

Wie benutze ich Apache -Eisberg -Tabellen?

Apache ICEBERG: Ein modernes Tabellenformat für das erweiterte Data Lake Management
Apache Iceberg ist ein hochmodernes Tabellenformat, das die Mängel herkömmlicher Bienenstocktabellen angeht und überlegene Leistung, Datenkonsistenz und Skalierbarkeit liefert. In diesem Artikel wird die Entwicklung von Iceberg, die wichtigsten Merkmale (Säuretransaktionen, Schemaentwicklung, Zeitreisen), Architektur und Vergleiche mit anderen Tabellenformaten wie Delta Lake und Parquet untersucht. Wir werden auch seine Integration in moderne Datenseen und ihre Auswirkungen auf das große Datenmanagement und die Analyse des Datenverwaltungswesens untersuchen.
Wichtige Lernpunkte
- Fassen Sie die Kernmerkmale und die Architektur von Apache Iceberg.
- Verstehen Sie, wie Eisberg das Schema und die Partitionentwicklung ohne Daten umschrieben.
- Erforschen Sie, wie Säuretransaktionen und Zeitreisen die Datenkonsistenz stärken.
- Vergleichen Sie die Fähigkeiten von Iceberg mit Delta Lake und Hudi.
- Identifizieren Sie Szenarien, in denen Eisberg die Leistung des Datensees optimiert.
Inhaltsverzeichnis
- Einführung in Apache Iceberg
- Die Entwicklung von Eisberg
- Verständnis des Eisberg -Formats
- Kernmerkmale von Apache Iceberg
- Taucher in Eisbergs Architektur eintauchen
- Eisberg gegen andere Tischformate: Ein Vergleich
- Abschluss
- Häufig gestellte Fragen
Einführung in Apache Iceberg
Apache Iceberg wurde 2017 (die Idee von Ryan Blue und Daniel Weeks) auf Netflix (die Idee von Ryan Blue und Daniel Weeks) erstellt und wurde erstellt, um Leistungsengpässe, Konsistenzprobleme und Einschränkungen des Hive -Tabellenformats zu lösen. Open-Sourced und spendete 2018 an die Apache Software Foundation und erlangte schnell an die Anziehung und lieferte Beiträge von Branchengiganten wie Apple, AWS und LinkedIn.
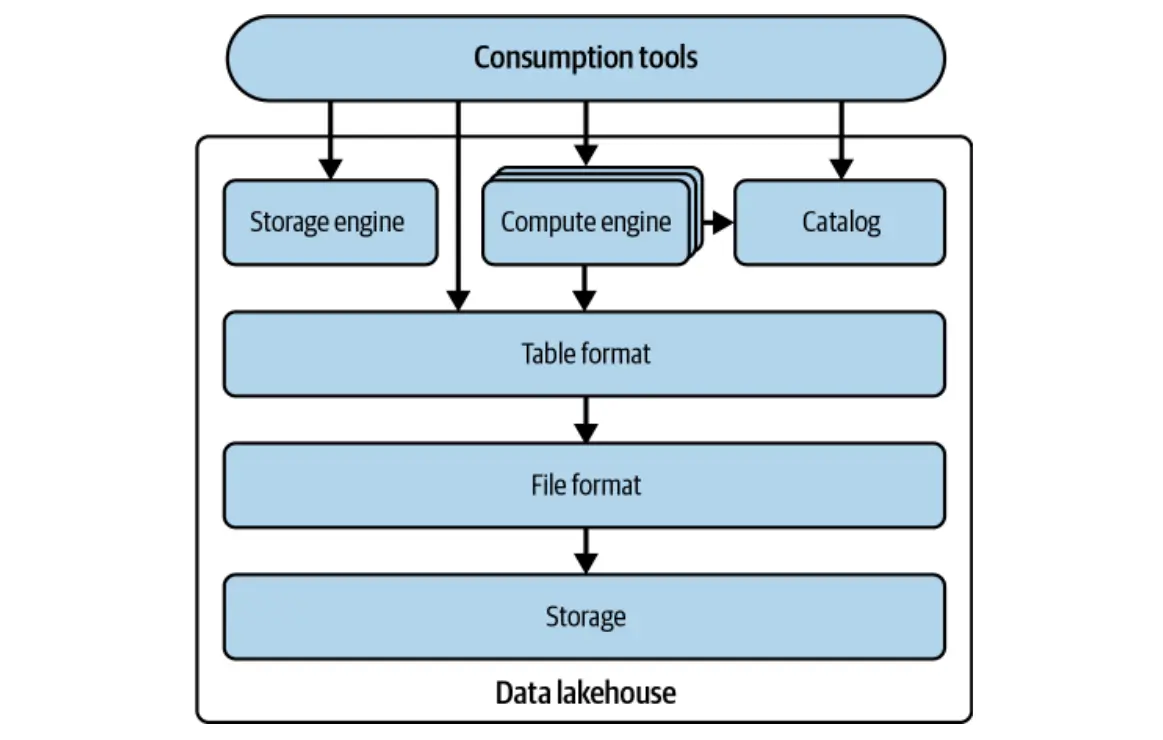
Die Entwicklung von Apache Iceberg
Die Erfahrung von Netflix zeigte eine kritische Schwäche im Bienenstock: seine Abhängigkeit von Verzeichnissen für die Tischverfolgung. Dieser Ansatz fehlte die Granularität, die für eine robuste Konsistenz, effiziente Parallelität und die erwarteten fortschrittlichen Merkmale in modernen Data Warehouses erforderlich war. Die Entwicklung von Iceberg zielte darauf ab, diese Einschränkungen zu überwinden, mit einem Fokus auf:
