynamisch entscheiden, welches Tool verwendet werden soll. Insgesamt führt dies zu einer verbesserten Genauigkeit und macht das System effizienter und skalierbarer.
Hier ist ein Beispiel für einen agierenden Lag -Workflow.
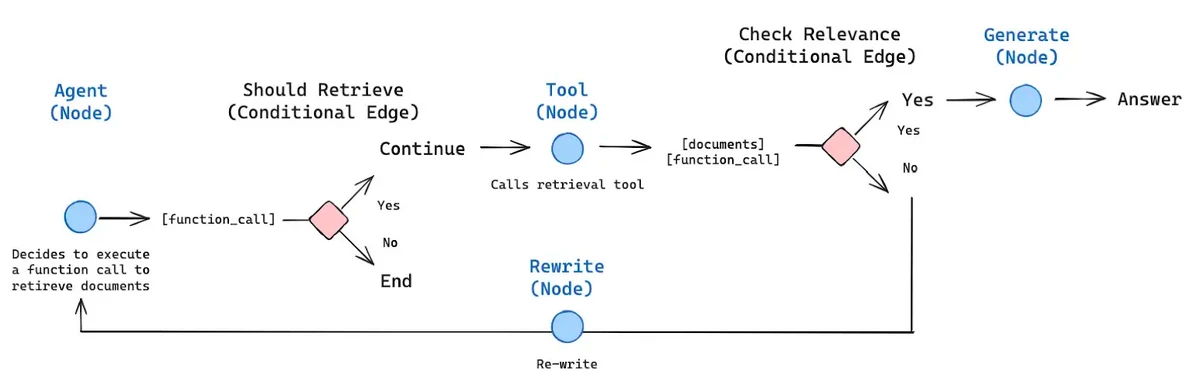
Das obige Bild bezeichnet die Architektur eines agierenden Rag -Frameworks. Es zeigt, wie KI -Agenten in Kombination mit Lappen unter bestimmten Bedingungen Entscheidungen treffen können. Das Bild zeigt deutlich, dass der Agent entscheidet, welche Kante basierend auf dem bereitgestellten Kontext ausgewählt werden soll, wenn ein bedingter Knoten vorhanden ist.
Lesen Sie auch: 10 Geschäftsanwendungen von LLM -Agenten
Architektur des intelligenten FAQ -Chatbots
Jetzt werden wir in die Architektur des Chatbots eintauchen, den wir bauen werden. Wir werden untersuchen, wie es funktioniert und was seine wichtigen Komponenten sind.
Die folgende Abbildung zeigt die Gesamtstruktur unseres Systems. Wir werden dies mit Langgraph implementieren, einem Open-Source-AI-Agenten-Framework von Langchain.
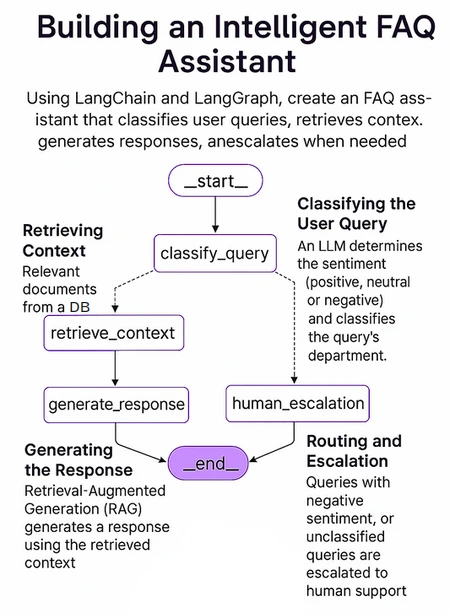
Die Schlüsselkomponenten unseres Systems umfassen:
- LangGraph: Ein leistungsstarkes Rahmen für Open-Source-Ai-Agenten, das komplexe, multi-agenten-, zyklische Graph-basierte Wirkstoffe effizient erzeugt. Diese Agenten können die Staaten im gesamten Workflow aufrechterhalten und die komplexen Abfragen effizient behandeln.
