
 Technologie-Peripheriegeräte
KI
Optimierung der KI -Leistung: Ein Leitfaden zur effizienten LLM -Bereitstellung
Technologie-Peripheriegeräte
KI
Optimierung der KI -Leistung: Ein Leitfaden zur effizienten LLM -Bereitstellung
Optimierung der KI -Leistung: Ein Leitfaden zur effizienten LLM -Bereitstellung

Mastering großes Sprachmodell (LLM), das für Hochleistungs-AI-Anwendungen dient
Der Aufstieg der künstlichen Intelligenz (KI) erfordert eine effiziente LLM -Bereitstellung für optimale Innovation und Produktivität. Stellen Sie sich vor, Sie haben einen KSA-betriebenen Kundendienst vor, der Ihre Bedürfnisse oder Datenanalyse-Tools vorwegnimmt, die sofortige Erkenntnisse liefern. Dies erfordert das Mastering-LLM-Servieren-Umwandlung von LLMs in Hochleistungsanwendungen, Echtzeitanwendungen. In diesem Artikel werden effiziente LLM -Servier- und -bereitstellungen untersucht, die optimale Plattformen, Optimierungsstrategien und praktische Beispiele für die Erstellung leistungsstarker und reaktionsschneller KI -Lösungen abdecken.

Wichtige Lernziele:
- Erfassen Sie das Konzept der LLM-Bereitstellung und deren Bedeutung in Echtzeitanwendungen.
- Untersuchen Sie verschiedene LLM -Servier -Frameworks, einschließlich ihrer Funktionen und Anwendungsfälle.
- Gewinnen Sie praktische Erfahrungen mit Code -Beispielen für die Bereitstellung von LLMs mithilfe verschiedener Frameworks.
- Lernen Sie, LLM -Servier -Frameworks für Latenz und Durchsatz zu vergleichen und zu benennen.
- Identifizieren Sie ideale Szenarien für die Verwendung spezifischer LLM -Servier -Frameworks in verschiedenen Anwendungen.
Dieser Artikel ist Teil des Datenwissenschaftsblogathons.
Inhaltsverzeichnis:
- Einführung
- Triton Inference Server: Ein tiefer Tauchgang
- Optimierung von Umarmungsface -Modellen für die Produktion von Produktionstexten
- VLLM: Revolutionierung der Stapelverarbeitung für Sprachmodelle
- DeepSpeed-Mii: Nutzung von Deepspeed für eine effiziente LLM-Bereitstellung
- OpenllM: Anpassungsfähige Framework -Integration
- Skalierungsmodellbereitstellung mit Ray Serve
- Beschleunigung der Schlussfolgerung mit ctranslate2
- Latenz- und Durchsatzvergleich
- Abschluss
- Häufig gestellte Fragen
Triton Inference Server: Ein tiefer Tauchgang
Triton Inference Server ist eine robuste Plattform für die Bereitstellung und Skalierung von maschinellen Lernmodellen in der Produktion. Es wird von Nvidia entwickelt und unterstützt TensorFlow, Pytorch, ONNX und benutzerdefinierte Backends.
Schlüsselmerkmale:
- Modellverwaltung: Dynamisches Laden/Entladen, Versionskontrolle.
- Inferenzoptimierung: Multimodell-Ensembles, Chargen, dynamische Charge.
- Metriken und Protokollierung: Prometheus -Integration zur Überwachung.
- Beschleunigerunterstützung: GPU-, CPU- und DLA -Unterstützung.
Einrichtung und Konfiguration:
Triton Setup kann kompliziert sein und die Vertrautheit von Docker und Kubernetes erfordern. Nvidia bietet jedoch umfassende Unterlagen und Unterstützung in der Gemeinschaft.
Anwendungsfall:
Ideal für groß angelegte Bereitstellungen, die Leistung, Skalierbarkeit und Support mit mehreren Rahmen fordern.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)
Optimierung von Umarmungsface -Modellen für die Produktion von Produktionstexten
Dieser Abschnitt konzentriert sich auf die Verwendung von Huggingface -Modellen für die Textgenerierung und betont die native Unterstützung ohne zusätzliche Adapter. Es verwendet Modell -Sharding für parallele Verarbeitung, Pufferung für Anforderungsverwaltung und Batching für die Effizienz. GRPC sorgt für eine schnelle Kommunikation zwischen den Komponenten.