Wichtige Designziele
- Datenkonsistenz: Aktualisierungen über mehrere Partitionen hinweg müssen atomar und nahtlos sein, wodurch die Benutzer inkonsistente Daten angezeigt werden.
- Leistungsoptimierung: Effizientes Metadatenmanagement war von größter Bedeutung, um Abfragenplanung Engpässe zu beseitigen und die Ausführung der Abfrage zu beschleunigen.
- Benutzerfreundlichkeit: Die Partitionierung sollte für die Benutzer transparent sein und eine automatische Abfrageoptimierung ohne manuelle Intervention ermöglichen.
- Schema -Anpassungsfähigkeit: Schema -Modifikationen sollten sicher behandelt werden, ohne dass vollständige Datensatzumschreiben erforderlich sind.
- Skalierbarkeit: Die Lösung musste effizient Petabyte von Daten verarbeiten und die Skala von Netflix widerspiegeln.
Verständnis des Eisberg -Formats
Iceberg befasst sich mit diesen Herausforderungen, indem sie Tabellen als strukturierte Liste von Dateien und nicht als Verzeichnis verfolgen. Es bietet ein standardisiertes Format, das Metadatenstruktur für mehrere Dateien definiert und Bibliotheken für eine nahtlose Integration in beliebte Motoren wie Spark und Flink bietet.
Ein Datenseestandard
Das Design von Iceberg Prioritiert die Kompatibilität mit vorhandenen Speicher- und Berechnung von Motoren und fördert eine breite Akzeptanz ohne wesentliche Änderungen. Ziel ist es, Eisberg als Branchenstandard zu etablieren, sodass Benutzer unabhängig vom zugrunde liegenden Format mit Tabellen interagieren können. Viele Datenwerkzeuge bieten jetzt native Eisberg -Unterstützung.
Kernmerkmale von Apache Iceberg
Iceberg übertrifft einfach die Grenzen von Hive. Es führt leistungsstarke Funktionen für die Verbesserung des Datenloads von Data Lake und Data Lakehouse. Zu den wichtigsten Funktionen gehören:
Säure -Transaktionsgarantien
Iceberg verwendet eine optimistische Parallelitätskontrolle, um die Säureeigenschaften sicherzustellen, und garantiert, dass Transaktionen entweder vollständig engagiert oder vollständig zurückgerollt sind. Dies minimiert Konflikte bei der Aufrechterhaltung der Datenintegrität.