- LLM: Ein effizientes und leistungsstarkes großes Sprachmodell, das den Anweisungen des Benutzers folgen und entsprechend mit dem besten Wissen antworten kann. Hier verwenden wir O4-Mini von OpenAI, ein kleines Argumentationsmodell, das speziell für Geschwindigkeit, Erschwinglichkeit und Werkzeuggebrauch ausgelegt ist.
- Vektordatenbank: Eine Vektordatenbank wird verwendet, um Vektor -Einbettungen zu speichern, zu verwalten und abzurufen, die normalerweise die numerische Darstellung von Daten sind. Hier verwenden wir Chromadb, eine Open -Source -AI -native Vektor -Datenbank. Es soll die Systeme befähigen, die von Ähnlichkeitssuche, semantischen Suchvorgängen und anderen Aufgaben mit Vektordaten abhängen.
Auch lesen
Praktische Implementierung zum Aufbau des intelligenten FAQ-Chatbots
Jetzt werden wir den End-to-End-Workflow unseres Chatbot basierend auf der oben diskutierten Architektur implementieren. Wir werden es Schritt für Schritt mit detaillierten Erklärungen, Code und Beispielausgängen machen. Also fangen wir an.
Schritt 1: Abhängigkeiten installieren
Wir werden zunächst alle erforderlichen Bibliotheken in unser Jupyter -Notizbuch installieren. Dazu gehören Bibliotheken wie Langchain, Langgraph, Langchain-Openai, Langchain-Community, Chromadb, Openai, Python-Dotenv, Pydantic und Pysqlite3.
!
Schritt 2: Importierende Bibliotheken importieren
Jetzt sind wir bereit, alle verbleibenden Bibliotheken zu importieren, die wir für dieses Projekt benötigen.
OS importieren JSON importieren Aus dem Einteichen der Einfuhrliste, typedDict, kommentiert, dikt aus dotenv import load_dotenv # Langchain & Langgraph spezifische Importe aus Langchain_openai import Chatopenai, OpenAiembedings von Langchain_core.Prompts importieren ChatpromptTemplate, MessagePlaceHolder aus pydantischem Import -Basemodel, Feld von Langchain_core.Messages Import SystemMessage, HumanMessage, Aimessage Aus Langchain_core.dokumenten importieren Sie Dokument von Langchain_Community.VectorStores importieren Chroma von Langgraph.graph import stategraph, Ende
Schritt 3: Richten Sie die OpenAI -API -Schlüssel ein
Geben Sie Ihren OpenAI -Schlüssel ein, um sie als Umgebungsvariable festzulegen.
von Getpass Import Getpass
Openai_api_key = getPass ("OpenAI -API -Schlüssel:")
load_dotenv ()
os.getenv ("openai_api_key")Schritt 4: Laden Sie den Datensatz herunter
Für verschiedene Abteilungen haben wir im JSON -Format einen Beispiel für FAQ -Datensatz im JSON -Format erstellt. Wir müssen es aus dem Laufwerk herunterladen und es entpacken.
! ! Unzip -o /content/blog_faq_files.zip
Ausgabe:
Schritt 5: Definieren der Abteilungsnamen für die Zuordnung
Lassen Sie uns nun die Zuordnung der Abteilungen so definieren, dass unser Agentensystem verstehen kann, welche Datei zu welcher Abteilung gehört.
# Definieren Sie die Abteilungsnamen (Stellen Sie sicher, dass diese Metadaten übereinstimmen, die während der Einnahme verwendet werden).
Abteilungen = [
"Kundendienst",
"Produktinformationen",
"Treueprogramm / Belohnungen"
]
UNNAKTIERUNG_DEPARTMENT = "Unbekannt/andere"
FAQ_FILES = {
"Kundendienst": "Customer_Support_Faq.json",
"Produktinformationen": "product_information_faq.json",
"Loyalitätsprogramm / Belohnungen": "loyaly_program_faq.json",
}Schritt 6: Definieren Sie die Helferfunktionen
Wir werden einige Helferfunktionen definieren, die für das Laden von FAQs aus den JSON -Dateien verantwortlich sind und sie auch in Chromadb speichern.