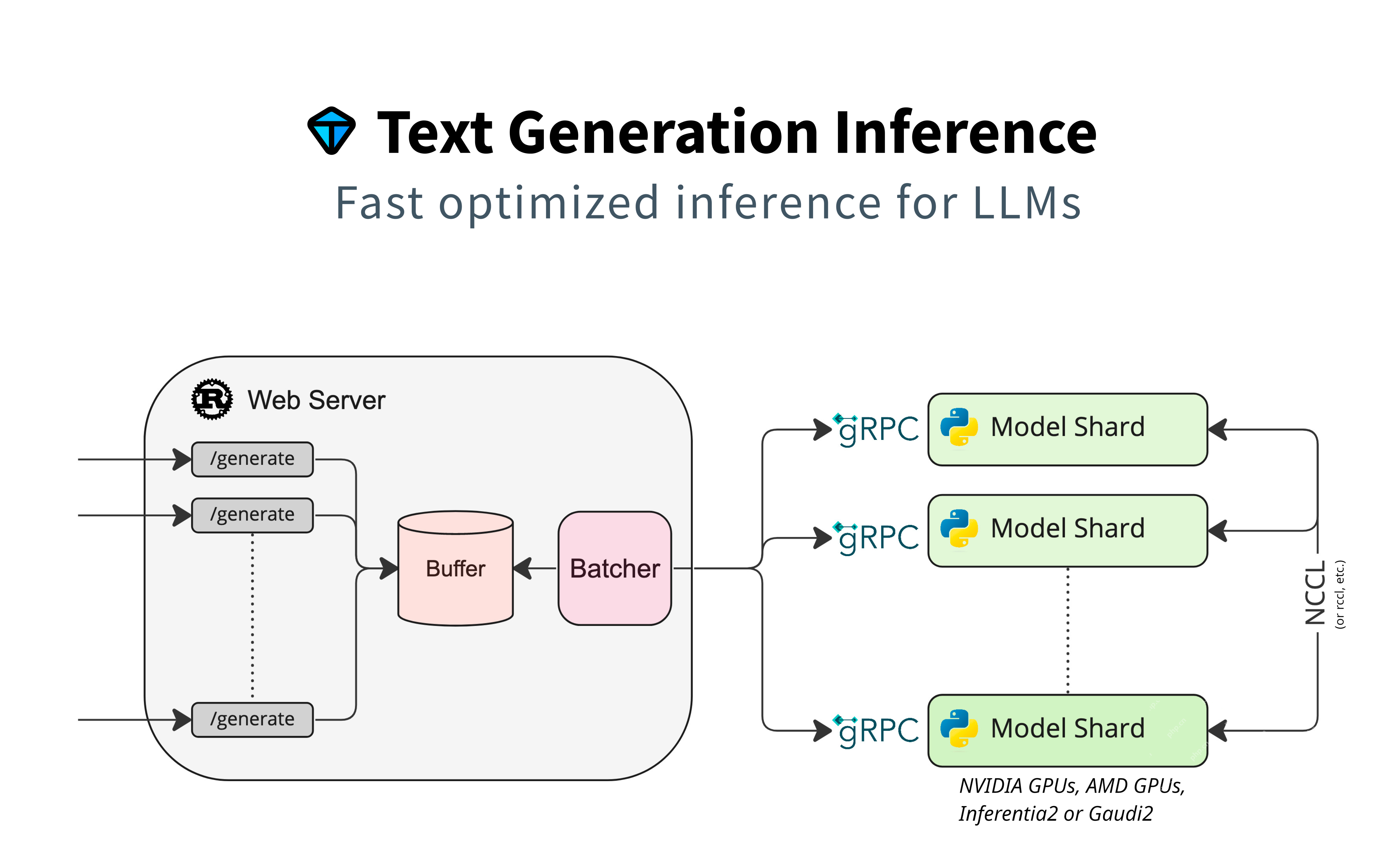
Schlüsselmerkmale:
- Benutzerfreundlichkeit: Nahtloses Umarmungsface-Integration.