Partitionentwicklung
Im Gegensatz zu herkömmlichen Datenseen ermöglicht Iceberg die Änderung der Partitionierungsschemata, ohne die gesamte Tabelle neu zu schreiben. Dies gewährleistet eine effiziente Abfrageoptimierung, ohne vorhandene Daten zu stören.
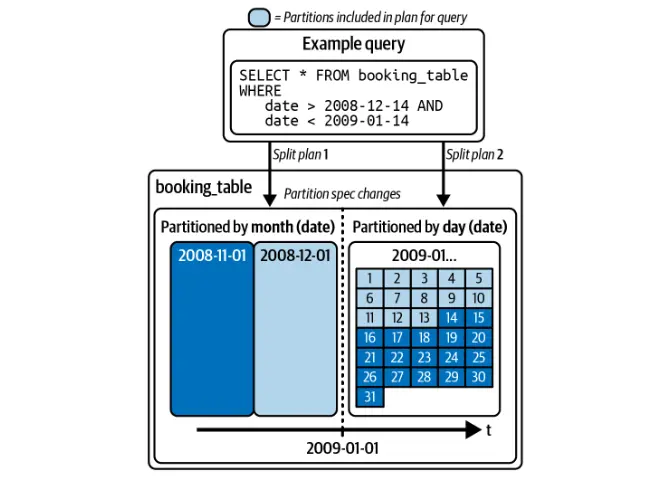
Versteckte Partitionierung
Iceberg optimiert automatisch Abfragen, die auf der Partitionierung basieren, und beseitigt die Notwendigkeit, dass Benutzer manuell durch Partitionsspalten filtern.
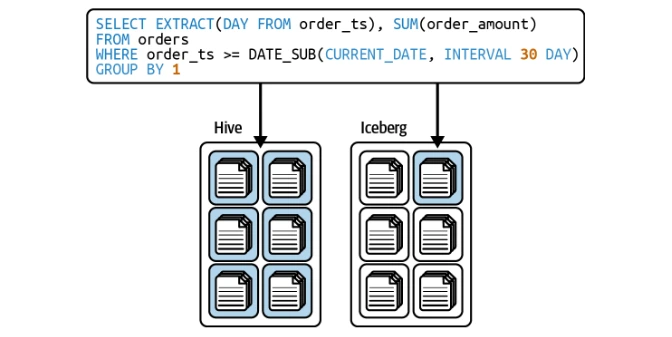
Operationen auf Zeilenebene (Kopie auf dem Schreiben und Merge-on-Read)
Iceberg unterstützt sowohl Kopien-auf-Schrei- als auch MORGE-On-Read-Strategien für effiziente Updates auf Zeilenebene.
Zeitreisen und Versionsrollback
Die unveränderlichen Schnappschüsse von Iceberg ermöglichen Zeitreisefragen und die Möglichkeit, in frühere Tischzustände zurückzukehren.

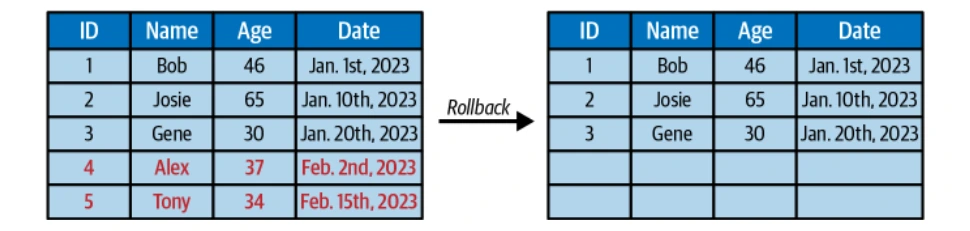
Schemaentwicklung
Iceberg unterstützt Schema -Modifikationen (Hinzufügen, Entfernen oder Ändern von Spalten), ohne dass Daten umschreiben, um Flexibilität und Kompatibilität zu gewährleisten.