1. Load_faqs (…): Es ist eine Helferfunktion, die die FAQ aus den JSON -Dateien lädt und in einer Liste namens All_faqs speichern.
Def load_faqs (Datei_Paths: dict [str, str]) -> dict [str, list [dict [str, str]]]:
"" "Lädt QA -Paare aus JSON -Dateien für jede Abteilung." "" "
All_faqs = {}
print ("Faqs laden ...")
Für die Abteilung file_path in File_paths.items ():
versuchen:
mit Open (Datei_Path, 'R', coding = 'utf-8') als f:
All_faqs [Dept] = json.load (f)
print (f " - geladen {len (All_faqs [Dept])} FAQs für {Dept}")
Außer FilenotFoundError:
print (f " - WARNUNG: FAQ -Datei nicht für {Dept}: {file_path}. Überspringen.")
außer JSON.JSONDECODEError:
print (f " - Fehler: Ich konnte JSON nicht für {Dept} aus {file_path} überspringen.")
RECHT ALL_FAQS2. Setup_chroma_Vector_Store (…): Diese Funktion richtet den Chromadb ein, um die Vektor -Einbettungen zu speichern. Hierzu definieren wir zunächst die Chroma -Konfiguration, dh das Verzeichnis, das die Chroma -Datenbankdateien enthält. Dann werden wir die FAQs in Langchains Dokumente umwandeln. Es enthält Metadaten und Seiteninhalte, die das vordefinierte Format für einen genauen Lappen sind. Wir können Fragen und Antworten für ein besseres Kontextabruf kombinieren oder einfach die Antwort einbetten. Wir behalten die Frage auch die Abteilungsnamen in den Metadaten.
# Chromadb -Konfiguration
Chroma_Persist_directory = "./Chroma_db_store"
CHROMA_Collection_Name = "CHATBOT_FAQS"
Def setup_chroma_vector_store (
All_faqs: dict [str, list [dict [str, str]],
persist_directory: str,
Collection_Name: str,
Einbettung_Model: Openaiembeding,,
) -> Chroma:
"" "Erstellt oder lädt einen Chroma -Vektorspeicher mit FAQ -Daten und Metadaten." "" "
Dokumente = []
print ("\ nprepararing Dokumente für Vektor Store ...")
Für die Abteilung, FAQs in All_faqs.items ():
Für FAQ in FAQs:
# Kombinieren Sie Fragen und Antworten für eine bessere Kontexteinbettung oder betten Sie einfach Antworten ein
# content = f "Frage: {faq ['Frage']} \ nanswer: {faq ['Antwort']}"
Content = FAQ ['Antwort'] # Einbettung oft nur die Antwort ist für das Abrufen von FAQ wirksam
doc = dokument (
Page_Content = Inhalt,
metadata = {
"Abteilung": Abteilung,
"Frage": FAQ ['Frage'] # Halten Sie die Frage in Metadaten für eine potenzielle Anzeige
}
)
documents.append (doc)
print (f "Gesamtdokumente vorbereitet: {Len (Dokumente)}")
Wenn nicht Dokumente:
ValueError erhöhen ("Keine Dokumente, die zum Vektorspeicher hinzugefügt wurden. Überprüfen Sie die FAQ -Laden.")
print (f "Initialisieren von Chromadb -Vektor Store (Persistenz: {persist_directory}) ...")
vector_store = chroma (
Collection_name = Collection_name,
Einbettung_Function = Einbettung_Model,
persist_directory = persist_directory,
)
versuchen:
vector_store = chroma.from_documents (
Dokumente = Dokumente,
Einbettung = Einbettung_Model,
persist_directory = persist_directory,
Collection_name = Collection_name
)
print (f "Erstellt und besiedelt Chromadb mit {len (Dokumenten)} Dokumenten.")
