
 Technologie-Peripheriegeräte
KI
Koka: Kontrastive Bildunterschriften sind Bild-Text-Fundamentmodelle visuell erklärt
Technologie-Peripheriegeräte
KI
Koka: Kontrastive Bildunterschriften sind Bild-Text-Fundamentmodelle visuell erklärt
Koka: Kontrastive Bildunterschriften sind Bild-Text-Fundamentmodelle visuell erklärt

Dieses Tutorial für die DataCamp-Community, die für Klarheit und Genauigkeit bearbeitet wurde, untersucht die Modelle der Bild-Text-Grundlage und konzentriert sich auf das innovative Contrastive Captioner (CoCA) -Modell. Coca kombiniert kontrastive und generative Lernziele einzigartig und integrieren die Stärken von Modellen wie Clip und Simvlm in eine einzelne Architektur.

Fundamentmodelle: Ein tiefes Tauchgang
Fundamentmodelle, die auf massiven Datensätzen vorgebracht sind, sind für verschiedene nachgeschaltete Aufgaben anpassbar. Während NLP einen Anstieg der Fundamentmodelle (GPT, Bert) verzeichnet hat, entwickeln sich auch immer noch die Modelle für Visionen und Visionsprachen. Untersuchungen haben drei primäre Ansätze untersucht: Einzel-Encoder-Modelle, Image-Text-Dual-Coder mit kontrastivem Verlust und Encoder-Decoder-Modellen mit generativen Zielen. Jeder Ansatz hat Einschränkungen.
Schlüsselbegriffe:
- Fundamentmodelle: Vorausgebildete Modelle anpassbar für verschiedene Anwendungen.
- Kontrastiven Verlust: Eine Verlustfunktion, die ähnliche und unterschiedliche Eingangspaare vergleicht.
- Quermodal-Wechselwirkung: Wechselwirkung zwischen verschiedenen Datentypen (z. B. Bild und Text).
- Encoder-Decoder-Architektur: Ein neuronales Netzwerkverarbeitungsing und generierende Ausgabe.
- Null-Shot-Lernen: Vorhersage von unsichtbaren Datenklassen.
- Clip: Ein kontrastives Sprachbild-Vor-Training-Modell.
- SIMVLM: Ein einfaches visuelles Sprachmodell.
Modellvergleiche:
- Einzel-Encoder-Modelle: Excel bei Visionsaufgaben, aber kämpfen
- Bild-Text-Doppel-Coder-Modelle (Clip, Align): Hervorragend für Klassifizierung und Abruf von Null-Shots, aber in Aufgaben begrenzt, die fusionierte Bildtextdarstellungen erforderlich sind (z. B. visuelle Beantwortung). . .
- Generative Modelle (SIMVLM): Verwenden Sie die Quermodale Interaktion für die gemeinsame Bildtextdarstellung, geeignet für VQA und Bildunterschriften.
Coca: Überbrückung der Lücke
coca zielt darauf ab, die Stärken kontrastiver und generativer Ansätze zu vereinen. Es verwendet einen kontrastiven Verlust, um Bild- und Textdarstellungen und ein generatives Ziel (Bildunterschriftenverlust) auszurichten, um eine gemeinsame Darstellung zu erzeugen.