Taucher in Eisbergs Architektur eintauchen
In diesem Abschnitt werden die Architektur von Iceberg und wie sie die Grenzen von Hive überwindet.
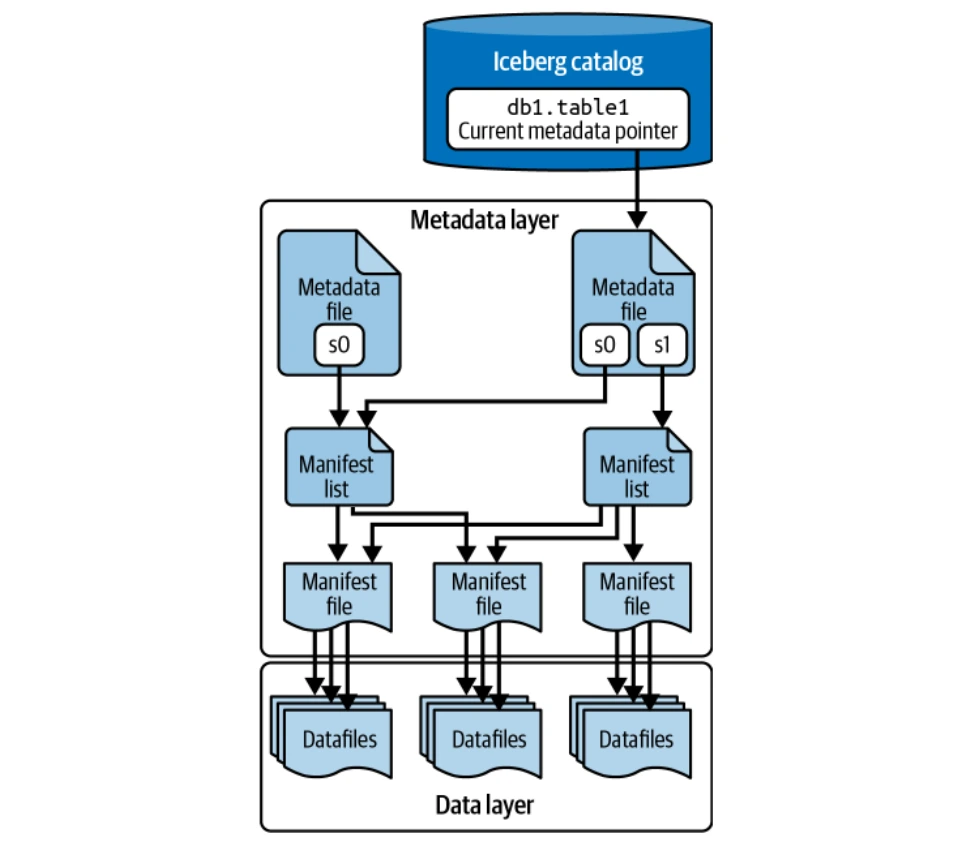
Die Datenschicht
Die Datenschicht speichert die tatsächlichen Tabellendaten (Datendateien und Löschen von Dateien). Es wird in verteilten Dateisystemen (HDFs, S3 usw.) gehostet und unterstützt mehrere Dateiformate (Parquet, ORC, AVRO). Parquet wird üblicherweise für seine Säulenspeicherung bevorzugt.


Die Metadatenschicht
Diese Ebene verwaltet alle Metadatendateien in einer Baumstruktur und verfolgt Datendateien und Operationen. Zu den Schlüsselkomponenten gehören Manifestdateien, Manifest -Listen und Metadatendateien. Puffin -Dateien speichern erweiterte Statistiken und Indizes für die Abfrageoptimierung.