- Anpassung: Ermöglicht Feinabstimmungen und benutzerdefinierte Konfigurationen.
- Unterstützung bei Transformatoren: Nutzt die Transformers Library.
Anwendungsfälle:
Geeignet für Anwendungen, die eine direkte Integration des Umarmungsfaktormodells erfordern, z. B. Chatbots und Inhaltsgenerierung.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)
VLLM: Revolutionierung der Stapelverarbeitung für Sprachmodelle
VllM priorisiert die Geschwindigkeit bei der sofortigen Lieferung, optimieren Latenz und Durchsatz. Es verwendet vektorisierte Operationen und parallele Verarbeitung für eine effiziente Chargen -Textgenerierung.

Schlüsselmerkmale:
- Hohe Leistung: optimiert für niedrige Latenz und hohen Durchsatz.
- Batch -Verarbeitung: Effiziente Handhabung von Chargenanfragen.
- Skalierbarkeit: Geeignet für groß angelegte Bereitstellungen.
Anwendungsfälle:
Am besten für Geschwindigkeitskritische Anwendungen wie Echtzeitübersetzung und interaktive KI-Systeme.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)
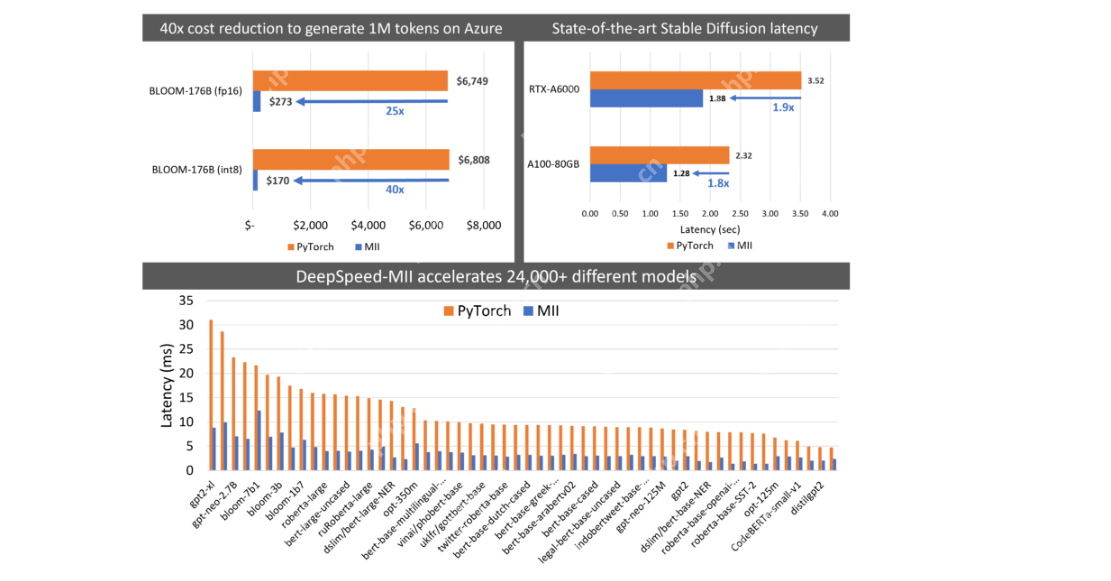
Deepspeed-Mii: Tiefenspeed für eine effiziente LLM-Bereitstellung nutzen
DeepSpeed-Mii ist für Benutzer mit DeepSpeed gedacht, die sich auf eine effiziente LLM-Bereitstellung und Skalierung durch Modellparallelität, Speichereffizienz und Geschwindigkeitsoptimierung konzentrieren.

Schlüsselmerkmale:
- Effizienz: Speicher und Recheneffizienz.
- Skalierbarkeit: Griff sehr große Modelle.
- Integration: nahtlos mit Deepspeed -Workflows.
Anwendungsfälle:
Ideal für Forscher und Entwickler, die mit Deepspeed vertraut sind und Hochleistungsschulungen und -Bereitungen priorisieren.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)
OpenllM: Flexible Adapterintegration
Openllm verbindet Adapter mit dem Kernmodell und verwendet Suggingface -Agenten. Es unterstützt mehrere Frameworks, einschließlich Pytorch.