Vector_Store.Persist () # Sicherstellen Sie die Persistenz nach der Erstellung
print ("Vektor Store bestand"))
außer Ausnahme als create_e:
print (f "Fataler Fehler: Kann nicht Chroma Vector Store erstellen: {create_e}")
Erhöhen create_e
print ("Chromadb -Setup vollständig.")
return vector_storeSchritt 7: Definieren Sie die Langgraph -Agentenkomponenten
Definieren wir nun unsere KI -Agentenkomponente, die die Hauptkomponente unseres Arbeitsflusss ist.
1. Zustandsdefinition: Es handelt sich um eine Python -Klasse, die den aktuellen Stand des Agenten während der Leitung enthält. Es enthält Variablen wie Abfrage, Stimmung, Abteilung.
Klassenagentenstate (TypedDict): Abfrage: str Sentiment: str Abteilung: str Kontext: STR # Abgerufener Kontext für RAG Antwort: STR # endgültige Antwort auf den Benutzer Fehler: str | Keine #, um potenzielle Fehler zu erfassen
2. Pydantisches Modell: Wir haben hier ein pydantisches Modell definiert, das eine strukturierte LLM -Ausgabe gewährleistet. Es enthält ein Gefühl, das drei Werte hat, „positiv“, „negativ“ und „neutral“ und einen Abteilungsnamen, der von der LLM vorhergesagt wird.
Klasse ClassificationResult (Basemodel):
"" Strukturierte Ausgabe für die Abfrageklassifizierung. "" "
SENTIMIENT: STR = Field (Beschreibung = "Stimmung der Abfrage (positiv, neutral, negativ)"))
Abteilung: STR = Field (Beschreibung = F "Relevanteste Abteilung aus der Liste: {Abteilungen [UNBUKED_DEPARTMENT]}. Verwenden Sie '{unbekannt_Department}', wenn nicht sicher oder nicht zutreffend.")3. Knoten: Im Folgenden finden Sie die Knotenfunktionen, mit denen jede Aufgabe einzeln verarbeitet wird.
- Classify_Query_Node: Es klassifiziert die eingehende Abfrage in das Gefühl sowie den Namen der Zielabteilung basierend auf der Art der Abfrage.
- ARINGABE_CONTEXT_NODE: Er führt den Lappen über die Vektor -Datenbank aus und filtert die Ergebnisse auf der Grundlage des Abteilungsnamens.
- Generate_Response_Node: Es generiert die endgültige Antwort basierend auf der Abfrage und dem abgerufenen Kontext aus der Datenbank.
- Human_escalation_node: Wenn das Gefühl negativ ist oder die Zielabteilung unbekannt ist, eskaliert es die Abfrage an den menschlichen Benutzer.
- Route_Query: Es bestimmt den nächsten Schritt basierend auf der Abfrage und Ausgabe des Klassifizierungsknotens.
# 3. Knoten
Def klassify_query_node (Status: AgentState) -> dict [str, str]:
"" "
Klassifiziert die Benutzerabfrage für Stimmung und Zielabteilung mit einem LLM.
"" "
print ("--- Klassifizierung der Abfrage ---")
query = state ["query"]
llm = chatopenai (model = "o4-mini", api_key = openai_api_key) # Verwenden Sie ein zuverlässiges, billigeres Modell
# Vorbereitung der Eingabeaufforderung für die Klassifizierung
prompt_template = chatpromptTemplate.from_messages ([[
SystemMessage (
Content = f "" "Sie sind ein erfahrener Abfrageklassifizierer für ShopUnow, ein Einzelhandelsunternehmen.
Analysieren Sie die Abfrage des Benutzers, um die Stimmung und die relevanteste Abteilung zu bestimmen.
Die verfügbaren Abteilungen sind: {',' .Join (Abteilungen)}.
Wenn die Abfrage nicht eindeutig in eine davon passt oder mehrdeutig ist, klassifizieren Sie die Abteilung als "{unbekannt_department}".
Wenn die Abfrage Frustration, Wut, Unzufriedenheit ausdrückt oder sich über ein Problem beschwert, klassifizieren Sie das Gefühl als "negativ".
Wenn die Abfrage eine Frage stellt, nach Informationen sucht oder eine neutrale Erklärung abgibt, klassifizieren Sie das Gefühl als "neutral".