Der Katalog
Der Katalog fungiert als zentrales Register und bietet den Standort der aktuellen Metadatendatei für jede Tabelle an, um alle Leser und Autoren konsistenten Zugriff zu gewährleisten. Verschiedene Backends können als Eisberg -Katalog (Hadoop -Katalog, Hive -Metastore, Nessie -Katalog, AWS -Kleberkatalog) dienen.
Eisberg gegen andere Tischformate: Ein Vergleich
Iceberg, Parquet, Orc und Delta Lake werden häufig in der Datenverarbeitung in großem Maßstab verwendet. Iceberg unterscheidet sich als Tabellenformat, das Transaktionsgarantien und Metadatenoptimierungen bietet, im Gegensatz zu Parquet und ORC, die Dateiformate sind. Im Vergleich zu Delta Lake zeichnet sich Iceberg in Schema und Partitionentwicklung aus.
Abschluss
Apache Iceberg bietet einen robusten, skalierbaren und benutzerfreundlichen Ansatz für das Data Lake-Management. Seine Funktionen machen es zu einer überzeugenden Lösung für Organisationen, die mit groß angelegten Daten umgehen.
Häufig gestellte Fragen
Q1. Was ist Apache Iceberg? A. Ein modernes Open-Source-Tabellenformat verbessert die Leistung, Konsistenz und Skalierbarkeit von Datensee.
Q2. Warum wird Apache Iceberg benötigt? A. um die Einschränkungen von Hive bei Metadatenhandhabung und Transaktionsfunktionen zu überwinden.
Q3. Wie geht Eisberg mit der Schema -Evolution um? A. Es unterstützt Schemaänderungen, ohne dass eine vollständige Tischumschreibung erforderlich ist.
Q4. Was ist die Partitionentwicklung in Eisberg? A. Änderung von Partitionierungsschemata ohne Umschreiben historischer Daten.
Q5. Wie unterstützt Eisberg Säuretransaktionen? A. durch optimistische Parallelitätskontrolle, um Atomaktualisierungen zu gewährleisten.
Das obige ist der detaillierte Inhalt vonWie benutze ich Apache -Eisberg -Tabellen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und Kosteneffizienz
Apr 16, 2025 am 11:37 AM
Die Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
 Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Raketenstartsimulation und -analyse unter Verwendung von Rocketpy - Analytics Vidhya
Apr 19, 2025 am 11:12 AM
Simulieren Raketenstarts mit Rocketpy: Eine umfassende Anleitung Dieser Artikel führt Sie durch die Simulation von Rocketpy-Starts mit hoher Leistung mit Rocketpy, einer leistungsstarken Python-Bibliothek. Wir werden alles abdecken, von der Definition von Raketenkomponenten bis zur Analyse von Simula
 Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Google enthüllt die umfassendste Agentenstrategie bei Cloud nächsten 2025
Apr 15, 2025 am 11:14 AM
Gemini als Grundlage der KI -Strategie von Google Gemini ist der Eckpfeiler der AI -Agentenstrategie von Google und nutzt seine erweiterten multimodalen Funktionen, um Antworten auf Text, Bilder, Audio, Video und Code zu verarbeiten und zu generieren. Entwickelt von Deepm
 Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
Open Source Humanoide Roboter, die Sie 3D selbst ausdrucken können: Umarme Gesicht kauft Pollenroboter
Apr 15, 2025 am 11:25 AM
"Super froh, Ihnen mitteilen zu können, dass wir Pollenroboter erwerben, um Open-Source-Roboter in die Welt zu bringen", sagte Hugging Face auf X.
 DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
DeepCoder-14b: Der Open-Source-Wettbewerb mit O3-Mini und O1
Apr 26, 2025 am 09:07 AM
In einer bedeutenden Entwicklung für die KI-Community haben Agentica und gemeinsam KI ein Open-Source-KI-Codierungsmodell namens DeepCoder-14b veröffentlicht. Angebotsfunktionen der Codegenerierung mit geschlossenen Wettbewerbern wie OpenAI,