Coca -Architektur:
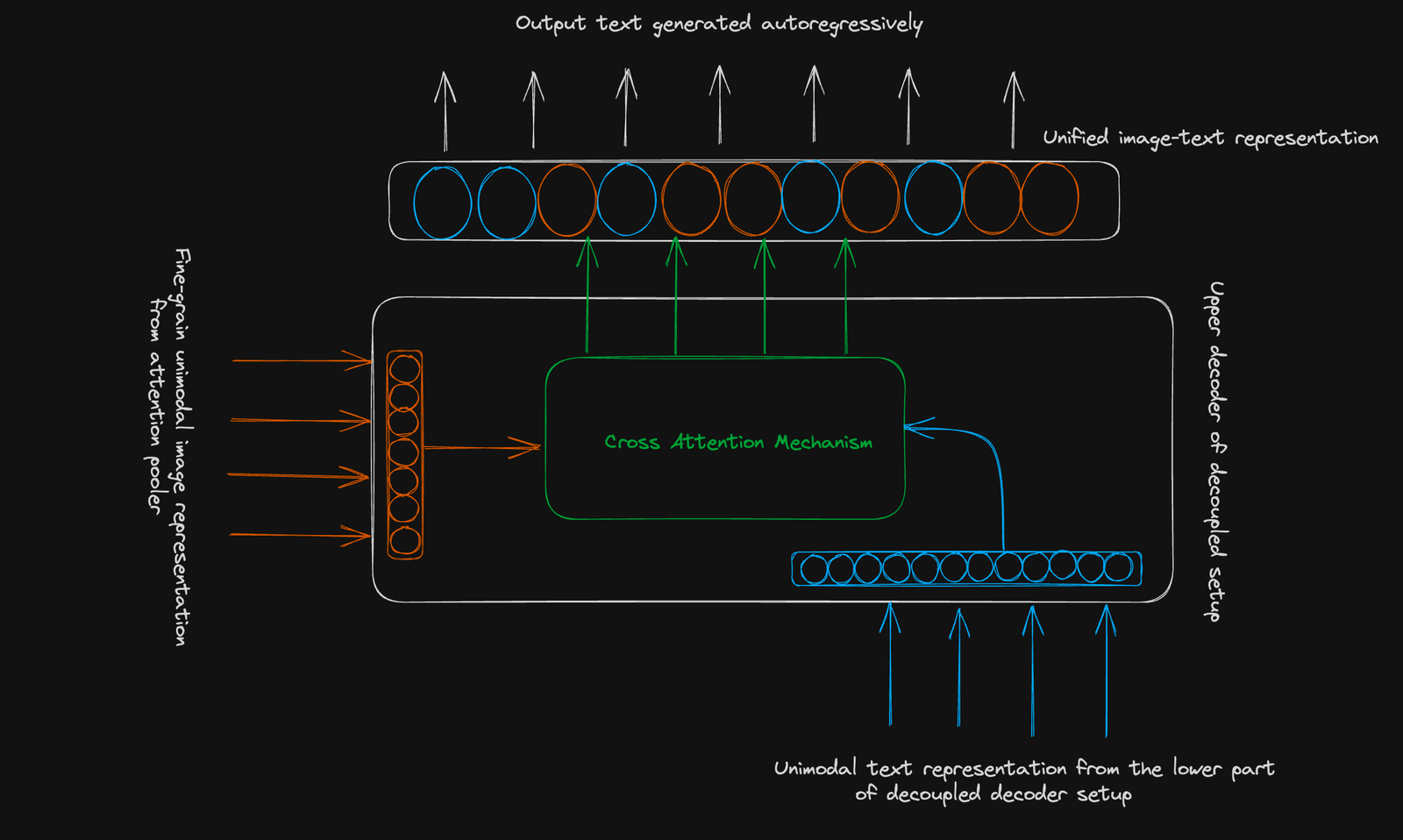
Coca verwendet eine Standard-Encoder-Decoder-Struktur. Seine Innovation liegt in einem entkoppelten Decoder :
- Unter Decodierer: erzeugt eine unimodale Textdarstellung für kontrastives Lernen (unter Verwendung eines [CLS] -Tokens).
- Oberer Decoder: generiert eine multimodale Bild-Text-Darstellung für generatives Lernen. Beide Decoder verwenden kausale Maskierung.
Kontrastes Ziel: lernt, im Zusammenhang mit Bildtextpaaren zu clusterbezogenen und nicht verwandten, in einem gemeinsam genutzten Vektorraum getrennt. Eine einzelne gepoolte Bildeinbettung wird verwendet.
generatives Ziel: verwendet eine feinkörnige Bilddarstellung (256-dimensionale Sequenz) und die modale Aufmerksamkeit, um Text autoregressiv vorherzusagen.