Wenn die Abfrage Zufriedenheit, Lob oder positives Feedback ausdrückt, klassifizieren Sie das Gefühl als "positiv".
Reagieren Sie nur mit dem strukturierten JSON -Ausgangsformat. "" "
),
HumanMessage (content = f "Benutzerabfrage: {Abfrage}")
]))
# LLM -Kette mit strukturiertem Ausgang
classifier_chain = prompt_template | llm.with_structured_output (ClassificationResult)
versuchen:
Ergebnis: ClassificationResult = Classifier_Chain.invoke ({}) # Übergeben Sie leeres Diktieren, da die Eingabe jetzt erforderlich erscheint
print (f "Klassifizierung Ergebnis: Sentiment = '{result.Sentiment}', Abteilung = '{result.department}'"))
zurückkehren {
"Sentiment": result.sentiment.lower (), # normalisieren
"Abteilung": Ergebnis. Abteilung
}
außer Ausnahme als E:
print (f "Fehler während der Klassifizierung: {e}")
zurückkehren {
"Sentiment": "Neutral", # Standard beim Fehler
"Abteilung": UNBUKUSE_DEPARTMENT,
"Fehler": f "Klassifizierung fehlgeschlagen: {e}"
}
Def retrieve_context_node (Status: AgentState) -> dict [str, str]:
"" "
Ruft den relevanten Kontext aus dem Vektor Store basierend auf Abfrage und Abteilung ab.
"" "
print ("--- Abrufen Kontext ---")
query = state ["query"]
Abteilung = Staat ["Abteilung"]
Wenn nicht Abteilung oder Abteilung == UNBUKTE_DEPARTMENT:
print ("Abrufen überspringen: Abteilung unbekannt oder nicht zutreffend.")
Rückgabe {"Kontext": "", "Fehler": "Ich kann den Kontext ohne gültige Abteilung nicht abrufen."}
# Initialisieren Sie das Einbettungsmodell und den Vektorspeicherzugriff
Einbettung_Model = openAiembeding (api_key = openai_api_key)
vector_store = chroma (
Collection_name = Chroma_Collection_Name,
Einbettung_Function = Einbettung_Model,
persist_directory = chroma_persist_directory,
)
retriever = vector_store.as_retriever (
Search_type = "Ähnlichkeit",
search_kwargs = {
'K': 3, # Relieve Top 3 Relevante Dokumente abrufen
'Filter': {'Abteilung': Abteilung} # *** Kritisch: Filter nach Abteilung ***
}
)
versuchen:
abgerufen_docs = retriever.invoke (Abfrage)
If abgerufen_docs:
context = "\ n \ n --- \ n \ n" .Join ([doc.page_content für doc in rendhev_docs])
print (f "abgerufen {len (abgerufen_docs)} Dokumente für die Abteilung '{Abteilung}'.").
# print (f "Kontext -Snippet: {Kontext [: 200]} ...") # Optional: Protokolls -Snippet
Rückgabe {"Kontext": Kontext, "Fehler": Keine}
anders:
Druck ("Keine relevanten Dokumente im Vektor Store für diese Abteilung.")
Rückgabe {"Kontext": "", "Fehler": "Kein relevanter Kontext gefunden."}
außer Ausnahme als E:
print (f "Fehler während des Kontext -Abrufens: {e}"))
Rückgabe {"Kontext": "", "Fehler": f "Abrufen fehlgeschlagen: {e}"}
Def generate_response_node (Status: AgentState) -> dict [str, str]:
"" "
Generiert eine Antwort mit Lappen basierend auf der Abfrage und dem abgerufenen Kontext.
"" "
print ("--- reaktion erzeugen (rag) ---")
query = state ["query"]
context = state ["context"]
llm = chatopenai (model = "o4-mini", api_key = openai_api_key) # kann ein fähigerer Modell für die Generation verwenden
Wenn nicht Kontext:
print ("Kein Kontext bereitgestellt, generische Antwort generieren.")