Schlüsselmerkmale:
- Framework Agnostic: unterstützt mehrere tiefe Lernrahmen.
- Agentenintegration: Nutzung von Umarmungen.
- Adapterunterstützung: Flexible Integration in Modelladapter.
Anwendungsfälle:
Ideal für Projekte, die Framework -Flexibilität und umfangreiche Verwendung von Huggingface -Tools benötigen.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)

Nutzung von Ray, der für die skalierbare Modellbereitstellung dient
Ray Serve bietet eine stabile Pipeline und eine flexible Bereitstellung für reife Projekte, die zuverlässige und skalierbare Lösungen benötigen.
Schlüsselmerkmale:
- Flexibilität: Unterstützt mehrere Bereitstellungsarchitekturen.
- Skalierbarkeit: Griff Hochlastanwendungen.
- Integration: Funktioniert gut mit Rays Ökosystem.
Anwendungsfälle:
Ideal für etablierte Projekte, die eine robuste und skalierbare Servierinfrastruktur erfordern.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)
Beschleunigung der Schlussfolgerung mit ctranslate2
Ctranslate2 priorisiert die Geschwindigkeit, insbesondere für CPU-basierte Inferenz. Es ist für Übersetzungsmodelle optimiert und unterstützt verschiedene Architekturen.
Schlüsselmerkmale:
- CPU -Optimierung: hohe Leistung für die CPU -Inferenz.
- Kompatibilität: Unterstützt beliebte Modellarchitekturen.
- Leichtes Gewicht: Minimale Abhängigkeiten.
Anwendungsfälle:
Geeignet für Anwendungen, die CPU -Geschwindigkeit und -Effizienz wie Übersetzungsdienste priorisieren.
Demo -Code und Erläuterung: (Code bleibt der gleiche wie in der ursprünglichen Eingabe)

Latenz- und Durchsatzvergleich
(Die Tabelle und das Bild, die Latenz und Durchsatz vergleichen, bleiben die gleichen wie in der ursprünglichen Eingabe)
Abschluss
Die effiziente LLM -Portion ist für reaktionsschnelle AI -Anwendungen von entscheidender Bedeutung. In diesem Artikel wurden verschiedene Plattformen mit jeweils einzigartigen Vorteilen untersucht. Die beste Wahl hängt von bestimmten Bedürfnissen ab.
Wichtigste Imbiss:
- Das Modell serviert bereitet geschulte Modelle für Inferenz ein.
- Verschiedene Plattformen zeichnen sich in verschiedenen Leistungsaspekten aus.
- Die Rahmenauswahl hängt vom Anwendungsfall ab.
- Einige Frameworks eignen sich besser für skalierbare Bereitstellungen in reifen Projekten.
Häufig gestellte Fragen:
(Die FAQs bleiben die gleichen wie im ursprünglichen Eingang)
HINWEIS: Die in diesem Artikel gezeigten Medien sind nicht im Besitz von [Erwähnung der zuständigen Entität] und werden nach Ermessen des Autors verwendet.
Das obige ist der detaillierte Inhalt vonOptimierung der KI -Leistung: Ein Leitfaden zur effizienten LLM -Bereitstellung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Gemini als Grundlage der KI -Strategie von Google Gemini ist der Eckpfeiler der AI -Agentenstrategie von Google und nutzt seine erweiterten multimodalen Funktionen, um Antworten auf Text, Bilder, Audio, Video und Code zu verarbeiten und zu generieren. Entwickelt von Deepm
 Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
"Super froh, Ihnen mitteilen zu können, dass wir Pollenroboter erwerben, um Open-Source-Roboter in die Welt zu bringen", sagte Hugging Face auf X.
 DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
In einer bedeutenden Entwicklung für die KI-Community haben Agentica und gemeinsam KI ein Open-Source-KI-Codierungsmodell namens DeepCoder-14b veröffentlicht. Angebotsfunktionen der Codegenerierung mit geschlossenen Wettbewerbern wie OpenAI,