Schlussfolgerung:
coca stellt einen signifikanten Fortschritt in den Modellen der Bild-Text-Grundlage dar. Der kombinierte Ansatz verbessert die Leistung in verschiedenen Aufgaben und bietet ein vielseitiges Tool für nachgeschaltete Anwendungen. Um Ihr Verständnis für fortgeschrittene Deep -Learning -Konzepte zu fördern, betrachten Sie DataCamps fortgeschrittenes Deep Learning mit Keras -Kurs.
Weitere Lesen:
- übertragbare visuelle Modelle von natürlicher Sprache aus natürlicher Sprache lernen
- Bild-Text vor dem Training mit kontrastiven Bildunterschriften
Das obige ist der detaillierte Inhalt vonKoka: Kontrastive Bildunterschriften sind Bild-Text-Fundamentmodelle visuell erklärt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1666
1666
 14
1425
52
1328
25
1273
29
1253
24
14
1425
52
1328
25
1273
29
1253
24

 10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
10 generative AI -Codierungsweiterungen im VS -Code, die Sie untersuchen müssen
Apr 13, 2025 am 01:14 AM
Hey da, codieren Ninja! Welche Codierungsaufgaben haben Sie für den Tag geplant? Bevor Sie weiter in diesen Blog eintauchen, möchte ich, dass Sie über all Ihre Coding-Leiden nachdenken-die Auflistung auflisten diese auf. Erledigt? - Lassen Sie ’
 GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
GPT-4O gegen OpenAI O1: Ist das neue OpenAI-Modell den Hype wert?
Apr 13, 2025 am 10:18 AM
Einführung OpenAI hat sein neues Modell auf der Grundlage der mit Spannung erwarteten „Strawberry“ -Scharchitektur veröffentlicht. Dieses innovative Modell, bekannt als O1
 Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics Vidhya
Apr 17, 2025 am 11:43 AM
SQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics Vidhya
Apr 13, 2025 am 11:20 AM
Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics Vidhya
Apr 13, 2025 am 11:20 AM
Einführung Mistral hat sein erstes multimodales Modell veröffentlicht, nämlich den Pixtral-12b-2409. Dieses Modell basiert auf dem 12 -Milliarden -Parameter von Mistral, NEMO 12b. Was unterscheidet dieses Modell? Es kann jetzt sowohl Bilder als auch Tex aufnehmen
 Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Wie baue ich multimodale KI -Agenten mit AGNO -Framework auf?
Apr 23, 2025 am 11:30 AM
Während der Arbeit an Agentic AI navigieren Entwickler häufig die Kompromisse zwischen Geschwindigkeit, Flexibilität und Ressourceneffizienz. Ich habe den Agenten-KI-Framework untersucht und bin auf Agno gestoßen (früher war es phi-
 Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Jenseits des Lama -Dramas: 4 neue Benchmarks für große Sprachmodelle
Apr 14, 2025 am 11:09 AM
Schwierige Benchmarks: Eine Lama -Fallstudie Anfang April 2025 stellte Meta seine Lama 4-Suite von Models vor und stellte beeindruckende Leistungsmetriken vor, die sie positiv gegen Konkurrenten wie GPT-4O und Claude 3.5 Sonnet positionierten. Zentral im Launc
 Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Wie ADHS -Spiele, Gesundheitstools und KI -Chatbots die globale Gesundheit verändern
Apr 14, 2025 am 11:27 AM
Kann ein Videospiel Angst erleichtern, Fokus aufbauen oder ein Kind mit ADHS unterstützen? Da die Herausforderungen im Gesundheitswesen weltweit steigen - insbesondere bei Jugendlichen - wenden sich Innovatoren einem unwahrscheinlichen Tool zu: Videospiele. Jetzt einer der größten Unterhaltungsindus der Welt
 Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Neuer kurzer Kurs zum Einbetten von Modellen von Andrew NG
Apr 15, 2025 am 11:32 AM
Schalte die Kraft des Einbettungsmodelle frei: einen tiefen Eintauchen in den neuen Kurs von Andrew Ng Stellen Sie sich eine Zukunft vor, in der Maschinen Ihre Fragen mit perfekter Genauigkeit verstehen und beantworten. Dies ist keine Science -Fiction; Dank der Fortschritte in der KI wird es zu einem R