# Fallback, wenn das Abrufen fehlgeschlagen ist, aber Routing entschied trotzdem einen Lumpenpfad
Antwort_text = "Ich konnte keine spezifischen Informationen zu Ihrer Abfrage in unserer Wissensbasis finden. Können Sie bitte umformulieren oder weitere Details angeben?"
Rückgabe {"Antwort": response_text}
# RAG -Eingabeaufforderung
prompt_template = chatpromptTemplate.from_messages ([[
SystemMessage (
content = f "" "Sie sind ein hilfreicher KI -Chatbot für ShopUnow. Beantworten Sie die Abfrage des Benutzers * nur * auf den bereitgestellten Kontext.
Seien Sie prägnant und adressieren Sie die Abfrage direkt. Wenn der Kontext die Antwort nicht enthält, geben Sie dies klar an.
Informieren Sie sich nicht.
Kontext:
---
{Kontext}
--- "" "
),
HumanMessage (content = f "Benutzerabfrage: {Abfrage}")
]))
Rag_chain = prompt_template | llm
versuchen:
response = rag_chain.invoke ({})
response_text = response.content
print (f "generierte RAG -Antwort: {response_text [: 200]} ...")
Rückgabe {"Antwort": response_text}
außer Ausnahme als E:
print (f "Fehler während der Antwortgenerierung: {e}")
Rückgabe {"Antwort": "Entschuldigung, ich habe einen Fehler beim Generieren der Antwort aufgetreten.", "Fehler": F "Generation fehlgeschlagen: {e}"}
Def Human_escalation_node (Status: AgentState) -> DICT [STR, STR]:
"" "
Bietet eine Nachricht, die angibt, dass die Abfrage zu einem Menschen eskaliert wird.
"" "
print ("--- Eskalieren zur menschlichen Unterstützung ---")
Grund = ""
Wenn State.get ("Sentiment") == "Negativ":
Grund = "Aufgrund der Art Ihrer Abfrage", "
ELIF STATE.get ("Abteilung") == UNBUKENTE_DEPARTMENT:
Grund = "Da Ihre Abfrage eine besondere Aufmerksamkeit erfordert,"
response_text = f "{euro} Ich muss dies zu unserem menschlichen Support -Team eskalieren. Sie werden Ihre Anfrage überprüfen und sich in Kürze bei Ihnen melden. Vielen Dank für Ihre Geduld."
print (f "Eskalationsnachricht: {response_text}")
Rückgabe {"Antwort": response_text}
# 4. Bedingte Routing -Logik
Def Route_Query (Status: AgentState) -> Str:
"" "Bestimmt den nächsten Schritt basierend auf den Klassifizierungsergebnissen." "" "
print ("--- Routing-Entscheidung ---")
Sentiment = State.get ("Sentiment", "Neutral")
Abteilung = State.get ("Abteilung", unbekannt_Department)
Wenn Sentiment == "negativ" oder Abteilung == UNBUKTE_DEPARTMENT:
print (f "Routing an: Human_escalation (Sentiment: {Sentiment}, Abteilung: {Abteilung})")
Rückgabe "Human_escalation"
anders:
print (f "routing to: retrieve_context (Sentiment: {Sentiment}, Abteilung: {Abteilung})")
zurück "retrieve_context" zurückgebenSchritt 8: Definieren Sie die Graph -Funktion
Erstellen wir die Funktion für das Diagramm und weisen dem Diagramm die Knoten und Kanten zu.
# --- Grafikdefinition ---
Def Build_agent_Graph (Vector_Store: Chroma) -> Staategraph:
"" "Baut den Langgraph -Agenten." "" "
Graph = stategraph (AgentState)
# Knoten hinzufügen
Graph.add_node ("klassifizieren_query", klassifizieren_query_node)
Graph.ADD_NODE ("RECRIEVE_CONTEXT", REDRIEVE_CONTEXT_NODE)
Graph.add_node ("generate_response", generate_response_node)
graph.add_node ("Human_escalation", Human_escalation_node)
# Einstiegspunkt festlegen
Graph.set_entry_point ("klassifizieren_query")
# Kanten hinzufügen
Graph.add_conditional_edges (
"Classify_query", # Quellknoten
Route_Query, # Funktion zur Bestimmung der Route
{ # Mapping: Ausgabe von Route_query -> Zielknoten
"Retrieve_Context": "Retrieve_Context",
"Human_escalation": "Human_escalation"
}
)
Graph.add_Edge ("RECRIEVE_CONTEXT", "generate_response")
Graph.add_Edge ("generate_response", Ende)
Graph.add_Edge ("Human_escalation", Ende)
# Kompilieren Sie die Grafik
# memory = sqliteSaver.from_conn_string (": memory:") # Beispiel für In-Memory-Persistenz
app = graph.compile () # # checkPointer = Speicher für statige Gespräche optional
print ("\ nagent Graph erfolgreich zusammengestellt.")
App zurückgebenSchritt 9: Agentenausführung initiieren
Jetzt werden wir den Agenten initialisieren und den Workflow ausführen.
1. Laden wir zunächst die FAQs.
# 1. laden FAQs
FAQS_DATA = load_faqs (faq_files)
Wenn nicht FAQS_DATA:
print ("Fehler: Keine FAQ -Daten geladen. Beenden.")
Ausfahrt()Ausgabe:

2. Richten Sie die Einbettungsmodelle ein. Hier werden wir OpenAi -Einbettungsmodelle für ein schnelleres Abruf einrichten.
# 2. Setup Vector Store Einbettung_Model = openAiembeding (api_key = openai_api_key) vector_store = setup_chroma_vector_store ( FAQS_DATA, Chroma_persist_directory, Chroma_collection_name, Einbettung_Model )
Ausgabe:

Lesen Sie auch: Wie wählen Sie die richtige Einbettung für Ihr Lappenmodell?
3. Erstellen Sie nun den Mittel mithilfe der vordefinierten Funktion und visualisieren Sie den Wirkstofffluss mit dem Meerjungfrau -Diagramm.
# 3.. Erstellen Sie das Agentendiagramm Agent_app = Build_agent_graph (vector_store) Von Ipython.display Import Display, Bild, Markdown display (image (agent_app.get_graph (). Draw_mermaid_png ())))
Ausgabe:

Schritt 10: Testen des Agenten
Wir sind im letzten Teil unseres Workflows angekommen. Bisher haben wir mehrere Knoten und Funktionen gebaut. Jetzt ist es an der Zeit, unseren Agenten zu testen und die Ausgabe zu sehen.
1. Definieren Sie zuerst die Testfragen.
# Testen Sie den Agenten test_queries = [ "Wie verfolge ich meine Bestellung?", "Was ist die Rückgaberichtlinie?", "Erzähl mir von den 'Urban Explorer' -Jacke -Materialien.",. ]
2. Jetzt testen wir den Agenten.
print ("\ n --- Testagent ---")
Für Abfragen in test_queries:
print (f "\ ninput query: {query}")
# Definieren Sie die Eingabe für den Graph -Aufruf
inputs = {"Abfrage": Abfrage}
# versuchen:
# Rufen Sie die Grafik auf
# Das Konfigurationsargument ist optional, aber bei Bedarf für die staatliche Ausführung nützlich
# config = {"Konfigurierbar": {"thread_id": "user_123"}} # Beispielkonfiguration
Final_State = agent_app.invoke (Eingänge) #, config = config)
print (f "Final State Department: {Final_State.get ('Abteilung')}")
print (f "Finale Status Sentiment: {Final_State.get ('Sentiment')}")
print (f "Agent Antwort: {Final_state.get ('Antwort')}")
If Final_State.get ('Fehler'):
print (f "Fehler aufgenommen: {Final_state.get ('Fehler')}"))
# außer Ausnahme als E:
# print (f "Fehlerläufe Agent -Diagramm für Abfrage '{Query}': {e}"))
# Traceback importieren
# TraceBack.print_exc () # detailliertes Traceback zum Debuggen drucken
print ("\ n --- Agentstests vollständig ---")print („\ n - Testagent -“)
Ausgabe:
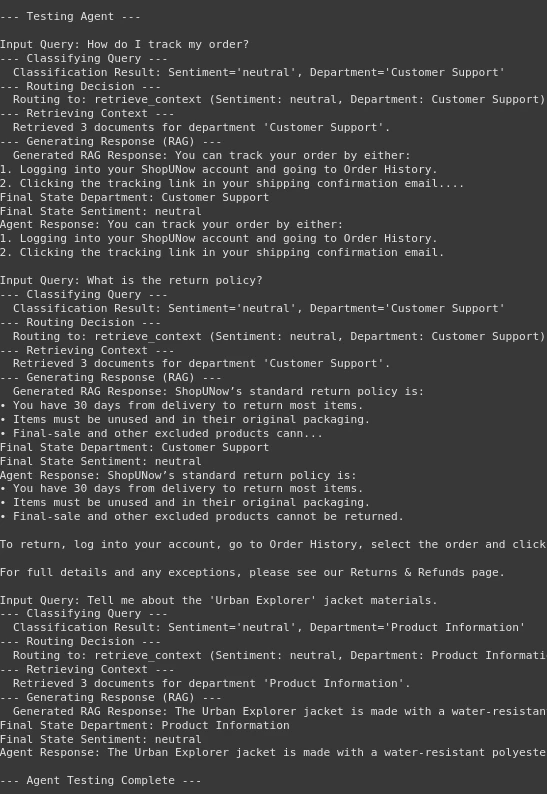
Wir können in der Ausgabe sehen, dass unser Agent gut abschneidet. Zuerst klassifiziert es die Abfrage und leitet dann die Entscheidung an den Abrufknoten oder den menschlichen Knoten. Anschließend kommt der Abrufteil erfolgreich ab, um den Kontext aus der Vektor -Datenbank abzurufen. Letztendlich generieren Sie die Antwort nach Bedarf. Daher haben wir unseren intelligenten FAQ -Chatbot gemacht.
Sie können mit dem gesamten Code hier auf das Colab -Notizbuch zugreifen.
Abschluss
Wenn Sie so weit erreicht haben, bedeutet dies, dass Sie gelernt haben, wie man einen intelligenten FAQ -Chatbot mit Agentic Rag und Langgraph erstellt. Hier haben wir gesehen, dass der Aufbau eines intelligenten Agenten, der eine Entscheidung argumentieren und treffen kann, nicht so schwer ist. Der von uns erstellte Agenten -Chatbot ist kostengünstig, schnell und kann den Kontext der Fragen oder Eingabebfragen vollständig verstehen. Die Architektur, die wir hier verwendet haben, ist vollständig anpassbar, was bedeutet, dass man jeden Knoten des Agenten für seinen jeweiligen Anwendungsfall bearbeiten kann. Mit Agentenlappen, Langgraph und Chromadb war es noch nie so einfach, Agenten zu machen. Nie so einfach. Ich bin sicher, was wir in diesem Handbuch behandelt haben, hat Ihnen das grundlegende Wissen gegeben, um komplexeres System mit diesen Tools zu erstellen.
Das obige ist der detaillierte Inhalt vonSo erstellen Sie einen intelligenten FAQ -Chatbot mit Agentic Rag. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1673
1673
 14
1428
52
1333
25
1277
29
1257
24
14
1428
52
1333
25
1277
29
1257
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Gemini als Grundlage der KI -Strategie von Google Gemini ist der Eckpfeiler der AI -Agentenstrategie von Google und nutzt seine erweiterten multimodalen Funktionen, um Antworten auf Text, Bilder, Audio, Video und Code zu verarbeiten und zu generieren. Entwickelt von Deepm
 Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
"Super froh, Ihnen mitteilen zu können, dass wir Pollenroboter erwerben, um Open-Source-Roboter in die Welt zu bringen", sagte Hugging Face auf X.
 DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
In einer bedeutenden Entwicklung für die KI-Community haben Agentica und gemeinsam KI ein Open-Source-KI-Codierungsmodell namens DeepCoder-14b veröffentlicht. Angebotsfunktionen der Codegenerierung mit geschlossenen Wettbewerbern wie OpenAI,
